

作者 | 百度MEG离线优化团队
导读
近些年移动互联网的高速发展驱动了数据爆发式的增长,各大公司之间都在通过竞争获得更大的增长空间,大数据计算的效果直接影响到公司的发展,而这背后其实依赖庞大的算力及数据作为支撑,因此在满足业务迭代的前提下如何控制成本是公司非常重要的一环。
本文将介绍百度MEG(移动生态事业群组)在离线资源降本增效方面用到的一些技术以及取得的一些成果。
全文4478字,预计阅读时间12分钟。
01 业务背景
随着百度App的日活用户的持续增长,为了满足广大用户对信息资讯更加精准的需求,MEG的各个业务模块对于离线算力和存储的需求也不断增加通过其驱动上层模型获得更好的效果,因此离线成本也逐年增加,如何满足业务增长的情况下最小化机器资源成本是本文重点关注的问题。就拿百度App后端推荐服务(后简称Feed)举例,拥有离线大数据计算数百万核、分布式存储数百PB,成本以亿为单位,而且还在持续增长,因此我们希望能够在满足推荐效果的前提下优化降低离线的成本。整体离线计算主要分为两大类,即数据挖掘类和数据分析类,其中挖掘类场景主要是通过python脚本提交的MapReduce任务为主,分析类场景主要是Spark及SQL类为主,底层集群资源都是EMR,存储统一使用百度公司分布式文件存储Appendonly File Storage(后简称AFS)。
02 优化思路
下面介绍下我们的优化思路,在此之前说下整个离线的业务背景,主要从三个方面说明,第一是管理混乱,队列失控、任务失控;第二是成本高,千万核计算、EB级的存储使用率低,同时增量的需求无法满足;第三是效率,包括任务运行的效率和资源交付的效率,主要表现为队列拥堵,任务跑不动。
针对以上问题及痛点,首先针对管理混乱的问题我们通过平台进行离线资源任务的全生命周期管理;其次是针对资源使用率低成本高的问题,我们自研智能调度机制实现对不同使用率队列的削峰填谷,基于存算分离技术实现快速合池,通过潮汐算力分时调度优化白天紧张的算力供给增量业务,再就是与INF共建RSS技术并规模化落地优化混部资源的稳定性,还有就是针对EB级的存储进行动态扩缩容实现存储的优化和供给。整体的挑战是如何利用有限的资源满足无限的需求。
03 算力优化
3.1 合池技术
接下来介绍下算力优化的第一个优化点,合池技术,首先说下为什么要合池,因为碎片化的队列会导致弹性不足、使用率很难最大化,维护成本高。如下图所示,一个大约5w核的队列,它的峰值是达到上限了,但是均值很低,很难满足更大资源量但是执行较快的需求,因此一方面是期望能把小的这种队列合并,另一方面提升整体的使用率,如下图第二个队列,最终实现降本增效。
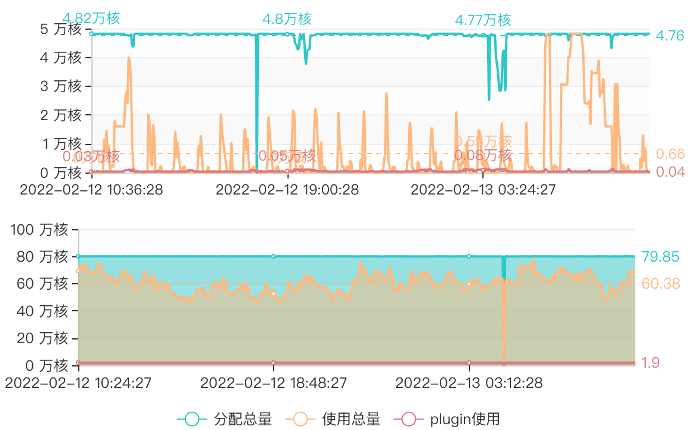
合池最大的挑战分两块,一是合池后如何保证任务的性能不退化,同时如何保障资源效率,二如何对业务无感透明合池。
接下来大致粗略的说一下合池的过程,如下图所示:就是将等量资源的几个小队列进行合并,提升队列的使用率上限,满足业务需求的同时退订一部分资源。
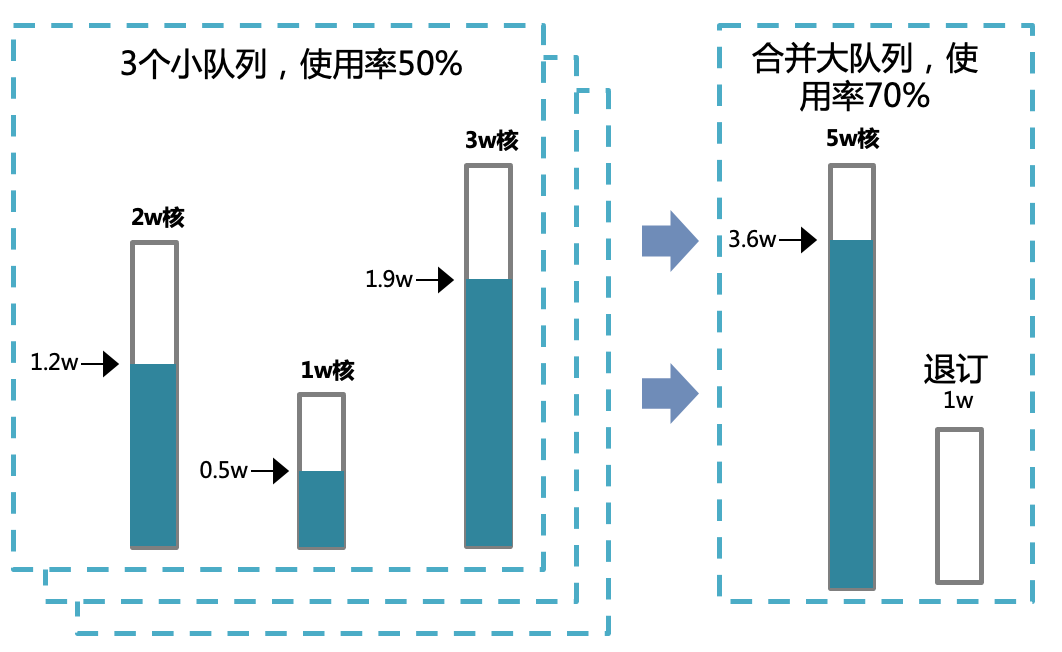
整体的技术方案主要包括两部分,一是智能调度,二是存算分离技术,下面会分开介绍下这两项技术的实现。
3.1.1 智能调度
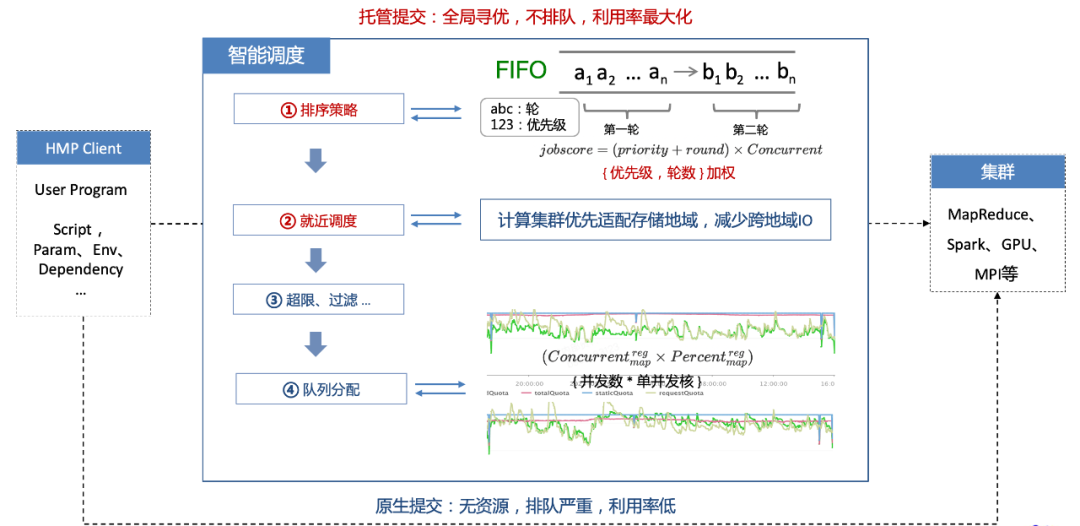
如下图所示,智能调度的整体架构如下,首先一个基于python的client,负责将用户的程序、参数、环境依赖等等进行打包,然后通过智能调度系统异步提交,系统会根据任务维度多维的特征,比如优先级、并发、所需资源等信息结合资源实时的水位进行智能最优匹配,其中调度系统比较核心的也是首要的就是排序,即要解决先调度谁后调度谁的问题,如下图中的排序策略,首先是一个FIFO的队列模型,排序策略会根据任务的优先级、等待轮数进行加权,然后结合任务的并发系数进而计算出来先后顺序,优先级分位三挡,VERY-HIGH、HIGH、NORMAL,优先级越高权重越大,其次是等待的时长越长权重越大,越优先调度;有了顺序后后面会根据任务要读取数据的地域就近匹配计算队列,减少跨地域网络IO的开销,此外还有队列资源打满或异常等过滤策略,以及任务使用资源超限降级等策略,最后是针对排好序的任务进行队列分配,根据实时获取的队列资源水位结合任务提交所需要的资源量(并发数*单并发核数),分配好队列,任务会被worker正式提交到集群上面去。智能调度在整个合池过程中充当非常重要的角色,它能保障任务在合池后性能不退化,通过合理的编排,针对峰谷不一的资源进行打平调度,重复利用闲散资源提升整体资源利用率。
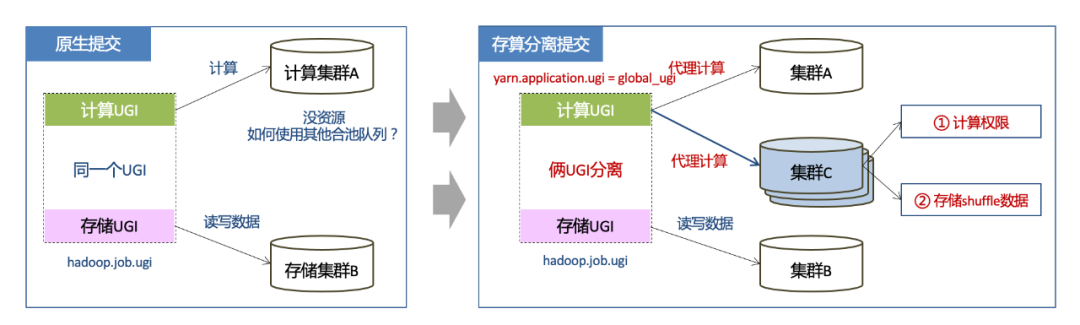
3.1.2 存算分离
刚才介绍的是调度提交的过程,此外在合池过程中另外一项核心的技术是存算分离,它是解决碎片化队列快速合池的关键,核心的点是说我们会提前在各个集群新建一个计算的ugi,并且给这个ugi分配好计算所需要的临时存储并开通合池队列的计算权限,UGI存算分离后,原来用户的UGI只作为读写数据使用,代理计算的UGI提前开通各集群的权限,并分配好中间存储,调度系统会自动调度到有资源的合池队列,用户不需要改代码,合池透明化。
总结下合池以后的效果,资源池化以后,千万核计算资源整体的使用率从55%提升到80%,增量供给和优化退订了数百万核资源,成本年化降低数千万。此外池化是得资源的交付效率大幅提升,从之前周级、月级缩短到天级,任务的整体耗时通过合理的调度和编排也降低了30%。
3.2 潮汐算力
接下来我介绍下算力优化的第二个优化点,潮汐,它的特点是体量大、数百万核、夜间特定时间段供给,成本低,免费用。可以用潮汐技术的场景包括策略模型调研类,数据回溯类等。如何把这部分资源充分利用好是项目的核心,主要通过如下三种方式实现潮汐的规模化应用,第一是显式的注册引导,第二是对存量可在夜间运行任务的画像挖掘,第三是对资源使用超限的分时管控,如下图所示:

△潮汐规模化应用的方式
潮汐的挑战有两个,第一是如何对存量任务画像、怎么尽可能保障在潮汐退场前执行完,如下图所示,接下来重点介绍下方案,就是通过隐式挖掘存量任务转潮汐,因为潮汐资源是0点供给5点准时退场,因此我们期望对一些存量例行的任务进行画像让它能够通过潮汐时间段加速实现算力优化,释放更多白天的算力,这里画像主要包括执行周期、频次、并发数、task总量等,利用这些信息给任务打一个潮汐的tag,在这个任务下次提交的时候使用一个时间加速模型判断其是否能在潮汐退场前执行完,该模型主要是通过例行任务常规的运行时间以及map、reduce的数量、并发量等计算出一轮计算缩需要的时间,然后乘以提升并发量以后要跑的轮数,算出来加速后的预期完成时间,然后判断是否能在潮汐退场前执行完,这块分两种情况,0-5点,5-24点,公式略有差异。
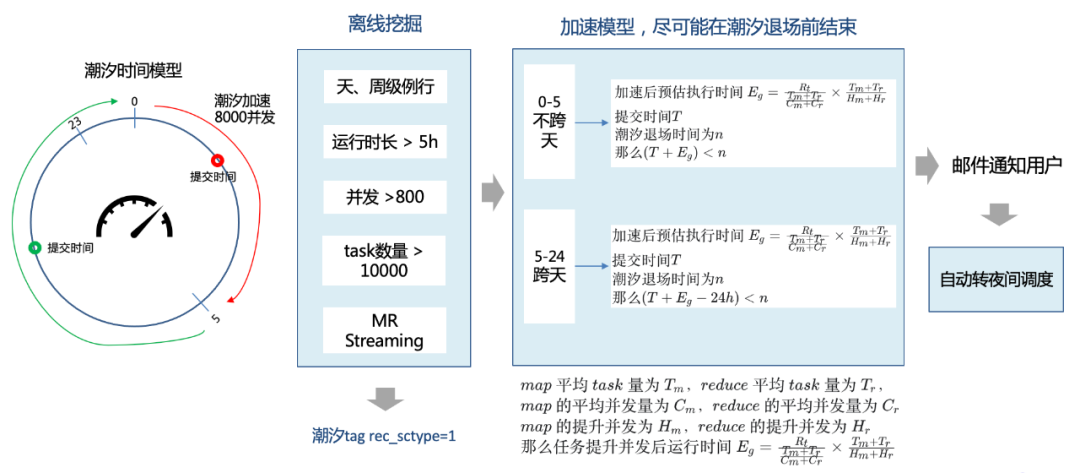
△潮汐时间加速模型
下面介绍一下潮汐的第二个技术点,也即是前面提到的另一个挑战,如何保障潮汐任务瞬时退场后不失败,第二天潮汐窗口来临后继续跑,解决方案是在现有的合池队列上进行扩展,在潮汐退场前提前降低并发,白天低速运行。
总结下潮汐在离线大规模应用的效果,首先是规模,目前潮汐的资源规模达到300W核,通过画像挖掘存量转夜间实现了年化约600万成本的节省。业务方面的话,有100+回溯、调研类任务通过潮汐实现了资源的满足,加速了模型调研的效率,提升了模型的效果。
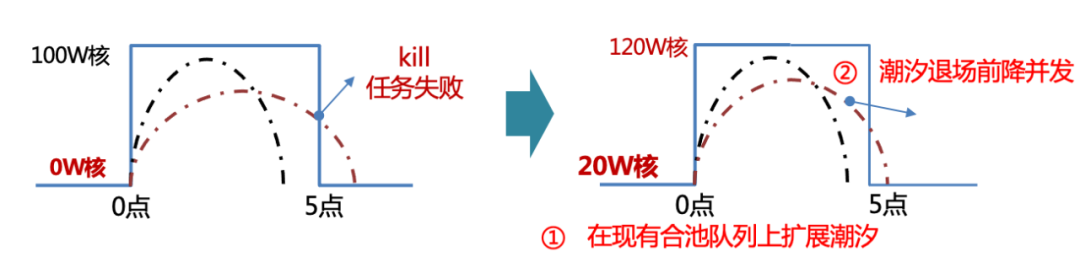
△潮汐队列断点续跑
3.3 RSS技术
接下来我介绍下算力优化的第三个优化点,RSS(Remote Shuffle Service)技术的规模化应用,大背景是离线标准型资源稳定,但成本高、稀缺,而混部资源成本低容易供给,但稳定性差、失败率高容易被抢占,如下图所示,失败率比较高。

△混部资源task失败率高
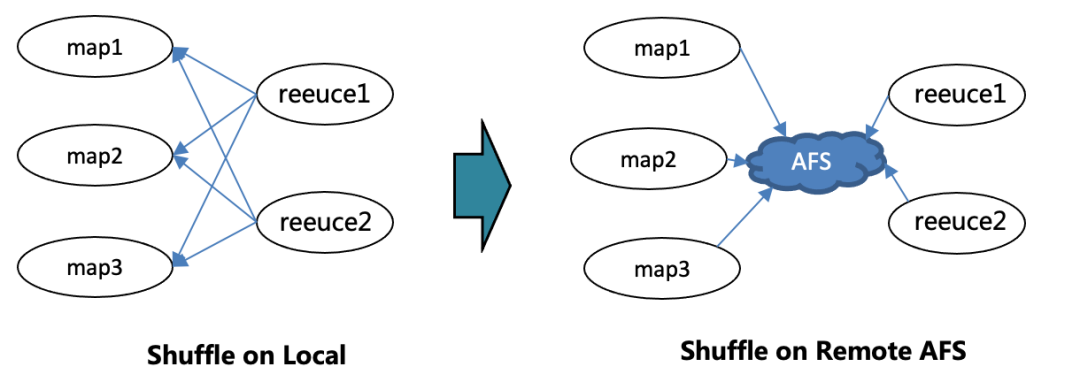
如果reduce2运行中被抢占,需要从所有上游map重新拉取数据,而上游map已经被另一个任务占用,也需要重新排队计算因此造成时长增加,因此RSS技术的核心是把shuffle数据存远程文件系统,这样reduce被抢占的话直接从afs拉取map产出,map不需要重算,开启RSS的任务执行时间基本与标准型资源性能持平。
04 储存优化
4.1 背景介绍
存储资源预算逐年收紧,为应对接下来的业务增长,需求基本靠优化来满足。当前整个公司储存空间的使用率大约为60%,从使用率维度看任然有一定的提升空间。Google Research于2021年发表了一篇名为Autopilot的论文《Autopilot: Workload Autoscaling at Google Scale》,核心思想是Quota Auto Resize By workloads,即根据实际quota使用情况动态分配,可引入一些简单的模型预测quota的需求变化量,该思想是我们实现AFS Quota超售的基本技术支撑,即按实际使用分配同时保障使用的时候能分配到,这样最大的好处就是存储是一个可被全局调度的大池,既能最大化提高存储流转回收的效率又可以提升整体存储的使用率进而达到成本优化的目的还能节省大量的运维成本,可谓一箭三雕。
回到我们实际的业务场景,大部分情况下业务申请预算都是按照全年需求的总量申请quota,实际交付后需要较长的时间才能将资源的使用率提升上来,这样就导致很大一部分quota的价值没有发挥出来,闲置在那,其他人也不起来,因此我们要实现quota的动态分配,实现资源全局最优。
4.2 Quota Resize
下面介绍下基于quota resize的优化模型,它会针对使用率低的存量账号进行动态的缩容,增量需求不再一次性分配,而是初始少量,根据实际使用情况逐步分配。
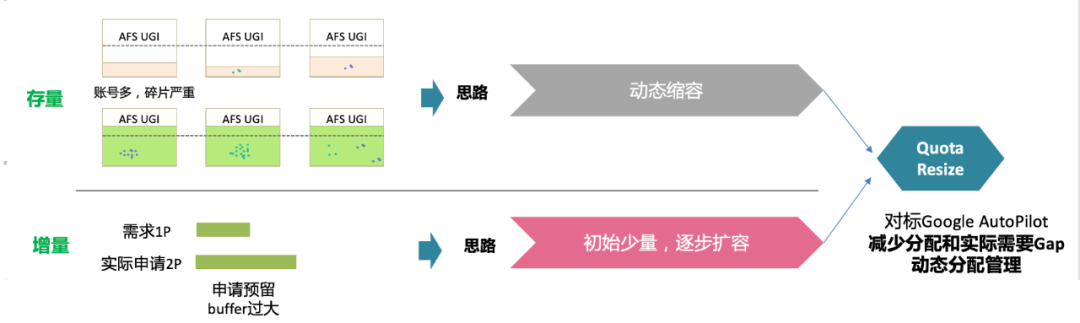
△quota resize简版方案
下面介绍下resize的整体流程,首先是收口增量需求,所有的需求申请通过平台流程中心进行,例如申请1P先初始化300T,容量管理服务会根据实时的资源使用水位结合滑动窗口通过集团云的升降配接口进行动态扩缩,核心的技术点是分钟级感知资源水位,和buffer池的预留设计以及基于滑动窗口的阶梯缩容机制。
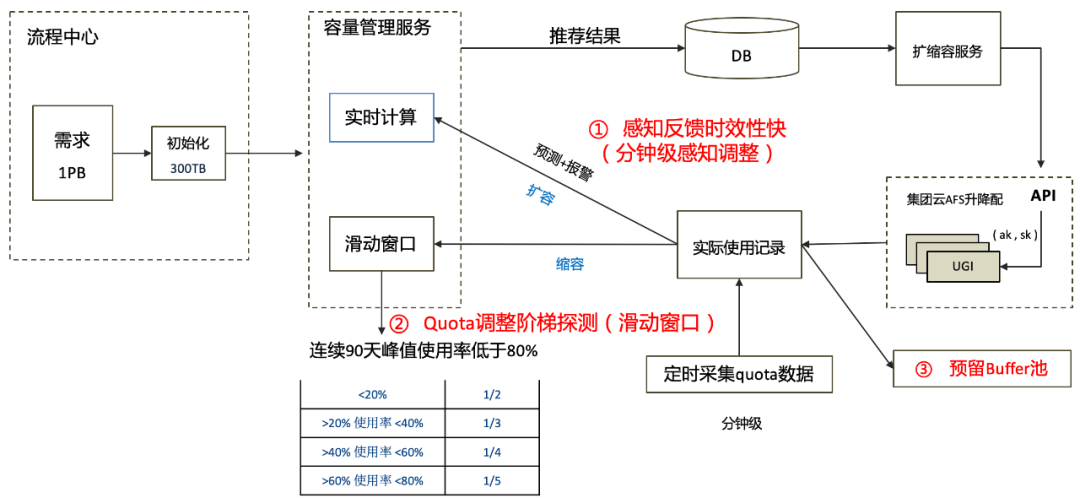
△afs quota resize流程架构
总结下resize项目的效果,首先是EB级存储的使用率从63%提升到78%,成本降低数千万,同时使用率方面与业界持平,此外资源的交付效率也大幅提升。
05 总结
本文主要介绍了百度MEG离线大数据计算和分布式文件存储的治理及优化思路,取得了阶段性的优化效果,业务覆盖方面目前覆盖了MEG超过80%的离线资源,优化使得每年计算成本降低约4000万,存储成本降低约3000万,降本的同时很好的支撑了增量不断的业务需求。离线资源的治理是个长期持久的工作,需要不断优化不断挖掘新的方式,技术方面也需要不断创新,后续会持续更新分享优化经验。
——END——
推荐阅读:
百度APP iOS端包体积50M优化实践(三) 资源优化
代码级质量技术之基本框架介绍
基于openfaas托管脚本的实践
百度工程师移动开发避坑指南——Swift语言篇
百度工程师移动开发避坑指南——内存泄漏篇
增强型语言模型——走向通用智能的道路?
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
