
前言
春天到了大地都复苏了,沉寂了很久的cpu也开始慢慢复苏了,所谓前人埋坑后人填坑,伴随着阿里云监控报警,线上CPU使用率暴增,于是就开始了排查之路。

出现问题现象
由于服务的cpu暴增到达一定程度,导致服务假死,接口调用全部返回502不可用,链接超时导致服务器方面无法给予正常的反应。
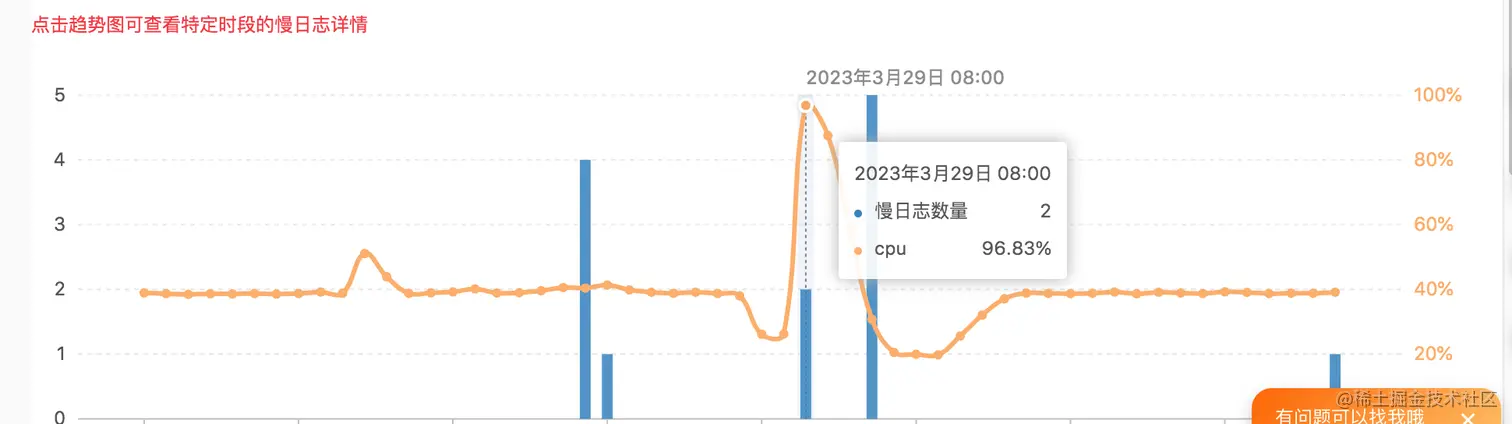
通过查看阿里云数据库RDS,慢sql日志进行分析,发现数据库的CPU使用率在某一时间到达了96%,这不完犊子了。
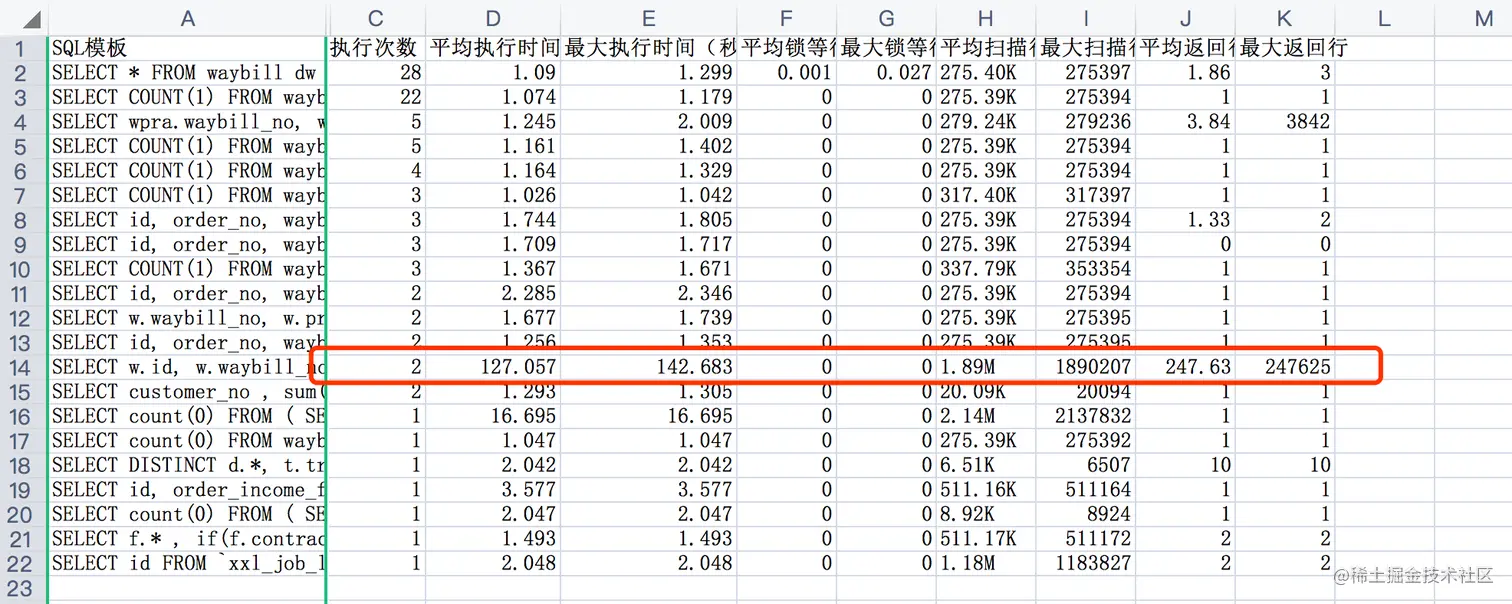
导出监控平台分析的慢sql,看到这个sql平均的执行时间,真的是再次刷新了我的认知,平均执行法时间2分多钟,这怕是执行的黄花菜都要凉了。
问题排查
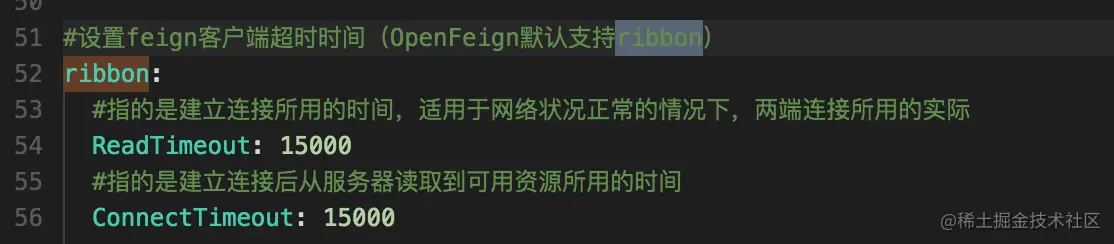
首先根据阿里云分析的慢sql进行再次分析,sql肯定是有问题的,而导致服务不可用的原因还需要看微服务的负载配置,于是我去查看了该服务Nacos的配置。这里我们看到该服务Ribbon超时时间为15妙,就意味着接口如果执行超过这个时间接口就无法继续执行,从而出现服务假死不可用的现象。
服务接口调用长时间没有反应,ribbon负载均衡会触发熔断机制,对服务进行保护,让服务不可调用。
涉及接口
通过慢sql对应到问题接口,对接口逻辑进行梳理,排查接口涉及到的sql。
通过对业务逻辑分析,发现这个接口对慢sql执行了两次,一次是正常分页查询数据,第二次是没有加分页参数,那么将全表查询,对查询的结果根据字段进行过滤,过滤出count条数。


其次是发现前端对这个接口进行两次调用,咱也不知道为什么,但是在请求上看来,访问该页面同一接口确实进行两次调用,本来接口就很慢了,这简直就是一个暴击。

慢sql分析
因为动态sql比较长,我只挑选我认为sql不是很合适的地方
查询列中用select嵌套查询

- sql中出现大量字段in的查询
In是走索引的查询,但是当in括号里面的条件比较多的情况下,就是传入的参数这个list列表长度比较大的情况下,是不走索引的,会进行全表扫描,in最终走不走索引其实是跟后面的数据有关系的。
表中数据量
主表大概在25w多数据,关联表比较大在170w数据。
主表索引加了很多,未必就是一件好事,索引的设置完全按照搜索条件来设置也未必对,涉及到关联表一定要添加索引。
关联表出现了很多重复数据,因为不了解之前业务的逻辑,不太清楚为什么出现很多重复数据,这也是表中数据量很大的原因,从而导致影响查询效率。
接口优化
既然现在问题找到了,就可以进行优化了,我说下我优化的思路,主要是从下往上进行优化。
慢sql优化,主要是针对嵌套查询改为left join 左外联查询,减少了in查询,查询出来的数据在代码中进行筛选,减少了一些不必要的索引。

通过conut()统计需要的条数,在所有count里面,count()是效率最高的了,有兴趣的朋友可以去了解下。

- 业务代码方面,限制了时间筛选的区间,从原来的不限时间勾选范围,跟业务进行沟通后,调整为只允许选择一周的时间范围进行查询,前后端都进行限制。

优化结果对比
由此可见优化后的执行效率还是比较高的,线上服务也没有在报警了,但是还有其他服务在报警…. 还有磁盘使用率到达90%…. Wtf真的是优化之路途漫漫啊。


总结
此次对于接口的优化点还不是很深,主要点是对代码、sql、业务进行优化,还未涉及到分表、加入缓存热点数据进行预热、修改负载均衡超时时间等…
其实偶尔的填坑也是一种学习的方式,不说了继续填坑了,哦!不对优化代码了~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
