
前言
之前遇到过一个由MySQL间隙锁引发线上sql执行超时的场景,记录一下。
背景说明
分布式事务消息表:业务上使用消息表的方式,依赖本地事务,实现了一套分布式事务方案
消息表名:mq_messages
数据量:3000多万
索引:create_time 和 status
status:有两个值,1 和 2, 其中99%以上的状态都是2,表示分布式事务全部已经执行完成,可以删除。
消息表处理逻辑:
1. 启动一个独立的定时任务,删除status=2的历史数据,具体的sql如下:
delete from mq_messages where create_time2. 定时任务执行频率:3分钟跑一次任务,一个任务执行200次 删除。这个条件基本上筛选出了90%以上的数据
业务逻辑:线上业务在执行时,不断的往表里插入status=1的数据,主键id随着时间是递增的
sql超时产生的场景
一次大型促销活动流量峰值的时候,出现了一次数据库连接被打满的情况,初步定位是数据量太大了导致锁表导致的。为了防止数据库连接被再次打满,需要尽快的删除状态为2的数据,手动执行定时任务,删除数据,具体sql为:
delete from mq_messages where status=2 limit 2000
三分钟执行一次任务,一个任务执行200次删除。
然后,数据库连接马上被打满,数据库挂了。
复盘分析
线上是否存在表锁?
初始化表结构(简化后的表结构)
CREATE TABLE `my_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) NOT NULL,
`b` int(11) NOT NULL,
`state` int(11) NOT NULL DEFAULT '1',
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `state` (`state`) USING BTREE
)
ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
存储过程准备测试数据
DELIMITER $$
CREATE PROCEDURE pro_copy_date()
BEGIN
SET @i=1;
WHILE @i验证
1. 数据基本情况
表中一共有10万条数据,只有后10条的state=1(id>99990)
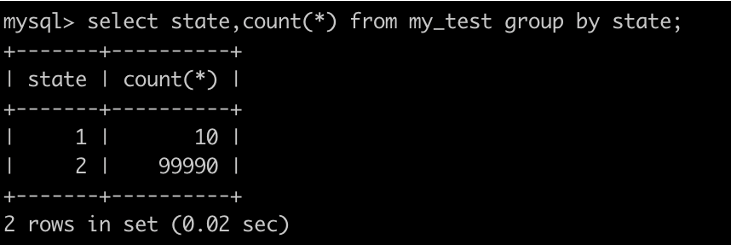
2. 事务隔离级别可重复读
3. 开启一个事务A,并且不提交
执行 DELETE FROM my_test WHERE state =2 LIMIT 2000;
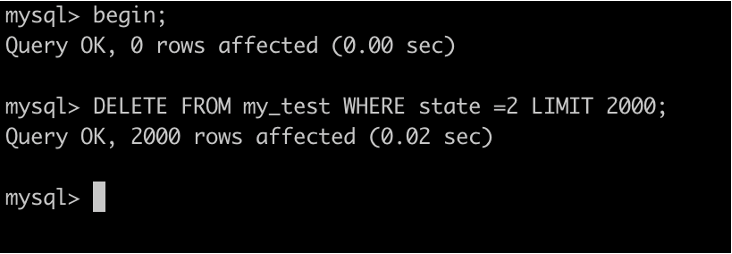
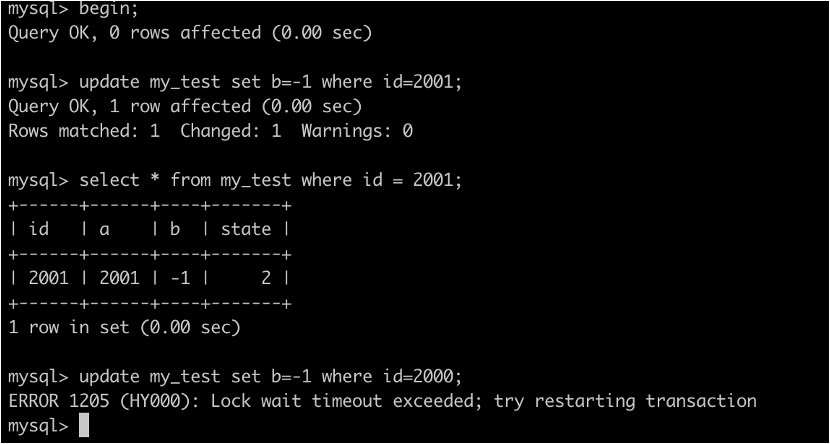
4. 开启另一个事务B
• 更新id=2001的数据,可以更新成功
• 更新id=2000的数据,被阻塞
• 说明没有表锁
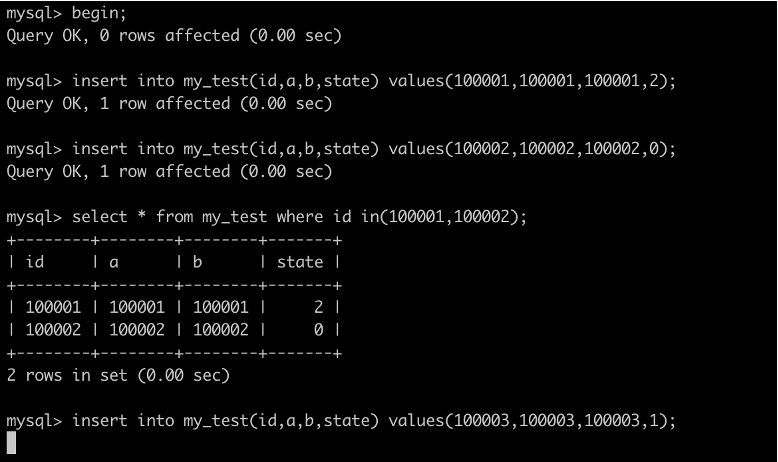
5. 开启另一个事务C
• 插入状态为2的数据,可以插入成功
• 插入状态为0的数据,可以插入成功
• 插入状态为1的数据,被阻塞
• 说明state的1和2的间隙被锁导致不能插入
结论
线上不存在表锁,而是间隙锁。
间隙锁
线上间隙锁场景分析
表中state一共两个值1和2。因此会产生三个间隙 (-∞, 1), (1, 2), (2, +∞) 和两个孤值1和2。根据前开后闭原则,对应的临建锁区间为 (-∞, 1], (1, 2],(2, +∞)
执行DELETE FROM my_test WHERE state =2 LIMIT 2000时,扫描到的行数为(state=2, id=1)到(state=2,i d=2000)。state=2落在区间](1,2]。因此锁住的范围是(state=1,id=100000) 到 (state=2,id=2000),如图所示:
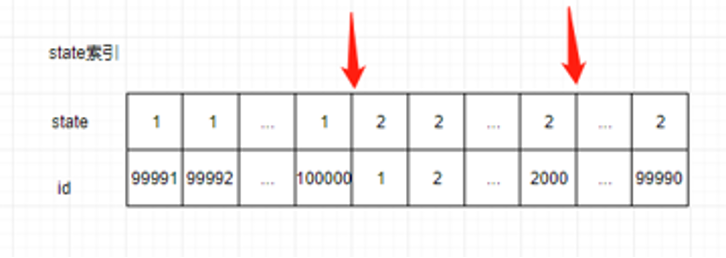
对于线上场景锁的范围是(state=1, id=status为1的最大id) 到 (state=2, id服务器托管网=要删除的记录中id的最大值)。由于线上只会插入state=1而且,id是递增的。新插入的id是表的最大值,所以新插入的记录一定会落在锁区间,所以新插入的记录都会被阻塞。
间隙锁作用
解决幻读
幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的数据行。
幻读专门指的是新插入的数据。
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。幻读在“当前读”下才会出现。innodb解决幻读的方法,间隙锁。
幻读带来的问题
新建测试表:
CREATE TABLE `my_test2` (
`id` INT (11) NOT NULL,
`b` INT (11) DEFAULT NULL,
`c` INT (11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE = INNODB;
-- 插入测试数据
NSERT INTO my_test2 VALUES(0, 0, 0),(5, 5, 5),(10, 10, 10),(15, 15, 15);
测试sql 1
begin;
select * from t where b=5 for update;
这个语句会命中 b=5 的这一行,对应的主键 id=5,因此在 select 语句执行完成后,id=5 这一行会加一个写锁,这个写锁会在执行 commit 语句的时候释放。
由于字段 b 上没有索引,因此这条查询语句会做全表扫描。那么,其他被扫描到的不满足条件的记录上,会不会被加锁呢?
假如只会在id为5的记录上加锁:
| | 事务A | 事务B | 事务C |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 where b=5 FOR UPDATE; 结果(5,5,5) | | |
| T2 | | UPDATE my_test2 SET b=5 WHERE id = 0; | |
| T3 | SELECT * FROM my_test2 where b=5 FOR UPDATE; 结果(0,5,0)(5,5,5) | | |
| T4 | | | INSERT INTO my_test2(1,5,1) |
| T5 | SELECT * FROM my_test2 where b=5 FOR UPDATE; 结果(0,5,0)(1,5,1)(5,5,5) | | |
| T6 | commit | | |
| | 事务A | 事务B |
|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 where b=5 FOR UPDATE; | |
| T2 | | UPDATE my_test2 SET b=5 WHERE id = 0; UPDATE my_test2 SET c=5 WHERE id = 0; |
| T3 | commit | |
假如只会在id为5的记录上加锁,会破坏事务A的加锁声明,即“把所有 b=5 的行锁住,不准别的事务进行读写操作”
| | 事务A | 事务B | 事务C |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 WHERE b=5 FOR UPDATE; UPDATE my_test2 SET c=10 WHERE b=5; | | |
| T2 | | UPDATE my_test2 SET b=5 WHERE id = 0; | |
| T3 | | | INSERT INTO my_test2(1,5,1) |
| T4 | commit | | |
T1时刻: id=5的这行数据,的c的值改成了10,事务还没提交,binlog还没写
T2时刻:id=0 这一行变成 (0,5,0), 变更写入binlog;
T3时刻:id=1 这一行变成 (1,5,1), 变更写入binlog;
T4时刻:事务A提交,写入binlog。
此时主库的数据为(0,5,0),(1,5,1),(5,5,10)
因此binlog写入的日志为:
UPDATE my_test2 SET b=5 WHERE id = 0;
INSERT INTO my_test2(1,5,1)
UPDATE my_test2 SET c=10 WHERE b=5;
从库执行完成binglog后数据就变成了(0,5,10),(1,5,10),(5,5,10),因此出现了数据的不一致
出现数据不一致的原因,是只锁了那一刻需要变更的行,并不能阻挡现有数据变成b=5。
如果把扫描到的行全部加锁会如何哪?由于b没有索引,索引得扫描全表才知道那一行需要更新,所以表中的每一条记录都会被锁住。
| | 事务A | 事务B | 事务C |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 where b=5 FOR UPDATE; UPDATE my_test2 SET c=10 WHERE b=5; | | |
| T2 | | UPDATE my_test2 SET b=5 WHERE id = 0; (block) | |
| T3 | | | INSERT INTO my_test2(1,5,1) |
| T4 | commit | | |
T1时刻: id=5的这行数据,的c的值改成了10,事务还没提交,binlog还没写
T2时刻:id为0的行被锁住,不能更新,等待锁释放;
T3时刻:id=1 这一行变成 (1,5,1), 变更写入binlog;
T4时刻:事务A提交,写入binlog。
T5时刻:事务A已提交,id=0的锁被释放,事务B更新成功,变成 (0,5,0),写入binlog
此时主库的数据为(0,5,0),(1,5,1),(5,5,10)
因此binlog写入的日志为:
INSERT INTO my_test2(1,5,1)
UPDATE my_test2 SET c=10 WHERE b=5;
UPDATE my_test2 SET b=5 WHERE id = 0;
从库执行完成binglog后数服务器托管网据就变成了(0,5,0),(1,5,10),(5,5,10),因此还是存在数据不一致
锁定了查找过程中扫描的行,有效的避免了修改带来的数据不一致问题。数据之间的间隙插入的数据依然会出现b=5的数据,因此要向解决这个问题我们还需在数据的间隙加锁。
| | 事务A | 事务B | 事务C |
|---|---|---|---|
| T1 | BEGIN; SELECT * FROM my_test2 b=5 FOR UPDATE; UPDATE my_test2 SET c=10 WHERE b=5; | | |
| T2 | | UPDATE my_test2 SET b=5 WHERE id = 0; (block) | |
| T3 | | | INSERT INTO my_test2(1,5,1) (block) |
| T4 | commit | | |
T1时刻: id=5的这行数据,的c的值改成了10,事务还没提交,binlog还没写
T2时刻:id为0的行被锁住,不能更新等待锁释放;
T3时刻:间隙(0,5)被锁住,不能插入等待锁释放;
T4时刻:事务A提交,写入binlog。
T5时刻:事务A已提交,id=0的锁被释放,事务B更新成功,变成 (0,5,0),写入binlog
T6时刻:事务A已提交,(0,5)的间隙锁被释放,事务C写入成功,变成 (1,5,1),写入binlog
此时主库的数据为(0,5,0),(1,5,1),(5,5,10)
因此binlog写入的日志为:
UPDATE my_test2 SET c=10 WHERE b=5;
UPDATE my_test2 SET b=5 WHERE id = 0;
INSERT INTO my_test2(1,5,1)
从库执行完成binglog后数据就变成了(0,5,0),(1,5,1),(5,5,10),完美解决了数据不一致
通过上面两个情况分析,如果只锁对应修改的行,会出现两个问题
1. 破坏加锁声明
2. 数据的不一致性
幻读的解决方法
通过上面案例分析,即使把所有的记录都加上锁,还是阻止不了新插入的记录。行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。
间隙锁,锁的就是两个值之间的空隙,表中一共有4条数据,因此会产生五个间隙 (-∞, 0), (0, 5), (5, 10), (10, 15), (15, +∞),在扫描确认要修改的行时,不仅仅要锁住扫描到的行,两边的间隙也要加上锁。
间隙锁和行锁合称 next-key lock(邻键锁),每个 next-key lock 是前开后闭区间。因此上述情况会有五个邻键锁(-∞,0],(0,5],(5,10],(10,15],(15, +∞)
间隙锁可以被多个事务同时加
间隙锁和行锁有区别,行锁只能被一个事务加上,但是间隙锁可以被多个事务加上。
如下图:开启两个事务,
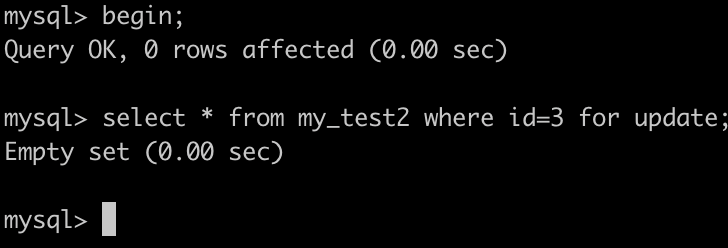
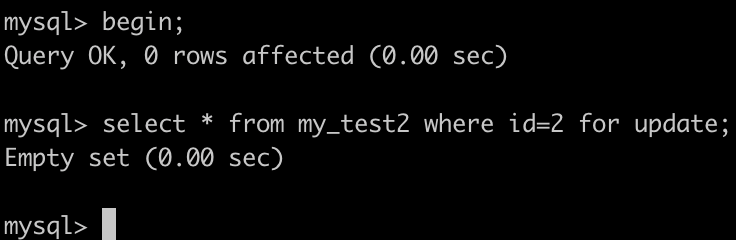
1. 事务A执行:SELECT * FROM my_test2 WHERE id=2 for UPDATE; 会锁住(0,5)这个间隙。
2. 事务B执行SELECT * FROM my_test2 WHERE id=3 for UPDATE;,同样也会锁住(0,5)这个间隙,而且可以成功。
间隙锁的目前是保护这个间隙不能插入数据,但他们不冲突。
加锁规则
原则1:加锁的基本单位是 next-key lock,next-key lock 是前开后闭区间。
原则2:查找过程中访问到的对象才会加锁。
优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
唯一索引上的范围查询会访问到不满足条件的第一个值为止
加锁规则—等值查询间隙锁
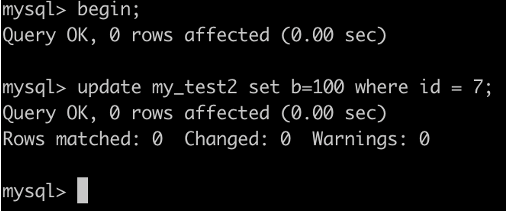
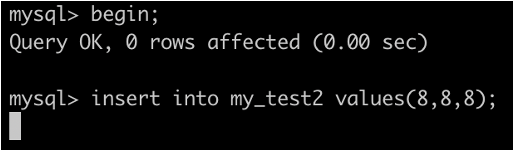
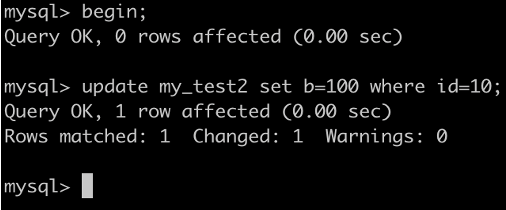
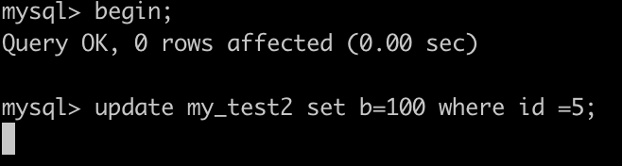
事务A执行UPDATE my_test2 SET b=100 WHERE id =7;
根据原则1,加锁的区间应该为(5,10].
根据优化2,这是一个等值查询 ,而 id=10 不满足查询条件,next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10)。
因此:事务B的插入会被阻塞,事务C的更新可以成功
事务A:
事务B:
事务C:
加锁规则—非唯一索引等值查询
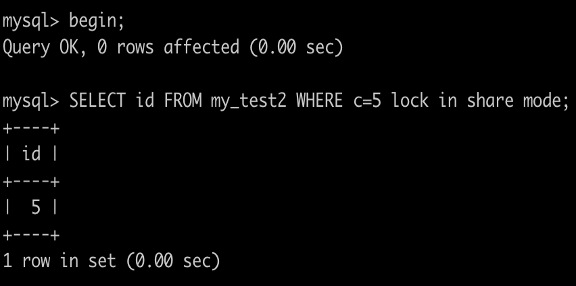
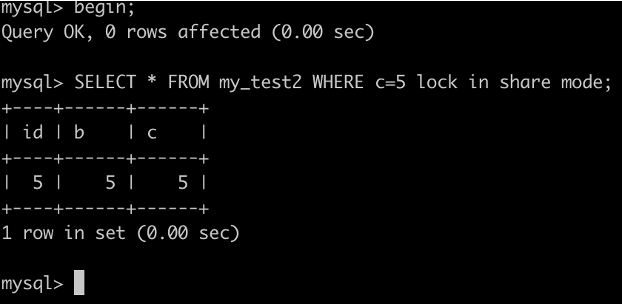
事务A执行SELECT id FROM my_test2 WHERE c=5 lock in share mode``;
根据原则1,加锁的区间应该为(0,5],由于c不是唯一索引还得往后扫描,因此(5,10]也会被加锁。根据优化2,会退化成(5,10)。因此索引c上的锁区间为(0,10)。
由于这个查询走的是索引覆盖,并不需要去主键索引查数据,因此id=5的行并不会被锁住 。
所以更新会成功,插入不会成功
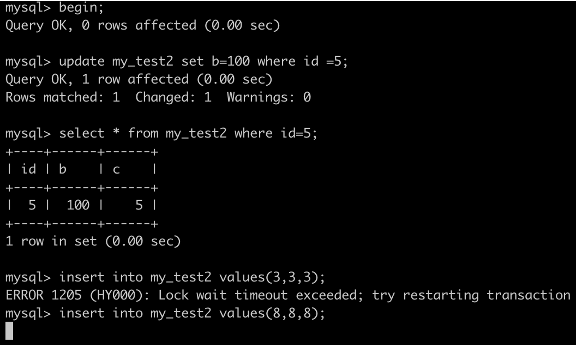
事务A执行SELECT * FROM my_test2 WHERE c=5 lock in share mode;
由于 查询全部的数据就需要,去主键索引上查找id=5的数据,根据原则2,id=5的这行数据也要被锁住,因此更新会被阻塞。
注意,如果执行的语句为SELECT id FROM my_test2 WHERE c=5 for UPDATE;虽然这个语句也会走索引覆盖,但是用for update mysql会认为你接下来要更新这行,因此顺便会给id=5的这行加锁。
加锁规则—非唯一索引,存在等值
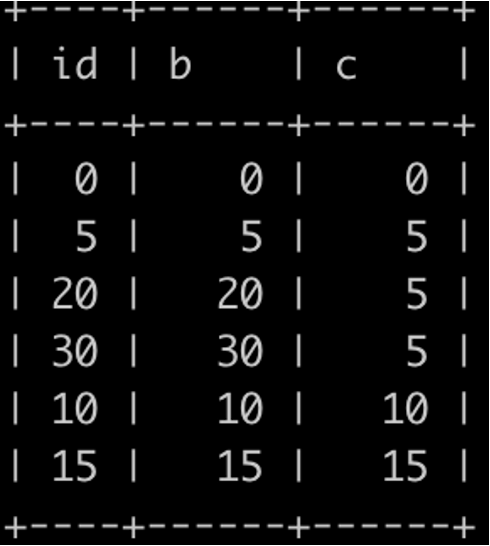
新插入两条数数据(20,20,5)和(30,30,5)
执行sql: DELETE FROM my_test2 WHERE c=5 LIMIT 2;
根据加锁原则,只会扫描c=5的数据,因此加锁区间为
(c=0,id=0) 到 (c=5,id=20)
INSERT INTO my_test2 VALUES(-1,0,0); //不阻塞
INSERT INTO my_test2 VALUES(1,0,0); //阻塞
INSERT INTO my_test2 VALUES(19,0,5); //阻塞
INSERT INTO my_test2 VALUES(21,0,5); //不阻塞
执行结果验证:
数据库底层实现博大精深,本文所述,根据线上场景进行了一些研究和探讨,希望能为相关场景提供一些启示。文章中难免会有不足之处,希望读者能给予宝贵的意见和建议。谢谢!
作者:京东物流 刘浩
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
