
文章目录
-
- 1. 目标检测算法分类
- 2. 区域卷积神经网络
-
- 2.1 R-CNN
- 2.2 Fast R-CNN
- 2.3 Faster R-CNN
- 2.4 Mask R-CNN
- 2.5 速度和精度比较
- 3. 单发多框检测(SSD)
- 4. YOLO
1. 目标检测算法分类
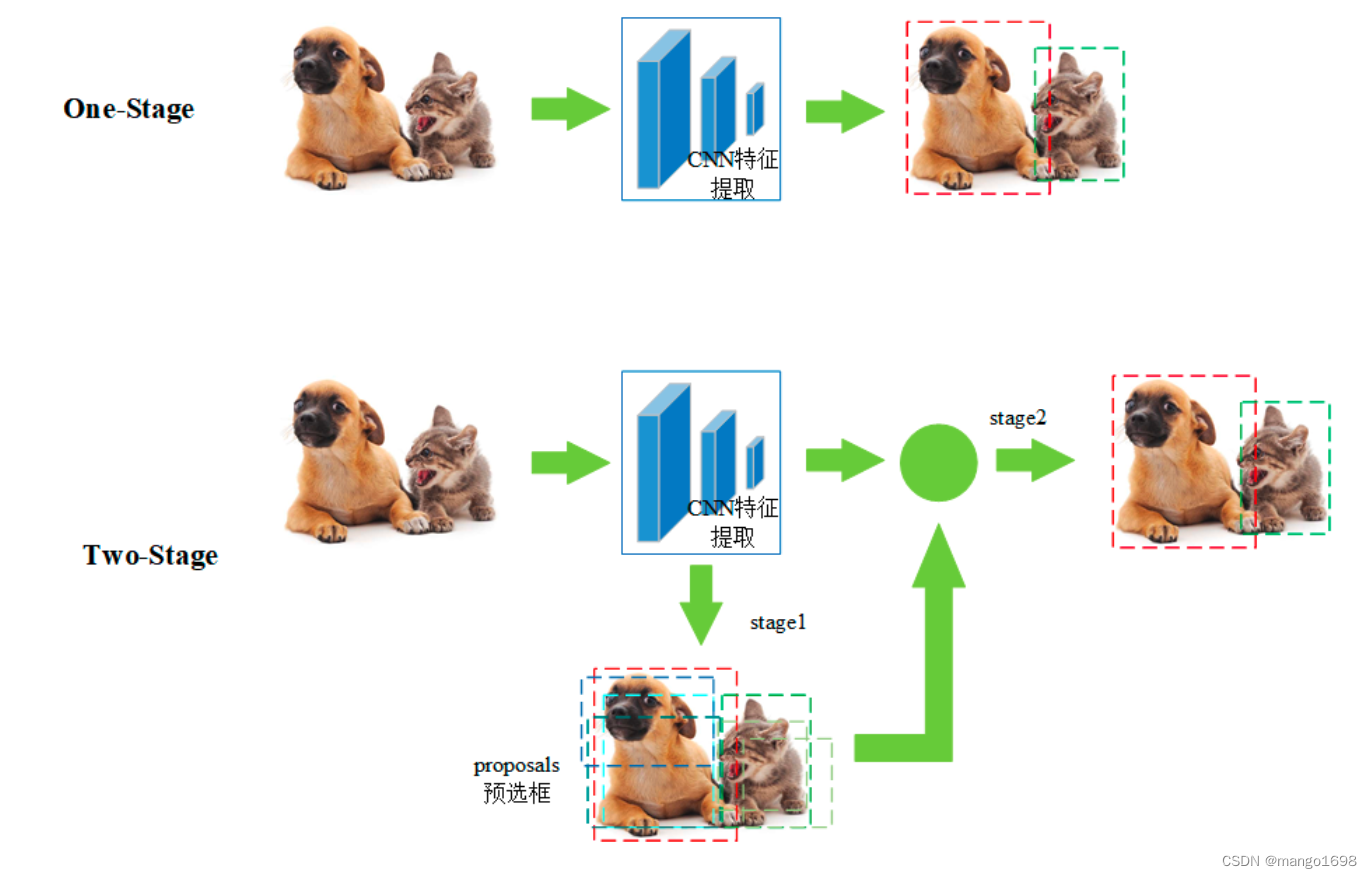
目标检测算法主要分两类:One-Stage与Two-Stage。One-Stage与Two-Stage是两种不同的思路,其各有各的优缺点。
One-Stage
主要思路:直接通过卷积神经网络提取特征,预测目标的分类与定位;
Two-Stage
主要思路:先进行区域生成,即生成候选区域(Region Proposal),在通过卷积神经网络预测目标的分类与定位;
优缺点
| 优缺点 | One-Stage | Two-Stage |
|---|---|---|
| 优点 | 速度快;避免背景错误产生false positives; 学到物体的泛化特征 | 精度高(定位、检出率);Anchor机制;共享计算量 |
| 缺点 | 精度低(定位、检出率);小物体的检测效果不好 | 速度慢;训练时间长;误报相对高 |
从目前看,在移动端一般使用 One-Stage算法。现在很难说,精度和准确率的问题,因为影响因素不仅仅取决于算法,还跟数据集大小、图像标注质量、训练参数等有很大的关系。
主要算法
One-Stage:YOLO系列(v1-v8),SSD系列(R-SSD、DSSD、FSSD等),Retina-Net,DetectNet,SqueezeDet。
Two-Stage:RCNN系列(Fast-RCNN、Faster-RCNN、Mask-RCNN),SPPNet,R-FCN。
2. 区域卷积神经网络
2.1 R-CNN
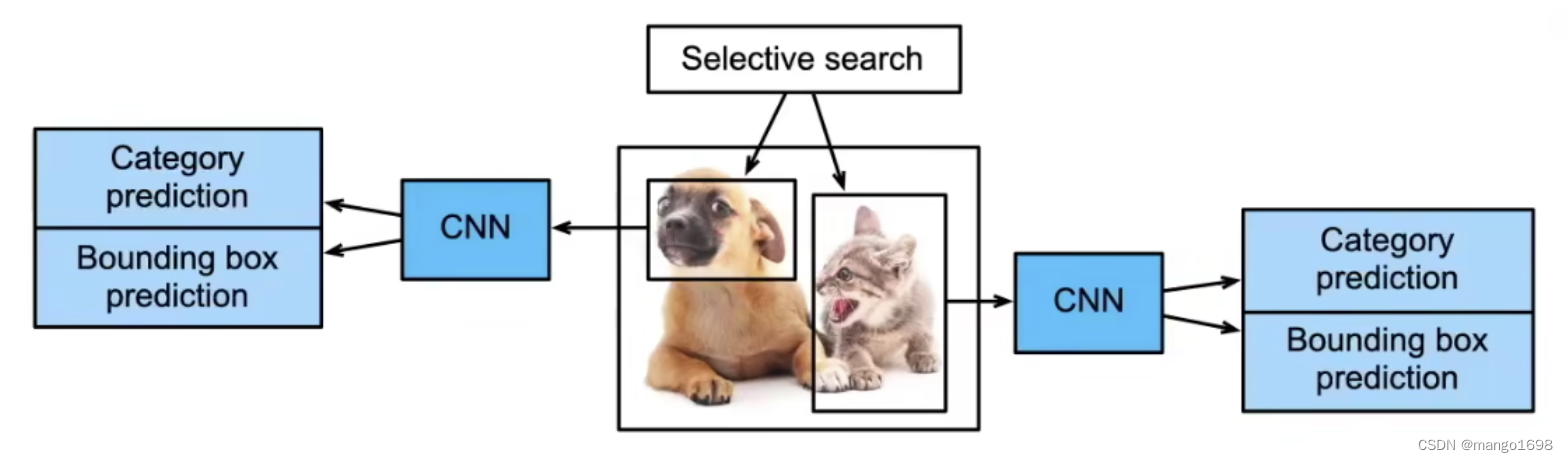
使用启发式搜索算法来选择锚框。
使用预训练模型来对每个锚框抽取特征。
训练一个SVM来对类别分类。
训练一个线性回归模型来预测边缘偏移框。
当锚框每次选择的大小不同,我们如何使这些锚框称为一个batch呢?
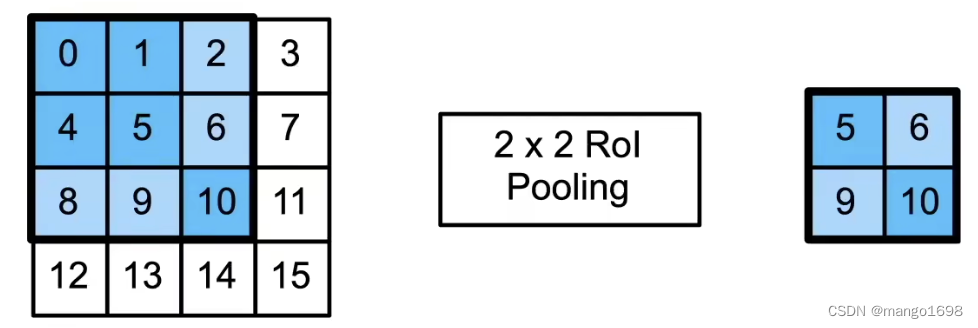
兴趣区域(ROI)池化层
ROI Pooling
- 给定一个锚框,均匀分割成
n
m
ntimes m
nm块,输出每块里的最大值 - 不管锚框多大,总是输出
n
m
nm
nm个值
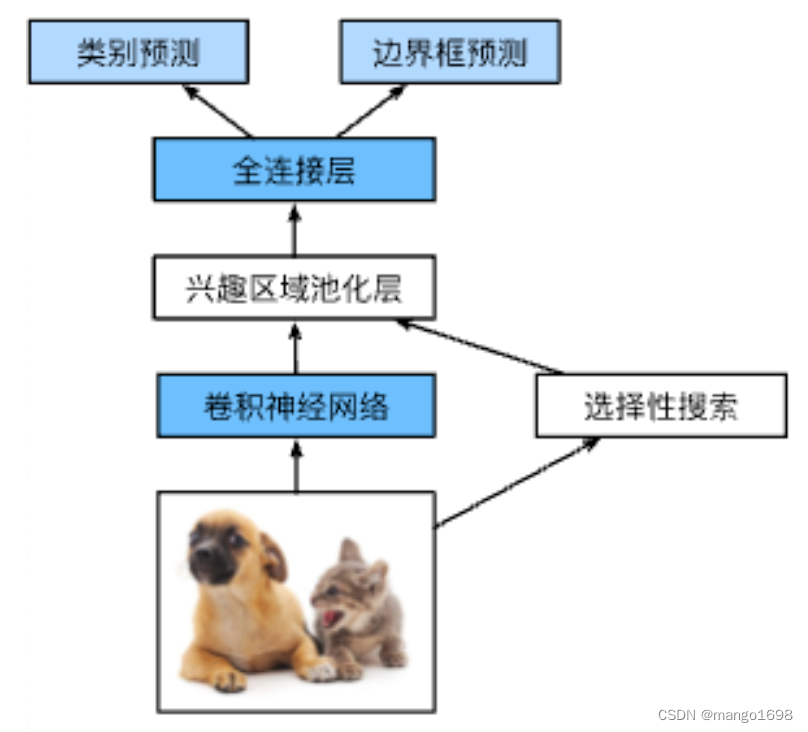
2.2 Fast R-CNN
对图片整体抽取特征。
- 不再对每一个锚框做CNN的特征抽取,而是对图片整体使用CNN进行特征抽取
- 使用RoI池化层对每个锚框生成固定长度特征
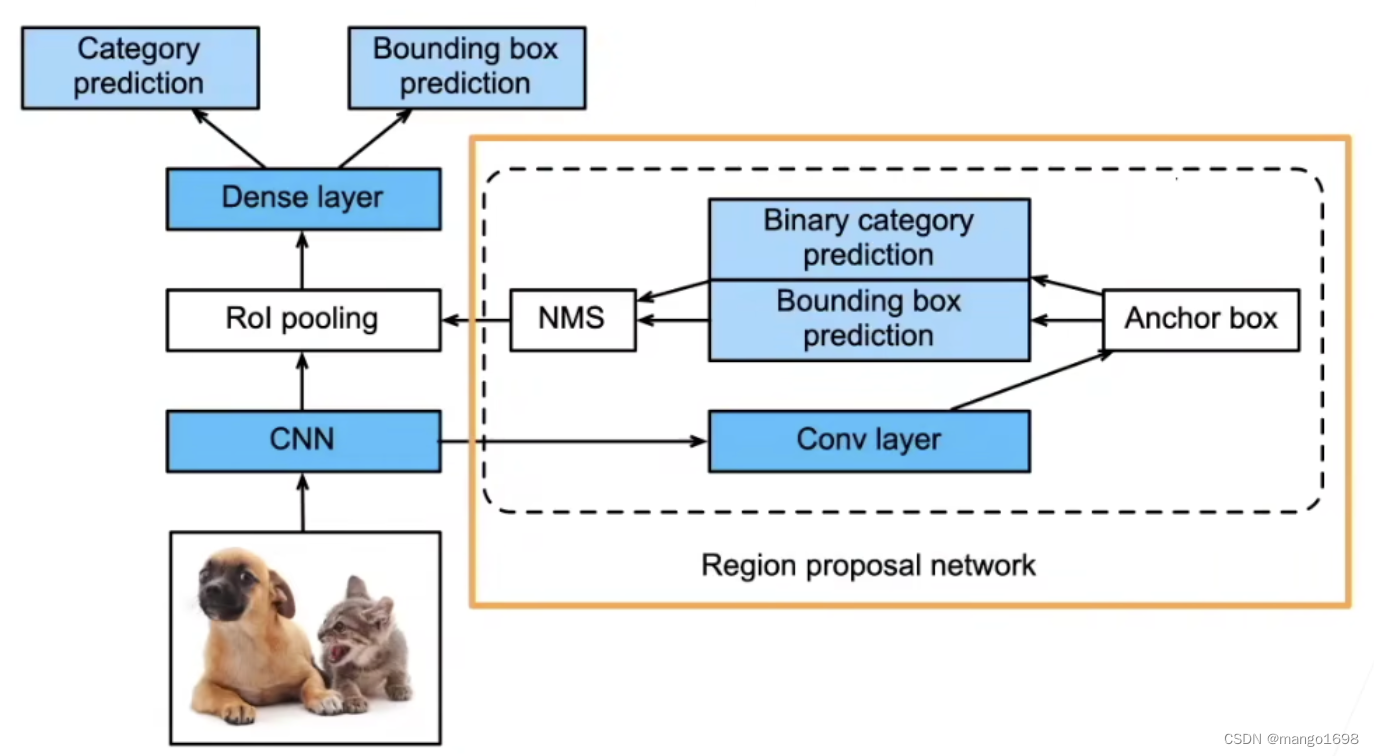
2.3 Faster R-CNN
- 使用一个区域提议网络来代替启发式搜索,来获得更好的锚框。
2.4 Mask R-CNN
- 如果有像素级别的标号,使用FCN来利用这些信息
- 在无人车领域运用较多
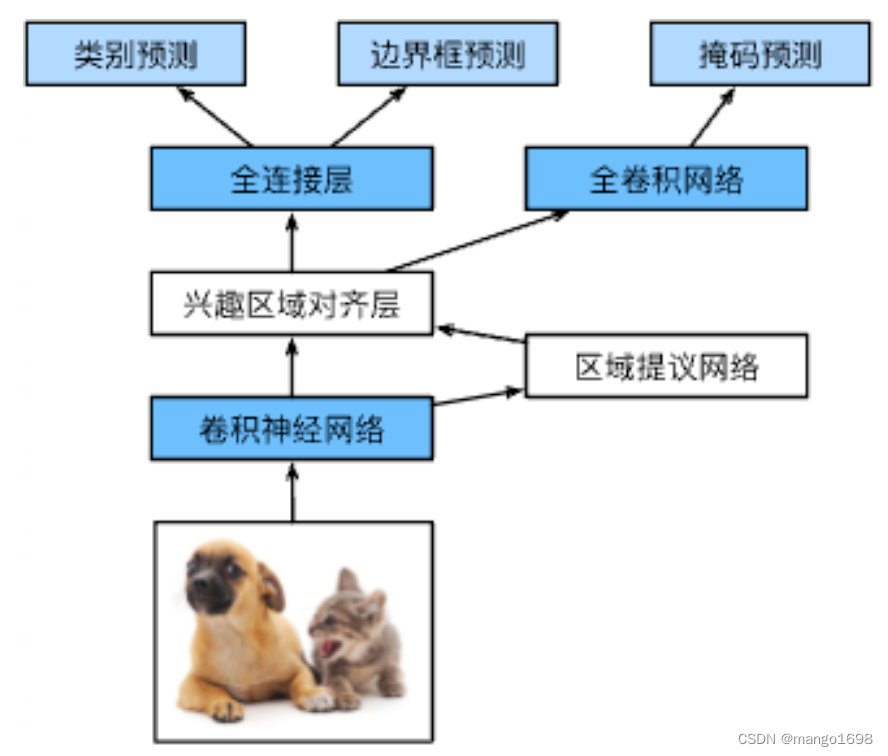
在做像素级别预测时,边界位置不要发生太多的错位。
2.5 速度和精度比较

总结:
- R-CNN是最早、也是最有名的一类基于锚框和CNN的目标检测算法
- Fast/Faster R-CNN持续提升性能
- Faster R-CNN和Mask R-CNN是在最求高精度场景下的常用算法
3. 单发多框检测(SSD)
SSD全称Single Shot Multibox Detector,是一种单阶段目标检测器。其优点是原始的YOLO和Faster R-CNN在推理速度和精度之间取得了更好的平衡。SSD模型是由Wei Liu等人在使用卷积神经网络(CNN)进行目标检测的研究中,提出的一种改进思路。
SSD用于图像分类、物体检测和语义分割等各种深度学习任务。相对于其他目标检测算法,SSD模型有更高的精度,而且速度也是非常快的。其主要思路是通过在CNN的最后几层添加多个预测层实现多尺度的目标检测,然后通过一个过滤策略对每个检测框进行筛选,最后输出最终的检测结果。
生成锚框
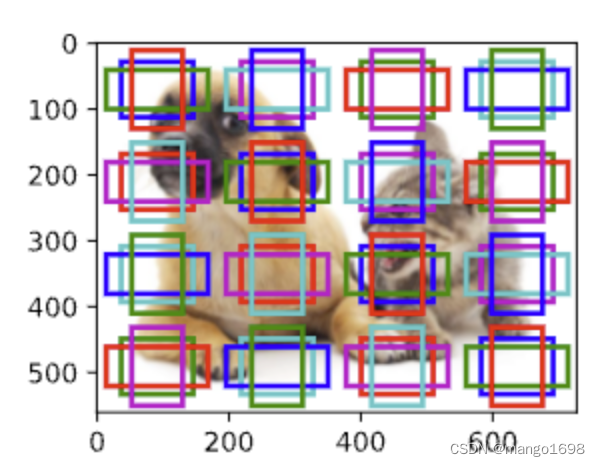
- 对每个像素,生成多个以它为中心的锚框
- 给定n个大小为
s
1
,
s
2
,
.
.
.
,
s
n
s_1,s_2,…,s_n
s1,s2,…,sn和m
m
m个高宽比,那么生成n
+
m
−
1
n+m-1
n+m−1锚框,其大小和高宽比分别为:
(
s
1
,
r
1
)
,
(
s
2
,
r
1
)
,
.
.
.
,
(
s
n
,
r
1
)
,
(
s
1
,
r
2
)
,
.
.
.
,
(
s
1
,
r
m
)
(s_1,r_1),(s_2,r_1),…,(s_n,r_1),(s_1,r_2),…,(s_1,r_m)
(s1,r1),(s2,r1),…,(sn,r1),(s1,r2),…,(s1,rm)
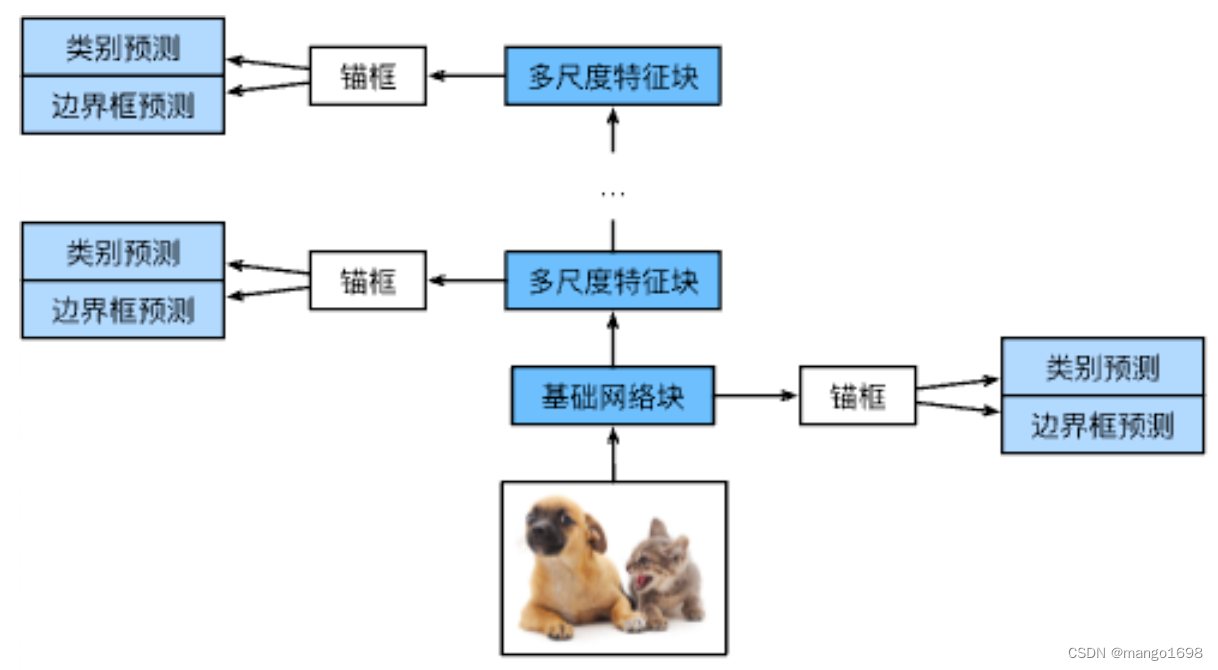
SSD模型
- 一个基础网络来抽取特征,然后多个卷积层块来减半高宽
- 在每段都生成锚框
- 底部段来拟合小物体,顶部短来集合大物体
- 对每个锚框预测类别和边缘框
总结:
- SSD通过单神经网络来检测模型
- 以每个像素为中心的产生多个锚框
- 在多个段段输出上进行多尺度的检测
4. YOLO
You Only Look Once
YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位的回归问题结合起来,从而做到了高效、灵活和泛化性能好,所以在工业界也十分受欢迎。
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。
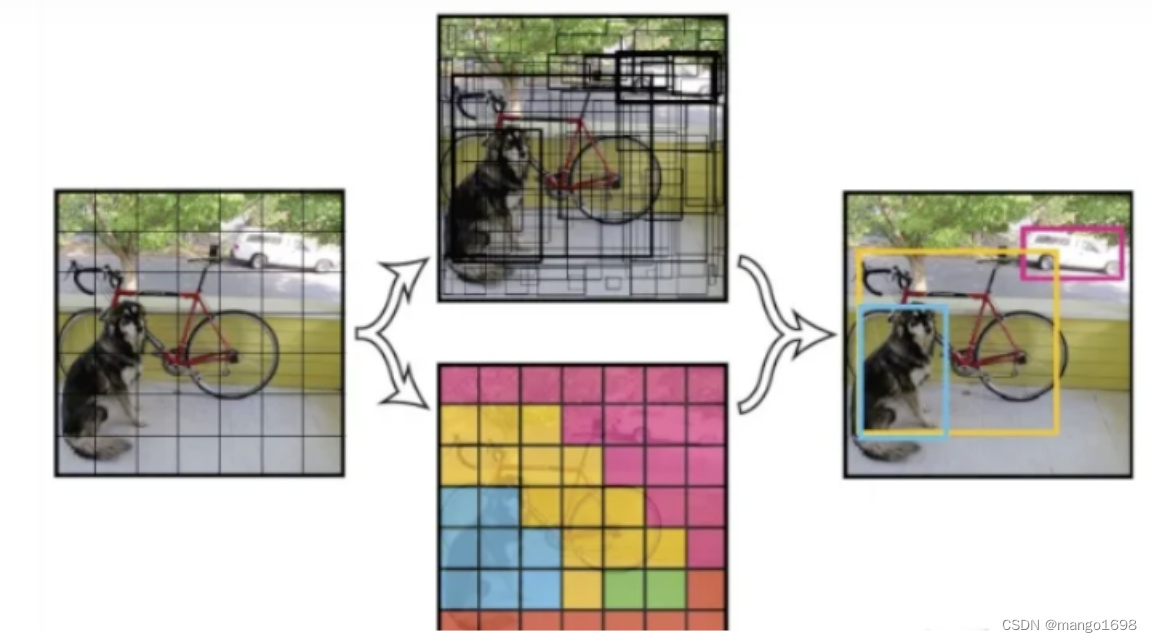
yolo尽量让锚框不重叠。
- SSD中锚框大量重叠,因此浪费了很多计算
- yolo将图片均匀分成
服务器托管网
SS
Stimes S
SS个锚框 - 每个锚框预测
B
B
B个边缘框 - 后续版本(V2,V3,V4…)有持续改进
YOLO家族进化史(V1-V8)
- YOLOv1
- YOLOv2:对YOLOv1进行改进
- YOLOv3:对YOLOv2进行改进
- YOLOv4:对YOLOv3进行改进
- YOLOv5:对YOLOv4进行改进
- YOLOx:以YOLOv3作为基础网络进行改进
- YOLOv6:由美团推出,更加适应GPU设备,算法思路类似YOLOv5(backbone+neck)+YOLOX(head)
- YOLOv7:是YOLOv4团队的续作,检测算法与YOLOv4,v5类似
- YOLOv8:是YOLOv5团队进一步开发的
服务器托管,北京服务器托管,服务器租服务器托管网用 http://www.fwqtg.net
