

导读:Curve 是一款高性能、易运维、云原生的开源分布式存储系统(CNCF Sandbox)。可应用于主流的云原生基础设施平台:对接 OpenStack 平台为云主机提供高性能块存储服务;对接 Kubernetes 为其提供 RWO、RWX 等类型的持久化存储卷;对接 PolarFS 作为云原生数据服务器托管网库的高性能存储底座,完美支持云原生数据库的存算分离架构。
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。本文将介绍Curve块存储相关的部分,并分享Curve在一些场景的应用。
全文目录:
1.分布式存储介绍
2.Curve架构及介绍
3.Curve主要亮点
4.Curve RoadMap
5. 问答环节
01分布式存储介绍
1.分布式存储的分类
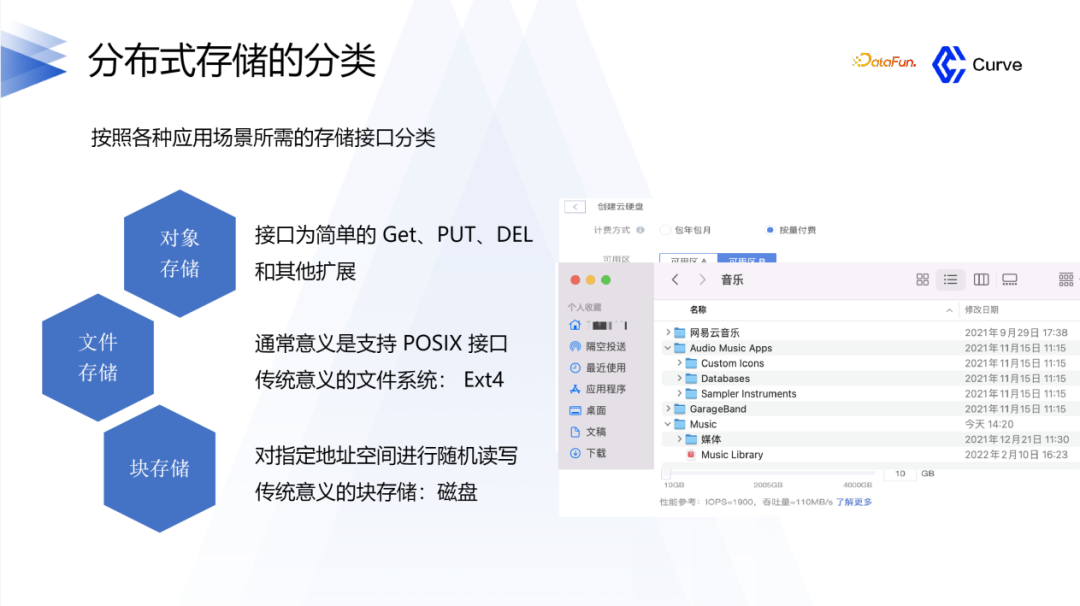
首先简单介绍一下分布式存储的分类。分布式存储可以分为三类:对象存储、文件存储和块存储。对象存储在互联网中应用的比较多,比如一个对象、一个图片、一个音频,这种可以通过PUT GET接口来进行存储。文件存储与传统意义的文件系统的区别是,它是分布式的,传统的项目对应的是Ext4,或者是NTFS。块存储,就是所谓的云盘。
2. 分布式存储的要素
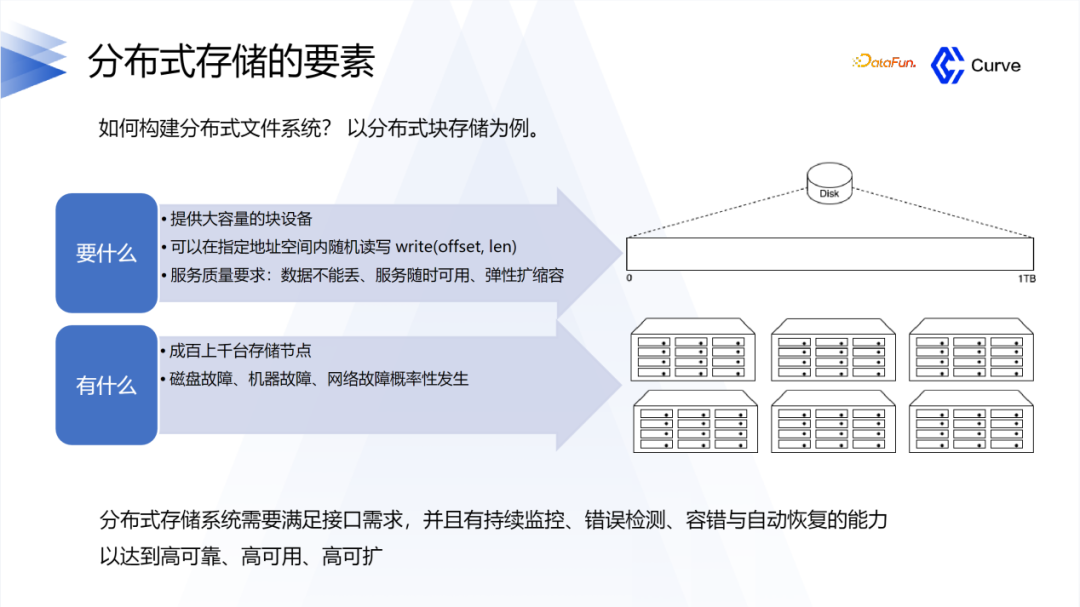
下面介绍一下分布式存储在设计时的一些要素。首先,需要大容量的硬盘空间,并且可以随机写,还有最重要的是要保证服务的质量,数据不能丢失,还要保证它的可用性。
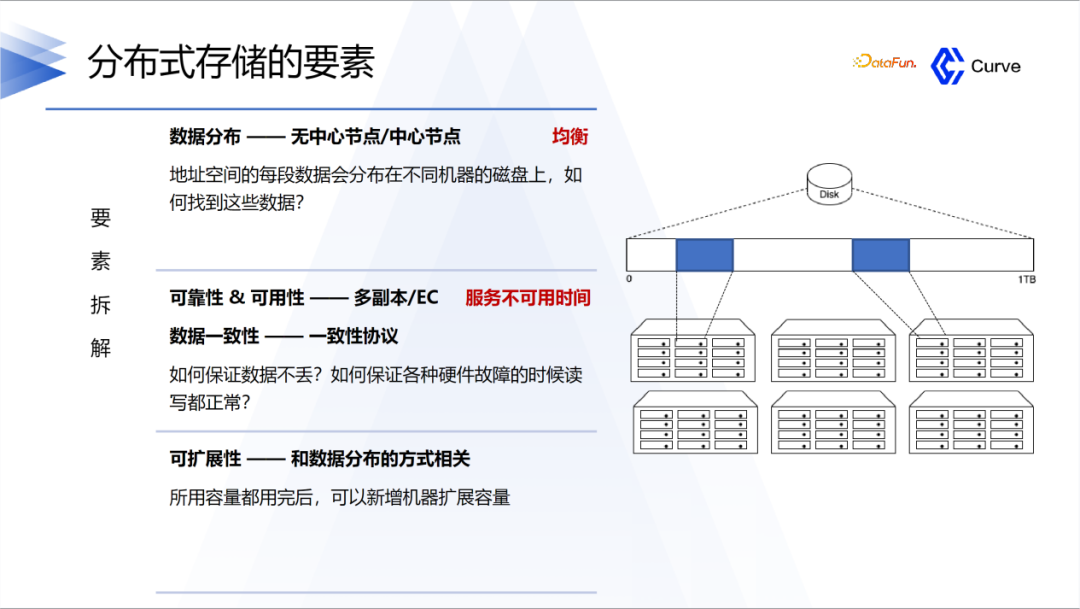
要素可以拆解为以下三方面:
①第一是高性能。在分布存储里面,存储节点会非常多,所以要知道数据存在什么位置以及如何去取。
②第二是可用性。要保证数据的可靠性,避免数据丢失,并且保证在机器故障时数据的读写是能够正常运行的。
③第三是可扩展性。如果容量用完了,可以新增机器扩展容量。
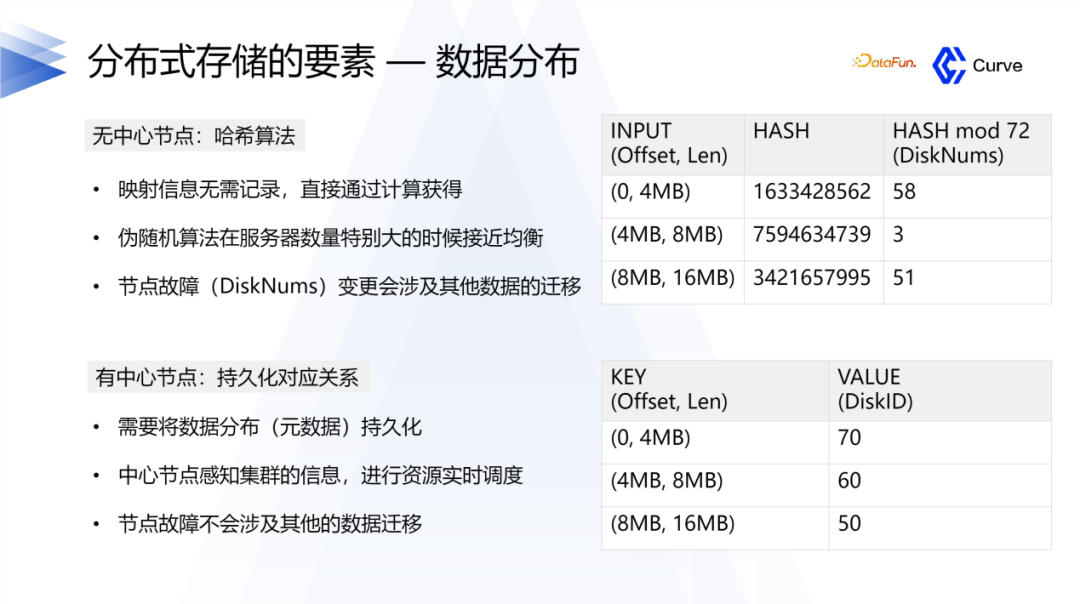
数据分布,主要有两种,一个是无中心节点,另一个是有中心节点。
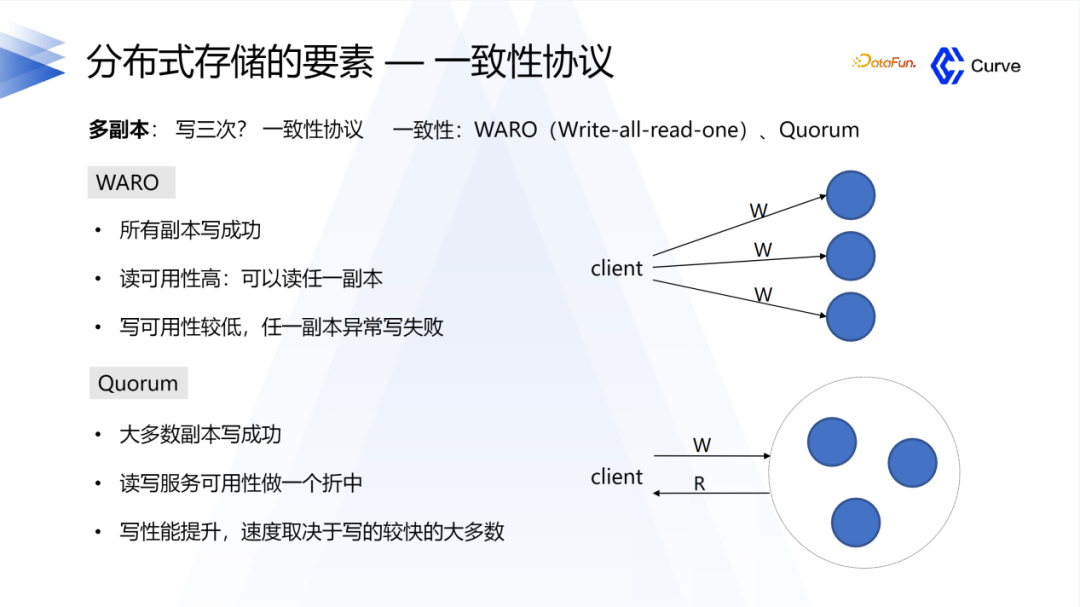
另外一个比较重要的点是一致性协议。首先是Ceph的强一致性。在分布式系统中,一致性是指在多个副本之间保持数据一致。在RADOS中,数据被分割成多个对象,每个对象都有多个副本,这些副本分布在集群的不同节点上。当一个对象被修改时,Ceph会确保所有的副本都被同时更新,从而保证了强一致性。第二是Raft算法,他只需要大多数副本保证更新完成就可以认为成功了。
02Curve架构及介绍
1. 项目介绍
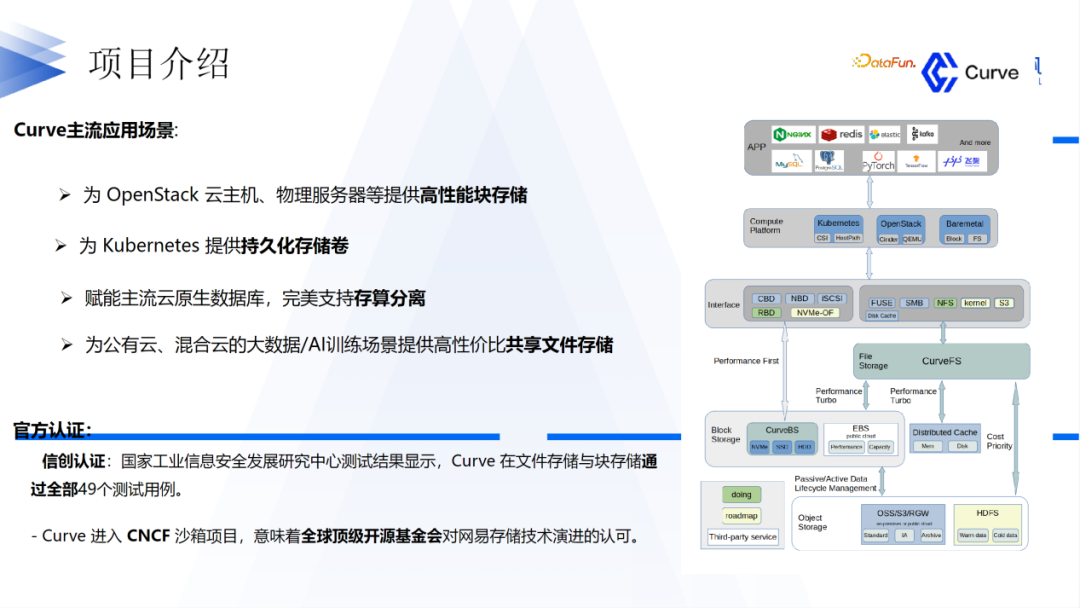
关于Curve,我们的愿景是希望打造一款性能比较好,适用多种场景的,并且是围绕开源的云原生分布式存储系统。目前,Curve已经捐赠给CNCF基金会,并成为其生态系统中的一个项目。Curve提供块存储和文件存储两种方式,以满足不同应用的需求。
对于Curve块存储,它具有快照克隆恢复功能,主要应用场景包括OpenStack云主机和Kubernetes持久存储卷。对于共享需求,Curve提供文件存储;对于性能要求较高且无共享需求的场景,建议使用Curve块存储。
Curve还与阿里巴巴的PolarDB进行了联合,作为其底层存储运行。此外,Curve也在AI训练领域得到了广泛应用。Curve在过去几年中通过了信创认证,并获得了工信部组织的中国开源创新大赛二等奖。
2. Curve的架构介绍
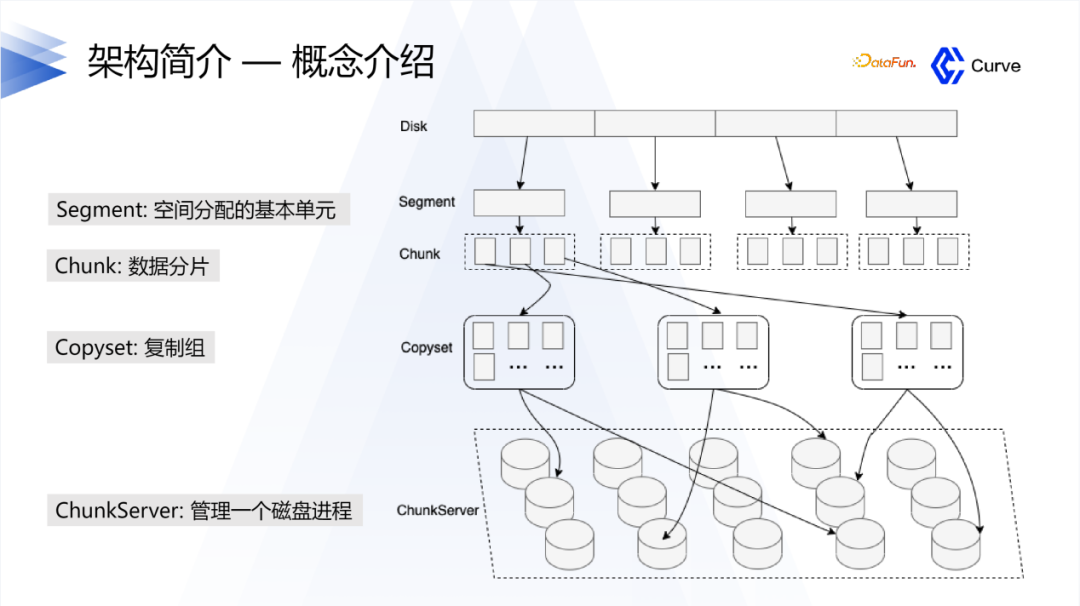
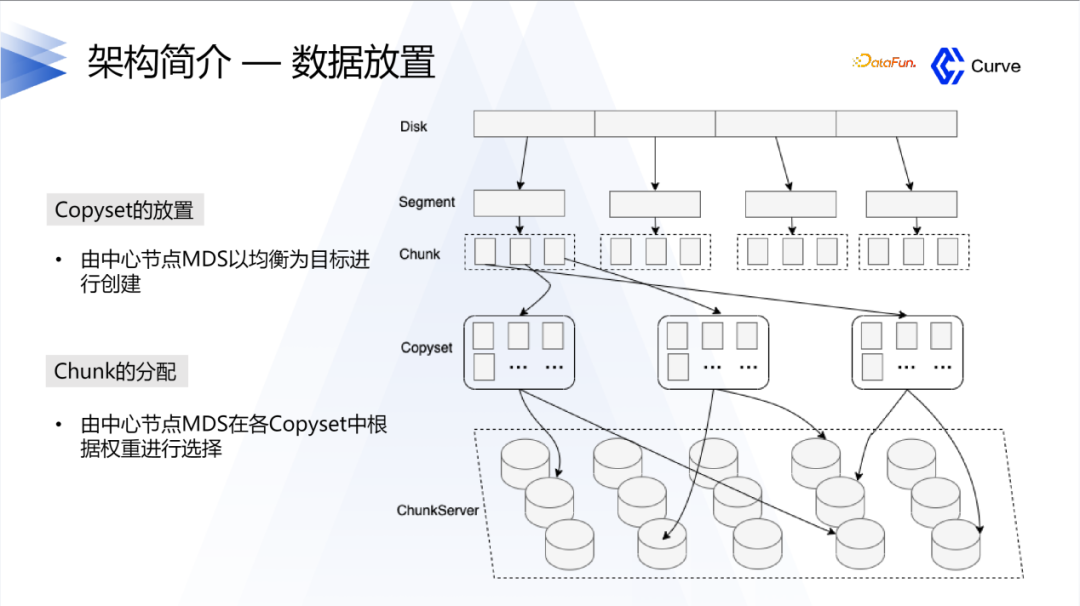
Curve的整体架构是以硬盘为单位进行空间分配,每个硬盘被划分为多个segment,而每个segment又包含多个chunk。引入segment的概念是为了减少原数据的量。类似于Ceph中的一个硬盘对应一个节点,Curve中的一个硬盘对应一个服务组件,由一个磁盘进程进行管理。
Curve采用了Raft协议作为其一致性协议的选择。这是因为Curve项目的背景与我们在网易的实际业务需求有关。在网易的业务中,之前大部分业务使用的是Ceph。然而,在使用Ceph过程中,一旦用户更换硬盘或某个机器发生故障,会导致业务出现卡顿,这是业务方无法接受的。因此,这促使我们进行Curve的研发。基于这个背景,我们选择了Raft协议。
选择Raft协议的原因有两个方面:一是Raft协议具有较高的可用性,相对于Ceph的强一致性模型,在集群中出现一些问题时,可用性不会受到太大影响。另一个原因是Raft协议相对较容易理解。
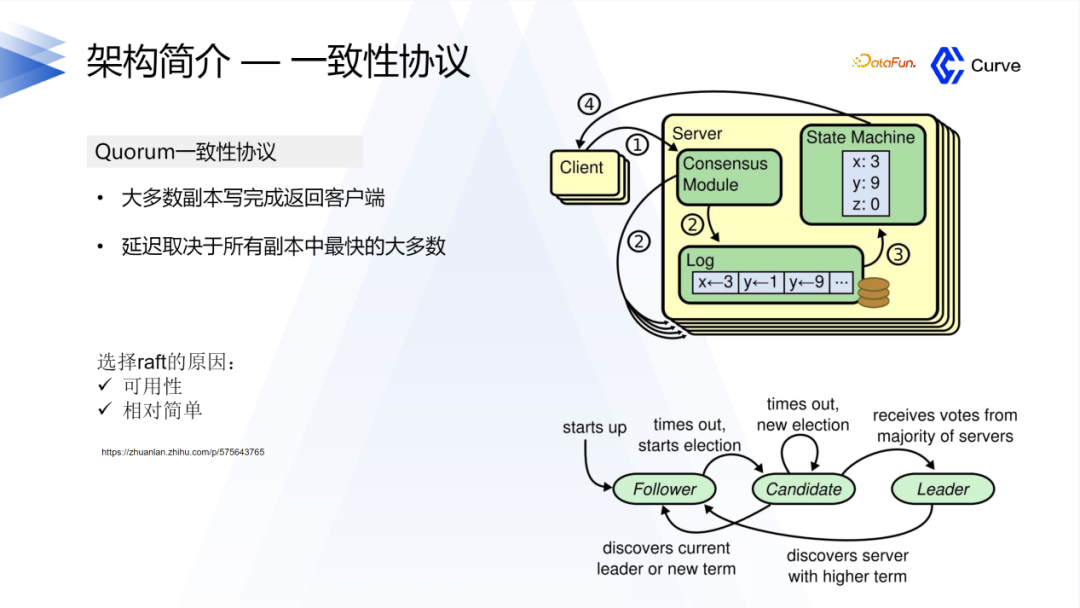
在Curve的开发过程中,我们希望能够快速迭代,并避免重复开发组件。为了实现这一目标,我们选择了百度的Braft和brpc这两个被广泛认可为优秀的组件作为底层基础。我们在这两个组件的基础上也进行了一系列的开发工作。
03Curve的主要亮点
Curve的主要亮点是以下四个方面:
下面将逐一展开介绍。
1. 高性能
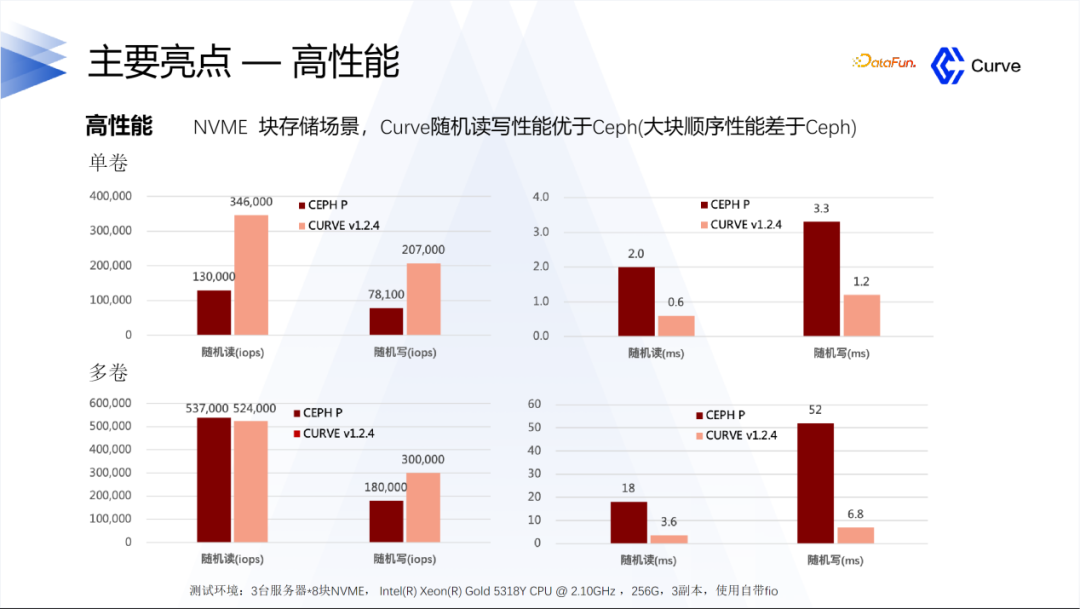
Curve在随机读写方面表现优于Ceph。然而,我们也要承认目前存在一个问题:在大块顺序读写方面,Curve的性能差于于Ceph。我们正在进行后续的优化工作,以改进这方面的性能表现。
在性能方面,我们的目标是支持云原生数据库,因为云原生数据库对性能要求较高。除了支持阿里巴巴的PolarDB数据库,我们还支持网易内部的其他数据库。我们致力于提供高性能的存储解决方案,以满足不同数据库的需求。
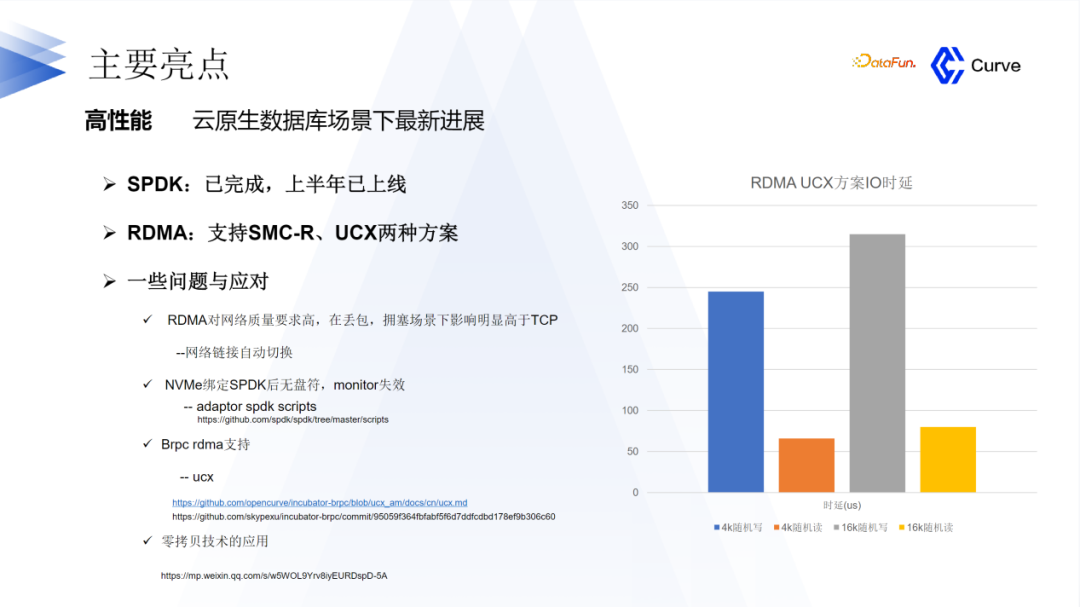
在数据库方面,我们引入了SPDK(Storage Performance Development Kit)和RDMA(Remote Direct Memory Access)技术。这两种技术已经在2023年上半年上线。然而,在实施过程中,我们也面临了一些问题和挑战。以下是一些典型的例子:
-
RDMA对网络质量要求较高。当用户的网络质量较差时,可能会出现丢包或拥塞现象,而这对性能的影响明显高于TCP。为了解决这个问题,我们实现了网络链路的自动切换机制。当用户的网络质量较差时,系统会自动切换到TCP来应对这个问题。
-
在将NVMe绑定到SPDK后,它将没有盘符。然而,缺少盘符会导致线上监控失效。对于一个存储系统来说,缺乏监控是不可接受的。为了解决这个问题,我们利用SPDK提供的一系列脚本进行了内部适配,以确保监控的正常运行。这些问题和挑战是我们在引入SPDK和RDMA技术时所面临的,我们正在努力解决它们,以提供更稳定和可靠的存储解决方案。
-
第三个挑战是关于Brpc的RDMA支持。在当时,Brpc的RDMA功能并不完善。因此,我们对Brpc的RDMA进行了支持。由于RDMA支持是一个较为常见的技术,我们对Brpc的RDMA进行了文档介绍和代码方面的比较。如果您对此感兴趣,欢迎加入我们的微信群进行学习和交流。
-
第四个挑战是关于零拷贝技术。在引入SPDK后,我们希望引入零拷贝技术。然而,零拷贝技术在实施过程中有很多要求。因此,我们对这项技术进行了一些探索和研究。最终,我们成功实现了零拷贝技术,并且我们的技术和性能得到了显著提升。

在混合存储方面,我们利用了bcache来实现。为什么要采用混合存储呢?因为使用NVMe或者SSD可能会在性能和成本方面遇到一些瓶颈。因此,我们希望能够利用HDD作为数据盘,类似于Ceph中的HDD,而利用高性能存储设备来提升低速磁盘的IO性能。为了实现这一目标,我们采用了bcache技术。
bcache技术在我们的架构中起到了重要作用。在最初的设计中,我们使用了一个NVMe硬盘和几块数据盘。然而,如果NVMe硬盘发生故障,那么整个数据盘的数据都会丢失。为了解决这个问题,我们采用了raid技术,以提供冗余备份。此外,我们还对bcache进行了优化。在优化过程中,我们遇到了一些问题,例如发现bcache的writeback机制会失效,即使写入的数据量未达到阈值。最终,我们发现这是一个bug,并进行了修复。有关这个bug的详细记录可以在上面图片的链接中找到。
在处理bcache Gc的影响方面,我们也进行了一些工作。例如,我们采取了分离的策略,将WAL单独放置在NVMe设备中,而不放在bcache Gc的范围内。通过这样的方式,我们能够减少bcache Gc对系统性能的影响。
第三个问题也是非常重要的,尽管在最初的测试中可能不容易发现,但我们花了相当长的时间来定位它。我们发现在测试集群性能时,重复测试可能导致性能下降。最终的定位结果表明,这实际上是由于NVMe硬盘本身存在的问题。在持续写入的情况下,NVMe硬盘的性能可能会下降。这与硬盘的SAD和OP空间有关。通过适当设置OP空间,可以提升硬盘的性能。
此外,我们还了解到三星的企业级硬盘可能存在一些问题,例如固件支持方面。有关这方面的详细记录可以在下面图片的参考链接中找到。如果您对此感兴趣,欢迎参考相关文档。

在高性能方面,我们仍然有许多工作要做。正如之前提到的,我们的随机读写性能要比Ceph好得多,但在顺序读写方面则差于Ceph。因此,我们将重点优化顺序读写性能,这是我们后续工作的重点之一。
另一个重要工作是本地快照的支持。目前,我们的快照功能将快照上传到S3存储。然而,对于一些用户来说,他们对数据的安全性要求更高,可能没有使用S3存储。因此,我们非常关注本地快照的支持,以满足这些用户的需求(本地快照功能已经开发完成,预计Q4可release)。
还有其它一些计划,可以查看相关的road map以获取更多信息。
2. 易运维

Curve是一个易运维的存储系统。即使对于不熟悉Curve的人来说,根据我们的文档,只需要花费十几分钟的时间就能够将Curve部署起来。除了部署易用性方面,我们还支持在Kubernetes云原生环境中进行部署。我们提供了类似于Operator的解决方案,使得Curve的部署和运维更加简单。目前,我们已经支持了基本的部署易用性,例如Operator,但还有一些高级功能,如自动升级,尚未完全实现,我们将在后续继续努力。
3. 更稳定
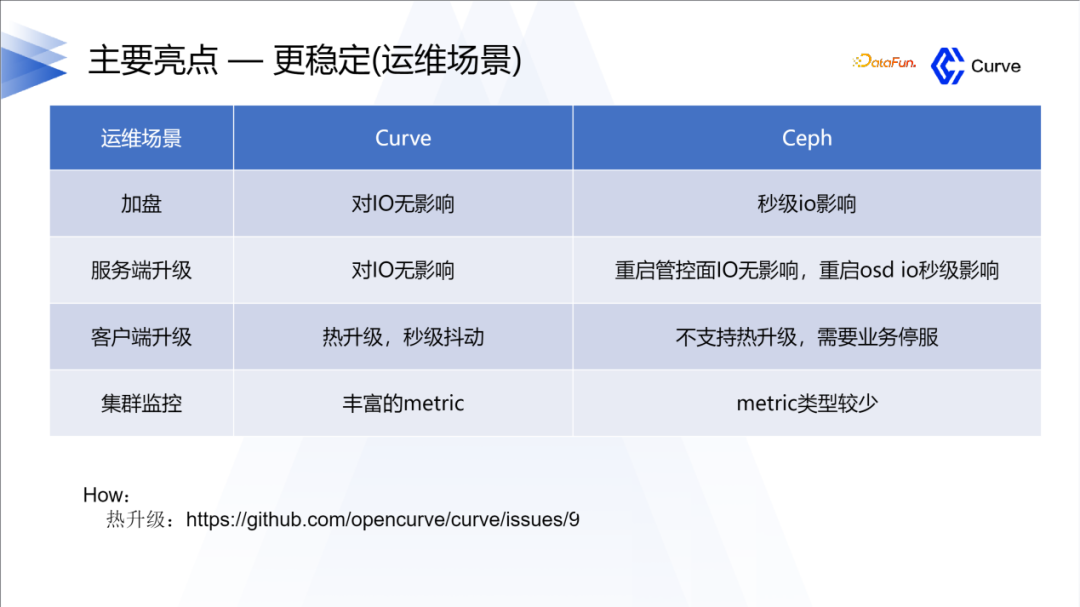
Curve在稳定性方面具有显著优势。正如之前提到的,我们选择开发Curve的原因之一就是为了提高系统的稳定性,这也是我们从Ceph中获得的经验。此外,热升级也是Curve的一个亮点。关于热升级的详细信息,您可以在我们的文档中找到相关介绍。
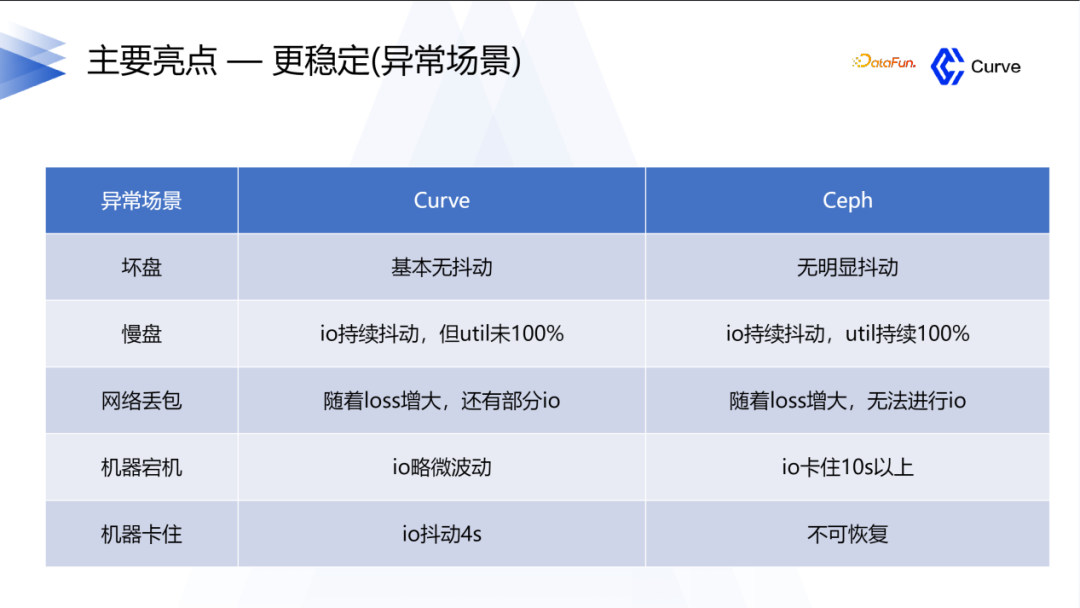
在Curve的开发过程中,我们对质量要求非常高。我们进行了单元测试、集成测试以及各种其他类型的测试,以确保系统的稳定性和可靠性。我们注重测试的全面性和多样性,以确保Curve在各种异常场景下都能表现出色。
4. 高质量
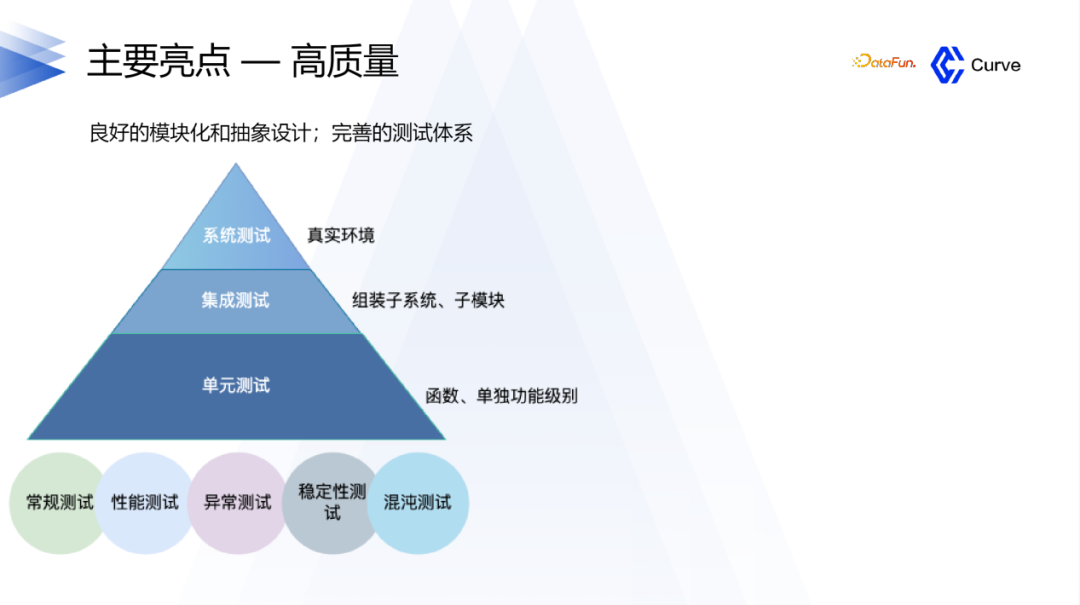
对于Curve项目,当开发者提交一个PR时,会自动触发CI流程。CI流程包括单元测试、集成测试和系统测试等多个测试环节。只有当CI流程通过并且测试通过后,PR才会被合并入代码库。这样的流程确保了代码的质量和稳定性。

在技术架构的先进性方面,简要介绍两个关键点。首先是中心化节点,它充当集群的中心,可以感知集群的负载容量和异常情况,并进行资源调度和数据均衡。其次是文件池的chunkfilepool,它通过降低文件原数据的开销来提高性能,同时也支持快照功能。目前,我们使用的是快照S3,这使得用户可以方便地与S3或其他对象存储进行对接。
04 RoadMap
最后来分享一下后续的计划。

除了CurveBS,我们还有Curve FS作为另一个重点方向。Curve BS已经在网易进行了两三年的大规模线上运行,数据非常稳定,目前主要是在进行支持一些高级特性方面的工作。而Curve FS在2022年6月份完成了第一个release版本并上线。截至目前,Curve FS的开发时间只有大约一年左右,还有很多工作要做。特别是在AI时代,我们希望Curve能够在支持AI方面做得更好,这也是我们的一个亮点。当然,除了支持Ai,我们还在开发其他场景的支持,例如ES和传统的接口,如HDFS。
05 问答环节
Q:Curve写入代码性能比Ceph低吗?
A:在性能方面,Curve在随机写方面表现比Ceph要好很多,但在顺序写方面则差于Ceph。这主要是因为Ceph在过去使用了双写的机制,导致日志和数据都需要写入两次。为了解决这个问题,Ceph后来采用了BlueStore引擎,使得大块写入时只需写入数据一次,从而减少了原数据的写入量。然而,Curve目前仍然存在日志和数据写入两份的问题,因为它使用了Raft机制。这导致了带宽的利用率不高,性能相对于Ceph较差。因此,我们的重点之一是优化Curve的顺序写性能,特别是在KBS(Kernel Block Service)方面。我们目前正在进行这方面的工作。
Q:我了解Curve,请提供CurveFS和CurveBS他们之间的区别和联系?
A:Curve FS是一个文件系统,而Curve BS是一个块存储系统。与Ceph相比,Curve有一个有趣的特点是Curve FS和Curve BS可以进行联动。这意味着Curve FS的数据既可以存储在S3中,也可以存储在Curve BS中。这是与Ceph相比的一个亮点。通过这种联动,我们可以根据性能需求直接对接Curve BS,或者根据成本需求直接对接S3。这是我们的一个亮点,为用户提供了更大的灵活性和选择性。
Q:SPD跟RDMA什么时候开源?
A:关于SPDK和RDMA,我们在GitHub上已经有一个版本可用。在上半年,我们在这方面进行了大量的工作,并且在不久前进行了上线。目前,我们正在整理相关的源代码和其他资料。预计在第四季度我们将完成整理工作并达到一个稳定的状态。
Q:Curve如何对接K8S?在这一方面做了一些什么事情?
A:Curve有一个重要亮点是易运维,我们开发了CurveAdm工具。CurveAdm工具通过容器化技术实现了部署和易运维的功能,这只是其中的一小部分。此外,我们还支持与云原生环境结合,我们已经通过Operator实现了这一功能。
—— END. ——
社区资讯:
Curve 社区上半年 Roadmap 进展及下半年规划
用户案例:
Curve 文件存储在 Elasticsearch 冷热数据存储中的应用实践
扬州万方:基于申威平台的 Curve 块存储在高性能和超融合场景下的实践
创云融达:基于 Curve 块存储的超融合场景实践
技术解析:
探索 : CurveBS 模拟 RBD 接口对接 OpenStack
Curve 安全加固:基于Kerberos的鉴权系统
CurveBS RDMA & SPDK 部署指南

-
GitHub:https://github.com/opencurve/curve
-
官网:https://opencurve.io/
-
用户论坛:https://ask.opencurve.io/
-
微信群:搜索群助手微信号 OpenCurve_bot
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
每天都是全新的一天,感谢今日努力的自己。 上一章简单介绍了外观模式(十三), 如果没有看过, 请观看上一章 一. 享元模式 引用 菜鸟教程里面的享元模式介绍: https://www.runoob.com/design-pattern/flyweight-pa…
