
面对在线推理服务使用的GPU资源不断增加、GPU利用率普遍较低的挑战,美团视觉研发团队决定通过模型结构拆分和微服务化进行优化,他们提出了一种通用高效的部署架构,来解决这种常见的性能瓶颈问题。
以“图像检测+分类”服务为例,优化后的服务压测性能指标GPU利用率由40%提升至100%,QPS也提升超过3倍。本文将会重点介绍推理服务部署架构优化的工程实践,希望对大家能有所帮助或启发。
- 0. 导读
- 1. 背景
- 2. 视觉模型服务的特点与挑战
- 2.1 模型优化工具与部署框架
- 2.2 视觉模型特点
- 2.3 视觉推理服务面临的问题与挑战
- 3. GPU服务优化实践
- 3.1 图像分类模型服务优化
- 3.2 图像“检测+分类”模型服务优化
- 4. 通用高效的推理服务部署架构
- 5. 总结与展望
0. 导读
美团视觉面向本地生活服务,在众多场景上落地应用了文字识别、图像质量评价、视频理解等视觉AI技术。此前,在线推理服务使用的GPU资源不断增加,但服务GPU利用率普遍较低,浪费大量计算资源,增加了视觉AI应用成本,这是美团也是很多企业亟需解决的问题。
美团视觉智能部通过实验分析发现,造成视觉推理服务GPU利用率低下的一个重要原因是模型结构问题:模型中预处理或者后处理部分CPU运算速度慢,导致推理主干网络无法充分发挥GPU运算性能。基于此,视觉研发团队通过模型结构拆分和微服务化,提出一种通用高效的部署架构,解决这种常见的性能瓶颈问题。
目前,该解决方案已经在多个核心服务上成功应用。以“图像检测+分类”服务为例,优化后的服务压测性能指标GPU利用率由40%提升至100%,QPS提升超过3倍。本文将会重点介绍推理服务部署架构优化的工程实践,希望对从事相关工作的同学们有所帮助或启发。
1. 背景
随着越来越多的AI应用进入生产应用阶段,推理服务所需要的GPU资源也在迅速增加。调研数据表明,国内AI相关行业推理服务的资源使用量占比已经超过55%,且比例未来还会持续升高。但很多公司面临的实际问题是,线上推理服务GPU利用率普遍较低,还具备很大的提升空间。
而造成服务GPU利用率低的重要原因之一是:推理服务本身存在性能瓶颈,在极限压力情况下也无法充分利用GPU资源。在这种背景下,“优化推理服务性能、提高GPU资源使用效率、降低资源使用成本”具有非常重要的意义。本文主要介绍如何通过架构部署优化,在保证准确率、推理时延等指标的前提下,提升推理服务的性能和GPU利用率。
2. 视觉模型服务的特点与挑战
近年来,深度学习方法在计算机视觉任务上取得显著进展,已经成为主流方法。视觉模型在结构上具有一些特殊性,如果使用现有推理框架部署,服务在性能和GPU利用率方面可能无法满足要求。
2.1 模型优化工具与部署框架
深度学习模型部署前通常会使用优化工具进行优化,常见的优化工具包括TensorRT、TF-TRT、TVM和OpenVINO等。这些工具通过算子融合、动态显存分配和精度校准等方法提高模型运行速度。模型部署是生产应用的最后一环,它将深度学习模型推理过程封装成服务,内部实现模型加载、模型版本管理、批处理以及服务接口封装等功能,对外提供RPC/HTTP接口。业界主流的部署框架有以下几种:
- TensorFlow Serving:TensorFlow Serving(简称TF-Serving)是Google发布用于机器学习模型部署的高性能开源框架,内部集成了TF-TRT优化工具,但是对非TensorFlow格式的模型支持不够友好。
- Torch Serve:TorchServe是AWS和Facebook联合推出的Pytorch模型部署推理框架,具有部署简单、高性能、轻量化等优点。
- Triton:Triton是Nvidia发布的高性能推理服务框架,支持TensorFlow、TensorRT、PyTorch和ONNX等多种框架模型,适用于多模型联合推理场景。
在实际部署中,无论选择哪种框架,需要同时考虑模型格式、优化工具、框架功能特点等多种因素。
2.2 视觉模型特点
与传统方法不同, 深度学习是一种端到端的方法,不需要单独设计特征提取、分类器等模块,用单个模型取代传统方法多模块任务。深度学习模型在分类、检测、分割、识别等视觉任务上呈现出巨大优势,做到了传统方法无法达到的精度。常用的视觉分类模型(如ResNet、GoogleNet等)和检测模型(如YOLO、R-FCN等)具有如下特点:
- 网络层数多(适合用GPU运算):以ResNet-50为例,网络包含49个卷积层和1个全连接层,参数量高达2千5百万,计算量达到38亿FLOPs(浮点运算数)。模型推理包含大量矩阵计算,适合用GPU并行加速。
- 输入图像尺寸固定(需要预处理):同样以ResNet-50为例,网络的输入是图像浮点类型矩阵,尺寸大小固定为224×224。因此二进制编码图片在送入网络前,需要做解码、缩放、裁切等预处理操作。
2.3 视觉推理服务面临的问题与挑战
由于视觉模型存在的上述特点,导致模型在部署和优化上存在2个问题:
- 模型优化不彻底:TensorRT、TF-TRT等工具主要针对主干网络优化,但忽略了预处理部分,因此整个模型优化并不充分或者无法优化。例如分类模型中ResNet-50所有网络层都可以被优化,但预处理中的图像解码(通常是CPU运算)操作”tf.image.decode”会被TF-TRT忽略跳过。
- 多模型部署困难:视觉服务经常存在组合串接多个模型实现功能的情况。例如在文字识别服务中,先通过检测模型定位文字位置,然后裁切文字所在位置的局部图片,最后送入识别模型得到文字识别结果。服务中多个模型可能采用不同训练框架,TF-Serving或Troch Serve推理框架只支持单一模型格式,无法满足部署需求。Triton支持多种模型格式,模型之间的组合逻辑可以通过自定义模块(Backend)和集成调度(Ensemble)方式搭建,但实现起来较为复杂,并且整体性能可能存在问题。
这两点常见的模型部署问题,导致视觉推理服务存在性能瓶颈、GPU利用率低,即便Triton这种高性能部署框架也难以解决。
通用部署框架重点关注的是“通信方式、批处理、多实例”等服务托管方面的性能问题,但如果模型本身中间某个部分(如图像预处理或后处理)存在瓶颈,优化工具也无法优化,就会出现“木桶效应”,导致整个推理过程性能变差。因此,如何优化推理服务中的模型性能瓶颈,仍然是一件重要且具有挑战性的工作。
3. GPU服务优化实践
分类和检测是两种最基础的视觉模型,常应用在图像审核、图像标签分类和人脸检测等场景。下面以两个典型服务为案例,单个分类模型和“分类+检测”多模型组合的使用情况,来介绍具体性能的优化过程。
3.1 图像分类模型服务优化
美团每天有千万量级的图片需要审核过滤有风险内容,人工审核成本太高,需要借助图像分类技术实现机器自动审核。常用的分类模型结构如图1,其中预处理部分主要包括“解码、缩放、裁切”等操作,主干网络是ResNet-50。预处理部分接收图像二进制流,生成主干网络需要的矩阵数据Nx3x224x224(分别代表图片数量、通道数、图像高度和图像宽度 ),主干网络预测输出图片分类结果。

图1 图像分类模型结构示意图
模型经过TF-TRT优化后的实际结构如下图2所示,主干网络ResNet被优化为一个Engine,但预处理部分的算子不支持优化,所以整个预处理部分仍然保持原始状态。

图2 图像分类模型TF-TRT优化结构图
3.1.1 性能瓶颈
模型经过TF-TRT优化后使用TF-Serving框架部署,服务压测GPU利用率只有42%,QPS与Nvidia官方公布的数据差距较大。排除TF-TRT和Tensorflow框架等可能影响的因素,最终聚焦在预处理部分。Nvidia进行性能测试的模型没有预处理,直接输入Nx3x224x224矩阵数据。但这里的线上服务包含了预处理部分,压测指标CPU利用率偏高。查看模型中各个算子的运行设备,发现模型预处理大部分是CPU运算,主干网路是GPU运算(具体细节参见图1)。
如下图3所示,通过NVIDIA Nsight System(nsys)工具查看模型运行时的CPU/GPU执行情况,可以发现GPU运行有明显间隔,需要等待CPU数据准备完成并拷贝到GPU上,才能执行主干网络推理运算,CPU处理速度慢导致GPU处于饥饿状态。结合服务压测的CPU/GPU利用率数据可以看出:预处理部分CPU消耗高、处理速度慢,是推理服务的性能瓶颈。

图3 分类模型nsys性能诊断图
3.1.2 优化方法
如下图4所示,针对预处理CPU消耗过高影响推理服务性能的问题,提出几种优化方法:
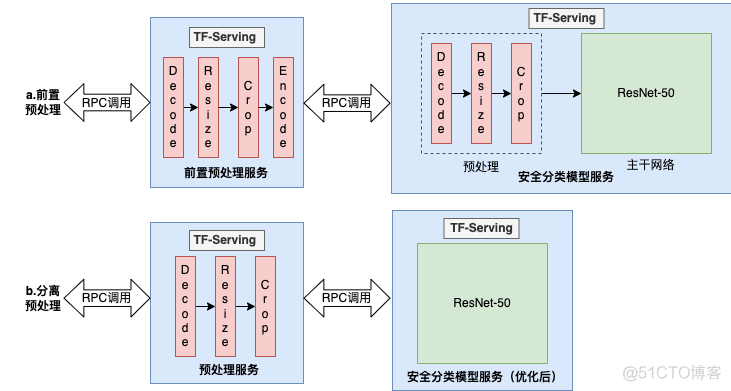
图4 优化方法对比
- 增加CPU:增加机器CPU数量是最简单的做法,但是受限于服务器硬件配置,1个GPU通常只配置8个CPU。所以增加CPU的方法只能用于性能测试数据对比,无法实际应用部署。
- 前置预处理:大尺寸图片的解码、缩放操作CPU消耗较高,相较而言小尺寸图片的处理速度会快很多。因此考虑对输入图片提前进行预处理,将预处理后的小图再送入服务。经过验证Tensorflow中缩放、裁切操作具有叠加不变性,即多次操作和单次操作对最终结果没有影响。预处理后的小图像经过编码后,再送入原始分类服务。需要注意的是图像编码必须选择无损编码(如PNG),否则会导致解码数据不一致,引起预测误差。前置预处理方式的优点是不需要修改原始模型服务,可操作性高、预测结果没有误差。缺点是需要重复预处理,导致整体流程时延增加、CPU资源浪费。
- 分离预处理:另外一种思路是将模型预处理部分和主干网络拆分,预处理部分单独部署到CPU机器上,主干网络部署到GPU机器上。这种做法让CPU预处理服务可以水平无限扩容,满足GPU处理数据供给,充分利用GPU性能。更重要的是将CPU和GPU运算进行解耦,减少了CPU-GPU数据交换等待时间,理论上比增加CPU数量效率更高。唯一需要考虑的是服务间的通信效率和时间,裁切后图像大小为224x224x3,采用无符号整型类型数据大小是143KB,传输时间和带宽在1万QPS以下没有问题。
3.1.3 优化结果
如下图5所示,我们利用NVIDIA Nsight System,对比上述几种方法优化后的模型运行情况。增加CPU和前置预处理的方法都可以缩短CPU预处理时间,减少GPU数据等待时间,提升GPU利用率。但相较而言,分离预处理的方法优化更加彻底,CPU到GPU的数据拷贝时间最短,GPU利用最为充分。

图5 优化方法nsys性能诊断对比图
各种方法优化后的线上服务压测性能结果见下图6(其中前置预处理和分离预处理中的CPU预处理服务额外使用16个CPU),机器配置的CPU型号是Intel(R) Xeon(R) Gold 5218 CPU@2.30GHz、GPU型号是Tesla T4。从压测结果可以看出:

图6 优化结果性能对比
1. 服务CPU增加到32核,QPS和GPU利用率(通过nvidia-smi命令获取的GPU-Util指标)提升超过1倍,GPU利用率提升至88%;
2. 前置预处理方法优化后服务QPS提升超过1倍,略优于增加CPU的方法,但从GPU利用率角度看仍有较大优化空间;
3. 分离预处理方法优化后QPS提升2.7倍,GPU利用率达到98%接近满载状态。
增加CPU并不能完全解决服务性能瓶颈问题,虽然GPU利用率达到88%,但是CPU-GPU数据传输时间占比较大,QPS提升有限。前置预处理方法也没有完全解决预处理性能瓶颈问题,优化并不彻底。相较而言,分离预处理方法充分发挥了GPU运算性能,在QPS和GPU利用率指标上都取得了更好的优化效果。
3.2 图像“检测+分类”模型服务优化
在一些复杂任务场景下(如人脸检测识别、图像文字识别等),通常是检测、分割、分类等多个模型组合实现功能。本节介绍的模型便是由“检测+分类”串接而成,模型结构如下图7所示,主要包括以下几个部分:

图7 原始模型结构示意图
- 预处理:主要包括图像解码、缩放、填充等操作,输出Nx3x512x512图像矩阵,大部分算子运行在CPU设备上。
- 检测模型:检测网络结构是YOLOv5,算子运行设备为GPU。
- 检测后处理:使用NMS(非极大值抑制)算法去除重复或误检目标框,得到有效检测框,然后裁切目标区域子图并缩放,输出Nx3x224x224图像矩阵,检测后处理大部分算子运行在CPU设备上。
- 分类模型:分类网络结构是ResNet-50,算子运行设备为GPU。
其中检测和分类两个子模型是单独训练的,推理时合并成单个模型,部署框架采用TF-Serving,优化工具采用TF-TRT。
3.2.1 性能瓶颈
模型中预处理和检测后处理大部分是CPU运算,检测和分类模型主干网络是GPU运算,单次推理过程中需要进行多次CPU-GPU之间数据交换。同样地,CPU运算速度慢会导致GPU利用率低,推理服务存在性能瓶颈。
实际线上服务压测GPU利用率68%,QPS也存在较大优化空间。服务配置为1GPU+8CPU(机器CPU型号是Intel(R) Xeon(R) Gold 5218 CPU@2.30GHz,GPU型号是Tesla T4)。
3.2.2 优化方法
仍然采用模型拆分的思路,将CPU和GPU运算部分单独部署微服务。如下图8所示,我们将原始模型拆分为4个部分,预处理和检测后处理部署成CPU微服务(可根据流量大小动态扩容),检测模型和分类模型部署成GPU微服务(同一张GPU卡上)。为了保持调用方式简单,上层采用调度服务串接各个微服务,提供统一调用接口,对上游屏蔽调用差异。拆分后的检测模型和分类模型经过TensorRT优化后采用Triton部署。
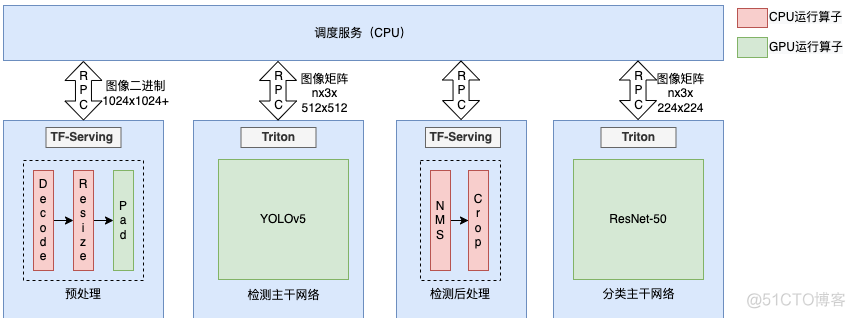
图8 模型优化部署结构示意图
3.2.3 优化结果
如下图9所示,除了原始服务和微服务拆分,另外还对比了增加CPU和Triton Ensemble两种方式的性能测试结果。Triton Ensmeble方式将所有子模型(包括预处理和后处理)部署在一个机器上,实现多模型流水线调度。对比可以看出:

图9 优化结果性能对比
- 原始服务CPU增加到32核,GPU利用率提升到90%,但QPS提升只有36%;
- Triton Ensemble方式与原始TF-Serving服务相比性能差距不大;
- 模型拆分微服务方式优化后QPS提升3.6倍,GPU利用率达到100%满载状态。
增加CPU的方法对服务GPU利用率提升较大、QPS提升不明显,原因在于CPU预处理和后处理时间缩短,但CPU-GPU数据传输时间在整个推理过程中仍然占比较大,GPU运算时间较少。
将模型拆分使用Triton Ensmeble方式部署实现多模型调度流水线,效率并不比模型拆分前高。因为多模型流水线是在同一台机器上,CPU和GPU相互影响的问题并没有解决,GPU处理效率受CPU制约。模型拆分微服务部署方式在服务层面实现了调用流水线,CPU预处理和后处理微服务可以根据流量动态增加资源,满足GPU模型微服务吞吐需求,实现了GPU/CPU处理解耦,避免了CPU处理成为瓶颈。
总而言之,拆分微服务的方式充分发挥了GPU运算性能,在QPS和GPU利用率指标上都取得了更好的效果。
4. 通用高效的推理服务部署架构
除了上述两个具有代表性的推理服务优化案例,视觉其它很多服务也采用了这种优化方式。这种优化方式具有一个核心思想:在CPU运算是瓶颈的推理服务中,将模型的CPU和GPU运算部分拆分,单独部署成CPU/GPU微服务。
根据这种思想,我们提出一种通用高效的推理服务部署架构。如下图10所示,底层使用通用的部署框架(TF-Serving/Triton等),将模型中CPU运算部分如预处理、后处理拆分单独部署成CPU微服务,主干网络模型部署成GPU服务,上层调度服务串联模型微服务实现整体功能逻辑。

图10 通用服务部署架构示意图
这里需要解释一个重要问题,为什么这种部署架构是高效的?
首先在宏观层面,模型拆分部署成微服务,通过调度服务实现了子模型流水线处理。拆分的子模型CPU微服务可以根据流量和处理能力动态扩容,避免模型预处理或后处理CPU运算能力不足成为性能瓶颈,满足了GPU模型微服务的吞吐需求。
其次在微观层面,如果模型包含多个CPU/GPU运算部分,那么GPU运算之间会存在间隔。如下图11所示,单次推理过程中两次GPU运算之间需要等待CPU后处理部分完成,CPU预处理也会影响GPU运算。模型拆分后,预处理和后处理部分独立部署成CPU服务,GPU服务中推理过程仅包含两个子模型运算部分,并且子模型间运算相互独立无数据关联,CPU-GPU数据传输部分可以与GPU运算过程并行,理论上GPU可以达到100%运行效率。

图11 推理过程对比示意图
另外,在时延方面,拆分微服务的部署方式增加了RPC通信和数据拷贝时间开销,但从实践来看这部分时间占比很小,对端到端的延迟没有显著影响。例如对于上面3.1节中的分类模型,优化前服务的平均耗时是42ms,优化后微服务形式(RPC通信协议为Thrift)的服务整体平均耗时是45ms。对于大部分视觉服务应用场景而言,这种级别的延迟增加通常并不敏感。
5. 总结与展望
本文以两个典型的视觉推理服务为案例,介绍了针对模型存在性能瓶颈、GPU利用率不高的问题进行的优化实践,优化后服务推理性能提升3倍左右,GPU利用率接近100%。根据优化实践,本文提出了一种通用高效的推理服务部署架构,这种架构并不局限于视觉模型服务,其它领域的GPU服务也可参考应用。
当然,这种优化方案也存在一些不足,比如优化过程中模型如何拆分比较依赖人工经验或者实验测试,没有实现优化流程的自动化与标准化。后续我们计划建设模型性能分析工具,自动诊断模型瓶颈问题,支持自动拆分优化全流程。
6. 本文作者
| 张旭、赵铮、岸青、林园、志良、楚怡等,来自基础研发平台视觉智能部。
| 晓鹏、駃飞、松山、书豪、王新等,来自基础研发平台数据科学与平台部。
———- END ———-
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
