
概述
在上一篇博客中,已经阐述了预训练过程中,神经网络中超参数的计算逻辑,本文,从程序实现的角度,将数学计算转换为程序代码,最终生成超参数文件;并将替换 聊聊 神经网络模型 示例程序——数字的推理预测 中已训练好的超参数文件,推理预测数字,最终比对下两者的精确度。
神经网络层实现
首先,根据神经网络各个层的计算逻辑用程序实现相关的计算,主要是:前向传播计算、反向传播计算、损失计算、精确度计算等,并提供保存超参数到文件中。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
from DeepLearn_Base.common.functions import *
from DeepLearn_Base.common.gradient import numerical_gradient
import pickle
# 三层神经网络处理类(两层隐藏层+1层输出层)
class ThreeLayerNet:
# input_size:输入层神经元数量,灰度图像的三维表示: 1 * 28 * 28 = 784
# output_size: 输出层神经元数量,10,表示10个数字
# hidden_size:第一层隐藏层神经元数量,50
# second_hidden_size:第二层隐藏层神经元数量,100
# weight_init_std:权重初始化
def __init__(self, input_size, hidden_size, output_size, second_hidden_size, weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, second_hidden_size)
self.params['b2'] = np.zeros(second_hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(second_hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 执行预测
def predict(self, x):
W1, W2, W3 = self.params['W1'], self.params['W2'], self.params['W3']
b1, b2, b3 = self.params['b1'], self.params['b2'], self.params['b3']
# 隐藏层第一层
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 隐藏层第二层
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# 输出层
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, 服务器托管网t)
# 精确度计算
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# 梯度计算
def gradient(self, x, t):
W1, W2, W3 = self.params['W1'], self.params['W2'], self.params['W3']
b1, b2, b3 = self.params['b1'], self.params['b2'], self.params['b3']
grads = {}
batch_num = x.shape[0]
# forward
# 隐藏层第一层
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 隐藏层第二层
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# 输出层
服务器托管网 a3 = np.dot(z2, W3) + b3
y = softmax(a3)
# backward
# 两层隐藏层计算梯度
# 输出层梯度: Loss与输出的导数,分类场景下,等于预测值-真实值
# 权重梯度: 隐藏层输出的转置 * 损失函数梯度
dy = (y - t) / batch_num
grads['W3'] = np.dot(z2.T, dy)
grads['b3'] = np.sum(dy, axis=0)
# 反向传播到隐藏层
# 隐藏层梯度:Loss与输出的导数 * 输出层权重的转置
da2 = np.dot(dy, W3.T)
dz2 = sigmoid_grad(a2) * da2
grads['W2'] = np.dot(z1.T, dz2)
grads['b2'] = np.sum(dz2, axis=0)
da1 = np.dot(da2, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
# 保存参数到文件
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
预训练实现
读取MNIST训练数据集,总共有60000个。每次从60000个训练数据中随机取出100个数据 (图像数据和正确解标签数据)。然后,对这个包含100笔数据的批数据求梯度,使用随机梯度下降法(SGD)更新参数。这里,梯度法的更新次数(循环的次数)为10000。每更新一次,都对训练数据计算损失函数的值,并把该值添加到数组中。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from DeepLearn_Base.dataset.mnist import load_mnist
from three_layer_net import ThreeLayerNet
# 读入数据
# x_train.sharp 60000 * 784
# t_train.sharp 60000 * 10
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = ThreeLayerNet(input_size=784, hidden_size=50, second_hidden_size=100, output_size=10)
iters_num = 10000 # 适当设定循环的次数
# 训练集大小 60000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 每批次迭代数量:600
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
# 从训练集中选取100个为一批次进行训练
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 更新超参数梯度
grad = network.gradient(x_batch, t_batch)
# 更新超参数W,b
# 基于SGD算法更新梯度,上面是随机选择的批数据处理,因此更新时,也是随即更新梯度
for key in ('W1', 'b1', 'W2', 'b2', 'W3', 'b3'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
# 输出到文件保存参宿后
network.save_params("E:workcodecodeDeepLearn_Basech04myparams.pkl")
用图像来表示这个损失函数的值的推移,如图所示;并保存最终的超参数到pkl文件。

应用自训练超参数
将之前用于预测图像文字中使用的超参数文件替换为自己预训练生成的pkl参数文件,并执行代码,打印出精确度。
这是基于默认的超参数进行推理后的精确度:
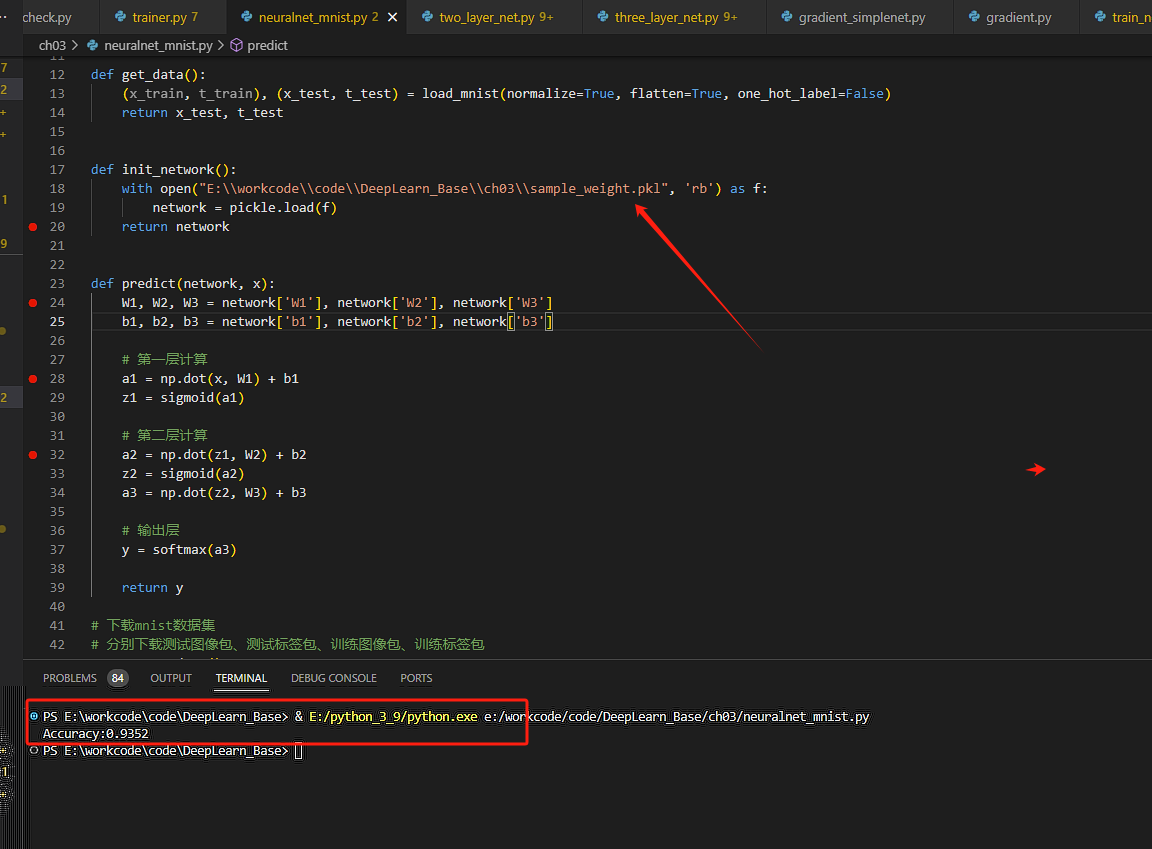
替换超参数文件,进行图像识别推理
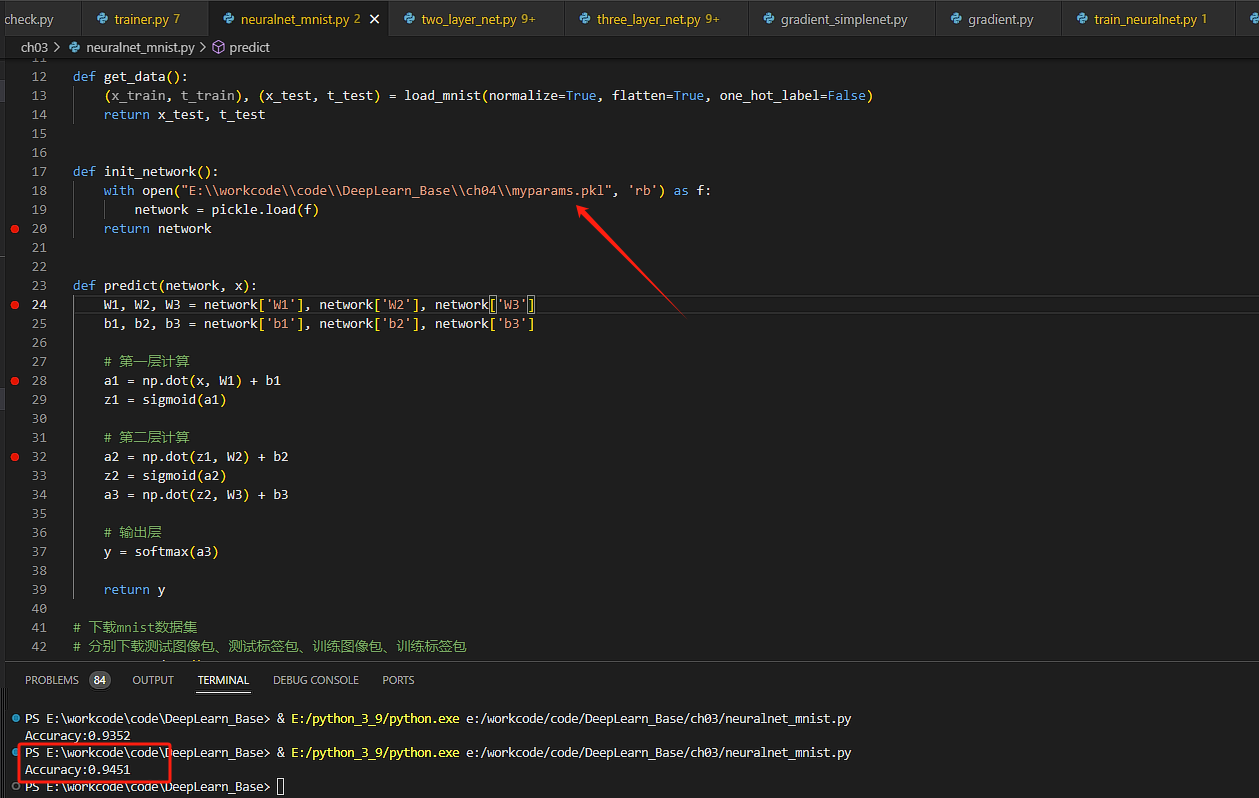
精确度上涨了0.01,因此选择合适的梯度更新超参数,是保证推理精确度好坏的关键。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 解决因对EFCore执行SQL方法不熟练而引起的问题
前言 本文测试环境:VS2022+.Net7+MySQL 因为我想要实现使用EFCore去执行sql文件,所以就用到了方法ExecuteSqlAsync,然后就产生了下面的问题,首先因为方法接收的参数是一个FormattableString,它又是一个抽象类,…
