
聚类算法
前言
作为数模小白,看了很多讲解新概念新模型的文章,这些文章往往要么讲的很浅不讲原理只讲应用,让人知其然不知其所以然。要么讲的很深小白看不懂,同时总是忽略关键部分,经常性引入陌生概念让初学者疑惑,因此有了本文,任何能熟练掌握线性代数知识且逻辑思维能力尚可的人都可以理解,而无需其他数模知识,涉及任何新概念都会先讲解后使用
所以我就打算把自己学完之后的笔记整理出来,其中每一篇文章中可能含有直接从其他文章中搜集过来的公式,因为这些文章原本只是我自己的笔记,我懒得敲公式,只是写完之后想着整理出来,弘扬一下互联网精神,于是就有了这个系列。
综述
聚类算法广义上属于分类算法的一种,但我们平时所说的分类算法往往指的是狭义分类算法,因此我们还是需要明确狭义分类(Classification)算法和聚类(Clustering)算法的区别的。
分类算法关注的问题是通过一个数据类别已知的训练数据集来获取分类方法,以便对数据类别未知的数据集进行分类,属于监督学习算法。而聚类算法是直接拿着一个数据类别未知的数据集就通过统计学手段进行分类,属于无监督学习算法。
监督学习算法上来便拿到了给定的类别且分好类了的正确数据集,因此将未知数据集分类后我们也能清楚的知道每个类别的意义,但是,像降维算法(如前文讲过的主成分分析)和聚类算法这样的无监督学习方法,我们就并不清楚每个分类到底是依据什么进行划分的、含义为何了,需要认为的对分类结果进行分析
聚类算法的分类
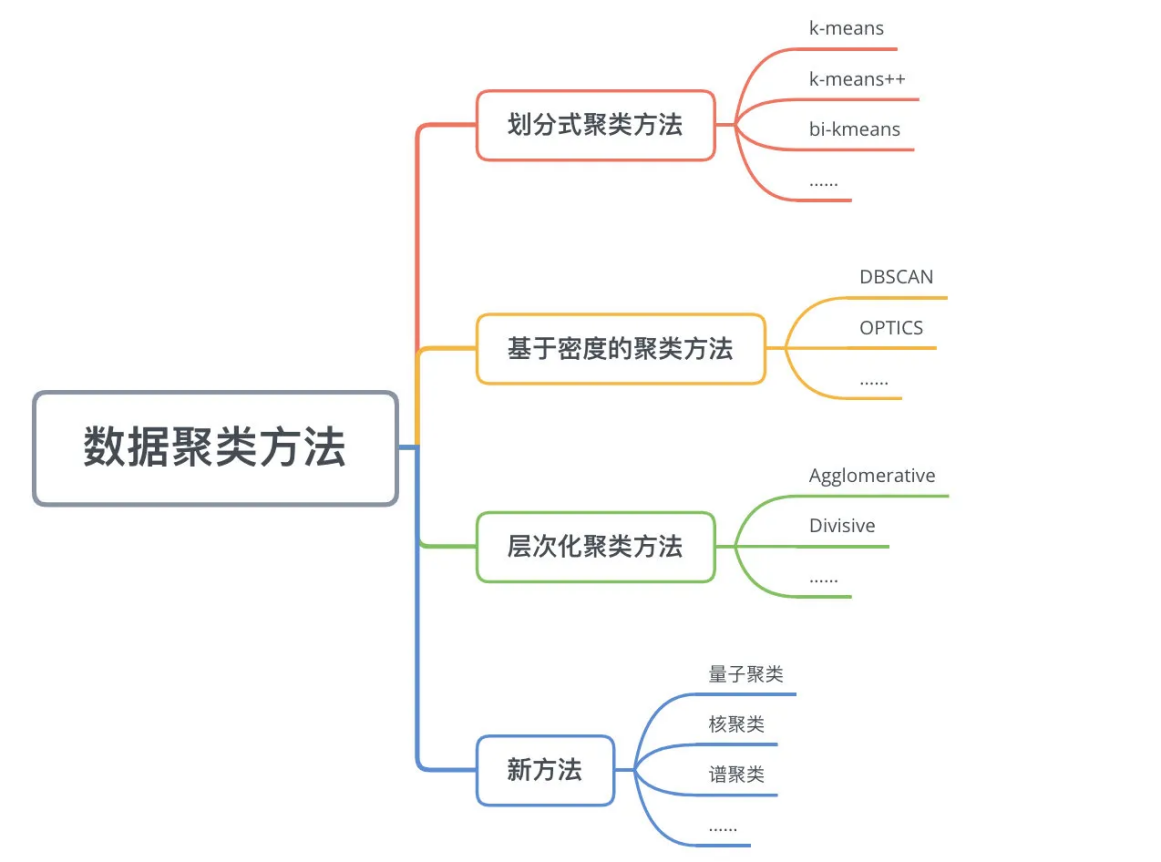
划分类聚类方法
划分类聚类方法需要事先认为指定cluster的数目或者聚类中心,直到达到“同一cluster内的点足够近,不同cluster的点足够远”的目标。
k-means及其变体k-means++、bi-kmeans、kernel k-means等就是常用的划分式聚类方法,让我们依次进行介绍
k-means算法
先进行可视化数据,然后通过观察指定聚类数目,然后进行以下流程:

假设xi是数据点,i是初始的聚类质心是数据点,L(x)=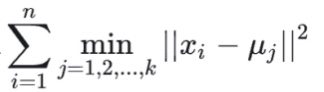 是该算法中度量聚类效果的指标,L(x)越小则聚类效果越好,因此经典K-means算法的目标函数可以写成Lmin(x)=
是该算法中度量聚类效果的指标,L(x)越小则聚类效果越好,因此经典K-means算法的目标函数可以写成Lmin(x)=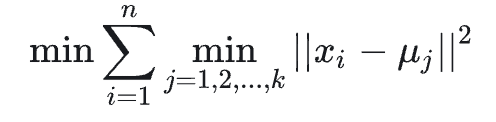 。
。
我们先随机选择k个初始质心,即初始聚类中心,然后遍历数据集中的每一个数据点,将数据点分配到质心距离其最近的那个cluster中,然后计算每个簇的均值,将均值作为新的质心,然后再重新遍历每个数据点,周而复始,直到L(X)足够小,达到事先指定的标注为止。
这里要引入一个概念,凸优化函数和非凸优化函数,我们将图像的极小值定义为最优解,那么凸优化函数指只有一个极小值的函数,换句话说极小值(我们找到的最优解)一定是最小值(全局最优解)的函数,我们找到的最优解一定就是全局最优解。而非凸优化函数指函数有多个极小值,我们找的最优解很可能不是全局最优解,而是局部最优解。
而由于该算法中的Lmin(x)就是一个非凸优化函数,换句话说我们很可能收敛于局部最优解而不是全局最优解,具体收敛于哪个极值点取决于我们选取的初始质心点,因此科学家提出了K-means的改进算法来解决这个问题
(忘掉数学里的凸函数凹函数的定义吧,凸优化函数和非凸优化函数最早就是指数学里的凸函数和凹函数,但时过境迁,计算机领域中的这一概念已经发生了极大的语义偏移,如果还用数学中的概念进行解释则会造成极大的误解和不变)
K-means++算法
K-means++更改了初始数据点选取方法,K-means++的选取算法如下:
先随机选取一个数据点作为初始聚类中心,然后计算每个数据点和已有最近聚类中心的距离,距离越大被选中作为下一个聚类中心的概率也就越大,然后运用轮盘法随机抽取下一个聚类中心,直到聚类中心数量达到实现设定的数量为止。
- means++仅仅优化了初始质心点选取这步,其他步骤与K-mean基本一致,但尽管如此也大大减小了收敛于局部最优解的可能性。
matlab中提供了kmeans函数,默认情况下kmeans函数执行的就是kmeans++算法
同时,K值该如何确定呢?一般我们算出各个K值的D值,D=类内平均距离/类间平均距离,然后还出D关于K的图像,取一个能使D足够低的尽可能小的K值作为我们kmeans的超参数K即可。
代码示例:
%随机获取150个点
X = [randn(50,2)+ones(50,2);randn(50,2)-ones(50,2);randn(50,2)+[ones(50,1),-ones(50,1)]];
opts = statset(‘Display’,’final’);
%调用Kmeans函数
%X N*P的数据矩阵
%Idx N*1的向量,存储的是每个点的聚类标号
%Ctrs K*P的矩阵,存储的是K个聚类质心位置
%SumD 1*K的和向量,存储的是类间所有点与该类质心点距离之和
%D N*K的矩阵,存储的是每个点与所有质心的距离;
[Idx,Ctrs,SumD,D] = kmeans(X,3,’Replicates’,3,’Options’,opts);
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot(X(Idx==1,1),X(Idx==1,2),’r.’,’MarkerSize’,14)
hold on
plot(X(Idx==2,1),X(Idx==2,2),’b.’,’MarkerSize’,14)
hold on
plot(X(Idx==3,1),X(Idx==3,2),’g.’,’MarkerSize’,14)
%绘出聚类中心点,kx表示是圆形
plot(Ctrs(:,1),Ctrs(:,2),’kx’,’MarkerSize’,14,’LineWidth’,4)
plot(Ctrs(:,1),Ctrs(:,2),’kx’,’MarkerSize’,14,’LineWidth’,4)
plot(Ctrs(:,1),Ctrs(:,2),’kx’,’MarkerSize’,14,’LineWidth’,4)
legend(‘Cluster 1′,’Cluster 2′,’Cluster 3′,’Centroids’,’Location’,’NW’)
Ctrs
SumD
bi-K-means算法
bikmeans更改了度量聚类效果的指标,运用SSE(误差平方和)来衡量聚类效果,SSE越小则聚类效果越好,SSE是凸优化函数,换句话说这是一个能稳定收敛于全局最优解的算法。
要注意的是,虽然这是一个能求出全局最优解的方法,但不代表他求出来的解就一定不会把数据点分错类,最优解不是正解,现实世界中不存在正解,随机因素是不可能排除的,因此不存在绝对不出错的分类算法。
bi-K-means算法首先将所有数据点视为一个cluster,然后将在这个cluster上进行k=2的经典k-means聚类,然后从两个结果cluster中选取一个进行继续划分,直到cluster 的总数达到事先规定的类数。其中,选取哪一个cluster进行划分取决于对其划分能否最大程度地降低SSE的值。
SSE是什么呢?如果目前有k个cluster,每个cluster都有一个属于自己的SSEi,k个SSEi的和就是SSE。SSEi就等于第i个cluster的元素到所在簇质心距离的平方和。
有趣的是,bi-K-means中进行的k=2的经典K-means聚类其实也可以被K-means++所替代,但是K-means++并不能对运算速度进行太多提升,甚至可能降低运算速度,K-means++是增大了得到全局最优解的概率可是bi-K-means本身就是一个100%得到全局最优解的算法,更是完全没必要使用k-means++作为子算法了,因此bi-K-means算法内部子算法选用的是经典K-means算法。
代码略
让我们比较一下三种算法
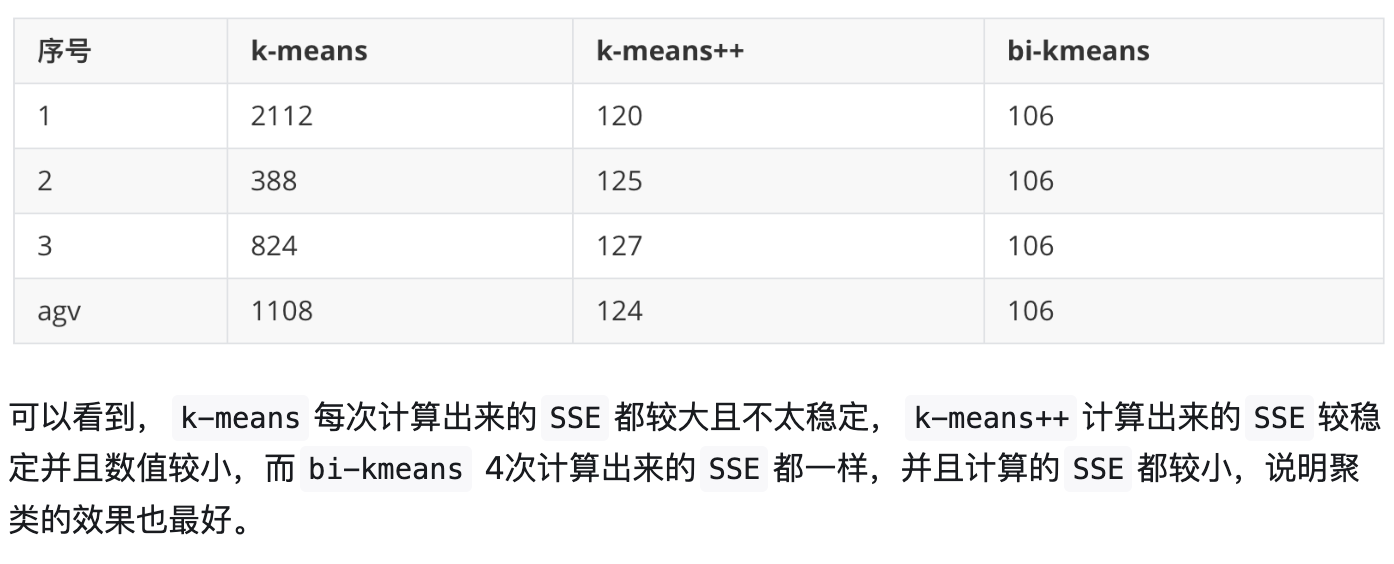
以上三种算法都只能用于解决数据集线性可分的问题对于数据集线性不太能分甚至很不太能分的问题就会得出荒谬的结果,因此引入了其他算法来解决数据集线性不可分的问题。
kernel-k-means算法和基于密度的划分方法等方法都可以解决这个问题,我们先来介绍kernel-k-means。
kernel-K-means
该算法将二维数据通过一个恰当的非线性映射转化为三维数据,从而把数据集转化为线性可分的数据集,然后在三维空间中利用其他kmeans算法进行常规聚类。形象的原理如下图所示:
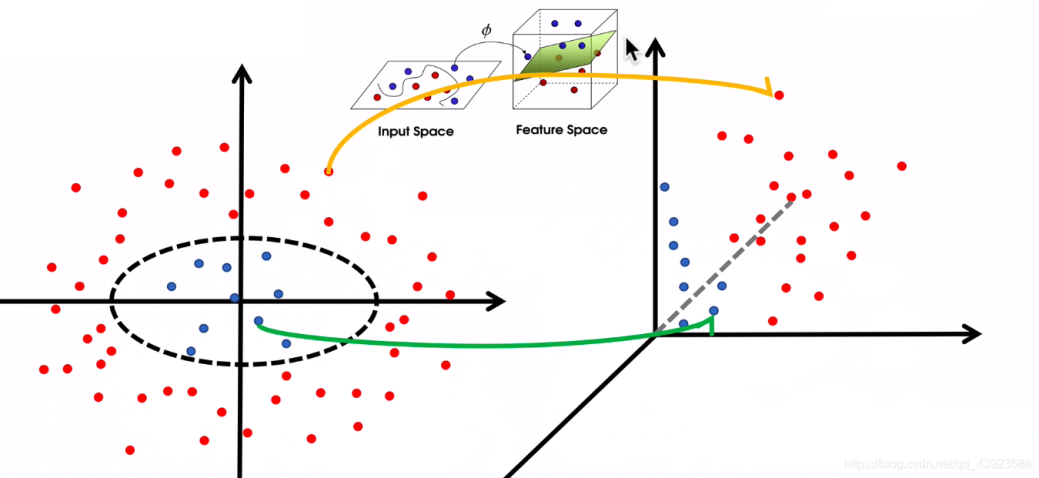
具体转化规则有很多种,实际问题中可能还需要具体分析,该算法比较复杂,如果最开始的直接观察可视化数据的时候发现数据集线性不可分,那不如直接用基于密度的聚类方法,因此这个算法暂时跳过。
基于密度的聚类方法
DBSCAN算法
首先要引入几个概念,对于含有若干数据点的集合X而言,X内的点会被分为核心点、边界点、噪声点三类,具体定义如下
对于特定的数据点x0而言,所有与x距离小于epsilon的点构成的集合被称作x0的epsilon邻域,而x0的epsilon邻域的点的个数称为x0的密度,记作(x0),epsilon往往是运算前给定的超参数
DBSCAN算法中还有一个超参数叫做邻域密度阈值,记作M,规定在X中,密度大于等于M的点被称为X的核心点,核心点构成的集合记作Xc,所有核心点epsilon邻域内的所有非核心点称作X的边界点(一个边界点可能在多个非核心店的epsilon邻域中),边界点构成的集合记作Xbd。X中既不是核心点又不是边界点的数据点就被命名为噪声点。
该算法具体流程如下
先标记所有数据点都是“未访问状态”,先随机选取一个未访问的数据点p,将其标记已访问,再判断p的密度和M的关系,如果p=M,则创建一个新的cluster C,并将p归入C中,对于p的epsilon邻域内的每一个点(不管是否访问过)都归入集合N中,然后依次访问集合N的每一个数据点p’,若p’的密度也大于等于M,则将p’的epsilon邻域中的所有未访问的点都添加到集合N中,否则将p’归入C中。然后只要还有未访问数据点,就周而复始继续选择下一个未访问的数据点,直到所有数据点都已被归类。
重新叙述一遍,
先标记所有数据点都是“未访问状态”,先随机选取一个未访问的数据点p,将其标记为已访问。如果(p)
最后,只要还有未访问数据点,就周而复始继续选择下一个未访问的数据点,直到所有数据点都已被归类。
(p的可达点递归式定义如下,在p的epsilon邻域中的点,或者在p的可达点的epsilon邻域中的点都是p的可达点)
在DBSCAN算法中,使用了统一的epsilon值,当数据密度不均匀的时候,如果设置了较小的epsilon值,则较稀疏处的点将很可能被集体认定为噪声点,很难形成cluster;如果设置了较大的epsilon值,则密度较大处的邻近的多个cluster容易被划分为同一个cluster,如下图所示。
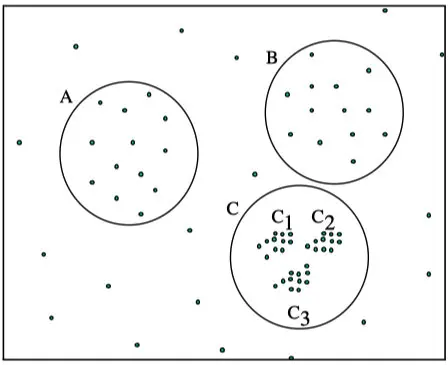
如果设置的epsilon较大,将会获得A,B,C这3个cluster
如果设置的epsilon较小,将会只获得C1、C2、C3这3个cluster
一般来说,DBSCAN算法有以下三个特点:
1.需要提前确定epsilon和M的值,但不需要提前设置聚类的个数
2.对初值选取敏感,对噪声不敏感
3.对密度不均的数据聚合效果不好
OPTICS算法
由于DBSCAN算法中epsilon的选取会相当程度地影响算法效果,而epsilon又很难人为指定一个很好的值,因此有了OPTICS算法,后者实际上是对前者的一种有效改进,主要解决的就是DBSCAN对epsilon极敏感的问题。
我们还需要引入几个概念,
- 核心距离r,定义为距离数据点p的epsilon邻域内第M近的数据点与p的距离(把p本身算作距离p第一近的点),当然如果(p)
- 可达距离rd,对于数据点p而言,p和数据点o的可达距离定义为p的核心距离和op间距的较大值,当然如果(p)
具体流程如下
- 初始化一个有序队列和一个结果队列,并将所有数据点初始化为“未访问状态”
- 从未访问状态节点中抽取一个样本点p,对于特定的p,先把p标记为已访问,
- 然后计算(p),若(p)=M,则将p标记为核心点并放入结果队列中,将p的epsilon邻域中的所有点按照可达距离进行升序排列放入对有序队列中
- 如果有序队列不为空,就弹出队首(即目前可达距离最近的数据点,如果队列为空,则跳至第七步。
- 如果弹出的队首q在结果队列中,则直接返回第四步;若弹出的队首q不在结果队列中,则先将其加入结果队列。
- 然后判断q是否为核心点,如果q不是核心点,则直接放回第四步,如果q是核心点,那么将q的epsilon邻域内的点也放入有序队列中,并将有序队列重新升序排列(如果已经在有序队列中了的点被重复放入有序队列中,则将其距离更新为较小的那一个),然后返回第四步
- 如果所有节点均已访问过,则运算停止,否则返回第二步
至此为止,我们其实都还没获得具体分类,只获得了一个结果队列。我们要先人为定义一个最大半径R,然后从结果序列中按顺序取出样本点,直到结果队列为空,对于取出的样本点p而言,如果p的可达距离小于等于R,则将其归入当前cluster中,否则如果改点的核心距离大于R则归类为噪声点,如果核心距离小于等于R则创建一个新的cluster,将其归入新的cluster中
epsilon依旧是人为指定的,但我们在OPTICS中使用的更多的是由epsilon算出来的核心距离r,这使得OPTICS中对epsilon的值不再那么敏感,随便设置为一个较大的数都可以得到大体一致的优秀分类结果,一般直接设置为正无穷。
因此这个算法中我们实际上用到的超参数是R与M,我们大可以把结果队列的可达距离关于队列编号(排在队列第几位编号就是几)的条形统计图画出来,比如像下图这般:
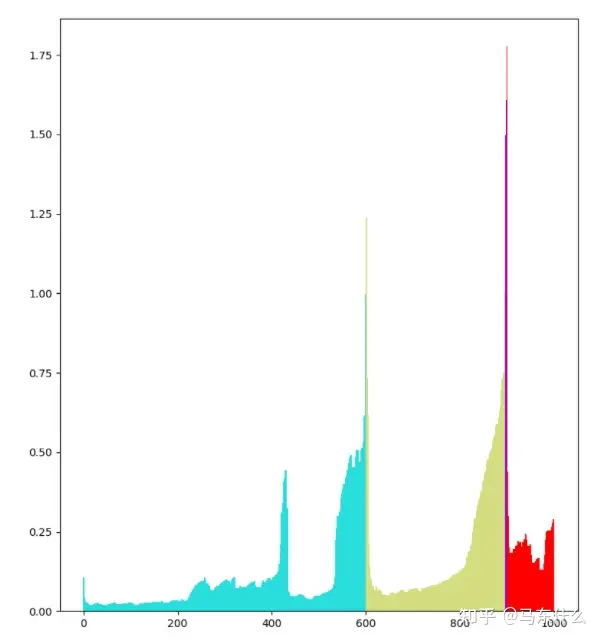
然后就可以很轻易的观察出应该选取的R与M,大大降低了选出恰当超参数的难度,从而大大提高了算法可靠性。
其实,OPTICS中用到的epsilon往往取正无穷,并不相当于DESCAN中的epsilon,而OPTICS中的R其实才相当于DESCAN中的epsilon,根据结果队列的图像挑选R和M的过程其实就是较为客观地确定DESCAN中的epsilon与M的过程,毕竟我们根据这个排序可以得到基于任何epsilon与M的DBSCAN算法的结果,可以理解为把epsilon放宽为一整个范围,形象地展示了每个epsilon会对应的分类结果,而非只取特定的epsilon
因此,OPTICS聚类有效降低了算法对于超参数的敏感性,且有效解决了密度不均导致分类效果较差的问题,相对于K-means算法还解决了线性不可分的数据集的有效处理问题。
DBSCAN可以直接用matlab的dbscan函数实现,OPTICS则需要手写实现,具体代码实现如下:
% [RD,CD,order]=optics(x,k)
% ————————————————————————-
% Aim:
% Ordering objects of a data set to obtain the clustering structure
% ————————————————————————-
% Input:
% x – data set
% k – number of objects in a neighbor服务器托管网hood of the selected object,即M
% ————————————————————————-
% Output:
% RD – vector with reachability distances (m,1)
% CD – vector with core distances (m,1)
% order – vector specifying the order of objects (1,m)
% ————————————————————————-
% Example of use:
% x=[randn(30,2)*.4;randn(40,2)*.5+ones(40,1)*[4 4]];
% [RD,CD,order]=optics(x,4)
function [RD,CD,order,D]=optics(x,k)
[m,n]=size(x); % m=70,n=2
CD=zeros(1,m);
RD=ones(1,m)*10^10;
% Calculate Core Distances
for i=1:m
D=sort(dist(x(i,:),x));
CD(i)=D(k+1); % 第k+1个距离是密度的界限阈值
end
order=[];
seeds=[1:m];
ind=1;
while ~isempty(seeds)
ob=seeds(ind);
%disp(sprintf(‘aaaa%i’,ind))
seeds(ind)=[];
order=[order ob]; % 更新order
var1 = ones(1,length(seeds))*CD(ob);
var2 = dist(x(ob,:),x(seeds,:));
mm=max([var1;var2]); % 比较两个距离矩阵,选择较大的距离矩阵
ii=(RD(seeds))>mm;
RD(seeds(ii))=mm(ii);
[i1 ind]=min(RD(seeds));
%disp(sprintf(‘bbbb%i’,ind))
end
RD(1)=max(RD(2:m))+.1*max(RD(2:m));
function [D]=dist(i,x)
% function: [D]=dist(i,x)
%
% Aim:
% Calculates the Euclidean distances between the i-th object and all objects in x
% Input:
% i – an object (1,n)
% x – data matrix (m,n); m-objects, n-variables
%
% Output:
% D – Euclidean distance (m,1)
[m,n]=size(x);
D=(sum((((ones(m,1)*i)-x).^2)’)); % 距离和
if n==1
D=abs((ones(m,1)*i-x))’;
end
层次化聚类方法
前面的那些算法会产生一种误差,叫做链式效应,是说如果分出来的cluster的形状是一个狭长的链子而非一个超球体,那么由于链子的存在而被归为一类的链子两端的元素其实差异很大。
为了降低链式效应,层次聚类法应运而生,层次聚类算法 (hierarchical clustering) 时间复杂度较高,大约为O(n^3),一般分为两类:
Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类或凝聚性层次聚类,每一个对象最开始都是一个 cluster,每次按一定的准则将最相近的两个 cluster 合并生成一个新的 cluster,如此往复,直至最终所有的对象都属于一个 cluster。这里主要关注此类算法。
Divisive 层次聚类: 又称自顶向下(top-down)的层次聚类或分裂型层次聚类,最开始所有的对象均属于一个 cluster,每次按一定的准则将某个 cluster 划分为多个 cluster,如此往复,直至每个对象均是一个 cluster。
拿Agglomerative 层次聚类为例,较为简单的一个实现方法如下:

matlab中的linkage函数可以用于实现Agglomerative 层次聚类法
function [idx, Z] = agglomerative(X, K)
% X: n-by-p matrix, each row is a data point
% K: number of clusters
% idx: n-by-1 vector, cluster index for each data point
% Z: (n-1)-by-3 matrix, linkage matrix
n = size(X, 1);
D = pdist(X); % compute pairwise distance between data points
Z = linkage(D); % compute linkage matrix
idx = cluster(Z, ‘maxclust’, K); % assign clusters based on max distance threshold
idx = XC;
end
总结
| Arabic | Hebrew | Polish |
| Bulgarian | Hindi | Portuguese |
| Catalan | Hmong Daw | Romanian |
| Chinese Simplified | Hungarian | Russian |
| Chinese Traditional | Indonesian | Slovak |
| Czech | Italian | Slovenian |
| Danish | Japanese | Spanish |
| Dutch | Klingon | Swedish |
| English | Korean | Thai |
| Estonian | Latv服务器托管网ian | Turkish |
| Finnish | Lithuanian | Ukrainian |
| French | Malay | Urdu |
| German | Maltese | Vietnamese |
| Greek | Norwegian | Welsh |
| Haitian Creole | Persian |
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 【服务器数据恢复】虚拟机文件丢失导致Hyper-V服务瘫痪,虚拟机无法使用的数据恢复案例
服务器数据恢复环境: Windows Server操作系统服务器,部署Hyper-V虚拟化环境,虚拟机的硬盘文件和配置文件存放在某品牌MD3200存储中,MD3200存储中有一组由4块硬盘组成的raid5阵列,存放虚拟机的数据文件;另外还有一块硬盘存放虚拟机数…
