
博客地址:https://www.cnblogs.com/zylyehuo/
(一)识别背景/目的
第十八届全国大学生智能汽车竞赛室外 ROS 无人车赛(高教组)
无人车在室外运行中, 需要探索未知环境, 识别障碍物, 停车标志牌、红绿灯等标志物。
比赛场地为不规则环形场地, 由红蓝两色锥桶搭建而成, 整体赛道由直线区域、 “S”弯、 直角区域、 圆形区域等部分元素或全部元素构成
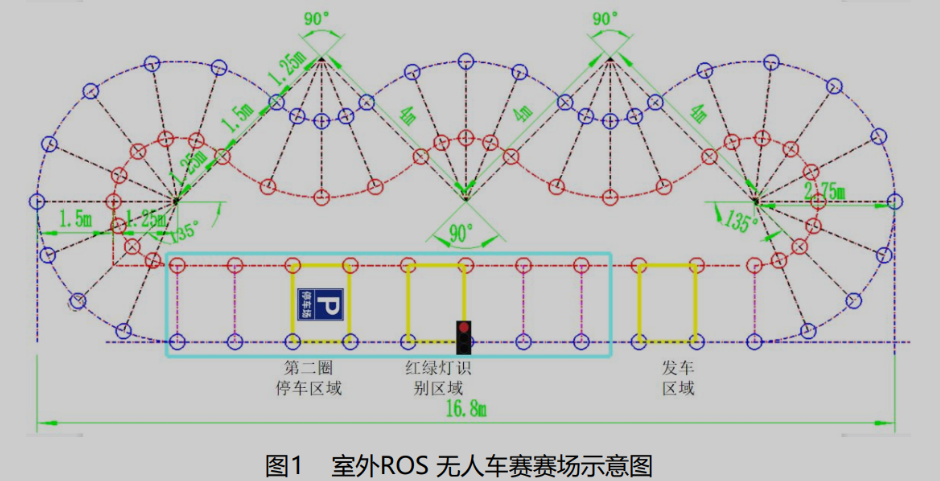
(二)识别/运行场地
① 一食堂二楼

② 室外网球场地

(三)实现效果


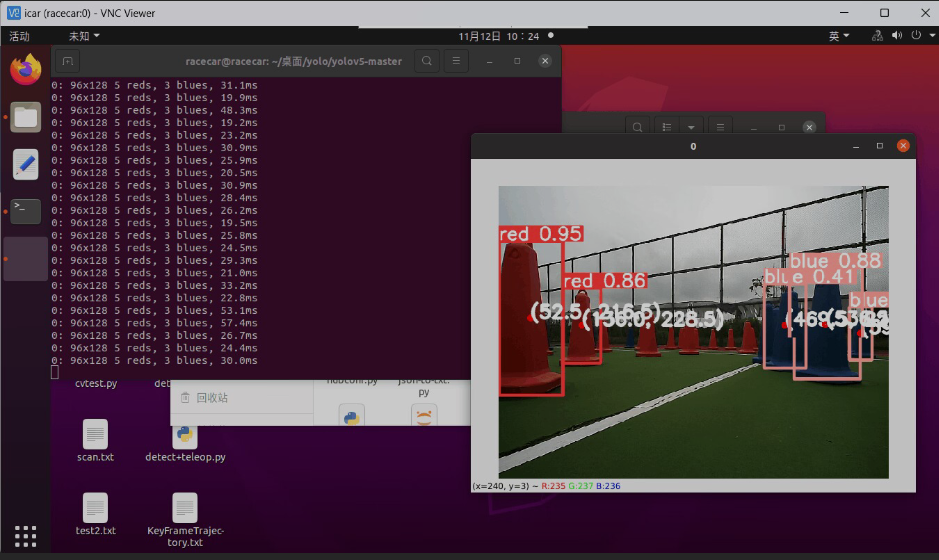
(四)技术栈
- 识别模型:yolov5
- 标注工具:labelmaster
- 运行环境:Ubuntu20.04
- 加速方式:使用onnx及tensorrt将模型进行推理加速
(五)识别类别
- 0: red 红色锥桶
- 1: blue 蓝色锥桶
- 2: stop 红绿灯(红灯)
- 3: wait 停车牌
(六)yolov5目标检测模型及其环境配置过程
第一步:下载yolov5源码
https://github.com/ultralytics/yolov5
第二步:解压源码压缩包
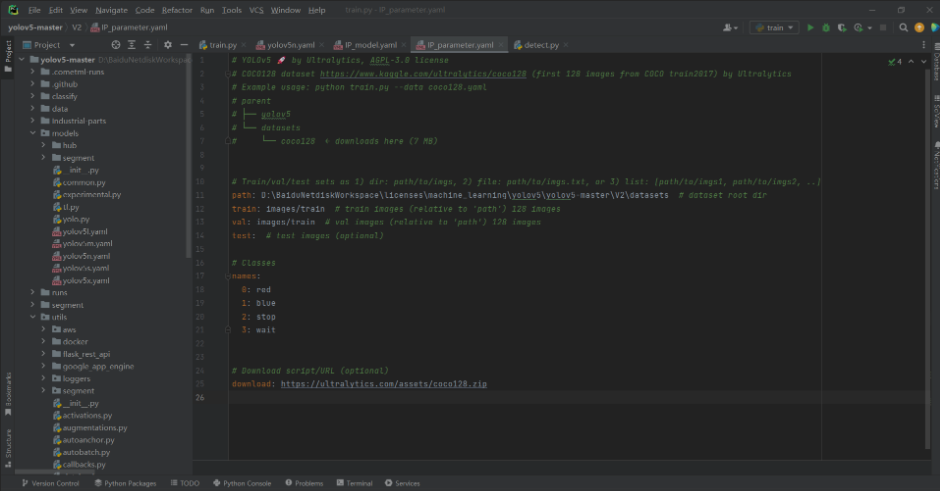
第三步:在代码编辑器 pycharm/vscode 中打开源码文件夹(配置完成)
(七)训练数据、测试数据采集

第一步:打开 ROS 智能车摄像头
终端输入 cheese
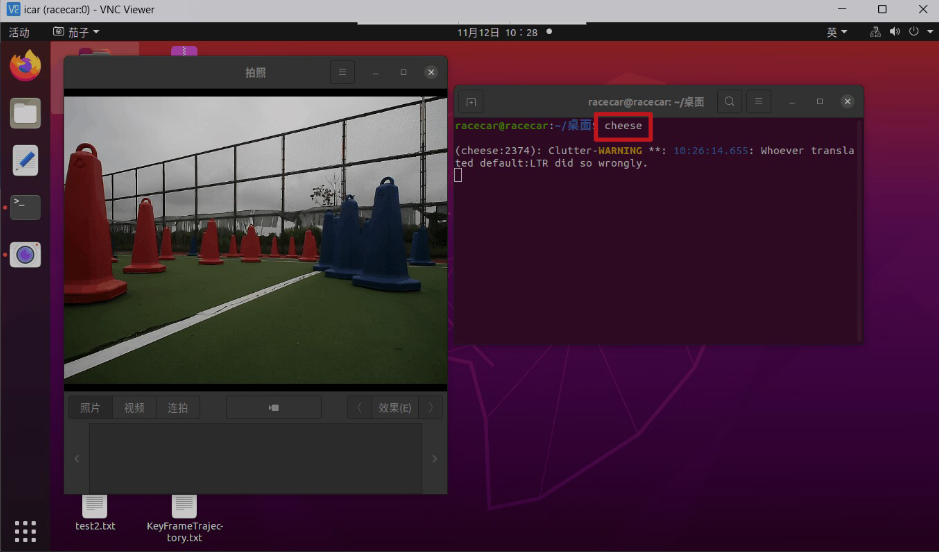
第二步:点击拍摄按键,采集数据集图片
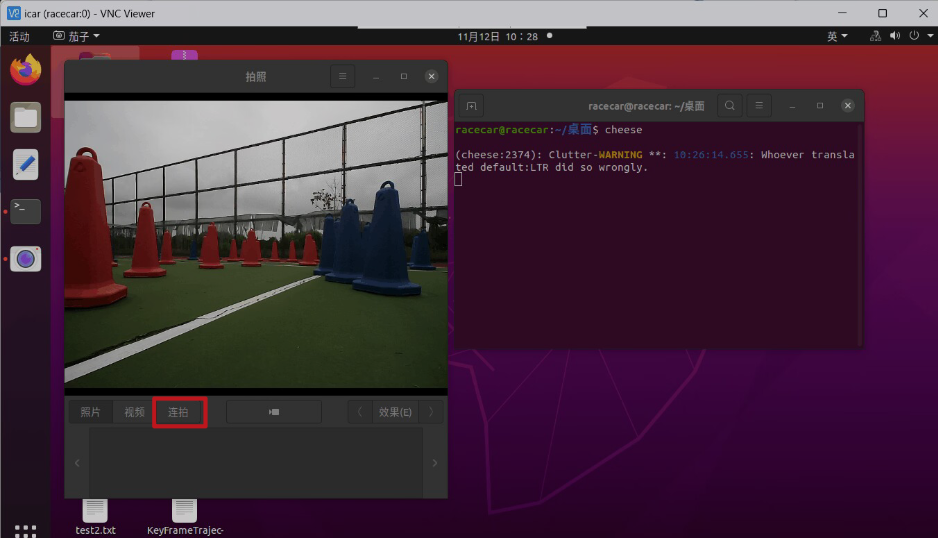
第三步:将无人车上的照片拷贝到电脑上,为数据标注做准备
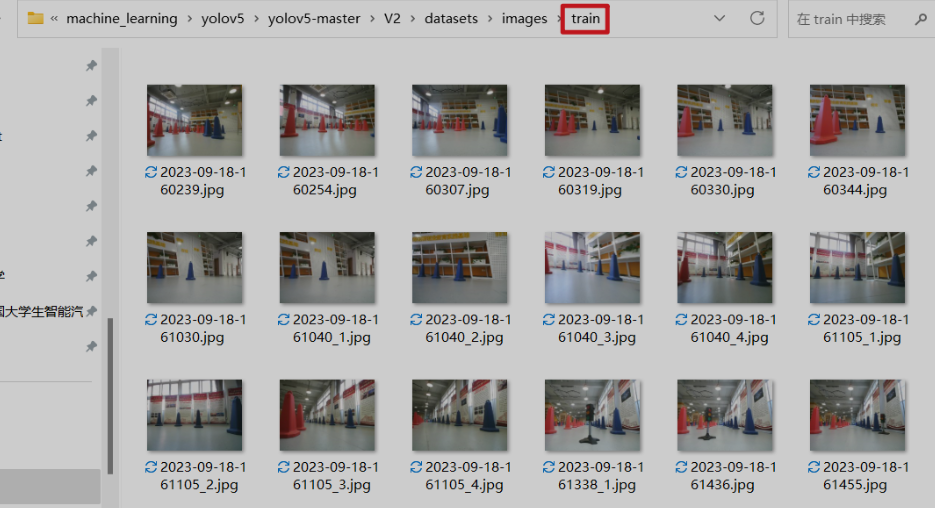
(八)训练数据、测试数据标注、整理
第一步:安装 labelmaster 库
pip install labelImg

第二步:启动 labelmaster
labelImg

第三步:打开采集图片的保存路径

第四步:鼠标右键图片,创建区块标注
左侧选择创建区块

鼠标移至目标的左上角

点击鼠标并拉直右下角

在出现的框里面选择自己标注目标的分类
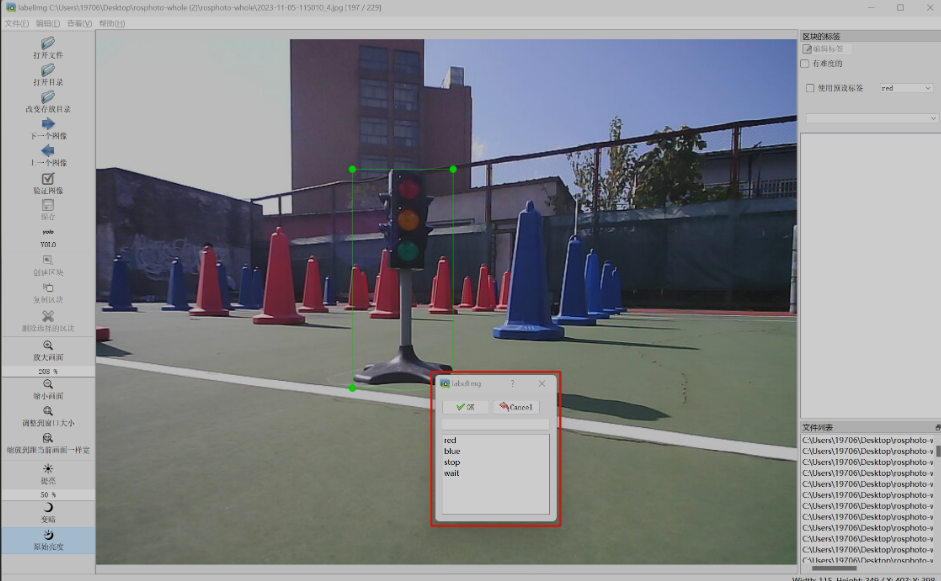
键入新的分类,则会自动生成一个新的分类
这边选择wait的红绿灯分类
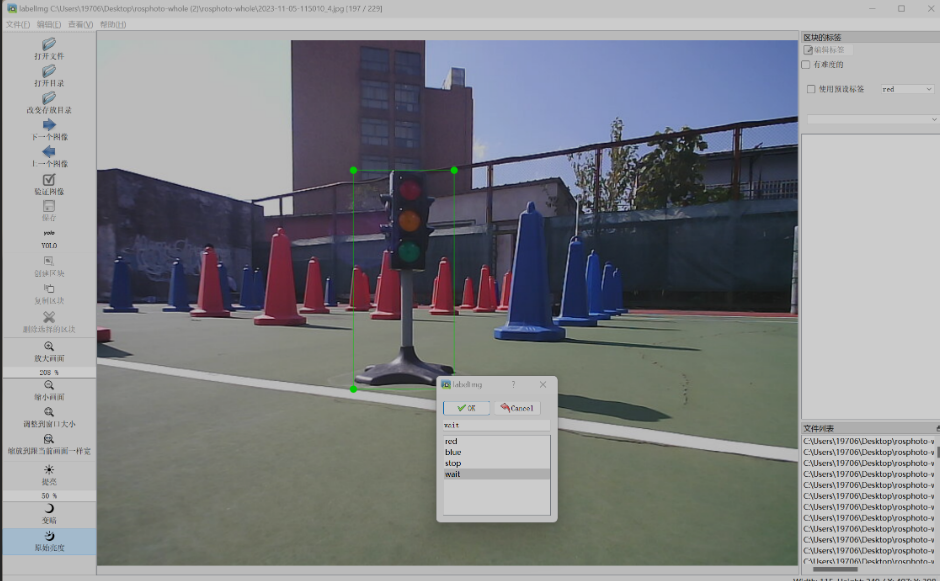
左键单击 ok 键
完成单个目标的标注

其他类别同样操作,只是分类时选择不同分类
依次按照识别类别对其余区块进行标注
例如下图选择red的红色锥桶分类

全部完成后左上角点击“改变保存目录”
选择保存的目标文件夹
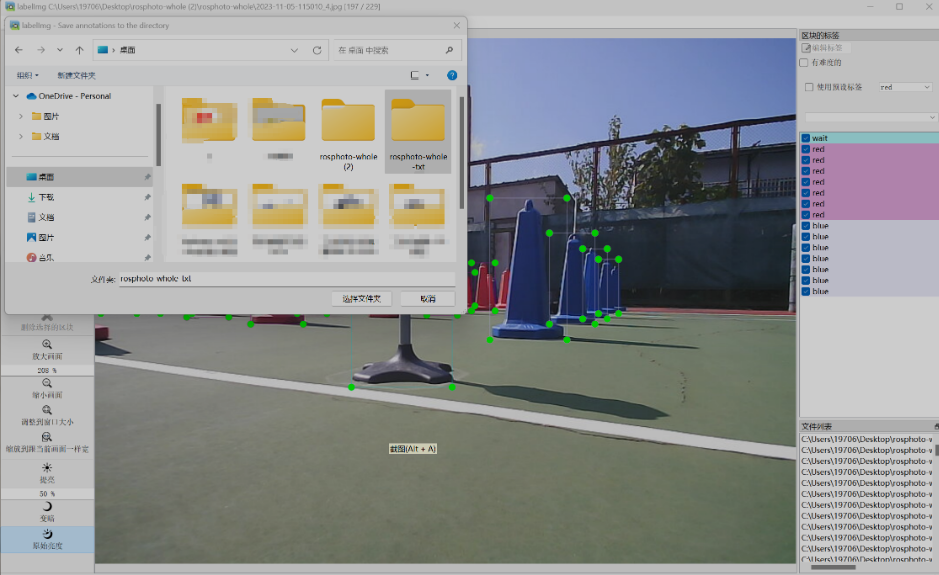
第五步:保存标注参数,保存为 .txt 文件后缀
点击保存下方的按键,改变保存的文件格式,保存为 .txt 文件后缀
“yolo”对应的是“txt”文件
“PascalVOC”对应的是“xml”文件
“CreatelML”对应的是“json”文件
最后单击保存完成标注
此时,保存的文件夹中会自动生成一个 class.txt 文件
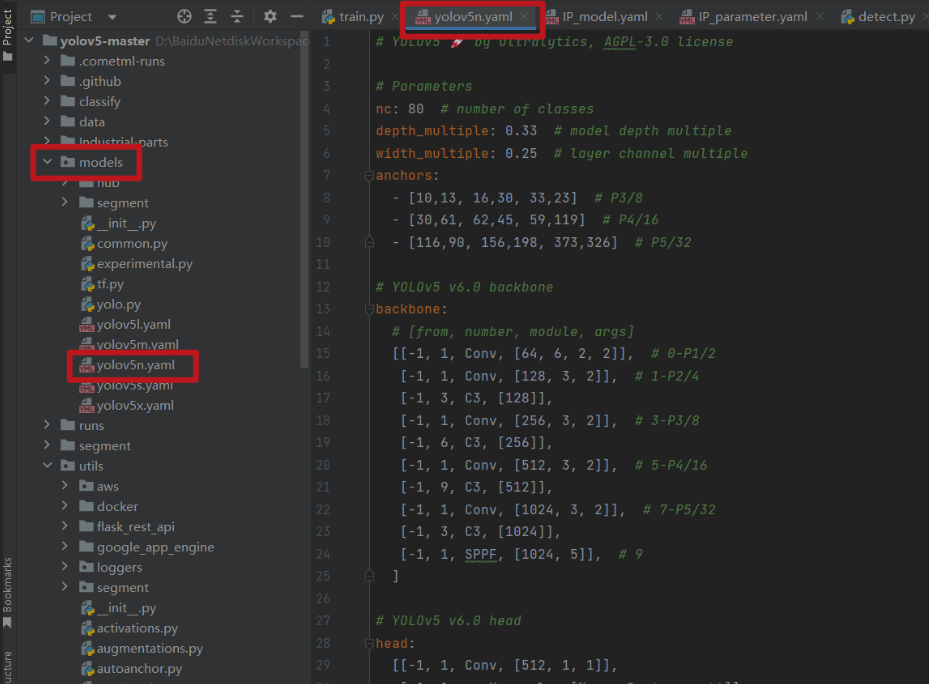
(九)模型训练过程
为了减小最终模型保存的大小,保证无人车整体运行的流程性,我们选用 yolov5n.yaml 的参数作为样本
源码:yolov5n.yaml
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
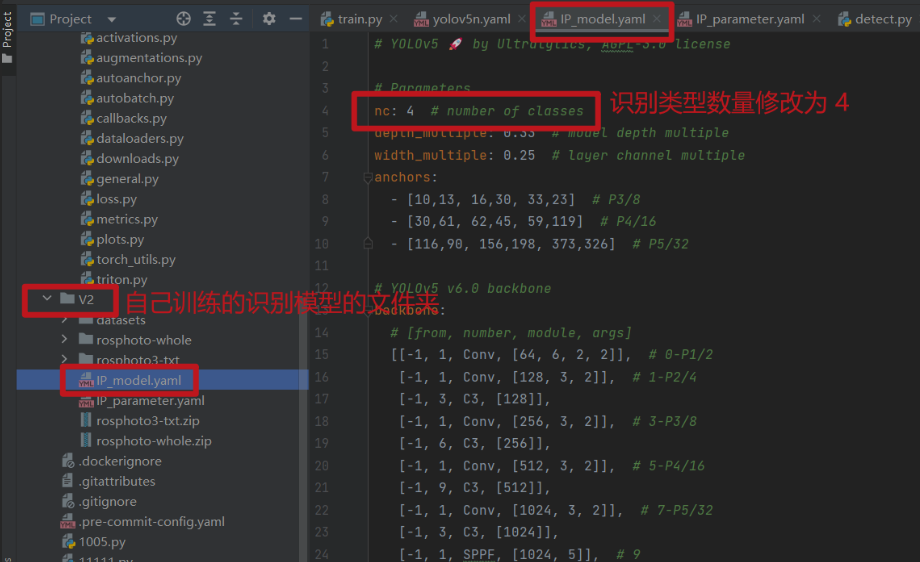
第一步:配置识别模型参数
① IP_model.yaml(在 yolov5n.yaml 基础上进行修改)
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
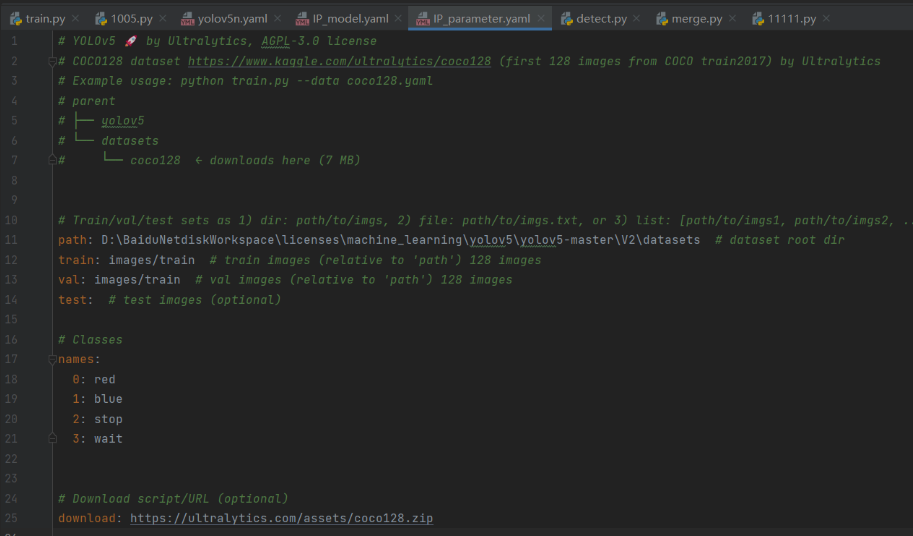
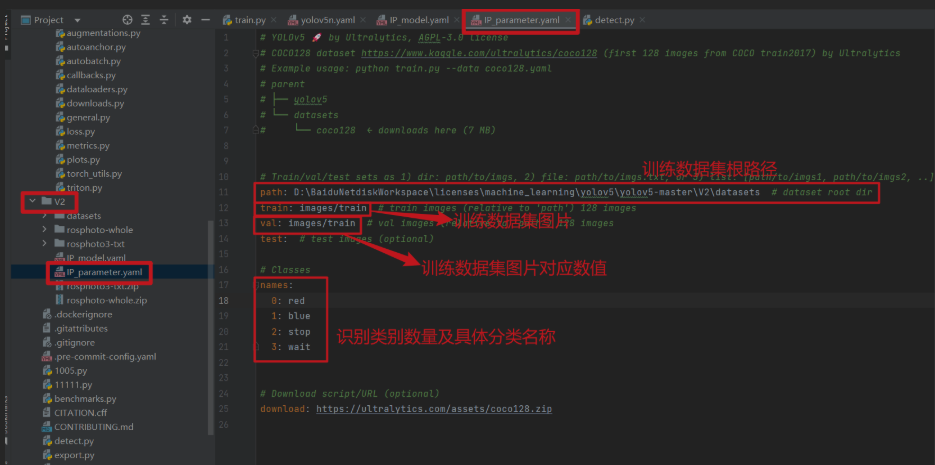
② IP_parameter.yaml(模型训练以及模型保存路径等参数设置)
path: D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterV2datasets # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/train # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: red
1: blue
2: stop
3: wait
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
第二步:编写模型训练代码
train.py
import argparse
import math
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
import random
import subprocess
import sys
import time
from copy import deepcopy
from datetime import datetime
from pathlib import Path
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.optim import lr_scheduler
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
import val as validate # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.dataloaders import create_dataloader
from utils.downloads import attempt_download, is_url
from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer,
yaml_save)
from utils.loggers import Loggers
from utils.loggers.comet.comet_utils import check_comet_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve
from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
smart_resume, torch_distributed_zero_first)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
GIT_INFO = check_git_info()
def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze =
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg,
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
callbacks.run('on_pretrain_routine_start')
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
opt.hyp = hyp.copy() # for saving hyps to checkpoints
# Save run settings
if not evolve:
yaml_save(save_dir / 'hyp.yaml', hyp)
yaml_save(save_dir / 'opt.yaml', vars(opt))
# Loggers
data_dict = None
if RANK in {-1, 0}:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Process custom dataset artifact link
data_dict = loggers.remote_dataset
if resume: # If resuming runs from remote artifact
weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
# Config
plots = not evolve and not opt.noplots # create plots
cuda = device.type != 'cpu'
init_seeds(opt.seed + 1 + RANK, deterministic=True)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = {0: 'item'} if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
amp = check_amp(model) # check AMP
# Freeze
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
# v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz, amp)
loggers.on_params_update({'batch_size': batch_size})
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
# Scheduler
if opt.cos_lr:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
else:
lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in {-1, 0} else None
# Resume
best_fitness, start_epoch = 0.0, 0
if pretrained:
if resume:
best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
del ckpt, csd
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning(
'WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.n'
'See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started.'
)
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# Trainloader
train_loader, dataset = create_dataloader(train_path,
imgsz,
batch_size // WORLD_SIZE,
gs,
single_cls,
hyp=hyp,
augment=True,
cache=None if opt.cache == 'val' else opt.cache,
rect=opt.rect,
rank=LOCAL_RANK,
workers=workers,
image_weights=opt.image_weights,
quad=opt.quad,
prefix=colorstr('train: '),
shuffle=True,
seed=opt.seed)
labels = np.concatenate(dataset.labels, 0)
mlc = int(labels[:, 0].max()) # max label class
assert mlc = accumulate:
scaler.unscale_(optimizer) # unscale gradients
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in {-1, 0}:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%11s' * 2 + '%11.4g' * 5) %
(f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', model, ni, imgs, targets, paths, list(mloss))
if callbacks.stop_training:
return
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in {-1, 0}:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
if not noval or final_epoch: # Calculate mAP
results, maps, _ = validate.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
half=amp,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
stop = stopper(epoch=epoch, fitness=fi) # early stop check
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'opt': vars(opt),
'git': GIT_INFO, # {remote, branch, commit} if a git repo
'date': datetime.now().isoformat()}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if opt.save_period > 0 and epoch % opt.save_period == 0:
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# EarlyStopping
if RANK != -1: # if DDP training
broadcast_list = [stop if RANK == 0 else None]
dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
if RANK != 0:
stop = broadcast_list[0]
if stop:
break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in {-1, 0}:
LOGGER.info(f'n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'nValidating {f}...')
results, _, _ = validate.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=plots,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
callbacks.run('on_train_end', last, best, epoch, results)
torch.cuda.empty_cache()
return results
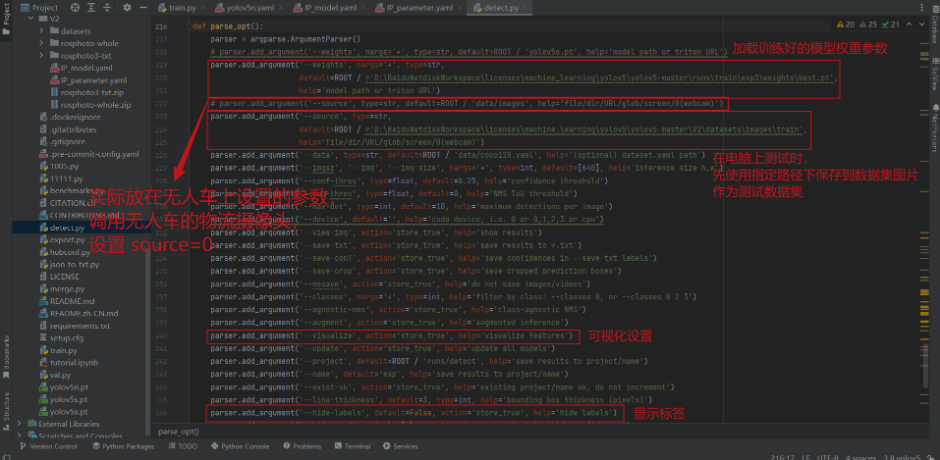
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / r'yolov5n.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'D:/BaiduNetdiskWorkspace/licenses/machine_learning/yolov5/yolov5-master/V2/IP_model.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'D:/BaiduNetdiskWorkspace/licenses/machine_learning/yolov5/yolov5-master/V2/IP_parameter.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=-1, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=256, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help服务器托管网='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=6, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if LOCAL_RANK, 'insufficient CUDA devices for DDP command'
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
# Train
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
# Evolve hyperparameters (optional)
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
meta = {
'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
if opt.noautoanchor:
del hyp['anchors'], meta['anchors']
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
# download evolve.csv if exists
subprocess.run([
'gsutil',
'cp',
f'gs://{opt.bucket}/evolve.csv',
str(evolve_csv),])
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.load服务器托管网txt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) 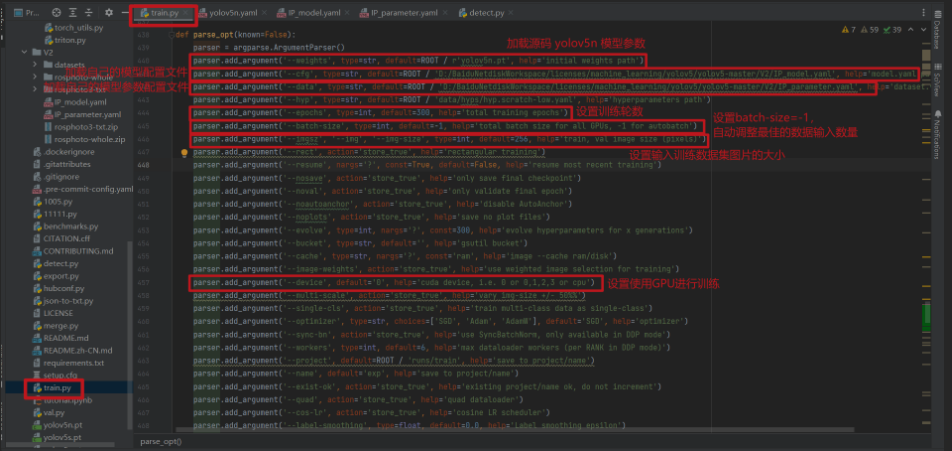
(十)模型推断过程的程序编写
第一部分:编写 detect.py
import argparse
import os
import platform
import sys
from pathlib import Path
import torch
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, smart_inference_mode
@smart_inference_mode()
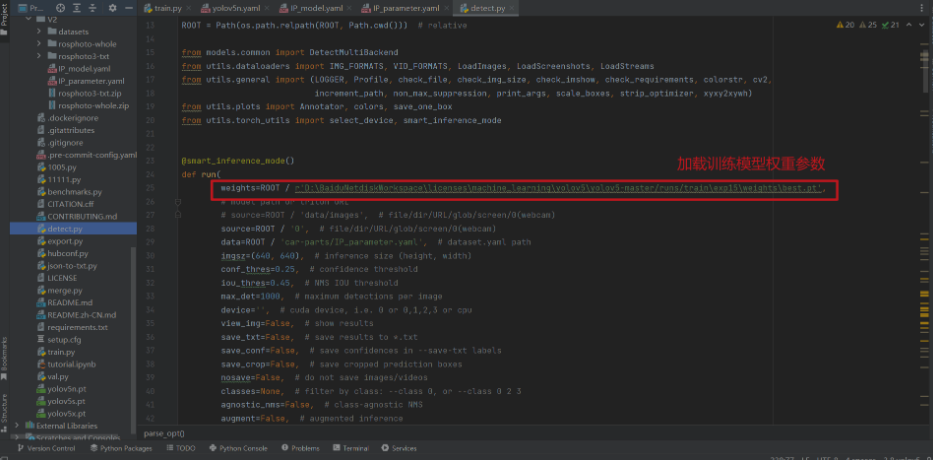
def run(
weights=ROOT / r'D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterrunstrainexp15weightsbest.pt',
# model path or triton URL
# source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
source=ROOT / '0', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'car-parts/IP_parameter.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
vid_stride=1, # video frame-rate stride
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# NMS
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
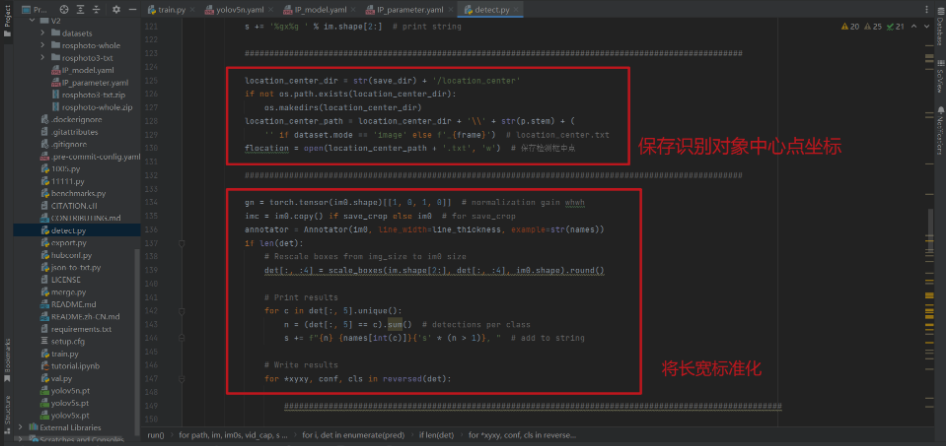
#####################################################################################################
location_center_dir = str(save_dir) + '/location_center'
if not os.path.exists(location_center_dir):
os.makedirs(location_center_dir)
location_center_path = location_center_dir + '\' + str(p.stem) + (
'' if dataset.mode == 'image' else f'_{frame}') # location_center.txt
flocation = open(location_center_path + '.txt', 'w') # 保存检测框中点
#####################################################################################################
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
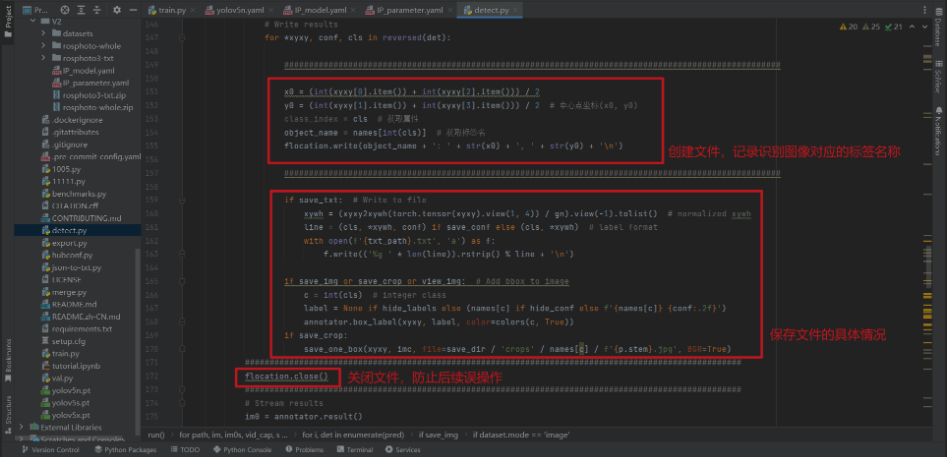
for *xyxy, conf, cls in reversed(det):
#####################################################################################################
x0 = (int(xyxy[0].item()) + int(xyxy[2].item())) / 2
y0 = (int(xyxy[1].item()) + int(xyxy[3].item())) / 2 # 中心点坐标(x0, y0)
class_index = cls # 获取属性
object_name = names[int(cls)] # 获取标签名
flocation.write(object_name + ': ' + str(x0) + ', ' + str(y0) + 'n')
#####################################################################################################
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + 'n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
#####################################################################################################
flocation.close()
#####################################################################################################
# Stream results
im0 = annotator.result()
if view_img:
if platform.system() == 'Linux' and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
# Print results
t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
# parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--weights', nargs='+', type=str,
default=ROOT / r'D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterrunstrainexp3weightsbest.pt',
help='model path or triton URL')
# parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--source', type=str,
default=ROOT / r'D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterV2datasetsimagestrain',
help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=10, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == '__main__':
opt = parse_opt()
main(opt)
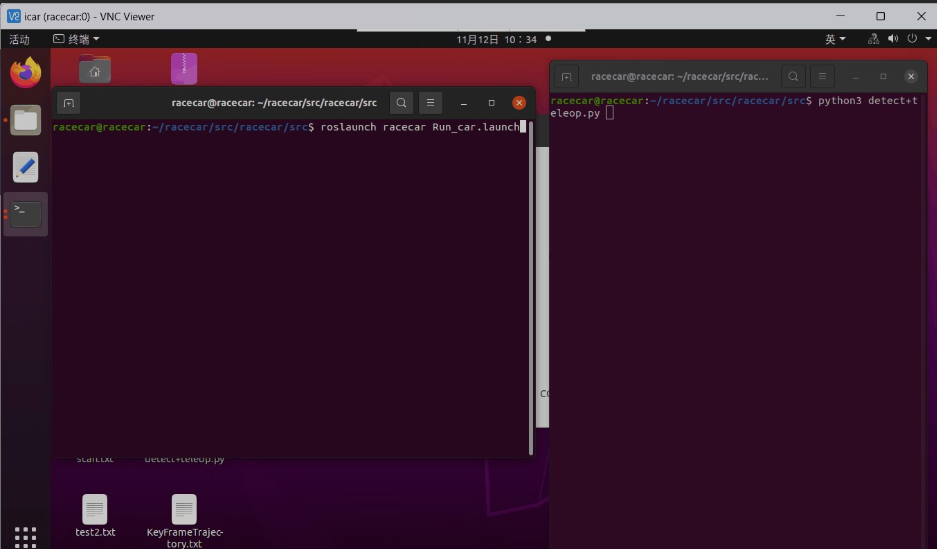
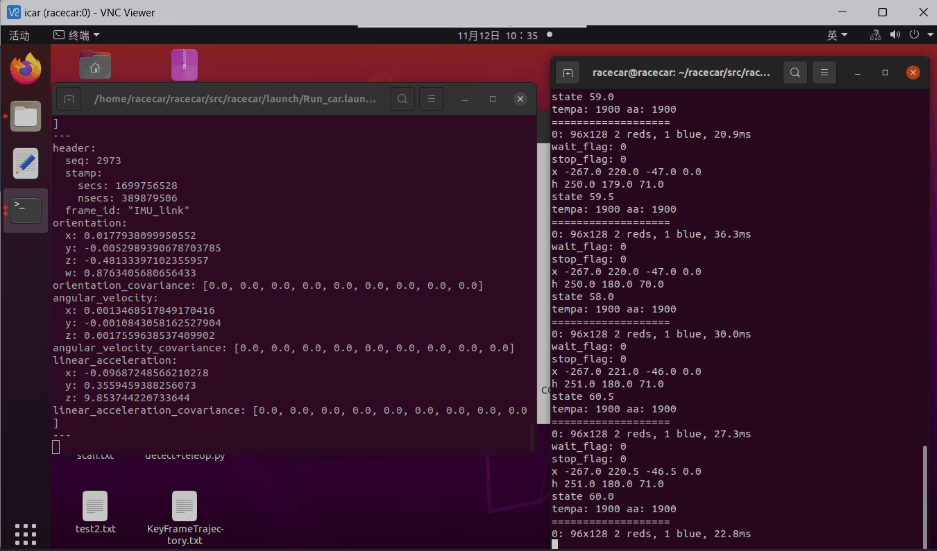
第二部分:在无人车终端运行代码,调用物理摄像头,查看具体效果

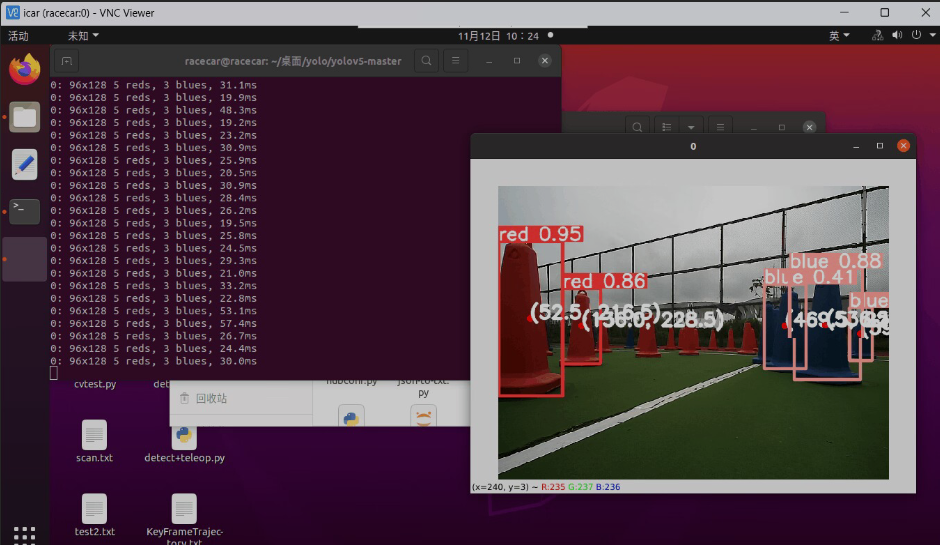
(十一)使用onnx及TensorRT将模型进行推理加速
第一步:将pt模型转化为onnx模型
① 安装onnx
pip install onnx

pip install onnxruntime

② 使用 export.py 导出模型为ONNX
python export.py --weights D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterrunstrainexp3weightsbest.pt --img-size 640 --batch-size 1 --include onnx


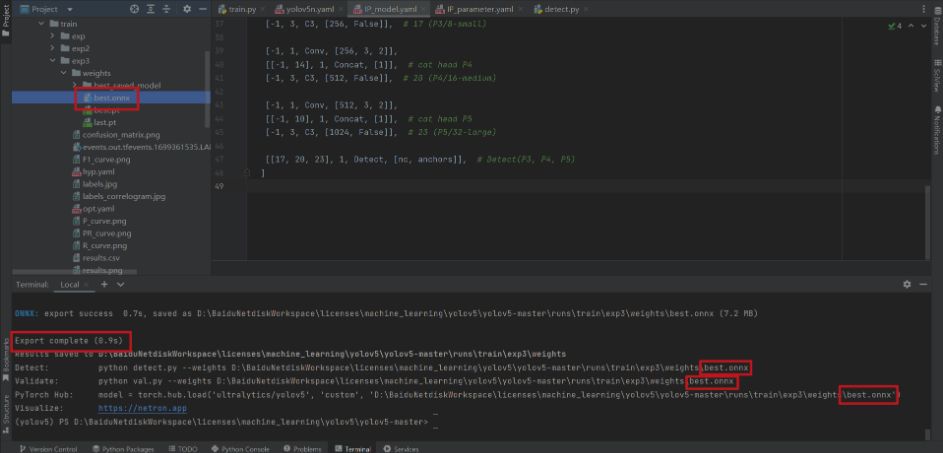
第二步:TensorRT环境安装及配置
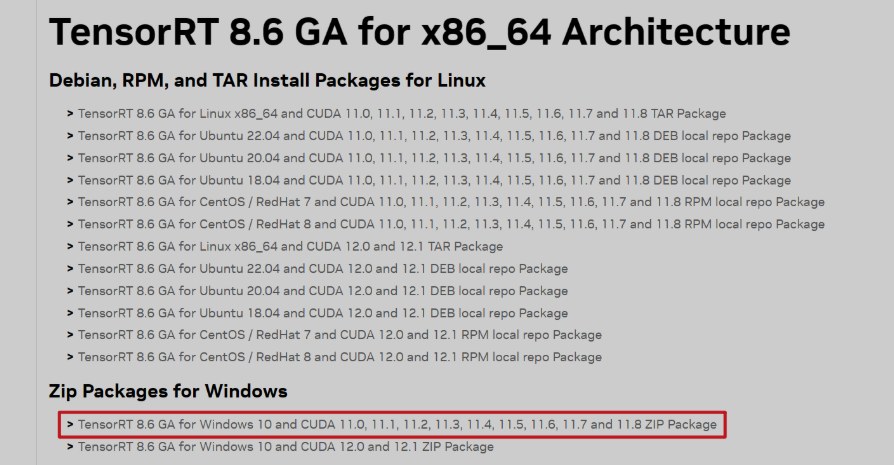
① 下载对应TensorRT版本
https://developer.nvidia.com/nvidia-tensorrt-8x-download
② 解压 TensorRT
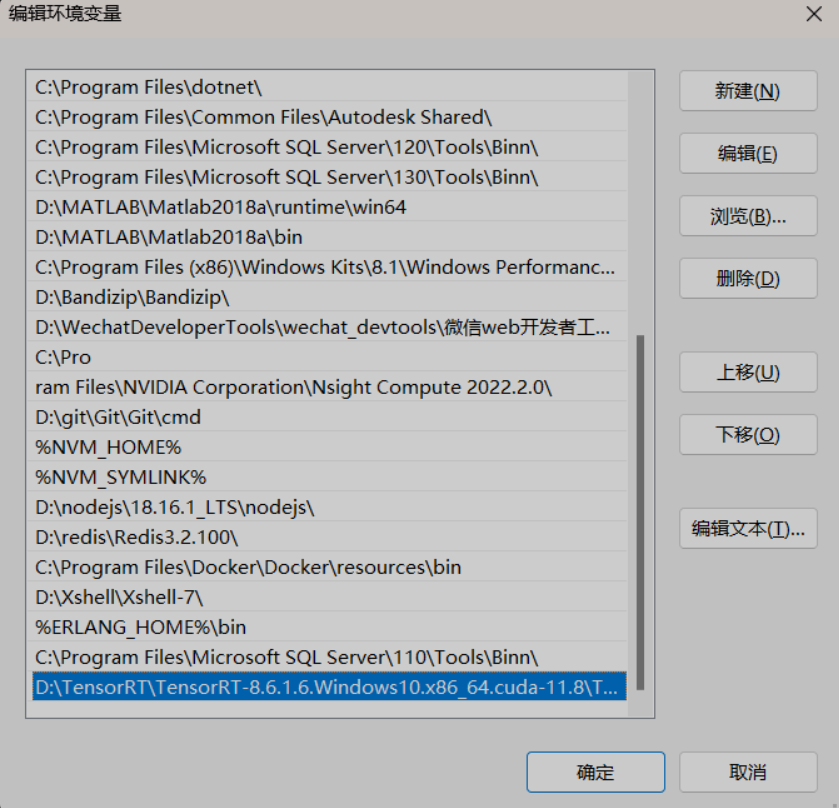
③ 配置环境变量
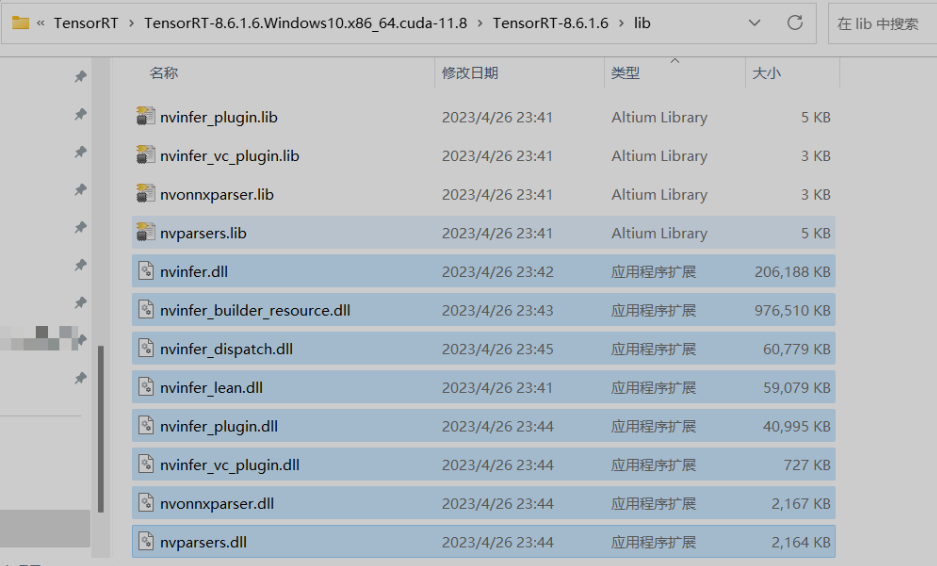
将TensorRT解压位置lib 加入系统环境变量
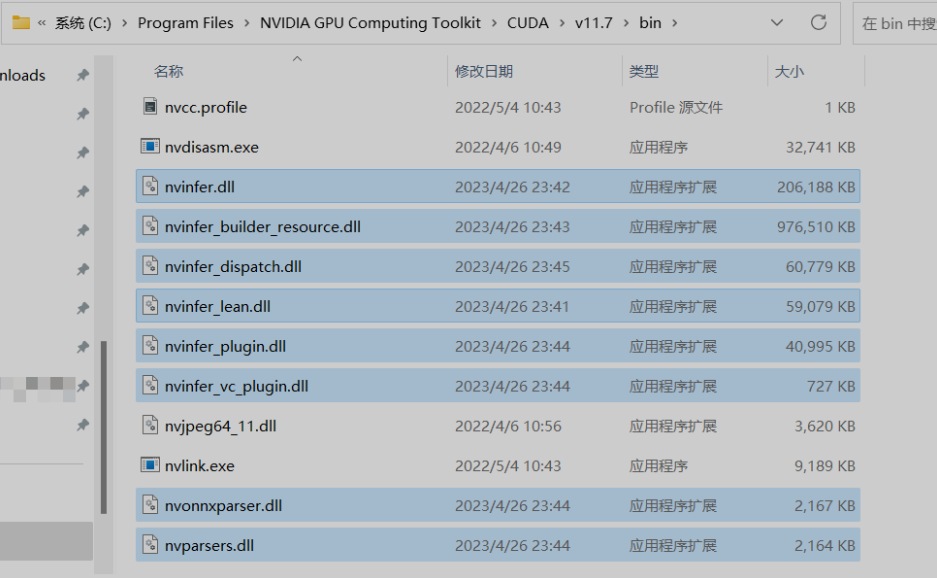
将TensorRT解压位置lib下的dll文件复制到C:Program FilesNVIDIA GPU Computing ToolkitCUDAv11.7bin目录下
④ 测试示例代码
用VS2019打开sampleOnnxMNIST示例(D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6samplessampleOnnxMNIST)
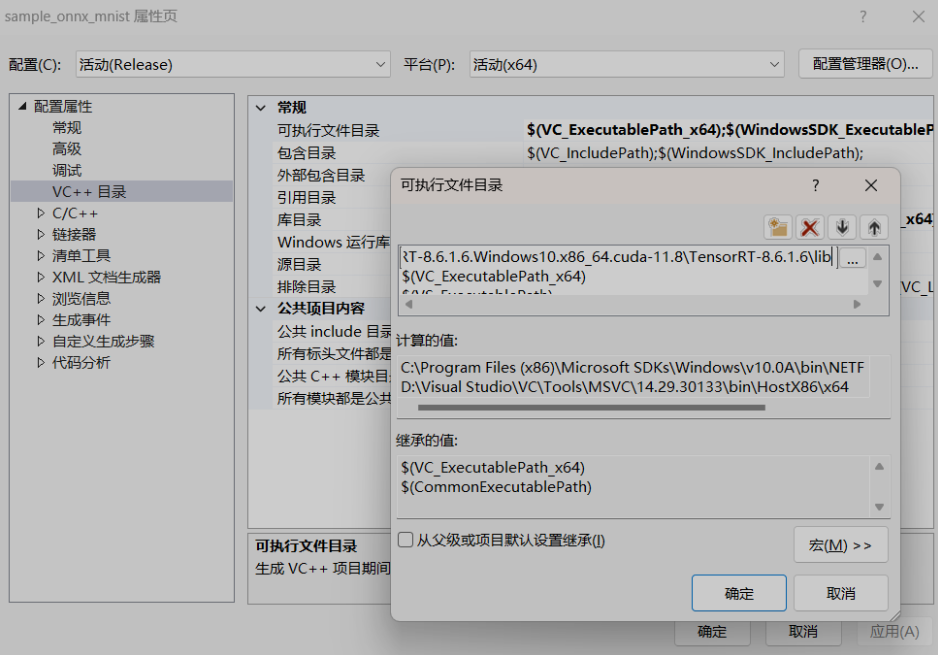
将D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6lib加入 VC++目录–>可执行文件目录
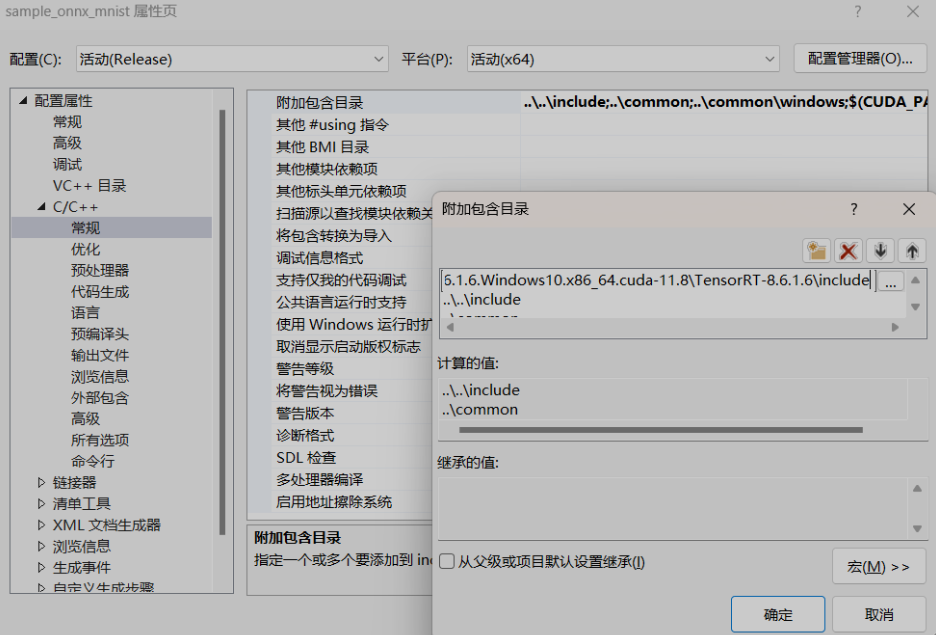
将D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6include加入C/C++ –> 常规 –> 附加包含目录
将D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6lib加入 VC++目录–>库目录
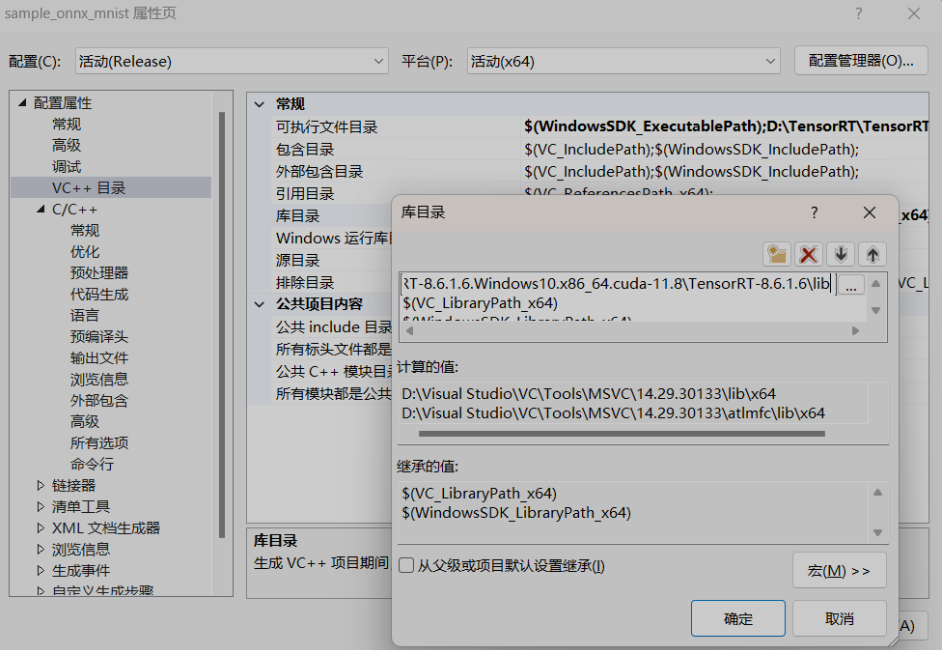
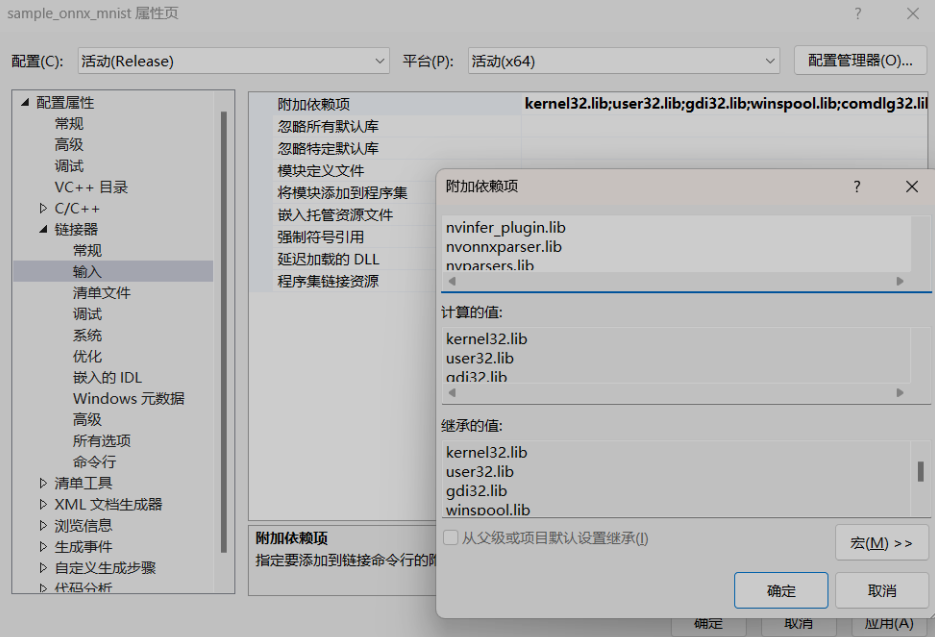
将nvinfer.lib、nvinfer_plugin.lib、nvonnxparser.lib和nvparsers.lib加入链接器–>输入–>附加依赖项
⑤ 安装 pycuda
https://www.lfd.uci.edu/~gohlke/pythonlibs/?cm_mc_uid=08085305845514542921829&cm_mc_sid_50200000=1456395916&cm_mc_uid=08085305845514542921829&cm_mc_sid_50200000=1456395916#pycuda
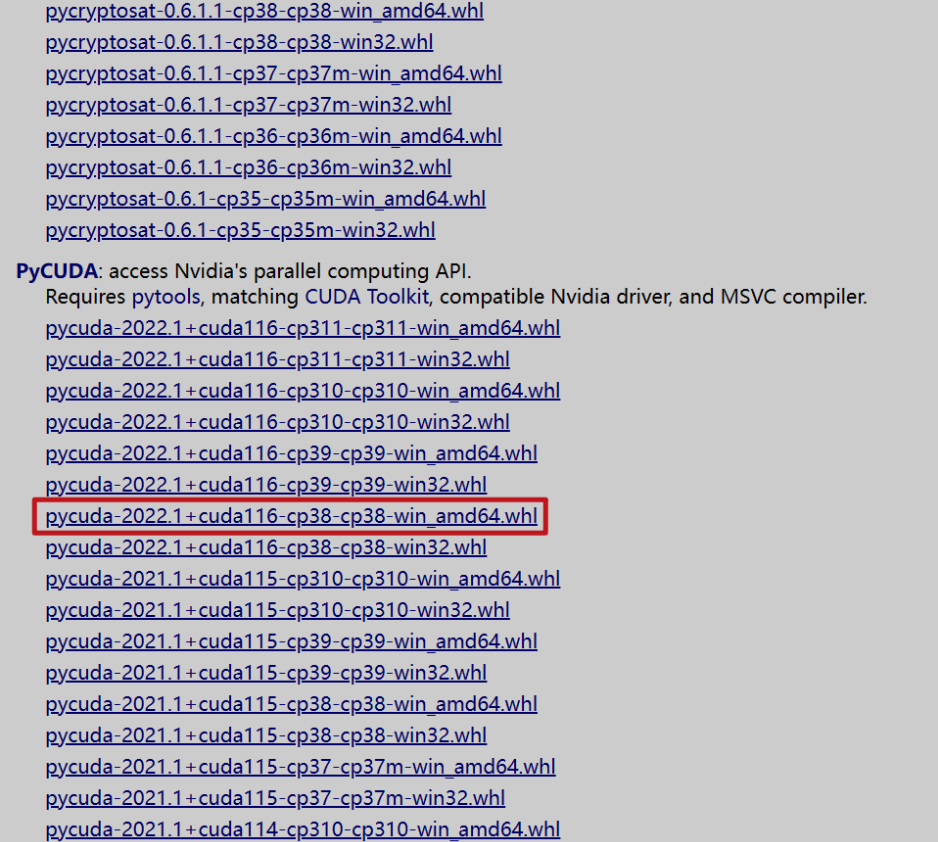
pip install "D:pycudapycuda-2022.1+cuda116-cp38-cp38-win_amd64.whl"


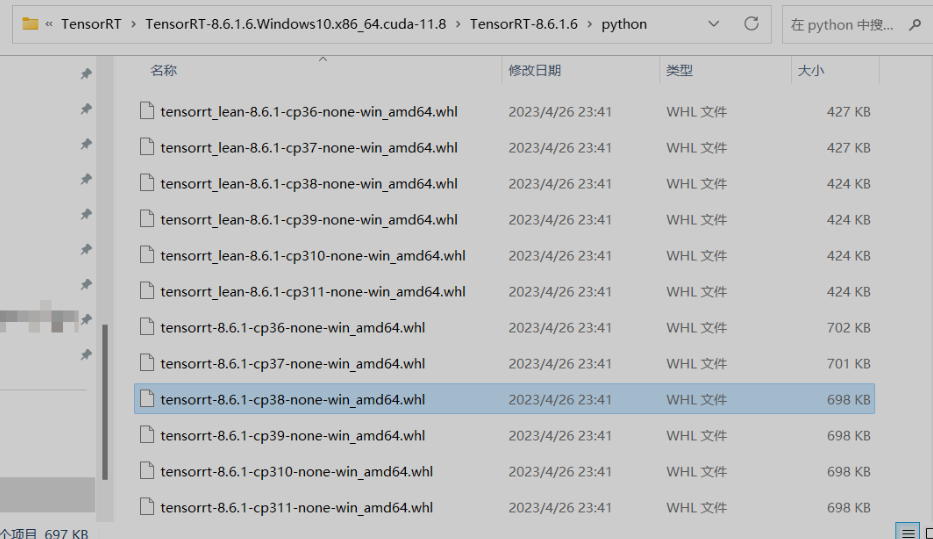
⑥ python 环境配置 TensorRT
pip install "D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6pythontensorrt-8.6.1-cp38-none-win_amd64.whl"

⑦ python 环境测试
python "D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6samplespythonnetwork_api_pytorch_mnistsample.py"

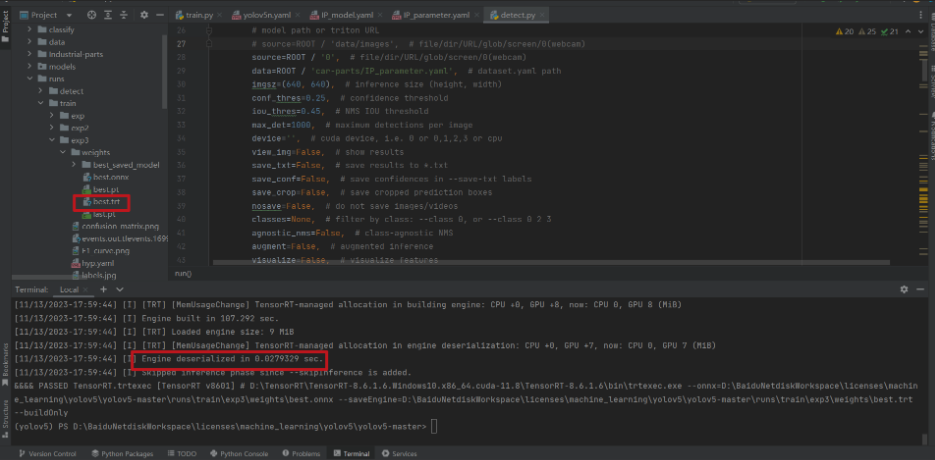
第三步:使用 TensorRT 编译 onnx 文件,转换成 .trt 后缀文件
D:TensorRTTensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8TensorRT-8.6.1.6bintrtexec.exe –onnx=D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterrunstrainexp3weightsbest.onnx –saveEngine=D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterrunstrainexp3weightsbest.trt –buildOnly

第四步:查看训练图片的维度
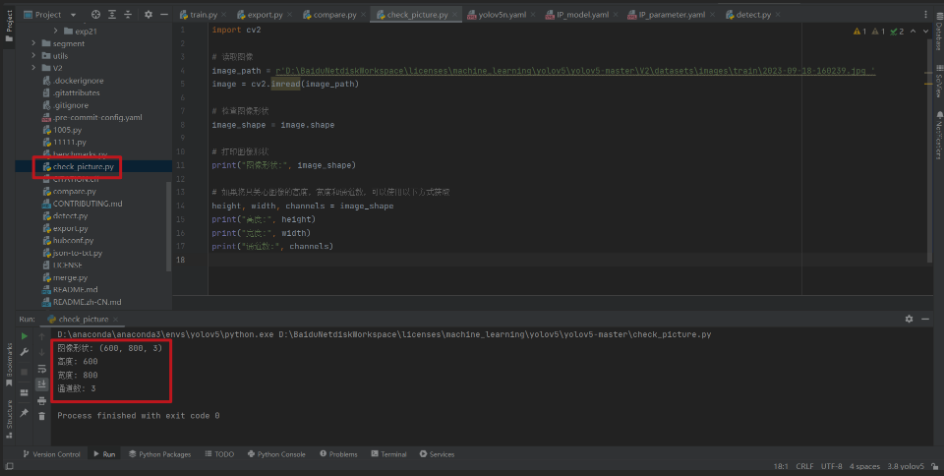
check_picture.py
import cv2
# 读取图像
image_path = r'D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterV2datasetsimagestrain2023-09-18-160239.jpg '
image = cv2.imread(image_path)
# 检查图像形状
image_shape = image.shape
# 打印图像形状
print("图像形状:", image_shape)
# 如果您只关心图像的高度,宽度和通道数,可以使用以下方式获取
height, width, channels = image_shape
print("高度:", height)
print("宽度:", width)
print("通道数:", channels)
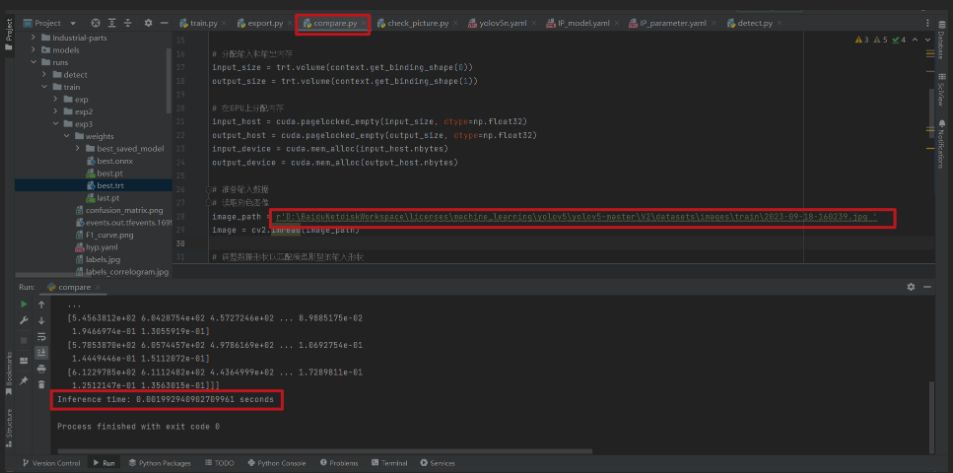
第五步:编写加速推理脚本
compare.py
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import cv2
import time
# 加载.trt文件
trt_file_path = r'D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterrunstrainexp3weightsbest.trt'
with open(trt_file_path, 'rb') as f, trt.Runtime(trt.Logger(trt.Logger.WARNING)) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
# 创建执行上下文
context = engine.create_execution_context()
# 分配输入和输出内存
input_size = trt.volume(context.get_binding_shape(0))
output_size = trt.volume(context.get_binding_shape(1))
# 在GPU上分配内存
input_host = cuda.pagelocked_empty(input_size, dtype=np.float32)
output_host = cuda.pagelocked_empty(output_size, dtype=np.float32)
input_device = cuda.mem_alloc(input_host.nbytes)
output_device = cuda.mem_alloc(output_host.nbytes)
# 准备输入数据
# 读取彩色图像
image_path = r'D:BaiduNetdiskWorkspacelicensesmachine_learningyolov5yolov5-masterV2datasetsimagestrain2023-09-18-160239.jpg '
image = cv2.imread(image_path)
# 调整数据形状以匹配模型期望的输入形状
input_data = image.astype(np.float32) / 255.0 # 归一化(假设模型期望的输入范围是 [0, 1])
# 使用cv2.resize调整图像大小
resized_image = cv2.resize(input_data, (640, 640))
input_data = np.transpose(resized_image, (2, 0, 1)) # 将通道移到正确的位置
input_data = np.expand_dims(input_data, axis=0) # 添加批处理维度
# 确保输入数据的长度与模型期望的输入大小一致
if input_data.size != input_size:
raise ValueError(f"Input data size ({input_data.size}) does not match the expected input size ({input_size})")
np.copyto(input_host, input_data.ravel())
cuda.memcpy_htod(input_device, input_host)
# 计时开始
start_time = time.time()
# 执行推理
context.execute_v2(bindings=[int(input_device), int(output_device)])
# 计时结束
end_time = time.time()
# 获取输出
cuda.memcpy_dtoh(output_host, output_device)
# 处理输出数据
result = output_host.reshape(context.get_binding_shape(1))
# 打印结果
print(result)
# 打印推理时间
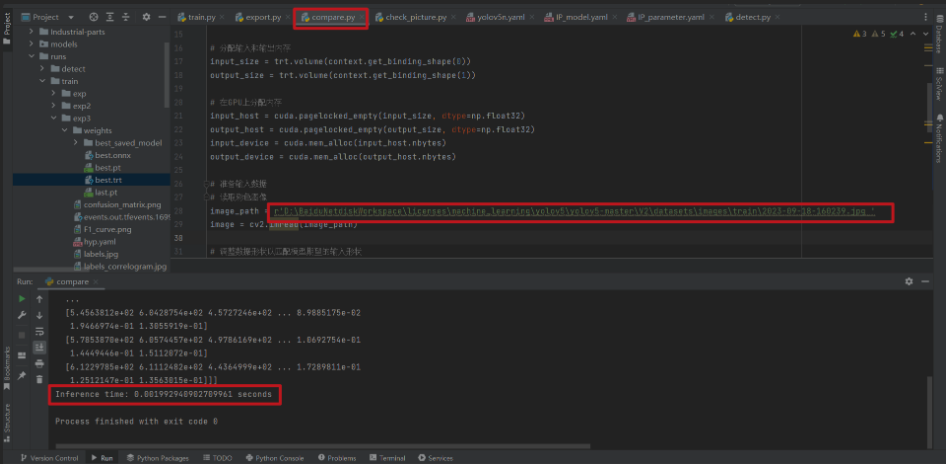
inference_time = end_time - start_time
print(f"Inference time: {inference_time} seconds")
第六步:对比测试
加速前
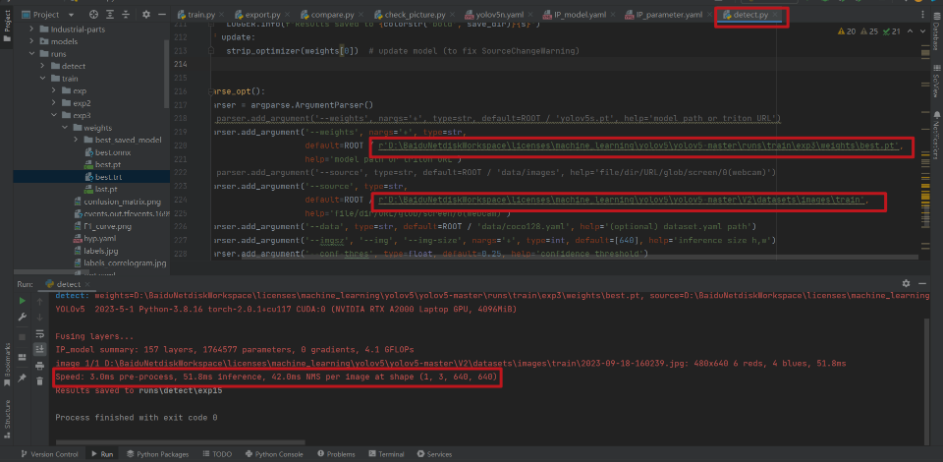
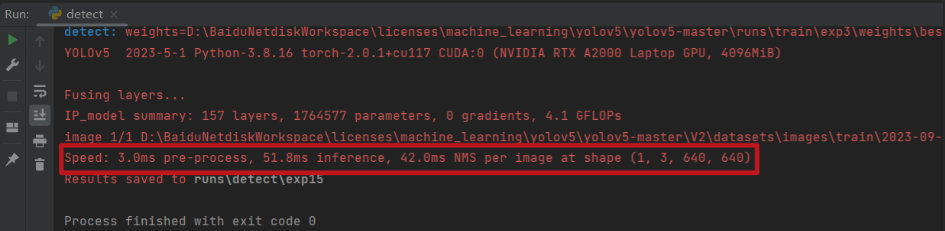
加速后
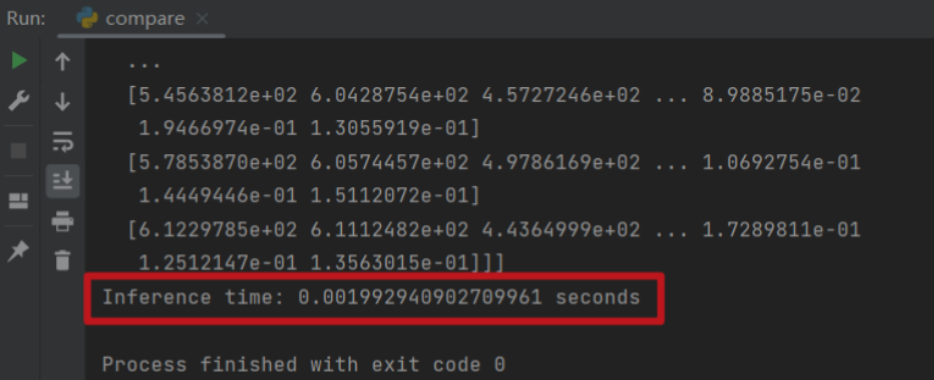
(十二)问题汇总
(1)error MSB8036:找不到 Windows SDK 版本……
参考链接
error MSB8036:找不到 Windows SDK 版本_microsoft.cpp.windowssdk.targe ts(46,5): error msb-CSDN博客
(2)too many values to unpack
参考链接
too many values to unpack (expected 4)_UC_Gundam的博客-CSDN博客
(3)运行示例时,提示找不到 MNIST数据
参考链接
TensorRT之安装与测试(Windows和Linux环境下安装TensorRT)_判断tensorrt是否可以正常使用-CSDN博客
(4)加载 libnvinfer.so.7报错
参考链接
TensorRT之安装与测试(Windows和Linux环境下安装TensorRT)_判断tensorrt是否可以正常使用-CSDN博客
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
