

本文内容包括但不限于:tcp四次挥手(同时关闭),tcp包的seq/ack号规则,tcp状态机,内核tcp代码,tcp发送窗口等知识。
问题是什么?
内核版本linux 5.10.112
一句话:四次挥手中,由于fin包和ack包乱序,导致等了一次timeout才关闭连接。
过程细节:
- 同时关闭的场景,server和client几乎同时向对方发送fin包。
- client先收到了server的fin包,并回传ack包。
- 然而server处发生乱序,先收到了client的ack包,后收到了fin包。
- 结果表现为server未能正确处理client的fin包,未能返回正确的ack包。
- client没收到(针对fin的)ack包,因此等待超时后重传fin包,之后才回归正常关闭连接的流程。
问题抓包具体分析
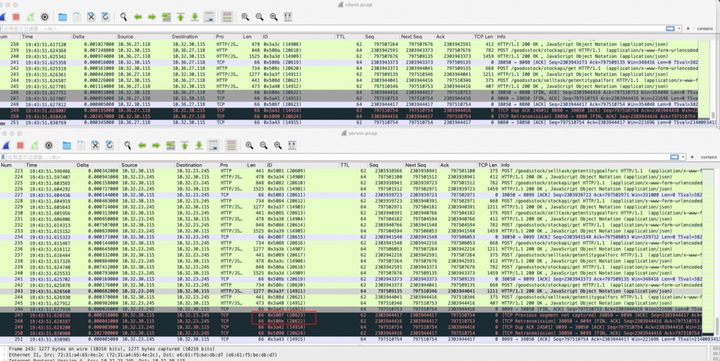
图中上半部分是client,下半部分是server。
重点关注id为14913,14914,20622,20623这四个包,后面为了方便分析,对seq和ack号取后四位:
- 20622(seq=4416,ack=753),client发送的fin包:client主动关闭连接,向server发送fin包;
- 14913(seq=753,ack=4416),server发送的fin包:server主动关闭连接,向client发送fin包;
- 20623(seq=4417,ack=754),client响应的ack包:client收到server的fin,响应一个ack包;
- 14914(seq=754,ack=4416),server发送的ack包;
问题发生在server处(红框位置),发送14913后:
- 先收到20623(seq=4417),但此时期望收到的seq为4416,所以被标记为[previous segment not captured]
- 然后收到20622,回传了一个ack包,id为14914,问题就出现在这里:这个数据包的ack=4416,这意味着server还在等待seq=4416的数据包,换言之,fin-20622没有被server真正接收到。
- client发现20622没有被正确接收,因此在等到timeout后,重新发送了fin包(id=20624),此后连接正常关闭。
(这里再次强调一下ack-20623和fin-20622,后面会经常提到这两个包)
首先,这个现象在直觉上是很不合理的,tcp应当有恰当的机制保证乱序恢复。这里20622和20623都已经到达了server,虽然发生了乱序,也不应当影响server把两者都接收,这是主要的疑问点所在。
经过初步分析,我们推测最可能的原因是20622被server的内核忽略了(原因目前未知)。既然是内核的行为,就先尝试在本地环境复现这个问题。然而喜闻乐见的没有成功。
新问题:尝试复现未成功
为了模拟上述乱序的场景,我们使用两台ecs,在client上伪造tcp包,与server处的正常socket通信。
server处的抓包结果如下:

注意看No.为5,6,7,8的包:
- 5: server向client发送fin(这里不知为何有一次重传,但是不影响后面的效果,没有深究)
- 6: client先传回了seq=1002的ack包
- 7: client后传回了seq=1001的fin包
- 8: server传回了ack=1002的ack包,ack=1002意味着client的fin包被正常接收了!(如果在问题场景下,此时回传的ack包,ack应当为1001)
之后,为了保持内核版本一致,把相同的程序转移到本地虚拟机上运行,得到同样的结果。换言之,复现失败了。
附:模拟程序代码
工具:python + scapy
这里用scapy伪造client,发送乱序的ack和fin,是为了观察server回传的ack包。因为client并未真的走了tcp协议,所以无论复现成功与否,都不能观察到超时重传。
(1)server处正常socket监听:
import socket
server_ip = "0.0.0.0"
server_port = 12346
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((server_ip, server_port))
server_socket.listen(5)
connection, client_address = server_socket.accept()
connection.close() #发送fin
server_socket.close()
(2)client模拟乱序:
from scapy.all import *
import time
import sys
target_ip = "略"
target_port = 12346
src_port = 1234
#伪造数据包,建立tcp连接
ip = IP(dst=target_ip)
syn = TCP(sport=src_port, dport=target_port, flags="S", seq=1000)
syn_ack = sr1(ip / syn)
if syn_ack and TCP in syn_ack and syn_ack[TCP].flags == "SA":
print("Received SYN-ACK")
ack = TCP(sport=src_port, dport=target_port,
flags="A", seq=syn_ack.ack, ack=syn_ack.seq+1)
send(ip / ack)
print("Sent ACK")
else:
print("Failed to establish TCP connection")
def handle_packet(packet):
if TCP in packet and packet[TCP].flags & 0x01:
print("Received FIN packet") #若收到server的fin,先传ack,再传fin
ack = TCP(sport=src_port, dport=target_port,
flags="A", seq=packet.ack+1, ack=packet.seq+1)
send(ip / ack)
time.sleep(0.1)
fin = TCP(sport=src_port, dport=target_port,
flags="FA", seq=packet.ack, ack=packet.seq)
send(ip / fin)
sys.exit(0)
sniff(prn=handle_packet)
问题出现的位置?
server处出现乱序,结果连接未能正常关闭,而是等到client超时重传fin包,才关闭连接。
问题带来什么影响?
server处连接关闭的时间变长了(额外增加200ms),对时延敏感的场景影响明显。
本文要解决什么问题?
- 该现象是否是内核的合法行为?(先剧透一下,是合法行为)
- 为什么本地复现失败了?
问题排查
经过了大约6个周末的间断式[看代码-试验]循环,终于找到了问题所在!下面将简要描述问题排查的过程,也包括我们的一些失败尝试。
初步分析
回到上面的问题,现在不仅不清楚问题原因,本地复现还完美符合理想情况。简单来说:
- 本地复现-乱序不影响挥手;
- 问题场景-乱序导致超时重传。
可以确定,问题很大概率出现在server对ack-20623和fin-20622的处理上。
(下面会以ack-20623和fin-20622代指乱序的ack和fin包)
关键在于:server发送fin后(进入FIN_WAIT_1状态),对后面收到的乱序ack-20623和fin-20622是如何处理的。这里涉及到tcp的状态转移,所以,首要问题是确定其中的状态转移过程。之后才能根据状态转移锁定对应的代码片段,做具体分析。
确定状态转移
由于问题发生在挥手过程中,很自然想到通过观察状态转移来判断数据包的接收/处理情况。
我们结合复现过程,利用ss和ebpf,监控tcp的状态变化。确定了server在收到ack-20623后,由FIN_WAIT_1进入了FIN_WAIT_2状态,这意味着ack-20623被正确处理了。那么问题大概率出现在fin-20622的处理上,这也证实了我们最初的猜测。
这里还有一个奇怪的点:按照正确的挥手流程,server在FIN_WAIT_2收到fin后应当进入TIMEWAIT状态。我们在ss中观察到了这个状态转移,但是使用ebpf监控时,并没有捕捉到这个状态转移。当时我们并未关注这个问题,后来才知晓原因:ebpf实现中,只记录tcp_set_state()引发的状态转移。而此处虽然进入了TIMEWAIT状态,却并未经过tcp_set_state(),因此ebpf中无法看到。关于这里如何进入TIMEWAIT,请看末尾的“番外”一节。
附:ebpf监控结果
(FIN_WAIT1转移到FIN_WAIT2时,snd_una有更新,确定ack-20623被正确处理了)
-0 [000] d.s. 42261.233642: PASSIVE_ESTABLISHED: start monitor tcp state change
-0 [000] d.s. 42261.233651: port:12346,snd_nxt:154527568,snd_una:154527568
-0 [000] d.s. 42261.233652: rcv_nxt:1001,recved:0,acked:0
-9451 [007] d... 42261.233808: changing from ESTABLISHED to FIN_WAIT1
-9451 [007] d... 42261.233815: port:12346,snd_nxt:154527568,snd_una:154527568
-9451 [007] d... 42261.233816: rcv_nxt:1001,recved:0,acked:0
-0 [000] dNs. 42261.464578: changing from FIN_WAIT1 to FIN_WAIT2
-0 [000] dNs. 42261.464588: port:12346,snd_nxt:154527569,snd_una:154527569
-0 [000] dNs. 42261.464589: rcv_nxt:1001,recved:0,acked:1
内核源码分析
事已至此,不得不看一看内核源码了。结合上面的分析,问题大概率发生在 tcp_rcv_state_process() 函数中,抽取出其中关于TCP_FIN_WAIT2的片段,然而很遗憾,在这个片段中没有发现疑点:
(tcp_rcv_state_process是接收数据包时处理状态转移的函数,位于net/ipv4/tcp_input.c)
case TCP_FIN_WAIT1:
case TCP_FIN_WAIT2:
/* RFC 793 says to queue data in these states,
* RFC 1122 says we MUST send a reset.
* BSD 4.4 also does reset.
*/
if (sk->sk_shutdown & RCV_SHUTDOWN) {
if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq &&
after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { //经过分析,不符合该条件
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
tcp_reset(sk);
return 1;
}
}
fallthrough;
case TCP_ESTABLISHED:
tcp_data_queue(sk, skb); //如果进入了这个函数,乱序会被纠正,fin的处理也在该函数中
queued = 1;
break;
如果运行到了这里,基本可以确定fin会被正常处理,所以我们将这个位置作为我们检查的终点。也就是说,乱序的fin-20622应当是没有成功到达此处的。我们从这个位置开始,向前查找,找到了一个非常可疑的位置,同样是在tcp_rcv_state_process中。
//检查ack值是否合法
acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH |
FLAG_UPDATE_TS_RECENT |
FLAG_NO_CHALLENGE_ACK) > 0;
if (!acceptable) { //如果不合法
if (sk->sk_state == TCP_SYN_RECV) //挥手过程中不会进入这个分支
return 1; /* send one RST */
tcp_send_challenge_ack(sk, skb); //回传一个ack然后丢弃
goto discard;
}
假如这里对fin-20622的ack检查没有通过,那么也会发送一个ack(即包14914, 这段代码中为challenge ack),然后丢弃掉(没有进入处理fin的流程)。这和问题场景是非常符合的。继续分析tcp_ack()函数,也找到了可能会判定非法的点:
/*这一段是判断收到的ack值与本地发送窗口的关系,
这里snd_una意为send un-acknowledge,即发送了,但未被ack的位置
*/
if (before(ack, prior_snd_una)) { //如果收到的ack值,已经被前面的包ack了
/* RFC 5961 5.2 [Blind Data Injection Attack].[Mitigation] */
服务器托管网
goto old_ack;
}
old_ack:
/* If data was SACKed, tag it and see if we should send more data.
* If data was DSACKed, see if we can undo a cwnd reduction.
*/
return 0;
总结一下:fin-20622有一种可能的处理路径,符合问题场景的表现。从server的视角:
- 首先收到ack-20623,更新了snd_una的值为该包的ack值,即754。
- 然后收到fin-20622,在检查ack值的阶段,由于该包的ack=753,小于此时的snd_nxt,因此被判定为old_ack,非法。之后acceptable返回值为0。
- 由于 ack 值被判定为非法,内核传回一个challenge ack包, 然后直接丢掉fin-20622。
- 因此,最终fin-20622被tcp_rcv_state_process丢弃,没有进入fin包处理的流程。
这样,相当于server并没有收到fin信号,与问题场景吻合。
找到了这一条可疑路径,接下来就要想办法验证了。
由于精确到了具体的代码片段,并且实际代码相当复杂,仅通过代码分析很难确定真实的运行路径。
于是我们放出大招,直接修改内核,验证上述位点的tcp状态信息,主要是状态转移和发送窗口。
修改内核配合测试
具体过程不再赘述,我们有了新的发现:(提示:使用的依然是“表现正常”的复现脚本)
- 收到ack-20623时,snd_una确实被更新了,这符合上面的假设,为fin包丢弃提供了条件。
- 乱序的fin包根本没有进入tcp_rcv_state_process()函数,而是被外层的tcp_v4_rcv()函数按照TIMEWAIT流程直接处理,最终关闭连接。
显然,第二点很可能是导致复现失败的关键。
- 更加证明了我们先前的假设,如果fin能进入tcp_rcv_state_process()函数,应该就能复现出问题。但可能因为线上场景与复现场景存在某些配置差异,导致代码路径分歧。
- 另外这个发现也颠覆了我们的认知,按照tcp的挥手流程,在收到fin-20622前,server发送fin后收到了ack,那么应当处于FIN_WAIT_2状态,工具监控结果也是如此,为何这里是TIMEWAIT呢。
带着这些问题,我们回到代码中,继续分析。在ack检查和fin处理之间,找到一处最可疑的位置:
case TCP_FIN_WAIT1: {
int tmo;
if (tp->snd_una != tp->write_seq) //一种异常情况,还有数据待发送
break; //可疑
tcp_set_state(sk, TCP_FIN_WAIT2); //转移至FIN_WAIT2,并且关闭发送方向
sk->sk_shutdown |= SEND_SHUTDOWN;
sk_dst_confirm(sk);
if (!sock_flag(sk, SOCK_DEAD)) { //延迟关闭
/* Wake up lingering close() */
sk->sk_state_change(sk);
break; //可疑
}
//可能会进入timewait相关的逻辑
tmo = tcp_fin_time(sk); //计算fin超时
if (tmo > sock_net(sk)->ipv4.sysctl_tcp_tw_timeout) {
//如果超时时间很大,则启动keepalive timer探活
inet_csk_reset_keepalive_timer(sk,
tmo - sock_net(sk)->ipv4.sysctl_tcp_tw_timeout);
} else if (th->fin || sock_owned_by_user(sk)) {
/* Bad case. We could lose such FIN otherwise.
* It is not a big problem, but it looks confusing
* and not so rare event. We still can lose it now,
* if it spins in bh_lock_sock(), but it is really
* marginal case.
*/
inet_csk_reset_keepalive_timer(sk, tmo);
} else { //否则直服务器托管网接进入timewait;经过测试,复现失败时ack包进入了这个分支
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto discard;
}
break;
}
这个片段对应ack-20623的处理过程,确实发现了和TIMEWAIT的关联,所以我们怀疑到前面的两个break上。如果提前触发了break,是不是就不会导致TIMEWAIT,进而能够复现成功?
话不多说直接动手,通过修改代码,发现两个break任意触发一个,都能够复现出问题场景,导致连接无法正常关闭!
对比两个break的条件,SOCK_DEAD成为最大嫌疑者。
关于SOCK_DEAD
从字面意思推测,这个flag应当和tcp的关闭过程有关,在内核代码中查找,发现两处相关的函数:
/*
* Shutdown the sending side of a connection. Much like close except
* that we don't receive shut down or sock_set_flag(sk, SOCK_DEAD).
*/
void tcp_shutdown(struct sock *sk, int how)
{
/* We need to grab some memory, and put together a FIN,
* and then put it into the queue to be sent.
* Tim MacKenzie(tym@dibbler.cs.monash.edu.au) 4 Dec '92.
*/
if (!(how & SEND_SHUTDOWN))
return;
/* If we've already sent a FIN, or it's a closed state, skip this. */
if ((1 sk_state) &
(TCPF_ESTABLISHED | TCPF_SYN_SENT |
TCPF_SYN_RECV | TCPF_CLOSE_WAIT)) {
/* Clear out any half completed packets. FIN if needed. */
if (tcp_close_state(sk))
tcp_send_fin(sk);
}
}
EXPORT_SYMBOL(tcp_shutdown);
从注释可以看出,这个函数具有close的一部分功能,但是不会sock_set_flag(sk, SOCK_DEAD)。那么再看一看tcp_close():
void tcp_close(struct sock *sk, long timeout)
{
struct sk_buff *skb;
int data_was_unread = 0;
int state;
if (unlikely(tcp_sk(sk)->repair)) {
sk->sk_prot->disconnect(sk, 0);
} else if (data_was_unread) {
/* Unread data was tossed, zap the connection. */
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONCLOSE);
tcp_set_state(sk, TCP_CLOSE);
tcp_send_active_reset(sk, sk->sk_allocation);
} else if (sock_flag(sk, SOCK_LINGER) && !sk->sk_lingertime) {
/* Check zero linger _after_ checking for unread data. */
sk->sk_prot->disconnect(sk, 0);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA);
} else if (tcp_close_state(sk)) {
/* We FIN if the application ate all the data before
* zapping the connection.
*/
tcp_send_fin(sk); //发送fin包
}
sk_stream_wait_close(sk, timeout);
adjudge_to_death:
state = sk->sk_state;
sock_hold(sk);
sock_orphan(sk); //这里会设置SOCK_DEAD flag
}
EXPORT_SYMBOL(tcp_close);
这里,tcp_shutdown和tcp_close都是tcp协议的标准接口,可以用于关闭连接:
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close, //close在这
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown, //shutdown在这
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
};
EXPORT_SYMBOL(tcp_prot);
综上,shutdown和close的一个重要差异在于shutdown不会设置SOCK_DEAD。
我们将复现脚本的close()换成shutdown()再测试,终于成功复现了fin被丢弃的结果!
(并且通过打印日志,确定丢弃原因就是之前提到的old_ack,终于验证了我们的假设。)
下面只需要回归线上场景,确认是否真的调用了shutdown()关闭连接。经过线上同学的确认,此处server确实是用了shutdown()关闭连接(通过nginx的lingering_close)。
至此,终于真相大白!
总结
最后,回答最初的两个问题作为总结:
- 该现象是否是内核的合法行为?
- 是合法行为,是内核检查ack的逻辑导致的;
- 内核会根据收到的ack值,更新发送窗口参数snd_una,并由snd_una判断ack包是否需要处理;
- 由于fin-20622的ack值小于ack-20623,且ack-20623先到达,更新了snd_una。后到达的fin在ack检查过程中,对比snd_una时被认为是已经ack过的包,不需要再处理,结果被直接丢弃,并回传一个challenge_ack。导致了问题场景。
- 为什么本地复现失败了?
- 关闭tcp连接时,使用了close()接口,而线上环境使用的是shutdown()
- shutdown不会设置SOCK_DEAD,而close则相反,导致复现时的代码路径与问题场景出现分歧。
番外:close()下的tcp状态转移
其实还遗留了一个问题:
为什么用close()关闭连接时,没有观察到fin包的状态转移FIN_WAIT_2 -> TIMEWAIT(没有进入tcp_rcv_state_process)?
这要从FIN_WAIT_1收到ack后讲起,上面的代码分析中提到,如果没有触发两个可疑的break,处理ack时将会进入:
case TCP_FIN_WAIT1: {
int tmo;
else {
tcp_time_wait(sk, TCP_FIN_WAIT2, tmo);
goto discard;
}
break;
}
tcp_time_wait()主要逻辑如下:
/*
* Move a socket to time-wait or dead fin-wait-2 state.
*/
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcp_sock *tp = tcp_sk(sk);
struct inet_timewait_sock *tw;
struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row;
//创建tw,其中将tcp状态置为TCP_TIME_WAIT
tw = inet_twsk_alloc(sk, tcp_death_row, state);
if (tw) { //创建成功,则会进行初始化
struct tcp_timewait_sock *tcptw = tcp_twsk((struct sock *)tw);
const int rto = (icsk->icsk_rto icsk_rto >> 1); //计算超时时间
struct inet_sock *inet = inet_sk(sk);
tw->tw_transparent = inet->transparent;
tw->tw_mark = sk->sk_mark;
tw->tw_priority = sk->sk_priority;
tw->tw_rcv_wscale = tp->rx_opt.rcv_wscale;
tcptw->tw_rcv_nxt = tp->rcv_nxt;
tcptw->tw_snd_nxt = tp->snd_nxt;
tcptw->tw_rcv_wnd = tcp_receive_window(tp);
tcptw->tw_ts_recent = tp->rx_opt.ts_recent;
tcptw->tw_ts_recent_stamp = tp->rx_opt.ts_recent_stamp;
tcptw->tw_ts_offset = tp->tsoffset;
tcptw->tw_last_oow_ack_time = 0;
tcptw->tw_tx_delay = tp->tcp_tx_delay;
/* Get the TIME_WAIT timeout firing. */
//确定超时时间
if (timeo ipv4.sysctl_tcp_tw_timeout;
/* tw_timer is pinned, so we need to make sure BH are disabled
* in following section, otherwise timer handler could run before
* we complete the initialization.
*/
//更新维护timewait sock的结构
local_bh_disable();
inet_twsk_schedule(tw, timeo);
/* Linkage updates.
* Note that access to tw after this point is illegal.
*/
inet_twsk_hashdance(tw, sk, &tcp_hashinfo); //加入全局哈希表(tcp_hashinfo)
local_bh_enable();
} else {
/* Sorry, if we're out of memory, just CLOSE this
* socket up. We've got bigger problems than
* non-graceful socket closings.
*/
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPTIMEWAITOVERFLOW);
}
tcp_update_metrics(sk); //更新tcp统计指标,不影响本次行为
tcp_done(sk); //销毁掉sk
}
EXPORT_SYMBOL(tcp_time_wait);
可见,在这个过程中,原本的sk被销毁了,并且创建了对应的inet_timewait_sock,进入计时。换言之,close的server收到ack时,虽然会进入FIN_WAIT_2,但是之后立即切换到了TIMEWAIT状态,且没有经过标准的tcp_set_state()函数,致使ebpf没有监控到。
之后再收到fin包时,则根本不会进入tcp_rcv_state_process(),而是由外层tcp_v4_rcv()进行timewait流程处理。具体来讲,tcp_v4_rcv()将根据收到的skb查询对应的内核sk,这里会查到上面创建的timewait_sock,其状态为TIMEWAIT,所以直接进入timewait的处理,核心代码如下:
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
struct sk_buff *skb_to_free;
int sdif = inet_sdif(skb);
int dif = inet_iif(skb);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
th = (const struct tcphdr *)skb->data;
lookup:
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, sdif, &refcounted); //从全局哈希表tcp_hashinfo中查询sk
process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
do_time_wait: //正常的timewait处理流程
goto discard_it;
}
综上,server调用close()关闭连接,收到ack后会转入FIN_WAIT_2,然后立刻转移为TIMEWAIT,不需要等待client的fin包。
一种简单的定性理解:调用close()的socket意味着完全关闭接收和发送,这样进入FIN_WAIT_2等待对方的fin意义不大(等待对方fin的一个主要目的是确定对方发送完毕),所以在确认己方发送的fin被对面收到之后(收到了client针对fin的ack),就可以进入TIMEWAIT状态了。
作者:
阿里云虚拟交换机团队:负责阿里云网络虚拟化相关的开发与维护。
阿里云内核网络团队:负责阿里云服务器操作系统中,内核网络协议栈的开发与维护。
原文链接
本文为阿里云原创内容,未经允许不得转载。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
