
导航
- 火线告警,CPU飚了
- 版本回退,迅速救火
- 猜测:分布式锁是罪魁祸首
- 代码重构,星夜上线
- 防患未然,功能可开关
- 高度戒备,应对早高峰
- 实时调整方案,稳了
- 结语
- 参考
本文首发于智客工坊-《记一次加锁导致ECS服务器CPU飙高分析》,感谢您的阅读,预计阅读时长3min。
每一次版本的上线都应该像火箭发射一样严肃,同时还需要准备一些预案。
前言
此前,我曾在《对几次通宵加班发版的复盘和思考》文中,表达过”每一次版本上线都应该像火箭发射一样严肃”的观点。与此同时,我也分析其中的原因并提出相应的解决方案。
我坚信,那篇文章中的措施和方案已经覆盖发版中遭遇的大部分场景。
尽管我们总是保持对技术的敬畏之心,每次发版也会验证的比较充分,仍然会有一些相对不太容易预知的事情发生。
所以,我将”火箭发射”观点改成了”每一次版本的上线都应该像火箭发射一样严肃,同时还需要准备一些预案“。
火线告警,CPU飚了
如果你很难定位线上的问题,快速回退是一个好办法。
在多年的职业历练中,我养成了一个习惯——每次执行完发版任务的第二天,都会积极关注公司相关业务群的动向,并尽可能早的到公司。
这一天,和往常一样,我在早高峰的路上奋力前行,突然群里闪现出一条业务方发出的消息。
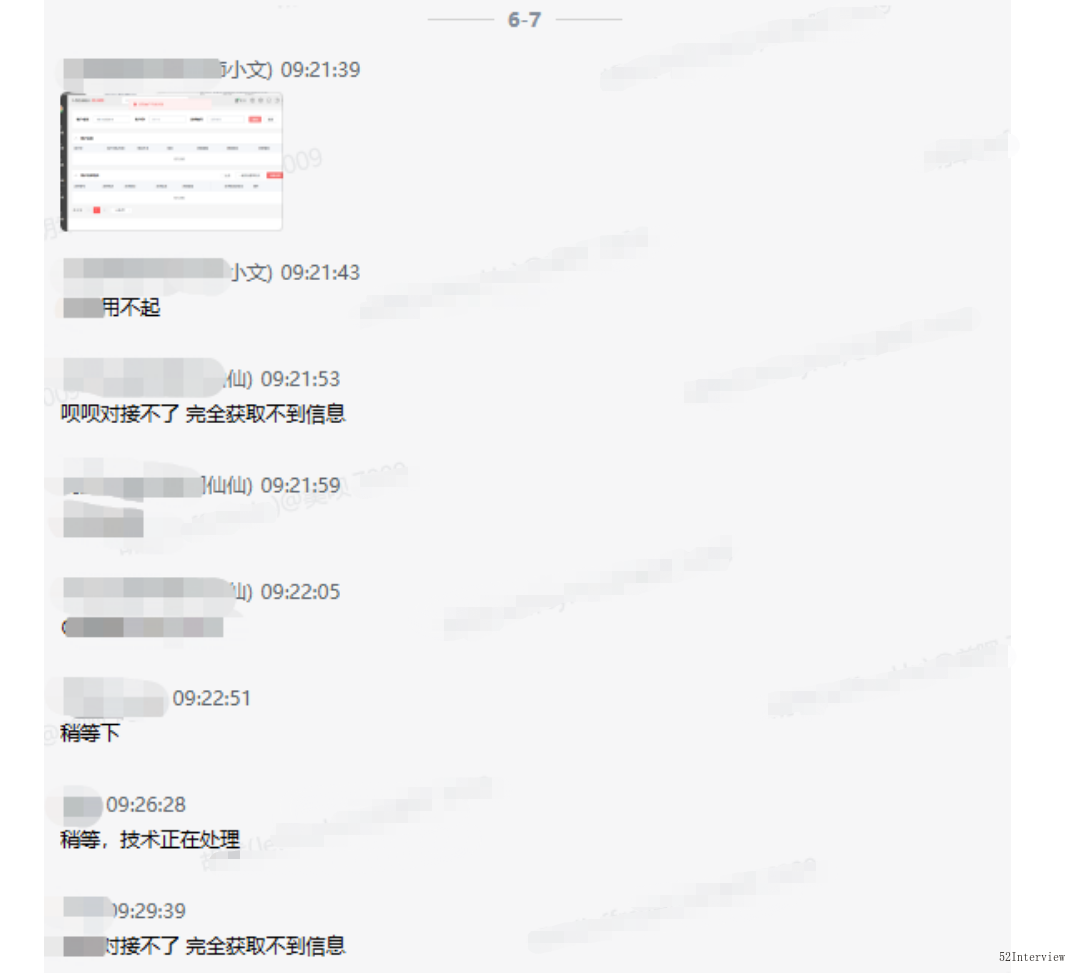
随即便是更多的业务对接群开始炸锅。
前段时间因为数据库性能问题,已经出现了几次线上宕机的情况,被用户吐槽。(为啥出现性能问题,此处省略若干字,后续有机会再娓娓道来)。
所以,每次今天再次遇到这样的问题,我们总是显得很被动。
我和业务团队的同事一边安抚用户的情绪,一边快马加鞭奔赴公司。
火速赶到公司之后,查看了报警日志,发现部署该业务接口的ecs CPU飙高了…
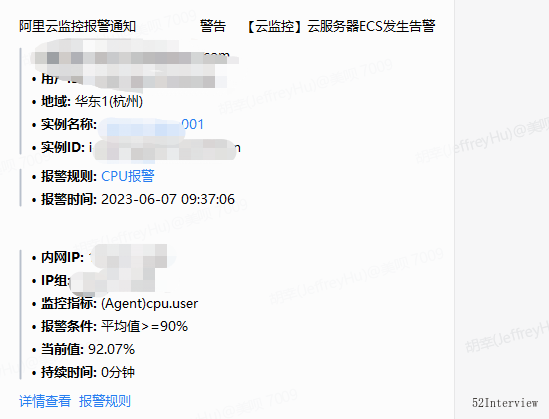

当机立断,回滚到上一版本。
大约一分钟之后,我们验证了可用性,并查看ecs和数据库各项指标,正常。
于是大家一一回复了用户群,对接群终于安静了。
猜测:分布式锁是罪魁祸
大胆假设,小心求证。
代码回滚之后一切变得正常,我们可以断定此次线上问题的一定是和昨晚的发版有关。
但是,是哪个功能或者那句代码引发了ecs cpu标高呢?
第一时间闪现在脑海里面的就是“一键已读”功能。
该功能的代码大致如下(已脱敏):
@Override
public void oneKeyRead(OneKeyReadBo bo) {
//...
//1. 拉取的未读的会话(群聊)
List unReadChatIds = listUnReadChatIds(loginUser.getUserId());
if (CollectionUtil.isEmpty(unReadChatIds)) {
log.info("当前用户没有未读会话!");
return;
//2. 循环处理单个群的消息已读
CompletableFuture.runAsync(
() -> {
processOneKeyReadChats(realUnReadChatIds, loginUser);
})
.exceptionally(
error -> {
log.error("批量处理未读的群会话异常:" + error, error);
return null;
});
}
@Resource
private Executor taskExecutor;
private void processOneKeyReadChats(List realUnReadChatIds, User loginUser) {
//循环处理单个群的消息已读
for (Long groupChatId : realUnReadChatIds) {
OneKeyReadMessageBo oneKeyReadMessageBo=new OneKeyReadMessageBo();
//...省略一些代码
oneKeyReadMessage(oneKeyReadMessageBo);
}
}
/**
* 单独处理一个群的消息已读
*/
private void oneKeyReadMessage(OneKeyReadMessageBo bo) {
// 批量已读,按会话加锁
String lockCacheKey = StrUtil.format("xxx:lock:{}:{}", bo.getUserId(), bo.getChatId());
RLock lock = redissonClient.getLock(lockCacheKey);
boolean success = false;
try {
success = lock.tryLock(10, TimeUnit.SECONDS);
} catch (InterruptedException ignored) {
}
if (!success) {
log.info(StrUtil.format("用户: {}, 消息: {}, 消息一键已读失败", bo.getUserId(), bo.getChatId()));
throw new BizException("消息已读失败");
}
try {
//1. ack 已读
//...省略若干代码
//2.chatmember已读
//...省略若干代码
//3.groupMsg已读
//...省略若干代码
} finally {
lock.unlock();
}
}
从上面的代码可以看出来,循环的最底层使用了分布式锁,且锁的时长是10s。
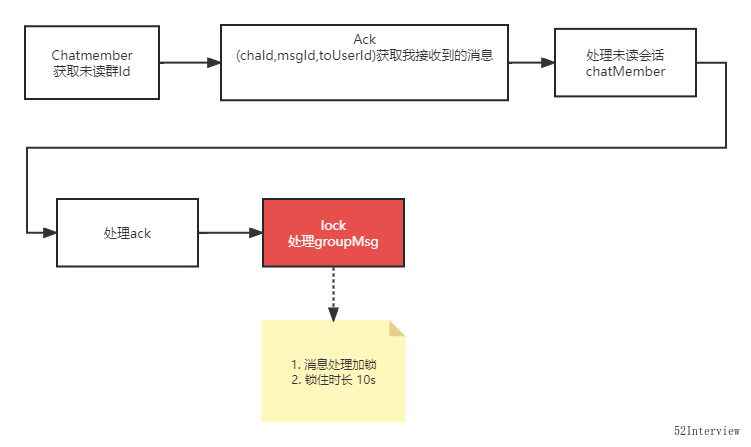
综上可以推断, ecs cpu爆高是底层消息处理加锁导致。
代码重构,星夜上线
重构应随时随地进行。
过去我们总是对旧项目中的“老代码”嗤之以鼻。回头看自己写过的代码,难免有点”时候诸葛亮”的意思。
在这次的版本中,为了节省时间,从项目中别处复用了处理groupMsg的代码(复制粘贴确实很爽)。
但是,忽略了那个加锁的方法在单个会话的处理是适合的,却不适合大批量的处理。
于是对代码进行重构。
主要是如下几个改进:
-
处理未读会话提前,批量并使用同步的方式执行,后续流程异步处理。
这样做其实是为了快速相应前端,且前端立马刷新列表,让用户能够感知到群会话的未读数已经清除。 -
将unReadChatIds分批处理,每次最大处理1000个。防止单次处理的未读会话过大,最终到unReadMsg上消息处理量控制在一万以内。(Mysql in 的数量进行控制)。
-
消息未读数处理取消锁。
大致代码如下:
@Override
public void oneKeyRead(OneKeyReadBo bo) {
//1. 拉取的未读的会话(群聊)
List unReadChatIds = listMyUnReadChatIds(loginUser.getUserId(), bo.getBeginSendTime(), bo.getEndSendTime());
if (CollectionUtil.isEmpty(unReadChatIds)) {
log.info("当前用户没有未读会话!");
return;
}
// 同步处理clear notify
batchClearUnreadCount(unReadChatIds, loginUser.getUserId());
//2. ack+groupMsg已读
CompletableFuture.runAsync(
() -> {
processOneKeyReadChats(unReadChatIds, loginUser);
})
.exceptionally(
error -> {
log.error("批量处理未读的群会话异常:" + error, error);
return null;
});
}
private void processOneKeyReadChats(List unReadChatIds, User loginUser) {
//批处理
int total = unReadChatIds.size();
int pageSize = 1000;
if (total > pageSize) {
RAMPager pager = new RAMPager(unReadChatIds, pageSize);
System.out.println("unReadChat总页数是: " + pager.getPageCount());
Iterator> iterator = pager.iterator();
while (iterator.hasNext()) {
List curUnReadChatIds = iterator.next();
if (CollectionUtil.isEmpty(curUnReadChatIds)) {
continue;
}
batchReadMessage(curUnReadChatIds, loginUser);
}
} else {
batchReadMessage(unReadChatIds, loginUser);
}
}
/**
* 批量处理消息已读
*/
private void batchReadMessage(List unReadChatIds, User loginUser) {
try {
//1. 批量ack 已读
//...省略若干代码
//2. groupMsg已读
//...省略若干代码
} catch (Exception ex) {
log.error(StrUtil.format("batchReadMessage 异常,error:{}", ex.getMessage()));
}
}
下班之后,火速上线。
防患未然,功能可开关
尽管从理论上我已经推断出这个锁是引发ecs cpu爆高的主要因素。但是,内心依然是忐忑的。
比如,这样改造之后,到底能有多大的优化下效果?是否能够抗住明天的早高峰?
如果CPU再次飙高怎么办?
看得出来,这个功能上线之后确实受到了客户的青睐,所以能否抗住明天的早高峰,值得思考。
思考再三,为了能够在线上遇到问题时,不用发版就能快速处理,我决定临时给这个功能增加了一个开关。
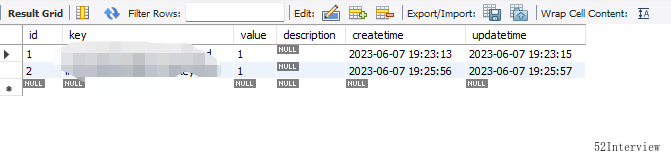
这样,当生产环境开始报警的时候,我就可以快速地关闭该功能。
办法虽笨,但是道理很简单,非常适合这样的场景。
高度戒备,应对早高峰
我们的系统主打一个字,稳。
保持系统的稳定性几乎是IT从业者的共识。
尽管我们已经做了代码重构,增加功能开关等工作,心里依旧是忐忑的。
第二天一大早我就来到公司。随时盯着各项监控指标,并等待早高峰的来临。
从9:00开始,已经用户开始使用我们的”一键已读”功能,但是服务器CPU使用率没有飙升,也没有报警。
观察了一下数据库的CPU使用率,逐渐开始走高并接近60%。
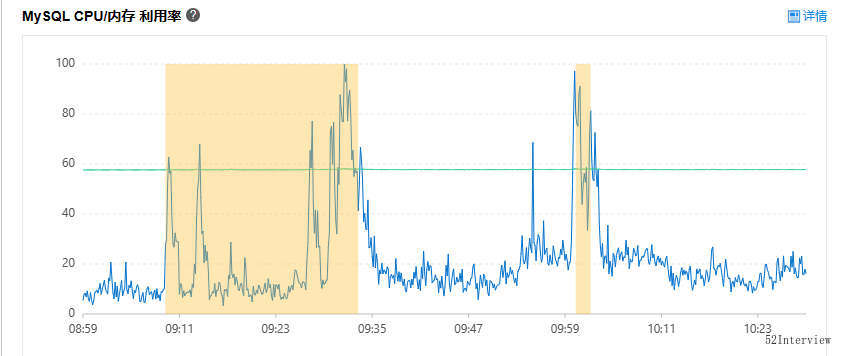
可以证明我们的代码重构是生效了的,这一点是值得欣慰的。
压力给到了mysql数据库,这是预料之中的,但是如果峰值超过90%,大概率会引发我们的系统崩溃。
我几乎每5s刷新一次数据库使用率这个指标,到了09:32,数据库使用率超过了98%,并且大约持续了1min,仍然在高位,系统已经游走在崩溃的边缘。
我迅速关闭了这个”一键已读”功能。
然后,数据库CPU使用率随即骤降,回归到20%~40%的水平。
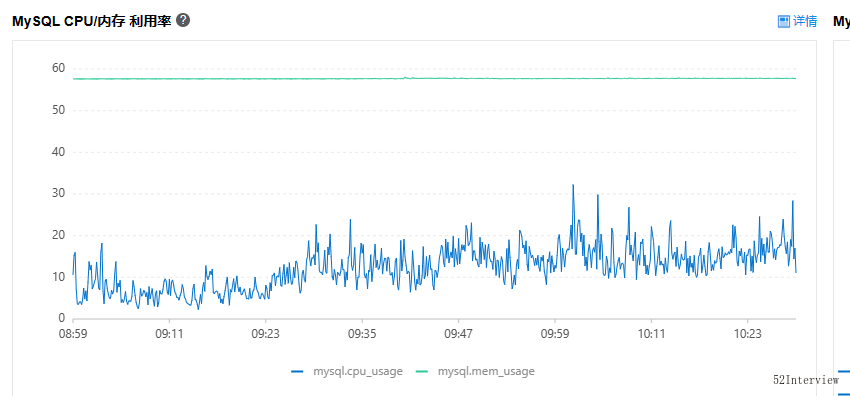
可能,您不太理解我为啥如此关注这个指标?
下图是我们系统正常情况下的数据库使用率,基本维持在30%以下。
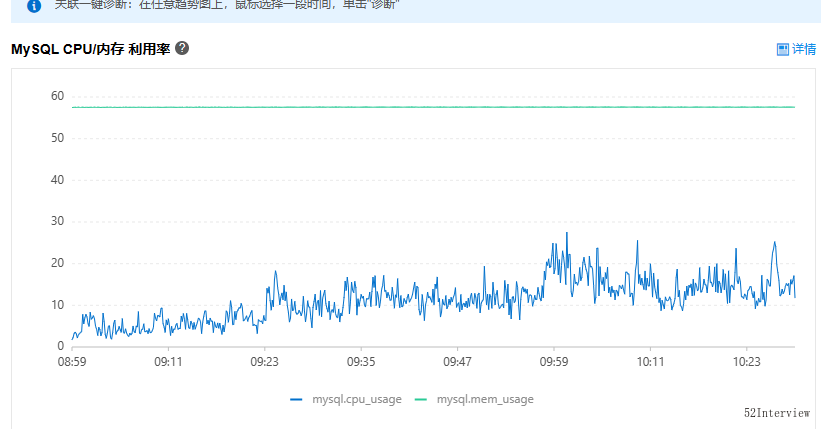
实时调整方案,稳了
那是什么原因导致数据库cpu突然飙高呢?
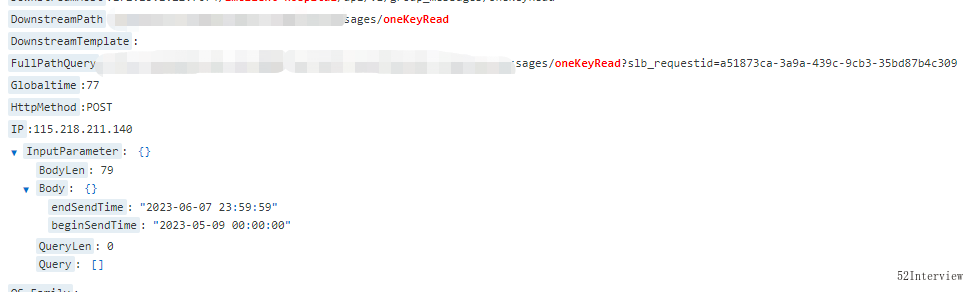
经过排查日志,发现有人选择近一个月的会话进行处理。
一个月的未读会话数量可能超过5000,下沉到群消息的未读数量,预计会在1w以上。
而群消息表的体量大概在2kw左右,这意味着要在这个大表里面in接近1w个参数。
连续排查发现,凡是选择一个月时间段的请求,数据库cpu都会立马飙升至60%以上。
权衡再三,我们立马将用户可选择的时长控制在一周以内(前端控制)。
再次开启功能,系统各项指标平稳且维持在合理范围。
至此,对该功能的处理终于完美收官了。
结语
哪有什么岁月静好,我们总是在打怪升级中成长。
在多年的职场洗礼之后,逐渐认识到技术并非孤立存在的。
或许对于大众而言所谓的”技术好”,不是单纯的卖弄技术,而是能够针对灵活多变的场景,恰到好处的运用技术。
活到老,学到老。
这里笔者只根据个人多年的工作经验,一点点思考和分享,抛砖引玉,欢迎大家怕批评和斧正。
参考
- 《对几次通宵加班发版的复盘和思考》

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
