
论文链接:Meta-Tuning Loss Functions and Data Augmentation for Few-Shot Object Detection
Abstract
现阶段的少样本学习技术可以分为两类:基于微调(fine-tuning)方法和基于元学习(meta-learning)方法。
基于元学习的方法旨在学习专用的元模型,使用学到的先验知识处理新的类,而基于微调的方法以更简单的方式处理少样本检测,通过基于梯度的优化将检测模型适应新领域的目标。基于微调的方法相对简单,但通常能够获得更好的检测结果。
基于此,作者将重点关注损失函数和数据增强对微调的影响,并使用元学习的思想去动态调整参数。因此,提出的训练方案允许学习能促进少样本检测的归纳偏置,从而增强少样本检测,同时保持微调方法的优点。
归纳偏置:为了实现泛化,一定的偏好(或者称为归纳偏置)是必要的,也就说在新数据集上实现泛化需要对最优解做出合理假设。引入归纳偏置的方式有很多,例如在目标函数中加入正则项。
1. Introduction
目标检测是计算机视觉的问题之一,依赖于大规模注释数据集,但由于数据集的收集和标注成本,催生出了一系列对标注数据要求较低的目标检测方法,例如结合弱监督学习、点注释(point annotations)和混合监督学习。类似的还有少样本目标检测(Few-Shot Object Detection, FSOD)。
在FSOD问题上,目标是通过迁移学习,用在大规模图像上训练的模型,为具有少量样本标记的新类构建检测模型。还有就是广义少样本目标检测(Generalized-FSOD, G-FSOD),目标是要构建在基础类和新类都表现良好的少样本检测模型。
FSOD分为元学习的方法与微调的方法。现阶段,微调的方法在这一问题上表现更为出色。微调的方法是典型的迁移学习,基于梯度优化进行对正则化损失最小化,使预训练模型适应少样本类别。
虽然能够对专门的参数进行训练的FSOD的元学习方法很有吸引力,但有两个重要的缺点:1、由于模型复杂性,有着过拟合训练类的风险;2、难以解释学到的内容。相对的,基于微调的FSOD方法简单且通用。
为什么说“难以解释学到的内容”:除了广为诟病的“神经网络模型是黑盒子”说法,还可能是因为元学习涉及多个任务的训练,任务之间亦有差异,这使得难以找到的通用的解释方法。
但是,基于微调的FSOD方法的最大优点也可能是最大缺点:它们普遍保留基类的知识,没有在很少的样本上学习到归纳偏置。为了解决这些问题,许多方法在微调的细节切入,例如:Frustratingly Simple Few-Shot Object Detection提出冻结一部分参数然后微调检测模型的最后一层;FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding修改了损失函数。然而这些这些针对少样本类的特定优化方式,由于都是手工完成,所以并不一定是最优的。
还是为了解决这些问题,作者引入元学习的思想,在FSOD的微调阶段调整损失函数和数据增强,这个过程称为元微调(meta-tuning),如图1所示。
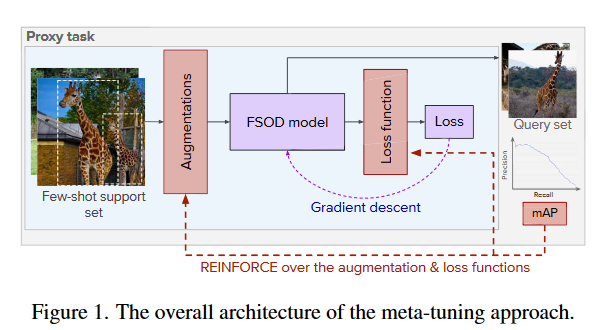
具体来说,就像元学习训练元模型一样,以数据驱动的方式逐步发现适合FSOD的最佳损失函数和数据(细节)增强。使用强化学习(Reinforcement Learning, RL)的技术调整损失函数与数据增强,最大化微调后的FSOD模型质量。作者通过对设置的损失项和增强列表进行调整,将搜索限制在有效的函数族内。最后将元学习调整的损失函数和增强以及FSOD特定的归纳偏置与微调方法相结合。
为了探索meta-tuning对于FSOD的潜力,作者将重点关注分类损失的细节(FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding展示了,在目标检测问题中,分类和定位中,分类更容易出错)。此外,作者首先关注了softmax的温度参数,设定了两个版本:1、简单的恒定温度参数;2、随微调迭代变化的动态温度,用指数多项式表示。
在所有情况下,通过meta-tuning学习的参数都会产生可解释的损失函数,与复杂的元模型相比,在基类上过拟合的风险可以忽略不计。作者还在meta-tuning过程中对数据增强的进行建模,作者还引入了分数缩放器,用于平衡学习基类和新类的分数。
2. Related Word(略)
3. Method
每张训练图片对应元组((x,y)),包括图像服务器托管网(x)和标注(y={y_0,dots,y_M}),每个对象的标注(y_i={c_i,b_i})表示类别标签(c_i)和检测边界(b_i={x_i,y_i,w_i,h_i})。当FSOD模型训练完成,评估阶段使用k张图片,图像的类来自新的类集合(C_n)。
对于基础模型,作者使用MPSR FSOD方法 作为损失函数和数据增强搜索方法的基础。为了使Faster-RCNN适应基于微调的FSOD,引入了多尺度位置采样调整(Multi-Scale Positive Sample Refinement, MPSR)分支来处理尺度稀疏问题
图像中的对象被裁剪并调整为多种尺寸以创建对象金字塔。MPSR对区域提议网络(Region Prosed Network, RPN)和检测头使用两组损失函数,并将不同比例的正样本与主检测分支检测结果一起反馈到损失函数中。最后,作者认为所提出的方法原则上可以应用于几乎任何基于微调的 FSOD 模型。
3.1 Meta-Tuning损失函数
对于元调整的FSOD,将重点关注分类损失函数(正如上文所述,分类比检测更容易出错)。对于MPSR的损失函数表示为:
]
其中(N_{ROI})是图像的候选区域,(y_i)是第i个ROI的真实标签,(f(x_i,y))是对应y的预测分数。为了使损失函数更灵活,重新定了损失函数:(mathcal{l}_{cls}(x,y;rho)),其中(rho)表示损失函数的参数。首先引入了温度标量(rho_tau),即(rho=(rho_ta服务器托管网u))。
]
引入的动机是来自温度缩放在其他问题的表现,例如知识蒸馏。对比手动调整的方式,这里引入元调整,通过定义动态温度函数(f_p)和新类缩放器(alpha)使损失函数更复杂:
]
其中(f_p(t)=exp(rho_at^2+rho_bt+rho_c)),这里(rho=(rho_a,rho_b,rho_c))是多项式系数三元组,(tin[0,1])为归一化后的微调迭代索引。(yin C_b)时,(alpha(y)=1);否则用缩放系数(rho_alpha)平衡基类和新类的学习。
3.2 Meta-tuning增强
对于元调整的数据增强部分,考虑到在基类学习的结果要迁移到新类,作者专注于光度增强。作者使用共享的增强幅度参数(rho_{aug})对亮度、饱和度和色调进行建模。在Randaugment: Practical Automated Data Augmentation With a Reduced Search Space证明了这是有效的。
3.3 Meta-tuning过程
作者使用基于强化学习的REINFORCE去搜索最佳损失函数和增强。
为了提高泛化能力,设置了代理任务:在基类训练数据上,模范新类的FSOD任务。为此,基类被分为两个子集,代理基类(C_{p-base})和代理新类(C_{p-novel})。同时,使用基类训练集分割构造3个不重叠的数据集:
- (D_{p-pretrain}),仅包含(C_{p-base})的样本,用来训练临时的目标检测模型进行元调整;
- (D_{p-support}),包含(C_{p-base}cup C_{p-novel}),在元调整期间充当微调数据;
- (D_{p-query}),包含(C_{p-base}cup C_{p-novel}),在元调整期间评估广义FSOD性能。
就像元学习的task,本文设置了一系列FSOD代理任务:在每个代理任务T,从(D_{p-support})选择训练数据。此外,还有对损失函数/增强幅度的参数组合(rho),这里每个(rho_jinrho)服从高斯分布:(rho_jsimmathcal{N}(mu_j,sigma^2))。
使用采样的(rho)对应的损失函数或数据增强,在支持图像上基于梯度优化微调初始模型,并在(D_{p-query})计算平均精度(mean Average Precision, mAP)。通过在多个代理任务支持样本上多次重复该过程获得多个mAP分数,然后在每一次训练之后,通过REFORCE规则更新(mu)进行元调整,以找到表现良好的(rho)。
]
其中(p(rho;mu,sigma))是高斯密度函数,(eta)是RL学习率。
我们以每次训练得到奖励最高的(rho)作为REFORCE更新规则。(R(rho))是通过白化后的mAP分数获得的归一化奖励函数.
白化:白化的目的是使得预处理后的数据具有以下特性:1、特征之间的相关性尽可能小;2、所有特征具有相同的方差;3、所有特征具有相同的均值。
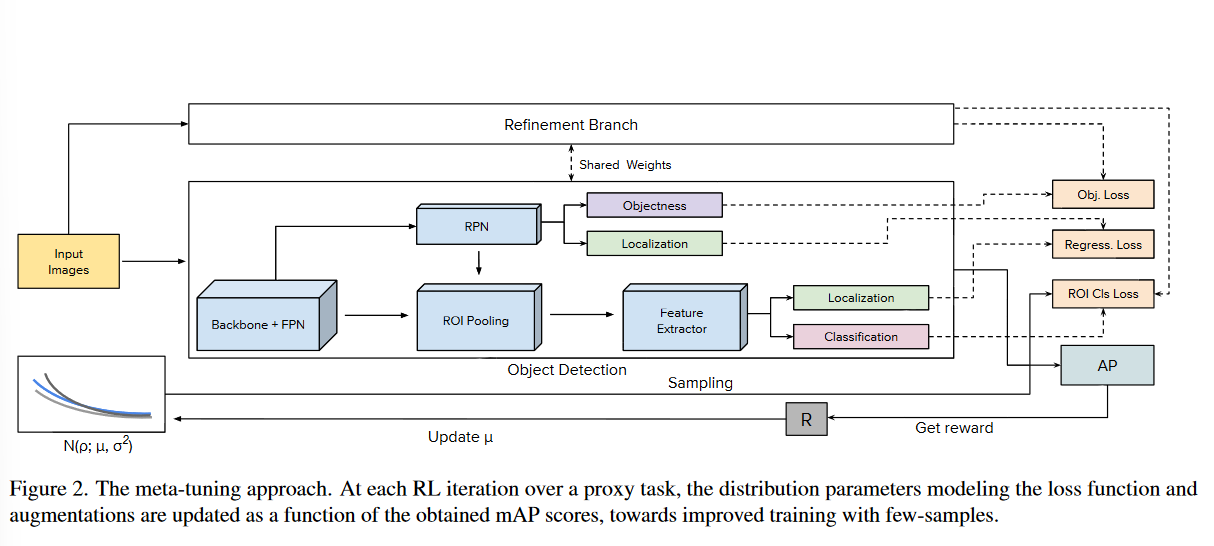
最后,从(sigma=0.1)开始,在RL迭代中减小(sigma),通过更保守的采样逐步减小探索,从而提高收敛性,最终方案如图2所示(作者真正的工作是“ROI Cls Loss”和下方根据AP更新(mu)的部分,Refinement Branch与Object Detection来自MPSR):
4. Experiments
对于指标的设置,作者选择mAP分别评估基础类和新类的检测结果。在广义FSOD评估中,选择调和平均值(Harmony Mean, HM)来计算性能,HM定义为(mathrm{mAP_{base}})和(mathrm{mAP_{novel}})的均值。
对于数据集。在Pascal VOC上存在3个独立的基类/新类,其中每个由15个基类和5个新类组成。在每次分割,选择5个基类模仿代理任务上的新类。在MS-COCO上,选择15个基类模仿代理任务上的新类,并评估10-shot和30-shot的情况。
对于Baseline,作者使用了MPSR和DeFRCN,两种FSOD上的SOTA算法
4.1 主要结果
作者首先将元调整结果与MPSR基线进行比较,如表1所示。
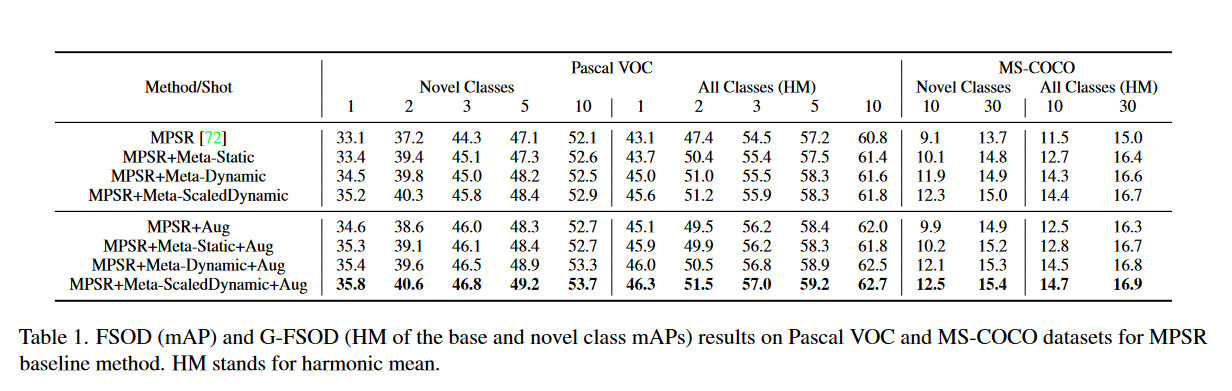
- Meta-Static:使用固定的温度参数;
- Meta-Dynamic:使用动态温度参数(公式(3)无(alpha));
- Meta-ScaledDynamic:使用新类缩放动态温度函数(公式(3));
- Aug:表示数据增强。
可以看到,随着算法改进和数据增强参数的添加,整体的表现得到了提高。

表2中展示不同算法在Pascal VOC上的对比,可以看到作者的方法在FSOD和G-FSOD上都取得了最高的得分。结果表明,将元学习的得到的归纳偏置与微调相结合是有效的。

图3第一行、第二行分别展示了没有元调整和有元调整(带缩放动态温度和数据增强)的视觉检测实例。可以看到误报减少、框更准确。

表3中展示了在MS-COCO上的对比,除了逊色于DeFRCN和LVC-PL,较其他算法都有改进。
4.2 消融研究
消融研究设计了元微调的三个细节:
- 代理任务的模仿:在代理任务上进行强化学习,用来模仿测试时的FSOD。
- 模型重新初始化:在每个代理任务上重新初始化模型,以避免累积的模型更新对奖励的不良影响。
- 奖励归一化:通过标准化单个任务中获得的奖励来进一步减少任务间方差的影响,从而允许对采样的损失函数和增强进行更独立的评估。
在表4中展示使用Pascal VOC Split-1 和 MPSR+Meta-Dynamic和5-shot在G-FSOD上的表现。
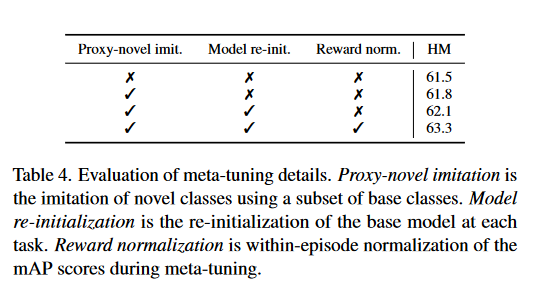
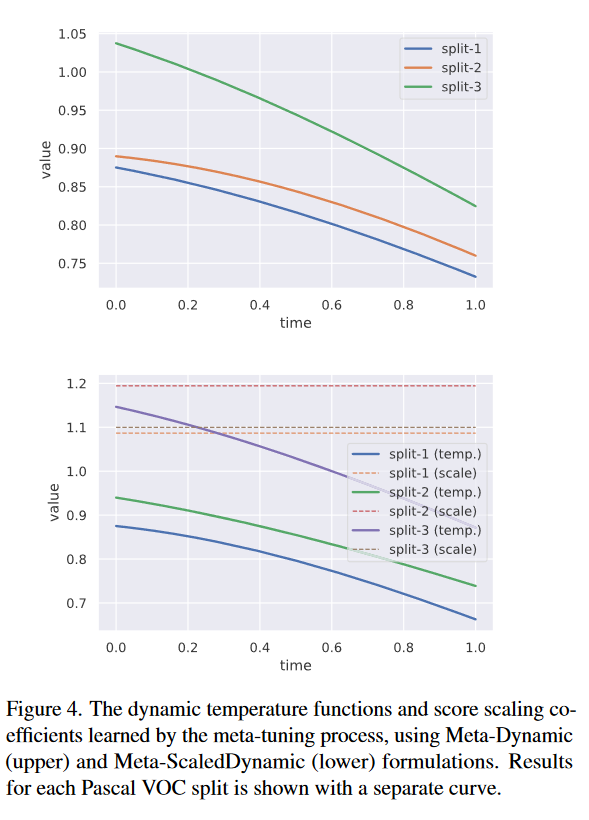
图4中展示了公式(2)和公式(3)使用的损失函数的相关参数训练变化。
5. Conclusion
基于微调的少样本目标检测模型简单可靠。但现有的微调改进都是使用手工的方式,作者提出引入元学习和强化学习,为小样本学习引入归纳偏置,使损失函数和数据增强幅度的学习变化可解释。最后,提出的元调整方式在数据集上取得较好的性能提升。
参考文献
- 【深度学习】归纳偏置(Inductive Biases)
- 知识蒸馏(Knowledge Distillation)简述(一)
- Model-Agnostic Meta-Learning (MAML)模型介绍及算法详解
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
