
来源:CVPR 2022
链接:https://arxiv.org/pdf/2206.02099.pdf
0、Abstract
本文解决了将知识从大型教师模型提取到小型学生网络以进行 LiDAR 语义分割的问题。由于点云的固有挑战,即稀疏性、随机性和密度变化,直接采用以前的蒸馏方法会产生较差的结果。为了解决上述问题,我们提出了点到体素知识蒸馏Point-to-Voxel Knowledge Distillation (PVD),它从点级别和体素级别转移隐藏知识。具体来说,我们首先利用逐点和体素输出蒸馏来补充稀疏监督信号。然后,为了更好地利用结构信息,我们将整个点云划分为几个超体素,并设计一种困难感知采样策略,以更频繁地采样包含不常见类和远处物体的超体素。在这些超级体素上,我们提出了点间和体素间亲和力蒸馏,其中点和体素之间的相似性信息可以帮助学生模型更好地捕获周围环境的结构信息。我们对两个流行的 LiDAR 分割基准进行了广泛的实验,即 nuScenes [3] 和 SemanticKITTI [1]。在这两个基准上,我们的 PVD 在三个代表性骨干网(即 Cylinder3D [36, 37]、SPVNAS [25] 和 MinkowskiNet [5])上始终大幅优于之前的蒸馏方法。值得注意的是,在具有挑战性的 nuScenes 和 SemanticKITTI 数据集上,我们的方法可以在竞争性的 Cylinder3D 模型上实现大约 75% 的 MAC 减少和 2 倍的加速,并在 SemanticKITTI 排行榜上所有已发布的算法中排名第一。我们的代码可在 https://github.com/cardwing/Codes-for-PVKD 获取。
1. Introduction
激光雷达语义分割在自动驾驶感知中发挥着至关重要的作用,因为它提供了周围环境的每点语义信息。随着深度学习的出现,人们提出了大量的 LiDAR 分割模型 [14,25,26,37],并在许多基准测试中占据主导地位 [1,3]。然而,令人印象深刻的性能是以大量计算和存储为代价的,这阻碍了它们部署在资源受限的设备中。
为了在自动驾驶汽车上部署这些强大的 LiDAR 分割模型,知识蒸馏 [10] 是一种流行的技术,它将暗知识从过度参数化的教师模型转移到细长的学生网络,以实现模型压缩。然而,由于点云固有的困难,即稀疏性、随机性和密度变化,直接将以前的蒸馏算法[9,10,17,24,28]应用于LiDAR语义分割会带来边际收益。
为了解决上述挑战,我们提出了点到体素知识蒸馏(PVD)。顾名思义,我们建议从点级和体素级提取知识。具体来说,为了对抗稀疏的监督信号,我们首先建议分别从教师那里提取点式和体素式概率输出。逐点输出包含细粒度的感知信息,而体素预测则包含有关周围环境的粗略但更丰富的线索。
为了有效地从无序点序列中提取有价值的结构知识,我们建议利用点级和体素级亲和力知识。通过测量点特征和体素特征的成对语义相似度来获得相似度知识。然而,直接模仿整个点云的亲和力知识是很困难的,因为有数万个点,并且这些点特征的亲和力矩阵有超过百亿个元素。因此,我们提出了超体素划分,将整个点云划分为固定数量的超体素。在每个蒸馏步骤中,我们仅对 K 个超体素进行采样,并提取从这些超体素中的点特征和体素特征计算出的亲和力知识,从而显着提高学习效率。考虑到不同类和不同距离的对象之间存在不均匀的点数分布,我们进一步引入了一种困难感知采样策略,以更频繁地采样包含少数类和遥远对象的超体素,强调对困难情况的学习。
我们的贡献总结如下。据我们所知,我们是第一个研究如何将知识蒸馏应用于激光雷达语义分割以进行模型压缩的。为了解决从点云中提取知识的困难,即稀疏性、随机性和变化密度,我们提出了点到体素知识蒸馏。此外,我们提出了超体素分区以使亲和蒸馏易于处理。还采用了困难感知采样策略来更频繁地对包含少数类别和远处物体的超体素进行采样,从而显着提高了对这些困难情况的蒸馏效率。从图 1 中可以看出,我们的方法比基线蒸馏方法产生了更准确的预测,特别是对于那些少数类别和遥远的对象。
我们对 nuScenes [3] 和 SemanticKITTI [1] 数据集进行了广泛的实验,结果表明,我们的算法在三个当代模型(即 Cylinder3D [36, 37]、SPVNAS [25]、MinkowskiNet [5])上始终大幅优于之前的蒸馏方法。值得注意的是,在 nuScenes 和 SemanticKITTI 基准测试中,PVD 在性能最佳的 Cylinder3D 模型上实现了大约 75% 的 MAC 减少和 2 倍的加速,性能下降非常小。
2. Related Work
2.1 LiDAR semantic segmentation
LiDAR 语义分割 [5,6,8,14,18,21,22,25,26,29–31,35,37] 对于自动驾驶车辆的导航至关重要。 PointNet [21]是使用多层感知(MLP)直接处理点云的开创性工作之一。尽管 PointNet 及其变体 [22] 在处理小规模点云方面非常有效,但在处理大规模室外点云时速度极其缓慢。为了应对大规模的室外点云,Hu 等人。 [14]利用随机采样进行点选择,并设计局部特征聚合模块以进一步保留关键特征。徐等人。 [31]提出了距离-点-体素融合网络来利用不同视图的优点。朱等人。 [37]提出了Cylinder3D方法,采用圆柱分区和非对称卷积来更好地利用点云中的有价值信息。唐等人。 [25]利用神经架构搜索来自动找到手头任务的最佳结构。尽管这些模型在各种基准测试中表现出了令人印象深刻的性能,但一个常见的缺点是这些网络太麻烦,无法部署在资源受限的设备上。为了能够在现实应用中部署这些强大但笨重的 LiDAR 语义分割模型,我们提出了点到体素知识蒸馏来实现模型压缩。
2.2 Knowledge distillation
知识蒸馏 (KD) 源于 G. Hinton 等人的开创性工作。 [10]。 KD 的主要目标是将丰富的暗知识从繁琐的教师模型转移到紧凑的学生模型,以缩小这两个模型之间的性能差距。大多数 KD 方法集中于图像分类任务,它们以各种形式的知识作为蒸馏目标,例如中间输出 [13, 23]、视觉注意力图 [12, 33]、层间相似度图 [32] 、样本级相似度图[20,27]等。最近,一些研究人员采用传统的KD技术来提取语义分割任务的知识[9,11,17,24,28]。例如,刘等人。 [17]提出同时提炼三个层次的知识,即像素级知识、成对相似性知识和整体知识。他等人。 [9]让学生模仿老师的压缩知识以及亲和力信息。尽管之前的蒸馏算法在 2D 分割上表现出了出色的性能,但由于点云固有的稀疏性、随机性和变化的密度,直接将其部署在 LiDAR 分割任务上会带来边际收益。据我们所知,我们是第一个将知识蒸馏应用于激光雷达语义分割的人。所提出的PVD可以有效地将点级和体素级知识传递给学生,并且适合提炼各种LiDAR语义分割模型。
3. Methodology
给定输入点云 X ∈ RN3,LiDAR 语义分割的目标是为每个点分配一个类标签 l ∈ {0, 1, …, C − 1},其中 N 是点的数量, C是类的数量。当代算法使用 CNN 进行端到端预测。
考虑到自动驾驶汽车通常计算和存储资源有限,并且要求实时性能,因此采用高效的模型来满足上述要求。知识蒸馏[10]被广泛采用,通过将丰富的暗知识从大型教师模型传递到紧凑的学生网络来实现模型压缩。然而,之前的蒸馏方法 [9,17,24,28] 是为 2D 语义分割任务量身定制的。由于点云固有的困难,即稀疏性、随机性和密度变化,直接应用这些算法提取 3D 分割任务的知识会产生不令人满意的结果。为了解决上述挑战,我们提出了点到体素知识蒸馏(PVD)来从点级别和体素级别转移知识。
3.1. Framework overview of Cylinder3D
我服务器托管网们首先简要回顾一下 Cylinder3D 模型[37],然后介绍基于它的点到体素蒸馏算法。以点云为输入,Cylinder3D 首先使用一堆 MLP 为每个点生成相应的特征,然后基于圆柱分区重新分配点特征 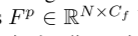 ,其中 Cf 是点特征的维度。属于同一体素的点特征通过maxpooling操作聚合在一起,得到体素特征
,其中 Cf 是点特征的维度。属于同一体素的点特征通过maxpooling操作聚合在一起,得到体素特征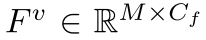 ,其中M是非空体素的数量。接下来,这些体素特征被输入到非对称 3D 卷积网络中,以产生体素输出
,其中M是非空体素的数量。接下来,这些体素特征被输入到非对称 3D 卷积网络中,以产生体素输出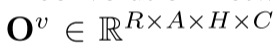 。进一步采用逐点细化模块来产生细化的逐点预测
。进一步采用逐点细化模块来产生细化的逐点预测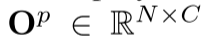 。这里,N、C、R、A和H分别表示点数、类数、半径、角度和高度。最终,我们将使用argmax运算来处理逐点预测,以获得每个点的分类结果。
。这里,N、C、R、A和H分别表示点数、类数、半径、角度和高度。最终,我们将使用argmax运算来处理逐点预测,以获得每个点的分类结果。
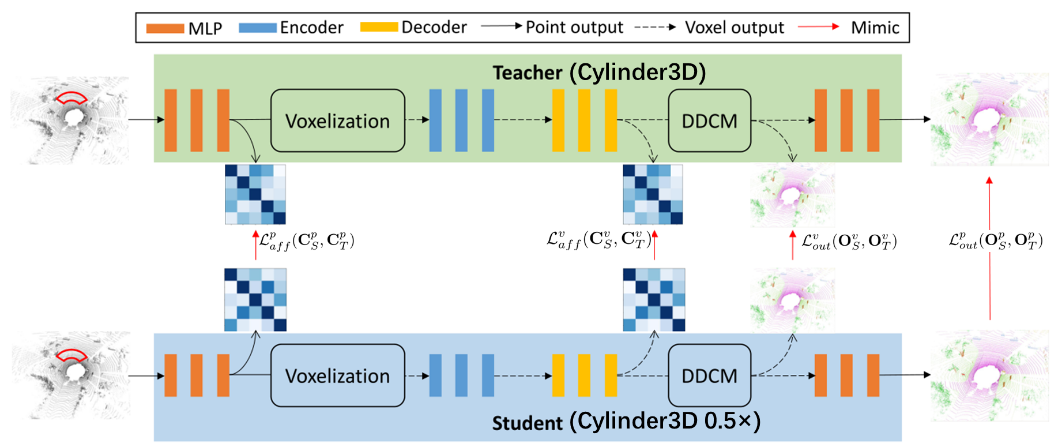
3.2. Point-to-Voxel Output Distillation
2D 和 3D 语义分割之间的主要区别在于输入。与图像相比,点云稀疏,很难利用稀疏的监督信号训练高效的学生模型。以前的蒸馏方法 [10, 17] 通常采用蒸馏教师网络的最终输出,即用于 LiDAR 语义分割的教师网络的逐点输出。尽管逐点输出包含环境的细粒度感知信息,但由于有数十万个点,学习这些知识的效率很低。为了提高学习效率,除了逐点输出之外,我们建议提取体素输出,因为体素的数量更小并且更容易学习。逐点输出蒸馏和体素输出蒸馏的结合自然形成了从粗到精的学习过程。逐点和体素输出蒸馏损失如下:
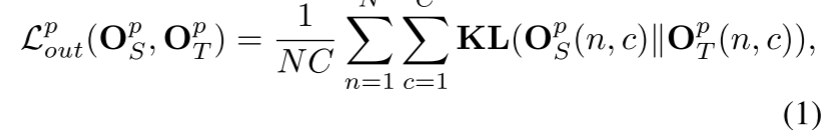
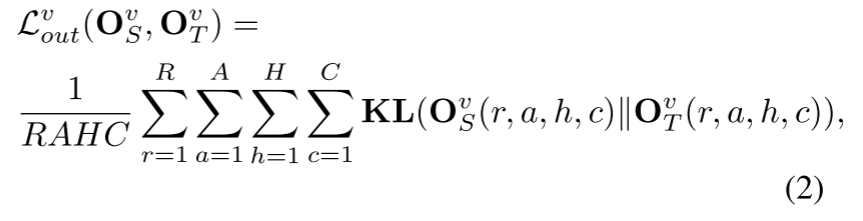 where KL(.) denotes the Kullback-Leibler divergence loss.
where KL(.) denotes the Kullback-Leibler divergence loss.
Labels for the voxelwise output 由于体素可能包含来自不同类别的点,因此如何为体素分配正确的标签对于性能也至关重要。遵循[37],我们采用多数编码策略,使用体素内具有最大点数的类标签作为体素标签。
3.3. Point-to-Voxel Affinity Distillation
提取逐点和体素输出的知识是不够的,因为它仅仅考虑每个元素的知识,而无法捕获周围环境的结构信息。由于输入点是无序的,这种结构知识对于基于激光雷达的语义分割模型至关重要。一种自然的补救措施是采用关系知识蒸馏[17],它计算所有点特征的成对相似度。然而,这种学习方案存在两个缺点:1)由于输入点云中通常有数十万个点,因此具有超过百亿个元素的相似度矩阵的计算成本很高并且极难学习。 2)不同类别和不同距离的物体之间存在显着的数量差异。上述学习策略忽略了这种差异,并平等地对待所有类和对象,从而使蒸馏过程不是最优的。
超体素划分:为了更有效地学习关系知识,我们将整个点云划分为多个超体素,其大小为Rs As Hs。每个超体素由固定数量的体素组成,超体素的总数为 Ns = ⌈ R/Rs ⌉ ⌈ A/As ⌉ ⌈ H/Hs ⌉ 其中 ⌈.⌉ 是上限函数。我们将对 K 个超体素进行采样以执行亲和蒸馏。
难度感知采样:为了使包含不太频繁的类和远处对象的超体素更有可能被采样,我们提出了难度感知采样策略。选择第 i 个超体素的权重为:
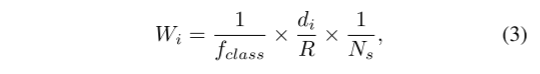
其中 fclass 是类频率,di 是第 i 个超体素的外弧到 XY 平面中原点的距离。我们将占整个数据集中所有点的 1% 以上的类视为多数类,其余类视为少数类。我们凭经验将超体素的类别频率设置为:fclass = 4 exp(−2Nminor) +1,其中Nminor是超体素中少数类别的体素数量。如果没有少数类体素,则fclass将为5。并且随着少数类体素数量的增加,fclass将很快接近1。然后,我们对权重进行归一化,得到第 i 个超体素被采样的概率为: Pi = Wi /Wi 。
点/体素特征处理:注意,对于每个点云,输入点的数量不同,密度也不同,从而使得超体素中点特征和体素特征的数量可变。对于损失函数的计算,最好保持特征数量固定。因此,我们将保留的点特征和非空体素特征的数量分别设置为Np和Nv。如果点特征的数量大于Np,那么我们将通过随机丢弃多数类的附加点特征来保留Np点特征。如果点特征的数量小于Np,我们将在当前特征上追加全零特征以获得Np个特征,如图3(a)所示。体素特征以类似的方式处理。
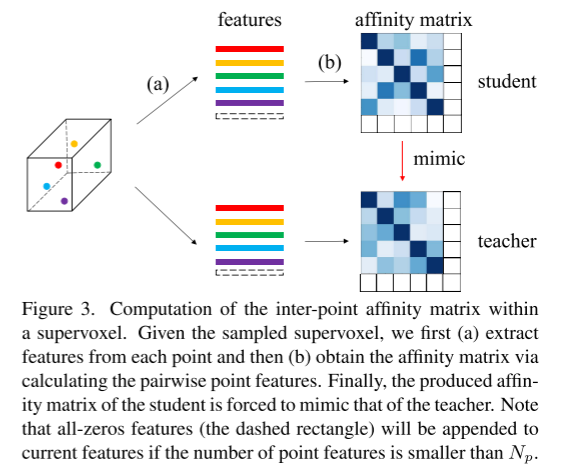
这里,我们在第 r 个超体素中分别有 Np 个点特征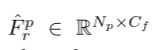 和 Nv 个体素特征
和 Nv 个体素特征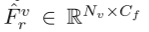 。然后,对于每个超体素,我们根据以下方程计算点间亲和力矩阵:
。然后,对于每个超体素,我们根据以下方程计算点间亲和力矩阵:
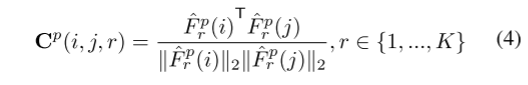
亲和度分数捕获了每对点特征的相似性,可以将其作为学生要学习的高级结构知识。点间亲和蒸馏损失如下:
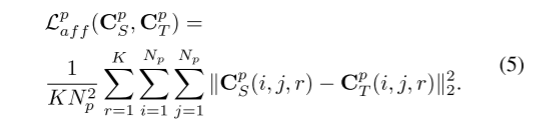
体素间亲和力矩阵的计算方式类似。最终,我们让学生模仿教师模型生成的亲和力矩阵。体素间亲和力蒸馏损失如下:
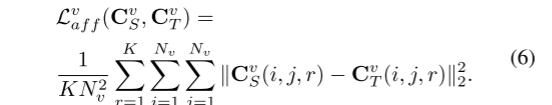
学习到的亲和力图的可视化:从图 4 中,我们可以看到 PVD 导致学生和教师之间的亲和力图更接近。通过PVD,属于同一类的特征被拉近,而不同类的特征在特征空间中被推开,从而产生更加清晰的亲和力图。与竞争对手的通道蒸馏方法[24]相比,PVD可以更好地将结构知识从教师转移到学生,这有力地验证了PVD在蒸馏LiDAR分割模型方面的优越性。
3.4. Final objective
我们最终的损失函数由七个项组成,即点输出和体素输出的加权交叉熵损失、lovasz-softmax损失[2]、点到体素输出蒸馏损失和点到体素亲和力蒸馏损失:
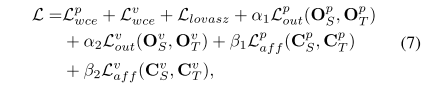
其中1、2、1和2是损失系数,用于平衡蒸馏损失对主要任务损失的影响。
(图中的四个红线,代表mimic损失)
4. Experiments
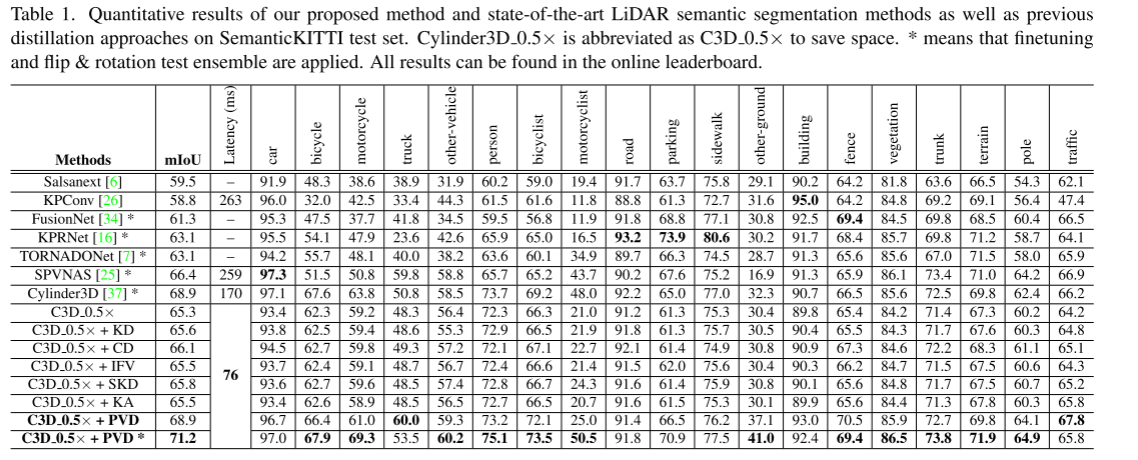
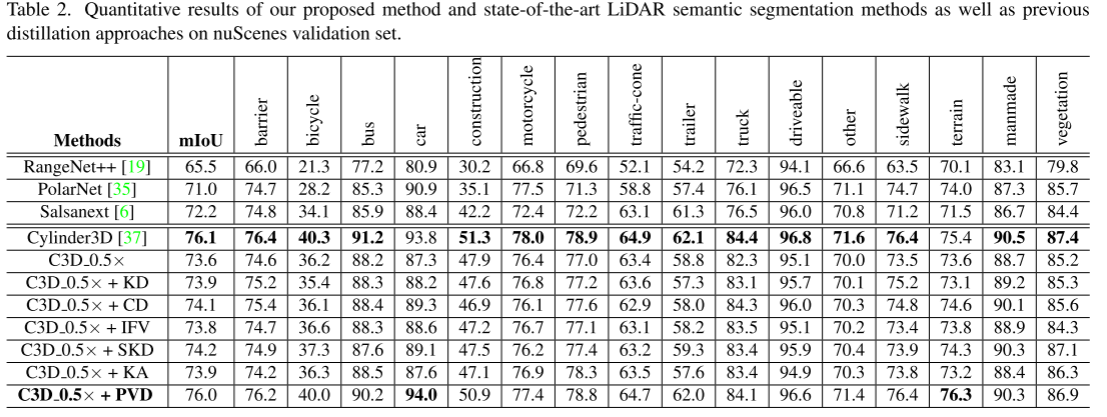
数据集。遵循Cylinder3D [37]的实践,我们在两个流行的LiDAR语义分割基准nuScenes [3]和SemanticKITTI [1]上进行了实验。对于nuScenes,它由1000个驾驶场景组成,其中选择850个场景进行训练和验证,其余150个场景选择进行测试。合并相似类并消除不常见类后,将 16 个类用于 LiDAR 语义分割。对于SemanticKITTI,它由22个点云序列组成,其中序列00至10、08和11至21分别用于训练、验证和测试。合并移动状态明显的班级,舍弃分数很少的班级,共选择19个班级进行训练和评估。
评估指标。按照[37],我们采用每个类的交并集(IoU)和所有类的mIoU作为评估指标。 IoU的计算为:IoUi = TPi TPi+FPi+FNi ,其中TPi、FPi和FNi分别代表第i类的真阳性、假阳性和假阴性。
实施细节。遵循[37],我们利用 Adam [15] 作为优化器,初始学习率设置为 2e-3。批量大小设置为4,训练epoch数为40。1、2、1和2分别设置为0.1、0.15、0.15和0.25。我们采用竞争对手的开源 Cylinder3D2 [37] 方法作为骨干,因为表现最好的 RPVNet [31] 和 AF2S3Net [4] 没有发布它们的代码。采用随机翻转、旋转、缩放和变换作为数据增强策略。体素输出的尺寸为48036032,其中三个维度分别表示半径、角度和高度。超级体素的尺寸设置为120608。 Nv和Np分别设置为3000和6000。采样的超体素数量K设置为4。对点特征提取模块的输出进行点间亲和力蒸馏,对编码器-解码器主干的输出进行体素间亲和力蒸馏。对于 nuScenes,Cylinder3D 0.5 是通过为整个网络的每一层修剪 50% 的通道从原始 Cylinder3D 模型生成的。对于 SemanticKITTI,Cylinder3D 0.5 是通过仅为非对称 3D 卷积网络的每一层修剪 50% 的通道而获得的,并且我们保持点特征提取模块不变,因为从输入点云中提取丰富的信息至关重要。我们还应用我们的方法来压缩 SPVNAS3 [25] 和 MinkowskiNet [5] 以验证我们算法的可扩展性。补充材料中提供了更多详细信息。
基线蒸馏算法。除了每个基准测试中最先进的方法之外,我们还将我们的方法与经典 KD 方法和为 2D 语义分割量身定制的当代蒸馏方法进行比较,包括普通 KD [10]、SKD [17]、CD [24]、 IFV [28] 和 KA [9]。这里,SKD将输出概率图和成对相似度图作为模仿目标。我们消除了 SKD 的原始整体蒸馏损失,因为将 GAN 纳入当前框架将导致严重的训练不稳定; CD利用中间特征图和分数图作为知识; IFV将类内特征变化从教师转移到学生; KA使学生提炼出教师整体输出的压缩知识和亲和力信息。
4.1. Results
与最先进的 LiDAR 分割模型的比较:我们将我们的模型与当代 LiDAR 语义分割模型进行比较,例如 KPConv [26]、TORNADONet [7] 和 SPVNAS [25]。从表1中我们可以看到,Cylinder3D 0.5+PVD(倒数第二行)在SemanticKITTI测试集上实现了与原始Cylinder3D模型相当的性能。与 KPConv 和 SPVNAS 相比,我们的 Cylinder3D 0.5+PVD 不仅实现了更好的性能,例如,在 mIoU 方面比 SPVNAS 高 3.8%,而且比 SPVNAS 方法具有更低的延迟(259 ms vs 76 ms)。具体来说,在自行车、摩托车和骑自行车的人等少数类别上,Cylinder3D 0.5+PVD 的 IoU 比 SPVNAS 方法至少高 10.5%。通过微调、翻转和旋转测试集成等工程技巧,我们的 Cylinder3D 0.5+PVD(最后一行)可以获得 71.2 mIoU,比原始 Cylinder3D 模型高 2.3 mIoU。在 nuScenes 验证集中也观察到了令人印象深刻的性能。我们的 Cylinder3D 0.5+PVD 在整体 mIoU 和每个类别的 IoU 方面表现出与原始 Cylinder3D 网络相似的性能。
与之前的蒸馏方法的比较:从表 1 和表 2 中我们可以看到,PVD 在两个基准测试中都显着优于基线蒸馏算法。 PVD与最具竞争力的KD方法之间的性能差距大于1.8。例如,在 SemanticKITTI 测试集上,我们的 PVD 比 CD 方法高 2.8 mIoU。在多数类别和少数类别上,我们的 PVD 显着优于传统的蒸馏算法。例如,在 nuScenes 数据集上,在自行车、公共汽车、汽车、拖车和人行道等类别中,PVD 至少比 SKD 高 2 mIoU。上述结果有力地证明了PVD在师生学习知识迁移方面的有效性。
泛化到更多服务器托管网架构:为了验证我们方法的泛化性,我们还应用 PVD 来压缩 SPVNAS [25] 和 MinkowskiNet [5]。由于SPVNAS不提供基于NAS架构的训练代码,因此我们对其手动设计的架构进行了实验。从表 3 中可以看出,与基线蒸馏算法相比,我们的 PVD 仍然为学生模型带来了更多的收益。例如,就 SPVNAS 主干上的 mIoU 而言,我们的 PVD 比 SKD 算法高出 2.6 mIoU。值得注意的是,PVD 可以安全地实现 75% 的 MAC 减少,而不会造成严重的性能下降。上述结果有力地证明了我们方法的良好可扩展性。
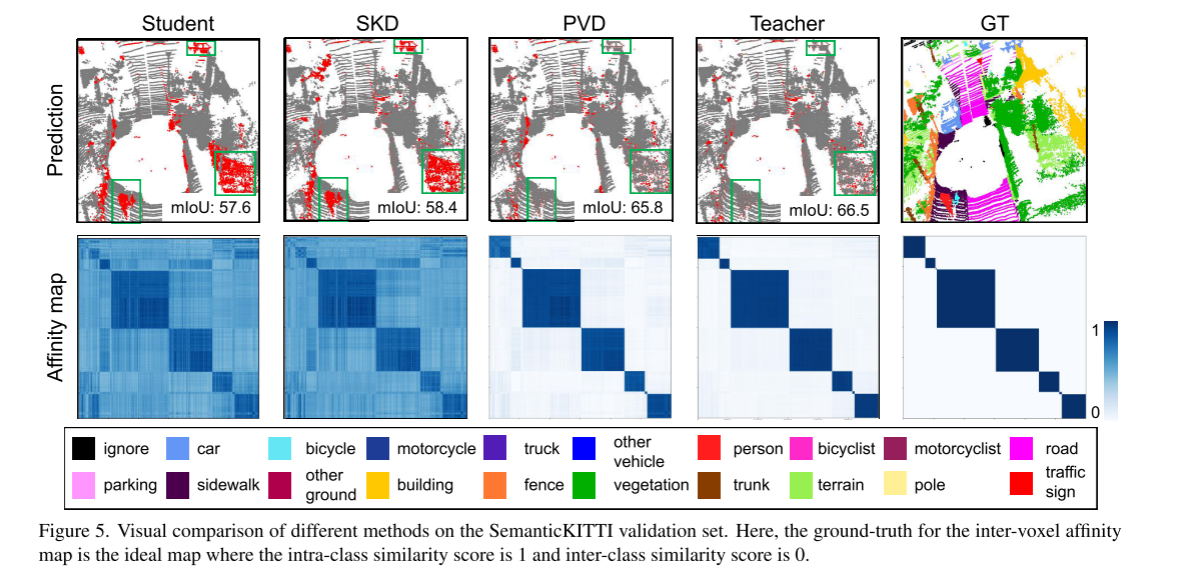
定性结果:从图5中可以看出,与SKD方法相比,我们的PVD极大地提高了学生模型的预测。 PVD 对少数类别(例如人和自行车)的预测误差明显小于 SKD。此外,对于远离原点的物体,例如绿色矩形突出显示的汽车,PVD 也能比 SKD 产生更准确的预测。 PVD具有较低的类间相似度和较高的类内相似度,这明确地展示了PVD从教师模型中提取结构知识的功效。
4.2. Ablation studies
在本节中,我们进行全面的消融研究,以检查每个组件的功效、超体素大小以及采样策略对最终性能的影响。实验在 SemanticKITTI 验证集中进行。补充材料中包含更多消融研究。
各成分的作用。从表 4 中,我们得到以下观察结果: 1) 结合点到体素输出蒸馏和亲和蒸馏带来最大的性能增益。 2)体素级蒸馏比点级蒸馏带来更多的增益,这表明引入体素级模仿损失的必要性。3)亲和蒸馏比输出蒸馏产生更多的收益,这证明了利用关系知识更好地捕获结构信息的重要性。

超体素大小。请注意,我们对采样的超体素进行点间和体素间蒸馏。超体素尺寸对PVD的效果具有不可忽视的影响,因为尺寸过小会使学生从亲和力蒸馏损失中学到很少,而大的超体素尺寸会削弱PVD的学习效率。在这里,我们将采样的超体素数量保留为 4,以消除该因素的影响。从表 5 中我们可以看到,将超级体素大小设置为 (120,60,8) 可获得最佳性能。显着增加或减少超体素尺寸将损害蒸馏效率。
抽样策略。我们比较了四种不同的采样策略,即原始难度感知采样、距离感知采样、类别感知采样和随机采样。在这里,距离感知采样只是更频繁地采样远处的点,而类别感知采样更有可能采样属于稀有类别的点。从图 6 可以看出,困难感知采样比其他三种策略带来更多的收益。具体来说,难度感知采样优于距离感知和类别感知采样,这表明距离和类别感知对于蒸馏效果都至关重要。困难感知抽样与随机抽样之间的巨大差距验证了困难感知抽样策略的必要性。
5、Conclusion
在本文中,我们提出了一种专为 LiDAR 语义分割量身定制的新型点到体素知识蒸馏方法(PVD)。 PVD 由点体素输出蒸馏和亲和蒸馏组成。进一步提出了超体素划分和难度感知采样策略,以提高亲和蒸馏的学习效率。我们在两个 LiDAR 语义分割基准上进行实验,结果表明 PVD 在蒸馏 Cylinder3D、SPVNAS 和 MinkowskiNet 方面明显优于基线蒸馏算法。令人印象深刻的结果表明 3D 分割模型中仍然存在大量冗余,我们的方法可以作为压缩这些繁琐模型的强大基线。
自己总结:
1、点对点蒸馏,体素对体素
2、超体素,包含多个体素,在K个超体素内进行亲和力蒸馏
3、难度采样
4、测试时采用增强,最终学生网络效果优于教师网络
参考博客:
知识蒸馏原理与PVKD论文阅读_昼行plus的博客-CSDN博客
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 龙芯发布 .NET 8 SDK 8.0.100-rc2 LoongArch64
随着.NET 8的发布的临近,国内的社区朋友们也很关心龙芯.NET 团队对于Loongarch .NET 8的发布时间,目前从龙芯.NET编译器团队的可靠信息,Loongarch .NET 8的发布会在2023年11月14日正式发布后也会发布,从龙芯2019年…
