
RPVNet: A Deep and Efficient Range-Point-Voxel Fusion Network for LiDAR Point Cloud Segmentation
Xu等人(2021b)
RPVNet:用于 LiDAR 点云分割的深度高效的距离-点-体素融合网络
我们设计了一个深度融合框架,在这三个视图之间具有多重和相互信息交互,并提出了一个门控融合模块(称为GFM),它可以根据并发输入自适应地合并三个特征。此外,所提出的 RPV 相互作用机制非常有效,我们将其总结为更通用的公式。通过利用这种有效的相互作用和相对较低的体素分辨率,我们的方法也被证明更加有效。
在本文中,我们提出了一种深度的、自适应的距离-点-体素融合框架,旨在协同所有三个视图的表示。更具体地说,如图4所示,我们设计了一种以点为中间主机的融合策略,并将范围像素和体素单元上的特征传输到点,然后应用自适应特征选择以便为每个点选择最佳特征表示,最后将点上的融合特征传输回范围图像和体素。与之前在网络前端或网络末端融合的其他多视图融合方法[6,42,33,20,39,14]相比,我们的方法在网络中多次进行上述融合,这允许不同的融合意见以更深入、更灵活的方式相互促进。至于效率:首先,我们利用哈希映射提出了一种高效的RPV交互机制。其次,我们在体素分支中使用相对较低的体素分辨率和稀疏卷积。第三,我们在类似于[21]的点分支上执行简单的MLP,摆脱低效的局部邻居搜索。最后,我们采用高效的范围分支来减少计算量。此外,我们发现数据集中的类别极其不平衡,因此我们在训练阶段设计了一个实例 CutMix 增强来缓解类别不平衡问题。
3.1.框架概述
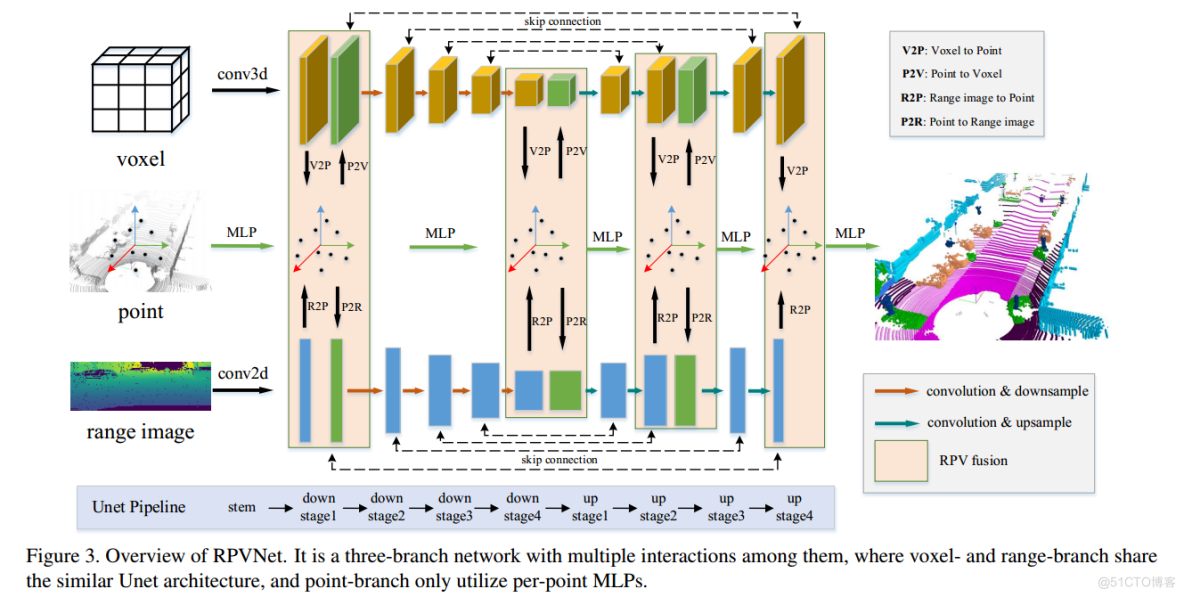
所提出的方法 RPVNet 的框图如图 3 所示。它是一个三分支网络,它们之间有多个交互。从上到下,三个分支分别是体素分支、点分支和范围分支。我们对体素分支和范围分支使用非常相似的 Unet。 Unet结构首先使用stem从原始输入中提取上下文信息,然后执行四个下采样阶段,最后连接四个上采样阶段以恢复原始点。 Pointbranch 是一个极其简单的 PointNet [24],有几个MLP。 RPV融合发生在stem、第四次下采样、第二次上采样和最后一个上采样阶段之后,为了公平比较,这与SPVCNN[30]相同。多视图交互的细节将在下一节中说明。
3.2.高效的多视图交互学习
原始点云可以转换为不同的视图,通常是体素和范围图像,因此点可以作为中间载体在这些视图之间建立连接,任何形式的点云表示都可以看作是原始点的映射。因此,我们通过构建多视图表示索引和多视图特征传播来实现高效的多视图交互式学习。通过索引系统实现多视图的统一特征映射和表示。通过特征传播获得多视角特征交互和学习。因此,我们在我们提出的 RPVNet 中构建了范围-点-体素交互模块,这将在下面详细介绍。
多视图表示索引。
给定点形式为 P ∈ R N(3+C) 的点云,我们可以通过某种“投影”函数将其转换为任何其他形式 X ∈ RMD,其中 N 表示点的数量,3 表示其在欧氏空间中的xyz坐标,C是该点的特征通道,M表示X形式的元素数量,D是指示其位置信息的维度。为了构建 P 和 X 之间的连接,我们首先使用“投影”函数
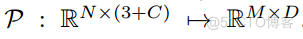
,随后是哈希函数
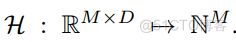
。这样我们就可以构建一个从P到X的哈希映射,这是一种高效的搜索。我们将X表示为点云的任意表示,任何形式的点云表示X都可以看作是原始点P的映射。需要注意的是,“投影”函数P可以是多对一的映射,在我们的例子中,哈希函数 H 是一对一的映射。
多视图特征传播。
其他形式的点云表示X中元素j的特征受到相应原始点的影响。而且,由于“投影”函数P可能是非注入的,j往往会受到P中多个密钥的共同影响。将j的所有密钥定义为

,j 的特征从相应的键传播。一般来说,从一个观点到另一个观点的特征传播可以表述为:
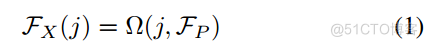
其中FX ∈ RMD,FP ∈ R N(3+C)是X和P的特征,()表示加权函数(例如平均、最大值)。
相反,我们将逆特征传播函数定义为(),它反映了从其他视点到点的信息流。公式如下:
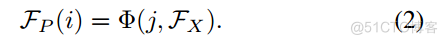
其中 i 表示 P 中的一个点。
范围-点-体素交互
基于点的表示保留了几何细节并捕获细粒度信息,这对于某些小实例(例如行人、自行车)是友好的。基于体素的表示将点映射到规则的3D网格中,同时保持空间结构,从而有效地提取各种3D维度的信息。然而,体素分辨率的存在会引入量化损失。基于范围的表示将稀疏点转换为结构化且稠密的图像,大感受野为大规模类别带来更丰富的语义信息。为此,我们有效地利用了这三个视图的信息,并实现了它们之间的交互学习,以提高各个类别的性能。
如上所述,我们首先建立Range-PointVoxel索引系统。具体包括从点到范围视图和体素表示的投影索引和体素化索引。投影索引是通过将点投影到球面上以生成距离图像来制定的,如[32]中所示。通过距离化,我们得到一个距离图像 R ∈ R HWD,其高度为 H,宽度为 W,以及地图中点的归一化坐标 G = (n; m),其中归一化坐标表示地图上任何规模的点。除了点和范围图像之间的映射之外,我们还通过将输入点云 P 转换为稀疏体素表服务器托管网示 V 来表示体素化索引。对于不同的体素大小 r,“投影”映射为
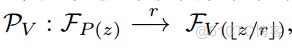
,其中 z 是点坐标。
基于Range-Point-Voxel索引系统,我们进一步进行彼此的特征传播。在这项工作中,我们使用平均将特征从 Point 传递到其他两个视图。因此,我们可以将方程1中的(j; FP )重写如下:
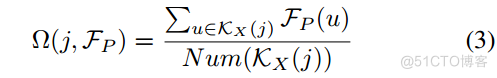
其中Num()表示计数函数,u表示KX(j)的元素。此外,特征的偏导数可以计算为:
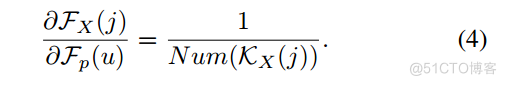
此外,对于其他视图到点视图的特征传播函数,为了简单起见,最近邻插值可以实现为
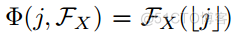
此外,我们遵循[30]的实现,它利用带有八邻域体素网格的三线性插值来实现体素的点视图。类似地,我们的范围到视点过程使用双线性插值方法:
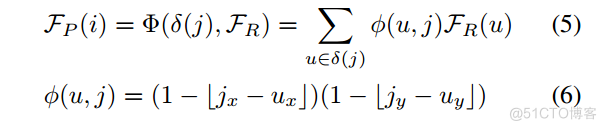
其中 () 计算双线性权重,(j) 表示 j 的四邻域网格。因此,偏导数为
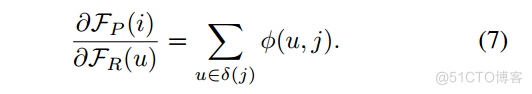
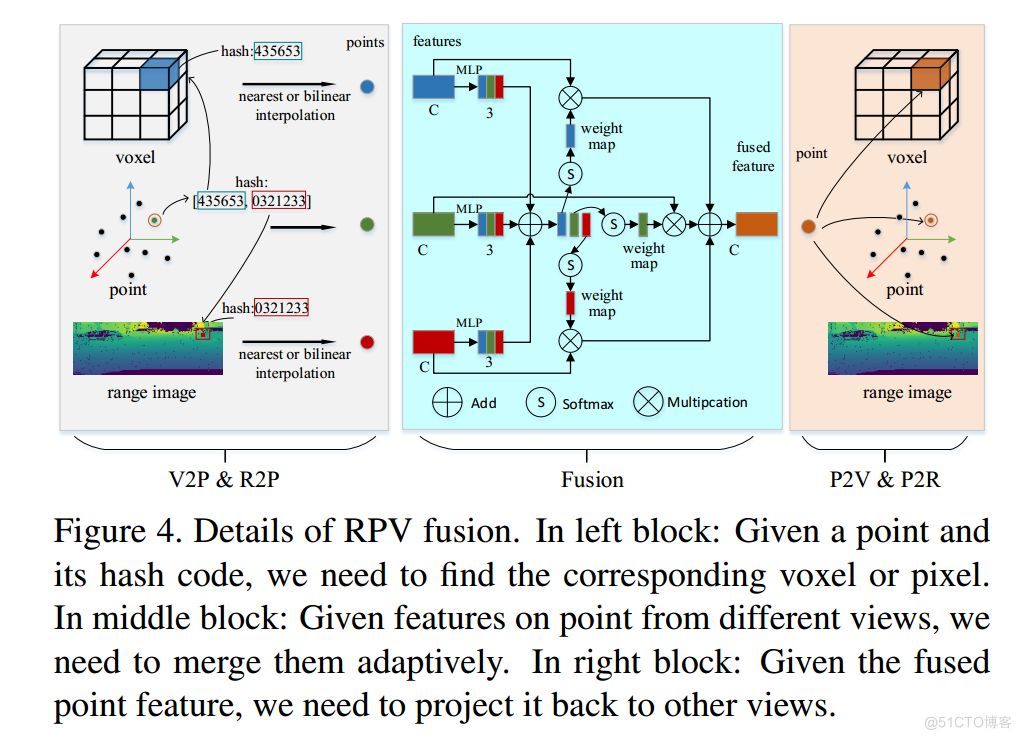
图 4. RPV 融合的详细信息。在左块中:给定一个点及其哈希码,我们需要找到相应的体素或像素。
在中间块:给定来自不同视图的点特征,我们需要自适应地合并它们。在右块中:给定融合点特征,我们需要将其投影回其他视图。
3.3.门控融合模块(GFM)
给定来自不同视图分支的L个特征向量Xi ∈ R NiCi,Ni ,Ci 分别是第i个特征向量的点数和通道数。多视图特征融合的本质任务是在大量无用信息的干扰下将有用信息聚合在一起。加法和串联是聚合多个特征的常用操作,但它们都会受到大量非信息特征的影响。
它们可以表述为:
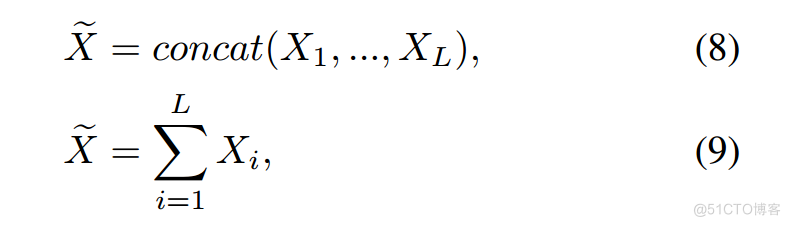
其中~X是融合的特征向量。不同视图分支的特征由于其可变性而重要性不一致。但上述初级融合策略忽略了每个特征向量的有用性,在融合过程中将大量无用特征与有用特征结合起来。
受成熟的门控机制[9,29,19]的启发,门控机制可以通过测量每个特征的重要性来自适应地聚合信息,我们的门控融合模块是在正常的基于加法的融合的基础上,通过门过滤信息流来设计的。正式定义为:
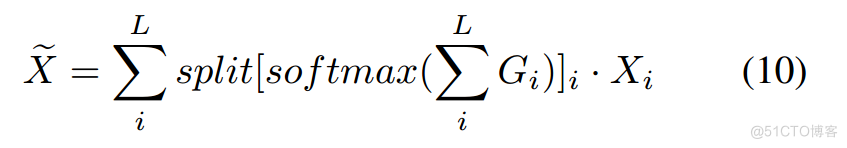
其中 表示逐元素乘法,Gi ∈ [0; 1]NL表示第i个表示的门向量。每个门向量每个表示有L个通道。每个通道上的特征权重投票通过求和叠加,并通过softmax转换为概率权重。最后,将相应通道上的结果分开以对输入特征进行加权。每个门向量 Gi = sigmoid(wi ∗ Xi) 由参数化为 wi ∈ R 1LCi 的卷积层估计。详细操作见图 4(b)。
3.4. Instance CutMix
尽管一些针对室内点云的数据增服务器托管网强方法[18,7,40]已被证明是有效的,但针对室外场景的研究却很少。受过去基于混合的方法的启发,我们提出了实例混合来应对激光雷达语义分割的不平衡类问题。
根据经验,如果允许不太频繁的对象在场景中重复出现,网络可以更准确地预测这些对象。受这一发现的启发,我们从训练集中的每一帧中提取稀有类对象实例(例如自行车、车辆)到一个迷你样本库中。训练时,样本从小样本池中按类别均匀随机选取。然后,将对这些样本进行随机缩放和旋转。为了确保与现实紧密契合,我们将对象随机放置在地面类点上方。最后,将其他场景中的一些新的稀有物体“粘贴”到当前的训练场景中,以模拟各种环境中的物体。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 秦淮数据财报:秦淮数据2023年的收入将下滑,盈利能力将减弱
秦淮数据2023年指引没有达到市场预期3月中旬,秦淮数据(CD)发布了2023年的财务指引。秦淮数据预计,2023财年全年收入将在58.88亿元至60.8亿元之间,正常化EBITDA将在30亿元至31.1亿元之间换句话说,根据其指引的中点,秦淮数据预计其202…
