
本文分享自华为云社区《MRS HBase全局二级索引原理与使用场景》,作者:学习一下大数据 。
一、HBase二级索引背景介绍
HBase是基于Key-Value的分布式存储数据库,对表中的数据按照rowkey的字典进行排序;当已知要查询的数据rowkey或其范围,可以快速查找到需要读取的数据;HBase提供Filter功能来查询具有服务器托管网特定列值的数据,当无法确定rowkey范围时,条件查询会劣化为全表查询,表数据量较大的场景下,查询容易超时,无法满足查询时延要求。
与结构化数据库(例如MySQL)相似,HBase二级索引就是为了提升此类条件查询场景性能:查询条件无法精确/模糊匹配rowkey(类似于DB主键),同时严格要求查询时延。
二、MRS HBase二级索引原理
用户可以将定义经常查询的列定义为索引列,通过冗余存储索引列数据以达到加速查询的效果,将时间不可控的全表条件查询转换为区间条件查询,从而做到查询低时延。
MRS提供两种HBase二级索引:本地索引(HIndex)和 全局索引(GSI);两者的区别是:
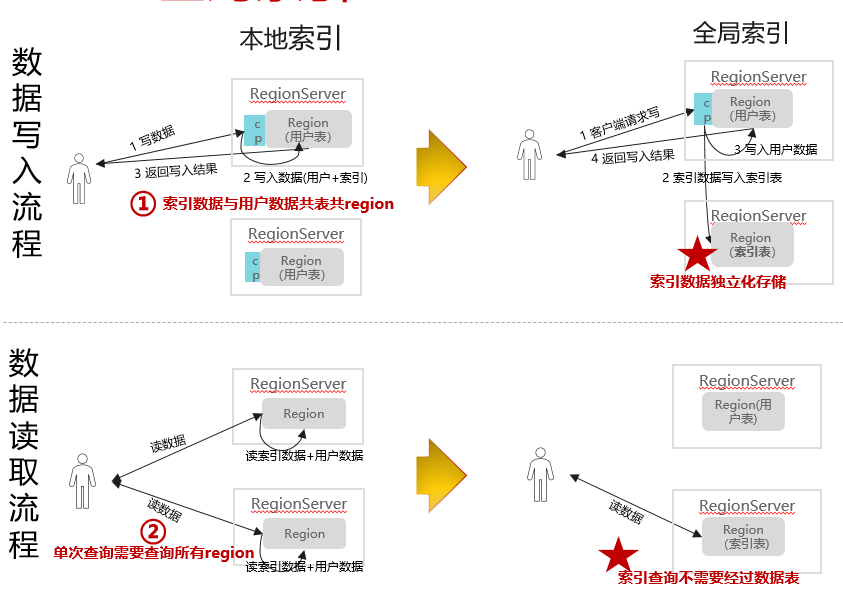

- 索引数据存储方式:本地索引存储索引数据到用户表的一个单独的列族中,全局索引存储到一个索引表中(索引数据独立存储)。
- 写入流程:本地索引一次性写入用户数据和索引数据,全局索引需要先后写入索引表和数据表。
- 读取流程:本地索引需要读取所有region的索引+用户数据,全局索引读取索引表(覆盖查询列场景下,不经过数据表)或索引表+数据表。
MRS 3.x版本提供了HBase全局索引能力,相较于本地索引,具有的优势有:
- 索引数据独立存储,解耦用户数据,稳定性更优。
- 索引查询链路优化,支持覆盖列(支持全覆盖),可以将经常查询的非索引列冗余存储到索引表,避免从原表获取数据,同时减少了查询过程中内部的RPC操作,在大规模数据场景下,查询性能更优。
此外,全局索引还提供以下工具,用于索引的维护:
- 索引创建/删除/状态修改工具
- 索引数据批量构建工具
- 索引数据一致性校验工具
三、MRS 全局二级索引使用场景
全局二级索引适用于以下场景:
- 经常使用固定条件(非rowkey)查询
- 查询时延有严格要求
- 用户表的数据量较大(region数量较多)
- 读多写少,对写入时延无严格要求(为保障索引数据一致性,全局索引采用分阶段式写入的方式,写入时延会有一定上升)
全局二级索引同时需要考虑,预留足够存储空间给索引表,索引数量/覆盖列/索引列越多,需要的空间越大,极限场景(全覆盖)下,与数据表大小相当。
四、MRS HBase全局二级设计与实战
基于HBase全局二级索引查询时,并非所有查询都能命中索引进行加速(HBase全局二级索引的使用规范详见用户手册),想要利用好索引功能,必须根据查询条件设计好索引。
以下实例展示了城市地点人流量统计功能实现,包括索引设计、查询条件等。
数据表定义
create 'city','cf',{SPLITS=>['0','1','2','3','4','5']}
rowkey定义:数据id(随机数字id,用于离散数据)
|
列名 |
含义 |
|
cf:city_id |
城市id(0-9) |
|
cf:locat服务器托管网ion_id |
场所id(0-9) |
|
cf:visitors_nums |
人流量数值 |
|
cf:time |
时间点(整小时) |
索引定义
索引名:idx_vn_time
索引字段:cf:visitors_nums+cf:time
覆盖列:全覆盖
该索引用于筛选人流量较大的地区信息
数据表查询对比
预置数据:10MB,预分区11个region,HBase集群节点3个
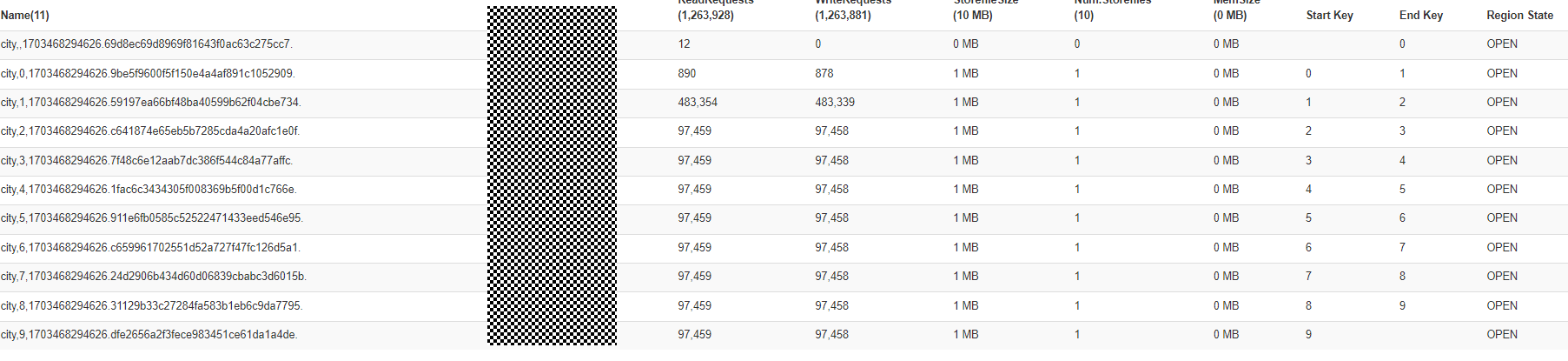
查询条件1:查询人流量大于9000的地区信息
scan 'city',{COLUMN=>'cf', FILTER=>"SingleColumnValueFilter('cf','visitors_nums',>=,'binary:9000')"}
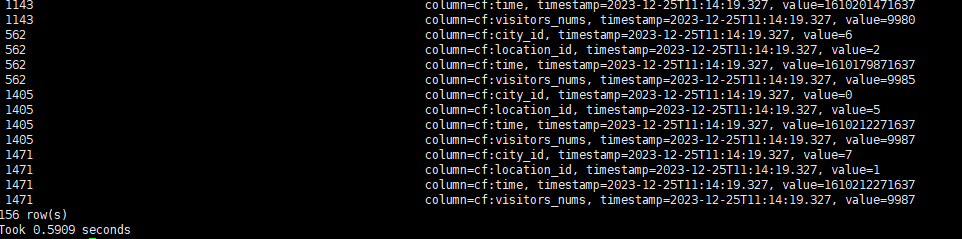
禁用索引后再次查询
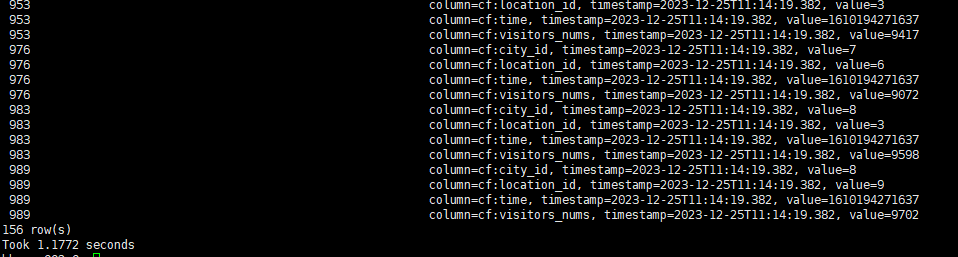
查询条件2:查询2021-01-10 0点-12点,人流量大于9000的地区信息
scan 'city',{COLUMN=>'cf', FILTER=>"SingleColumnValueFilter('cf','visitors_nums',>=,'binary:9000') AND SingleColumnValueFilter('cf','time',>=,'binary:1610208000000') AND SingleColumnValueFilter('cf','time',
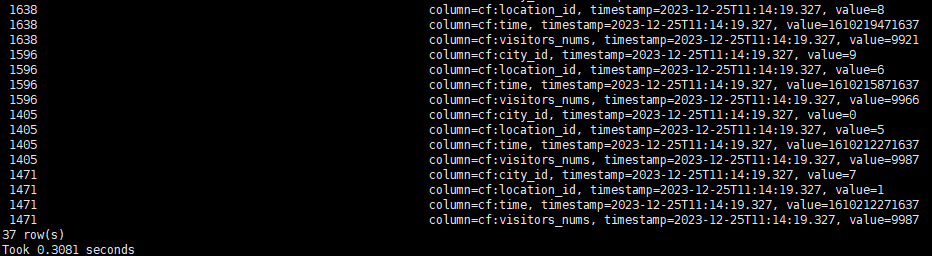
禁用索引后再次查询
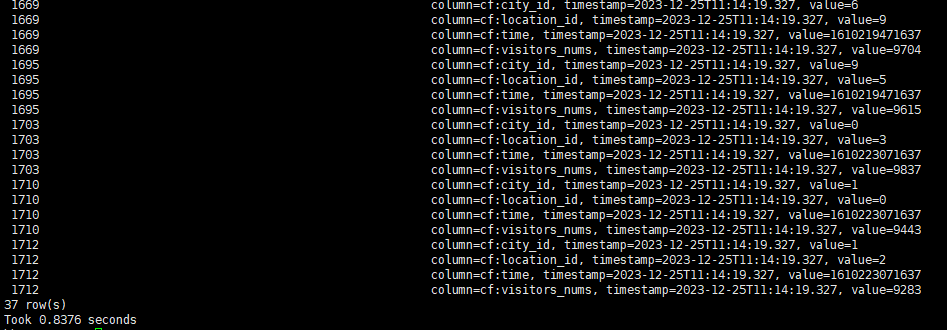
可以看到,命中索引时,查询效率提升十分明显,即使在小表上,也能获得数倍的性能提升。
注:命中索引后的查询结果按索引定义排序
点击关注,第一时间了解华为云新鲜技术~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
引言: 背景是我现在要跑的实验在一台服务器上跑有点来不及了,需要将conda环境和文件一起迁移到另一台服务器上。文件的迁移可以用scp或者rsync。但是conda虚拟环境的迁移则不行。 步骤: step 1 将当前的虚拟幻境信息写入environment.y…
