

本文探讨了一系列语言大模型的推理优化技巧,涵盖KV缓存、量化和稀疏性等方法,并分享了如何有效实施这些技术。对于想要优化Transformer模型,以期提升推理速度或效率的人来说值得一读。
本文作者为机器学习研究员Finbarr Timbers,他曾是DeepMind的工程师。 (本文由OneFlow编译发布,转载请联系授权。原文: https://www.artfintel.com/p/transformer-inference-tricks)
作者 |Finbarr Timbers
OneFlow编译
翻译|杨婷、宛子琳
1
键值(KV)缓存
目前,键值(KV)缓存是最常见(也是最重要)的解码器优化方法。在解码器模型中,对于每次解码迭代,提示的键和值将是相同的。此外,一旦你运行了一个词元,该词元的键和值将在后续的每个迭代中保持不变。因此,你可以缓存提示,并在解码时逐渐将每个词元的KV张量添加到缓存中,这样可以减少大量计算。在注意力机制中,我们能够将形状为(batch, context_length, feature_dim)的两个张量相乘,变为将形状为(batch, 1, feature_dim)的查询张量与形状为(batch, context_length, feature_dim)的KV张量相乘。因此,采样的复杂度不再是二次方,这使我们能够获得更长上下文长度的良好解码(采样)性能。
实际上,这会在你的实现中增加复杂性,因为现在你不仅仅是运行纯函数,而且有了状态(state),所以即便一个序列已经完成了推理,你仍需要持续运行推理(参见Google MaxText的实现,https://github.com/google/maxtext)。
KV缓存需要2 * n_layers * n_heads * d_head个参数。对于GPT-3,其中n_layers = 96,n_heads = 96,d_head = 128,这意味着每个上下文中的词元需要2.4m个参数。使用典型的16位精度,每个词元需要5MB;如果上下文窗口有2048个词元,那就需要将10GB的HBM用于KV缓存。这虽然昂贵,但每GB的消耗都物有所值。
这些内存需求是在消费级GPU上训练语言大模型如此困难的重要原因之一。目前最强大的消费级显卡是4090,只有24GB的HBM。虽然其每秒浮点运算次数(FLOPS)可与企业级芯片相媲美,但其内存限制要低得多,这使得难以将权重和KV缓存置入内存。
2
推测性解码
推测性解码是一种在计算能力充裕时使用的技术,通常用于本地推理设置。它利用了现代加速器的特性,即在批次数据上运行推理所需的时间与在单个数据点上运行推理的时间相同。以A100为例,你可以在相同的时间内对多达160个数据点进行推理,所需推理时间与单个数据点相同。因此,现在已经出现了许多利用这一特性的技术,如束搜索(beam search)、MCTS(蒙特卡洛树搜索)或推测性解码。
推测性解码包括两个模型:一个小而快的模型以及大而慢的模型。由于现代解码器的推理速度与参数数量成正比,使用较小的模型可以在大型模型运行一次推理所需的时间内运行多次推理。
现代解码器模型(如GPT系列)使用了自回归采样技术,即要对N个词元的序列进行采样,模型会进行N次推理,每次推理都要使用前一次推理的结果。
在推测性解码中,你会并行运行这两个模型。快速模型会运行一批推理并猜测大模型将预测哪些词元,然后将这些猜测相叠加。与此同时,大模型在后台运行,检查较小模型是否记录了相同结果。较小模型能够在大模型进行一次推理的时间内进行多次猜测。然而,鉴于我们有多余的计算能力,大模型能够并行评估所有猜测。因此,我们支付顺序生成序列成本的唯一地方是在较小的模型上。

推测性解码的主要缺点是它需要一个“草稿(draft)”模型,该模型能够预测较大模型的输出,而且你必须让两个模型同时存在于同一台机器的内存中(或者在多GPU设置下的同一节点上)。这增加了复杂性,需要额外的工作,因为你必须训练两个模型(原始模型和“草稿”模型)。此外,任何性能提升都受限于小模型能够在多大程度上精确地预测大模型。如果小模型始终能够准确预测大模型的行为,那么我们就可以直接使用它!因此,推测性解码能够发挥作用的程度存在根本差距。HuggingFace声称它通常可以将解码速率提高一倍,这与原始论文(https://arxiv.org/abs/2211.17192)中声称的2至3倍的提升一致。
最近出现了一种试图改进推测性解码的前向解码(Lookahead Decoding)技术(https://lmsys.org/blog/2023-11-21-lookahead-decoding/),该技术让模型生成n-gram,然后在无需草稿模型的情况下递归匹配这些n-gram。这种技术被称为Jacobi解码(来自他们的博客截图),可能是对贪婪解码的潜在改进。Jacobi解码的工作原理是在生成词元的每一点上生成n个词元,对整个序列进行“猜测”。然后,将其与先前的猜测相验证,如果两者匹配,就接受该猜测。这可以在没有副作用的情况下减少时延,因为在最坏的情况下,它会变成贪婪解码。
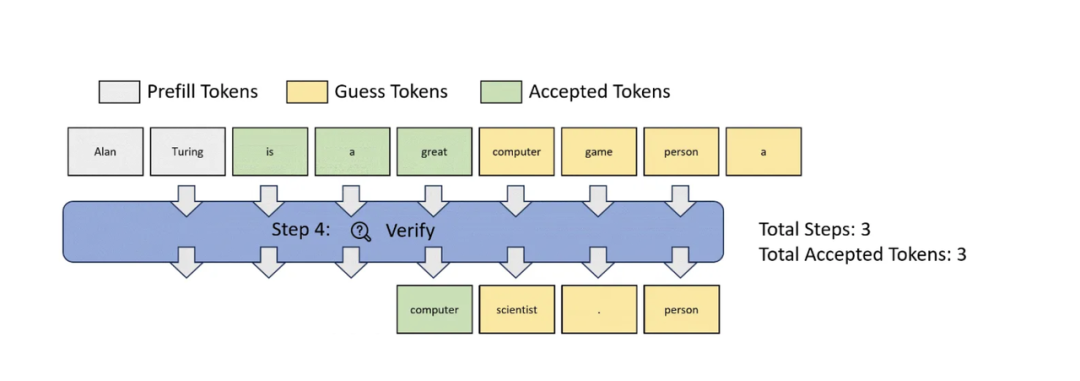
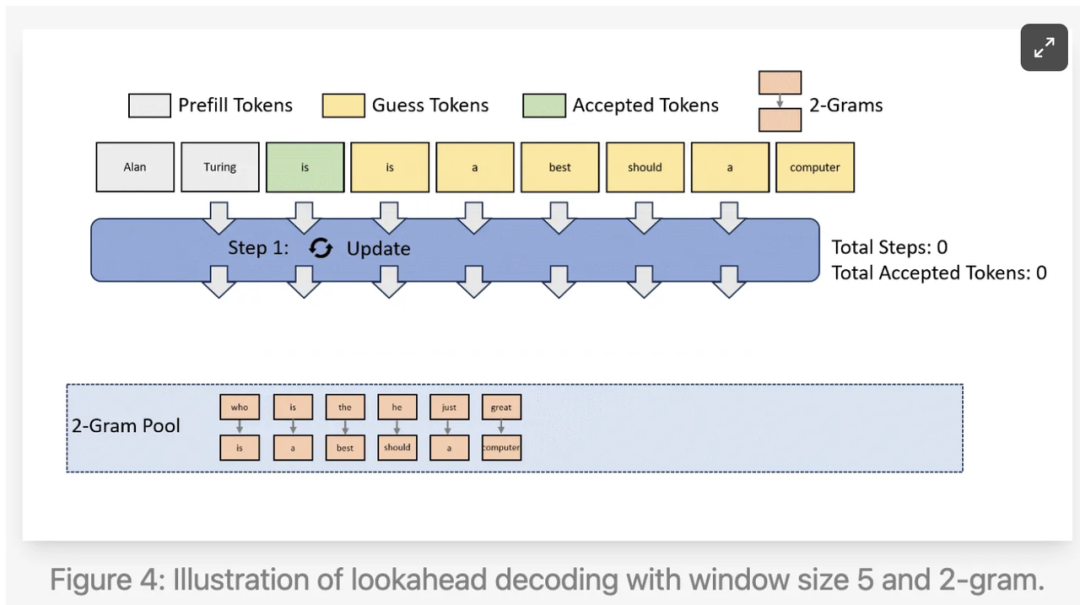
前向解码通过保留解码过程中生成的n-gram,并尝试将它们用作猜测,进一步改进了这一技术。鉴于已生成的文本与将要生成的文本之间存在很高的相关性,这也有可能以极低的成本,显著改进时延。这一技巧非常巧妙。考虑到这项技术才发布不久,我非常好奇它在实际场景中的性能表现。
3
有效稀疏性
在仅解码器Transformer中,模型核心是注意力机制,可总结为如下的注意力方程:
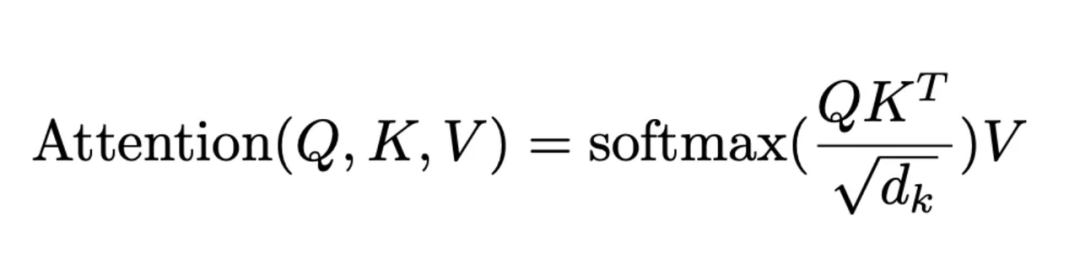
softmax操作会使非最大值变得很小。

因此,我们将数值张量(在注意力方程中用V表示)与一个主要由零(zero)组成的张量相乘。结果,注意力机制的输出中包含了大量的零,最高可达97%(https://x.com/YesThisIsLion/status/1647747069086666752?s=20)。类似地,在多层感知器网络(MLP)中的每个ReLU之后,我们也得到了大量稀疏性。
不幸的是,现在要实际利用这一点比较困难。如果权重中存在稀疏性,那么可通过结构化稀疏性(例如torch.sparse)做大量工作,但目前还不清楚系统能够多大程度地利用激活的稀疏性。
可以进行的一个优化是:如果某个激活为零,服务器托管网那么可以跳过加载与该激活对应的权重,并避免相应计算。据我所知,这并未很好地得到主流张量计算程序的支持,但对于Llama.cpp等自定义推理实现来说,这一优化比较容易实现。
这是因为激活是每个词元的函数,因此有效稀疏性也是随机分布在词元上。因此,这种优化的效果会随着批大小的增加呈指数级衰减。假设我们的有效稀疏性为X%,批大小为N,那么对于一个给定激活的所有条目在整个批次中都为零的概率可以表示为X^N。我制作了一张表格,列出了不同X和N值的情况。这种衰减效应非常显著。
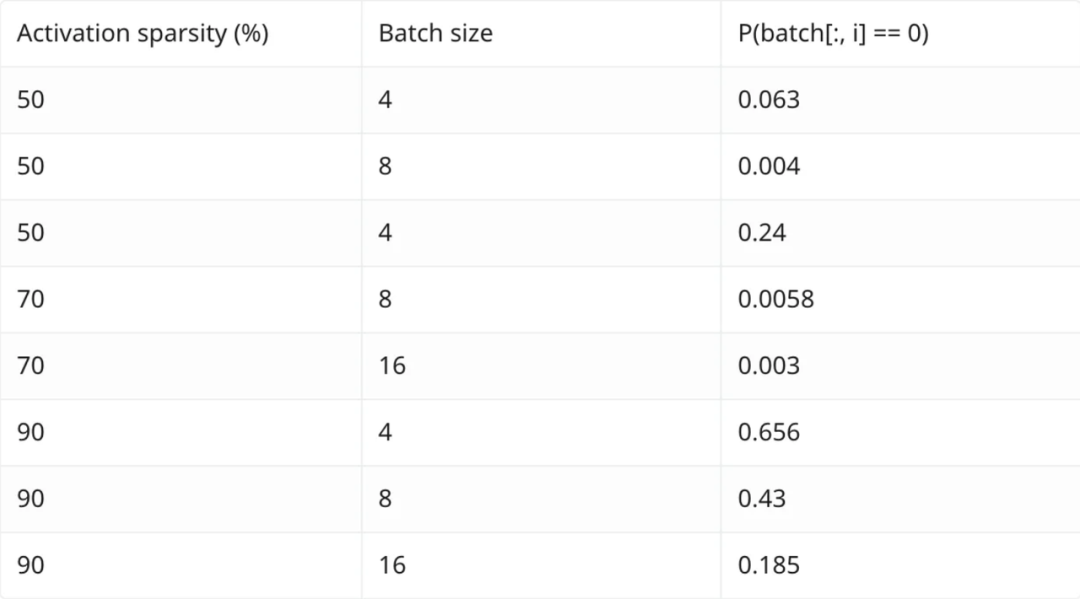
因此,除批大小为1的情况,利用这一方法十分困难,即使在这种情况下,使用推测性解码通常更为有效。但如果你想要在本地运行推理,并且确实需要降低时延,这可能是一个很棒的技巧。
4
量化
量化是人们更为熟悉的技巧之一。我之前已经写过量化的相关内容(https://finbarrtimbers.substack.com/p/efficient-llm-inference),所以不打算在具体方法上花费太多时间。我们很难精确度量量化的效果。GPTQ论文等文献所使用的模型与SOTA模型差距较大,因为大型实验室并未公开其所使用的模型,并且学术界无法与大型实验室所拥有的资源相匹敌。
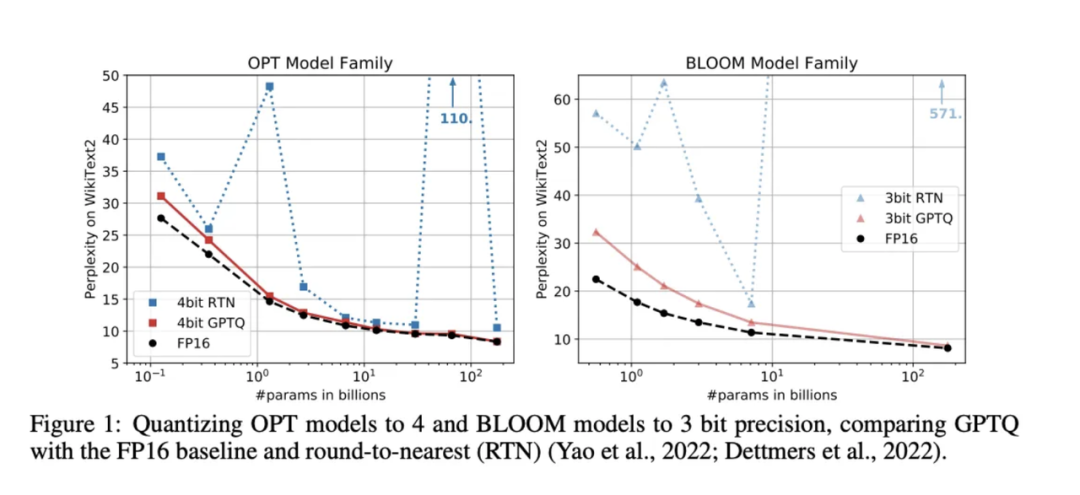
例如,GPTQ报告了OPT和BLOOM模型的量化结果,这些结果远不如当前的一系列开源模型,更不用说GPT-4了。
当然,大型实验室并未公开其研究进展,而我看到的大部分个案报告都来自那些试图在消费级硬件上运行较小模型的人,这种硬件的内存非常有限。我认为,很多业余爱好者(即非大型实验室研究人员)都被在本地运行庞大模型的吸引力所诱惑,因此他们对量化产生了浓厚兴趣。但实际上,量化并不具备固有优势!从第一性原则出发,如果你有两个位数相同的模型,它们应该具有相同数量的词元/秒,并且应该具有类似的性能水平。只有在使用更高精度格式的位数时做得很糟,才会有较大差异。
但文献中的观点与我的直觉不一致。上述GPTQ论文发现,将模型量化为低至4倍的精度时,性能的下降微乎其微。我认为,这是因为性能更差的模型更容易在量化过程中保持其性能不受损。如果假设两个相同的LLM,一个经过2万亿词元的训练,另一个经过5000亿词元的训练(分别称为LLM-2T、LLM-500B),在进行量化时,我认为经过更多词元训练的模型在性能上受到的影响更大,因为它应该更充分地利用这些词元。我们仍然预计经过量化的LLM-2T会优于LLM-500B,但我认为从LLM-2T到经过量化的LLM-2T的性能下降,会比从LLM-500B到经过量化的LLM-500B的下降更显著。
注:虽然上述论点很有说服力,但实际上并没有相关的文献支持。量化似乎确实非常接近于“免费的午餐”。
近期的研究,如关于k-bit推理规模定律的论文(https://arxiv.org/abs/2212.09720),在一系列LLM架构上进行了大量实验,得出了不同的位数分配对模型性能的影响。他们研究了在给定精度水平下使用N个参数的模型与使用2N个参数和一半精度的模型之间的权衡。其结果非常引人注目,与未进行量化的性能几乎没有差别(至少对于4位或更多位而言)。
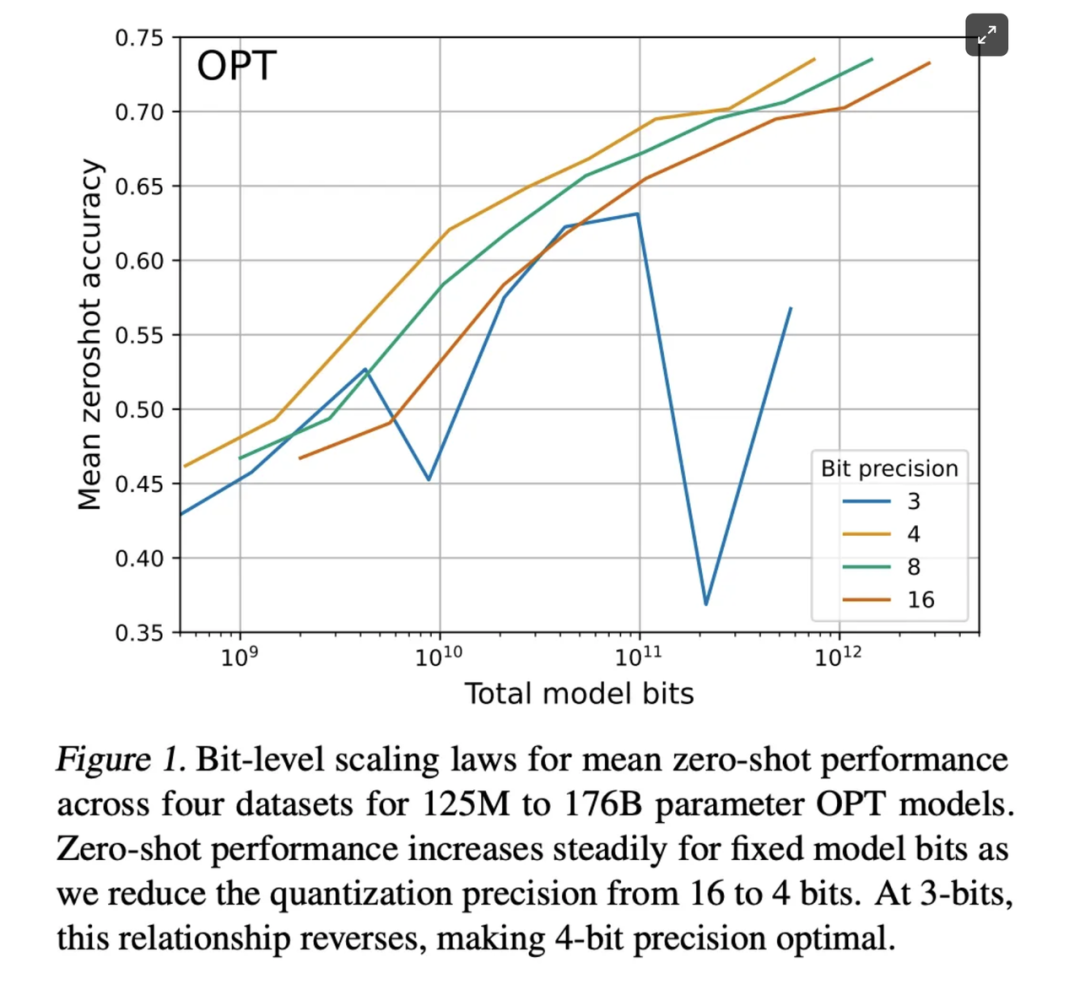
基本上,他们发现可以将精度降至4位而不损失任何性能,量化几乎不会导致任何权衡。你可以运行一个小4倍的模型而不会显著降低性能。由于在现代加速器上推理性能等于处理的位数(即使用较少精度时每秒可以获得更多的运算次数),这点很有帮助。
因此,我的结论是:推荐采纳“k-bit推理论文”的建议。然而,对于生产负载,我对使用低于8位的精度还有些犹豫。fp8是目前现代加速器本地支持的最低精度浮点格式,即使如此,支持也是有限的。我建议在fp8精度下进行训练和推理,并观察进一步量化可能带来的精度损失对你的用例来说是否可以接受。当生产环境中缺乏来自这些平台(例如Nvidia和Torch/JAX团队)的本地支持时,我很难推荐在生产环境中使用更低级别的精度。
根据我从文献中了解到的(这与我的直觉相符),fp8严格来说优于int8,但在硬件上的支持有限。如果你在一个GPU资源充沛的组织,并且能够将H100用于所有任务,那么请使用fp8。否则,也可以使用int8,而且相比起来要容易得多(PyTorch使其变得相当容易,尽管API不太稳定)。
关于实际进行模型量化,PyTorch团队已经服务器托管网撰写了一篇关于如何具体操作的文章(https://pytorch.org/blog/accelerating-generative-ai/),并提供了一系列API用于简化操作,尽管它们不太稳定。此外,bitsandbytes是另一个出色的量化库,不过我个人还未使用过。
(特别感谢@cis_female与我讨论稀疏性的复杂性,以及@nostalgebraist纠正量化部分中的错误。我现在认为,证据表明,至少量化到4位或更多位,在性能方面的权衡非常小。)
其他人都在看
-
大型语言模型的推理演算
-
LoRA微调语言大模型的实用技巧
-
可复现的语言大模型推理性能指标
-
ChatGPT规模化服务的经验与教训
-
机器学习硬件十年:性能变迁与趋势
-
微调语言大模型选LoRA还是全参数?
-
语言大模型推理性能工程:最佳实践
-
语言大模型的分布式训练与高效微调指南
试用OneFlow: github.com/Oneflow-Inc/oneflow/

本文分享自微信公众号 – OneFlow(OneFlowTechnology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: Vulnhub-driftingbules:5 靶机复现完整过程
kali的IP地址:192.168.200.14 靶机IP地址:192.168.200.60 一、信息收集 1.对利用nmap目标靶机进行扫描 由于arp-scan属于轻量级扫描,在此直接使用nmap进行对目标靶机扫描开放端口 nmap -A -p 1-65服…
