
分析&回答
Omega架构我们暂且称之为混合数仓。
什么是ECS设计模式
在谈我们的解法的时候,必须要先提ECS的设计模式。
简单的说,Entity、Component、System分别代表了三类模型。
实体(Entity):实体是一个普通的对象。通常,它只包含了一个独一无二的ID值,用来标记它是一个独立的对象。
组件(Component):对象一个方面的数据,以及对象如何和世界进行交互。用来标记实体是否需要进行这一方面的处理,通常使用结构体,类或关联数组实现。
系统(System):每个系统不间断地运行(就像每个系统运行在自己的私有线程上),处理标记使用了该系统处理的组件的每个实体。
Entity对应于数仓中的Table,Component对应Schema,System对应数仓中SQL逻辑。
对于数仓来说,每张表的意义是由一群schema决定的。而每一个schema只代表一个含义。SQL代码的作用是组装schema到对应的table中,实现它的业务意义。对于一个OLAP系统,我们喜欢大宽表的意义就是因为OLAP分析的是schema之间的关系,用大宽表可以很轻易的提取所需要的schema,组装一个业务所需的表。
ECS设计模式的核心思想就是,所有shcema都独立出来,整个数仓就是一个大宽表。当需要使用的时候,把对应的schema组装成具有业务含义的table。这就像一个个Component组装成一个Entity一样。而SQL在其中起到的作用是就是产出对应的schema和组装schema。
将ECS设计模式引入数仓设计,希望开发者可以更加关注于逻辑,关注数据如何处理,也就是S的部分。业务则由从列构建表的时候产生。将表结构和数据处理逻辑进行拆分,从而希望能提升SQL代码的可读性和结构性。
传统数仓的数据处理流程
数仓通常是分为三层:ODS(原始数据),DW(数据仓库层),ADS(应用数据层)。ODS是从消息中间件中拿到的最原始的数据。DW层则是对数据进行加工后的数据,通常还是分为:DWS和DWD。DWD层中是对ODS层的数据进行清洗后提取的出来的。而DWS层是经过了一些轻度汇总后的数据。用户可以基于此层直接加工出ADS层所需的数据。ADS层则是产出应用最终所需的数据。
所以我们一般的数仓数据处理流程是:
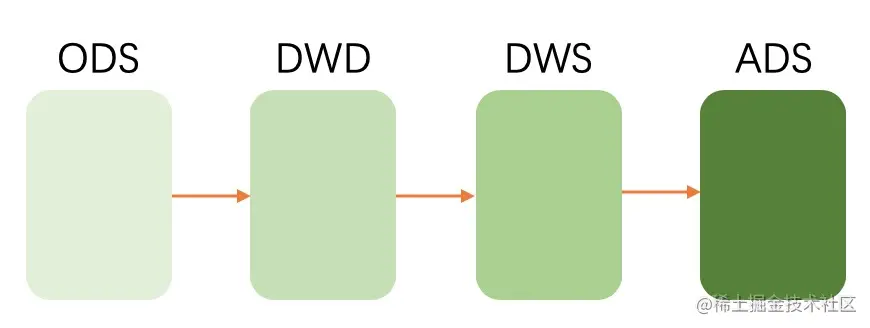
基于ECS设计模式设计的混合数仓
在ECS的设计模式下,核心考虑的是Component是产出。产出具有业务含义的component,组装出具体的业务表(Entity)。
Schema的注册和Table注册
对应在数仓模型中,可以这么理解:数仓里的表,任何一个schema都是独立的。它们不具有业务含义,只是业务的一个属性。组合起来构成一个具有业务含义的表。
因此,我们需要一个专门管理schema的系统。这里包含了schema注册和shcema使用。schema注册系统主要负责对schema唯一性作保证,避免schema重复从而影响使用。同时规定好Schema从元数据中提取的规则(正则表达式或者拆分字符串),保证不论在什么系统中都可以得到唯一的提取结果。
schema的使用则依赖table注册系统。通过table注册系统,将服务器托管网一些具有相关含义的schema串联起来,形成table提供给业务使用。
如下图:
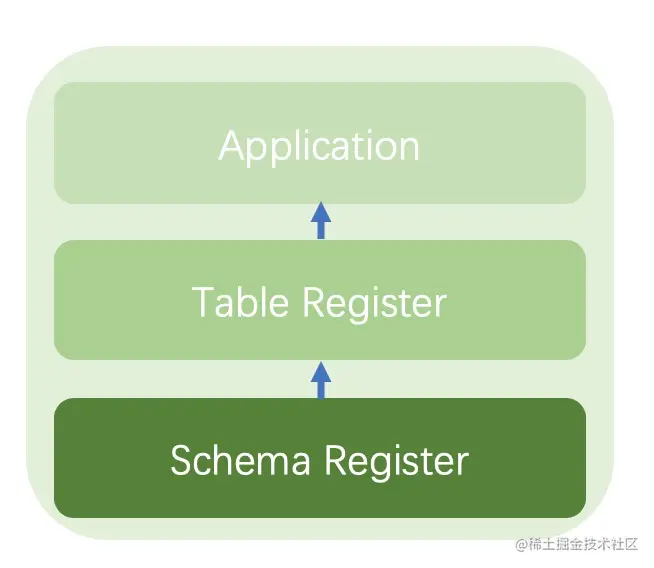
Schema开发与混合数仓架构
有了schema注册,就要提到schema产出的问题了。在上文提到过,在服务器托管网Lambda架构下,离线实时数仓需要同时维护两份代码,其实就是需要维护两份schema的注册和产出过程。在Kappa架构中,虽然只需要在实时数仓中做数据处理,但面对大量历史数据处理时需要消耗非常多的资源,而且中间结果复用能力有限,不适合复杂的业务。
由于我们将schema 注册抽离出来,在ECS的设计模式下,数据加工过程只有schema之间的交互,所以只需要关心数据加工部分代码。而对于Flink(Blink)与MaxCompute(ODPS)来说,数据处理部分的sql代码都遵循相近的SQL规范(这里没查到对应的SQL版本,但使用过程中感受是几乎一致,差别在于一些函数上。这一点可以通过UDF等方式解决。),所以可以保证很好的复用性。如果实时数仓和离线数仓数据处理层面的代码差异较大的话,可以引入编译器的形式解决。在任务提交的时候对代码进行差异化的编译,适用于对应的数仓。
从而我们可以画出以下的架构图:
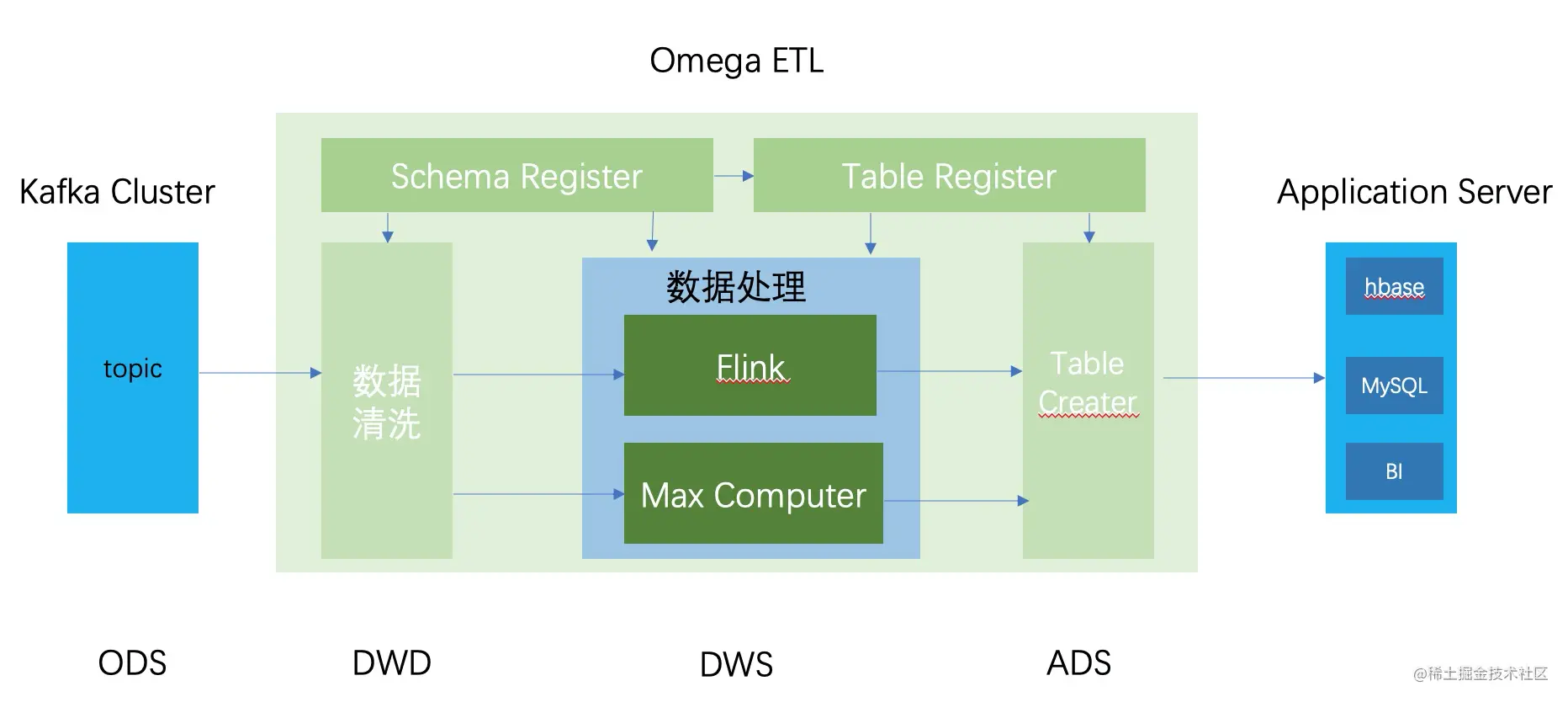
Kafka传入的消息是这套架构的ODS层,这一点上跟Lambda和Kappa架构是保持一致的。
数据进入数仓后,数据会被Schema Register中注册的规则提取出来,产出一个个对应的schema。即对应DWD层。
有了schema后,数据进入处理加工逻辑。即System部分。这里需要针对实时和离线数仓分别产出对应的加工代码,并执行具体的加工。此处对应的是DWS层。
最后,将加工后产出的schema和table Register系统结合,产出最终的ADS层的数据。
这套架构的好处是通过ECS设计模式的思想,将数据处理过程拆分成:数据声明(Schema Register,Table Register),数据处理(System)和结果拼接(Table Creater)三个流程。在这三个过程中,将Flink、Max Compute视为计算资源,将整体数据加工处理的逻辑独立在底层中间件之上,与开发环境解耦。从而实现工程化的管理数据仓库里的数据和加工过程。
但这套架构也存在一定的问题。例如,实时数据和离线数据是不互通的。如果统计过去180天UV总数时,需要离线和实时数据合并去重的处理就会遇到麻烦。
反思&扩展
这个架构命名为Omega架构,对应希腊字母中的Omega,含义是“终结”。我希望这套架构能解决目前实时数仓和离线数仓比较混乱的局面,可以让大数据开发、管理的能力更上一个台阶,让更多小伙伴可以更加方便的取数,加工,从而更好的服务于业务。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手]或关注 [喵呜刷题] -> 面试助手免费刷题。如有好的面试知识或技巧期待您的共享!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
