
1、简介
在Prometheus平台中,警报由独立的组件Alertmanager处理。通常情况下,我们首先告诉Prometheus Alertmanager所在的位置,然后在Prometheus配置中创建警报规则,最后配置Alertmanager来处理警报并发送给接收者(邮件,webhook、slack等)。2、部署
# 下载地址
https://prometheus.io/download/
# 部署
Anertmanager可以不用和Prometheus部署在同一台机器,只要服务之间可以通信即可。
# wget https://github.com/prometheus/alertmanager/releases/download/v0.20.0/alertmanager-0.20.0.linux-amd64.tar.gz
# tar xf alertmanager-0.20.0.linux-amd64.tar.gz -C /usr/local/
# ln -s /usr/local/alertmanager-0.20.0.linux-amd64/ /usr/local/alertmanager
# 修改alertmanager配置文件
# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'gaojing@163.com'
smtp_auth_username: 'gaojing@163.com'
smtp_auth_password: 'password'
smtp_require_tls: false
route:
group_by: ['alertname'] # 分组标签
group_wait: 10s # 分组等待时间,同一组内在10秒钟内还有其它告警,如果有则一同发送
group_interval: 10s # 上下两组间隔时间
repeat_interval: 1h # 重复告警间隔时间
receiver: 'mail' # 接收者是谁
receivers: # 定义接收者,将告警发送给谁
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
- name: 'mail'
email_configs:
- to: '532141928@qq.com'
# 检查配置文件
# ./amtool check-config alertmanager.yml
# 使用systemd来管理alertmanager服务
# cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
# 启动alertmanager服务
# systemctl daemon-reload
# systemctl start alertmanager
# systemctl enable alertmanager3、配置prometheus与alertmanager集成
配置告警规则可参考:https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
# vim /usr/local/prometheus/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093 # alertmanager的通信地址
rule_files:
- "rules/*.yml" # alertmanager使用的配置文件存放地址
# mkdir /usr/local/prometheus/rules
# cat /usr/local/prometheus/rules/general.yml
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0 # 表达式当前实例服务状态,1为正常
for: 3m # 告警持续时间5分钟
labels:
severity: page # 告警级别
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} 已经停止工作3分钟."
# /usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml
Checking /usr/local/prometheus/prometheus.yml
SUCCESS: 1 rule files found
Checking /usr/local/prometheus/rules/general.yml
SUCCESS: 1 rules found
# systemctl restart prometheus.service重启服务之后就能看到新的规则
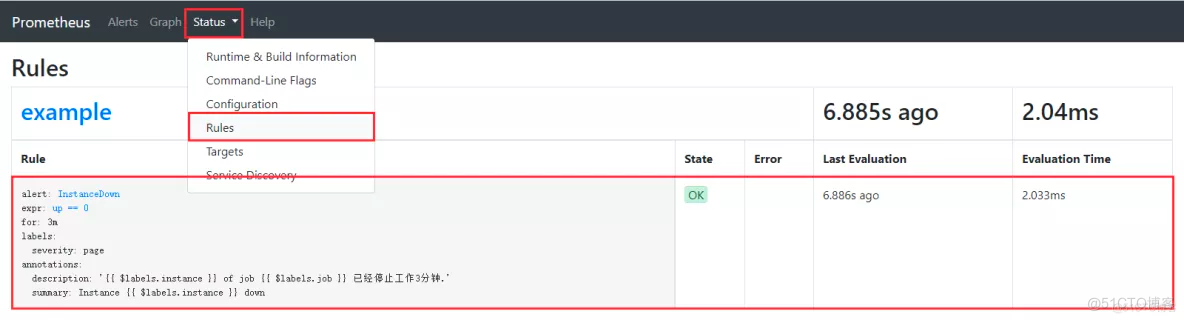
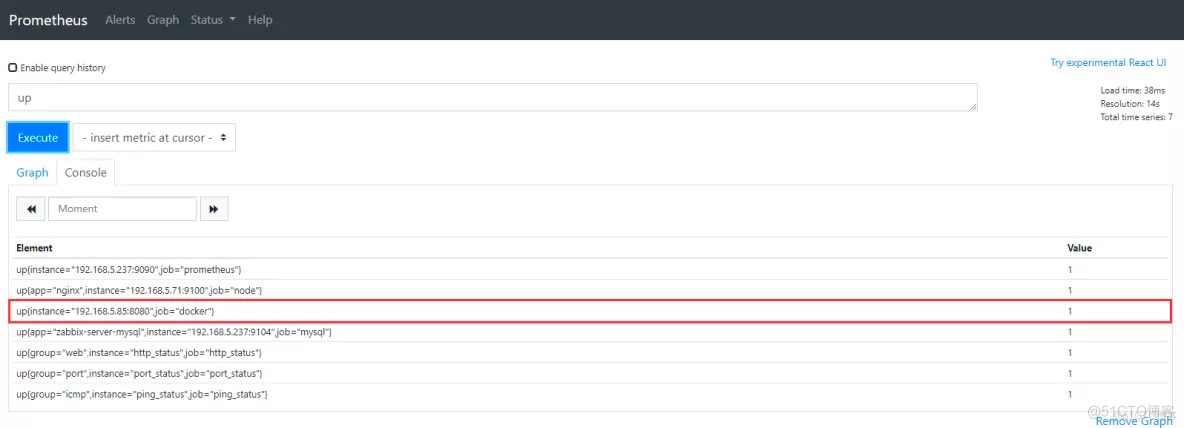
停止一个服务进行验证
告警状态
Inactive:这里什么都没有发生。
Pending:已触发阈值,但未满足告警持续时间(即rule中的for字段)
Firing:已触发阈值且满足告警持续时间。警报发送到Notification Pipeline,经过处理,发送给接受者。
这样的目的是多次判断失败才发告警,减少邮件。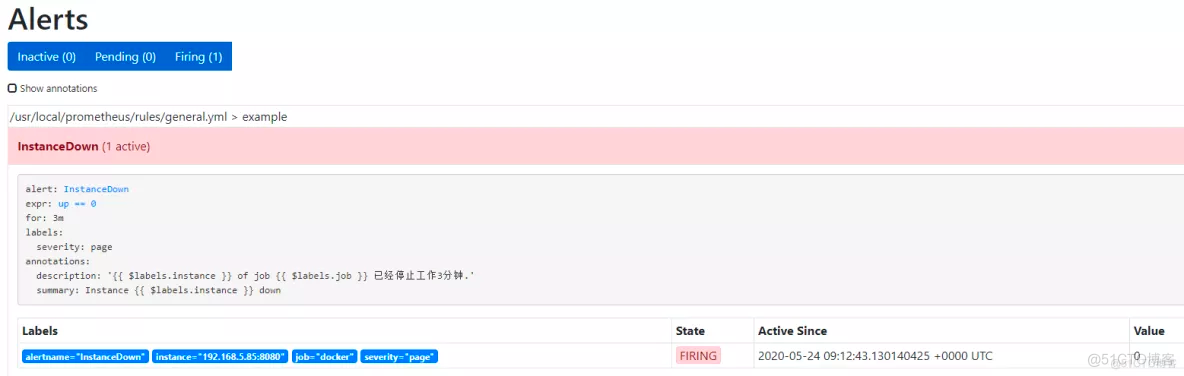
查看邮箱已经收到邮件

告警分配到指定接收到组,处理流程如下
接收到Alert,根据labels判断属于哪些Route(可存在多个Route,一个Route有多个Group,一个Group有多个Alert)。
将Alert分配到Group中,没有则新建Group。
新的Group等待group_wait指定的时间(等待时可能收到同一Group的Alert),根据resolve_timeout判断Alert是否解决,然后发送通知。
已有的Group等待group_interval指定的时间,判断Alert是否解决,当上次发送通知到现在的间隔大于repeat_interval或者Group有更新时会发送通知。
route:
receiver: 'default-receiver' # 所有不匹配以下子路由的告警都将保留在根节点,并发送到“default-receiver”
group_wait: 30s # 为一个组发送通知的初始等待时间,默认30s
group_interval: 5m # 在发送新告警前的等待时间。通常5m或以上
repeat_interval: 1h # 发送重复告警的周期。如果已经发送了通知,再次发送之前需要等待多长时间。
group_by: [cluster, alertname] # 报警分组依据
routes:
- receiver: 'database-pager' # 所有service=mysql或者service=cassandra的告警分配到数据库接收端
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager' # 所有带有team=frontend标签的告警都与此子路由匹配,它们是按产品和环境分组的,而不是集群
group_by: [product, environment]
match:
team: frontend
receivers: # 定义接收者,将告警发送给谁
- name: 'database-pager'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
- name: 'frontend-pager'
email_configs:
- to: '532141928@qq.com'4、告警的收敛(分组、抑制、静默)
告警面临最大问题,是警报太多,相当于狼来了的形式。收件人很容易麻木,不再继续理会。关键的告警常常被淹没。在一问题中,alertmanger在一定程度上得到很好解决。
Prometheus成功的把一条告警发给了Altermanager,而Altermanager并不是简简单单的直接发送出去,这样就会导致告警信息过多,重要告警被淹没。所以需要对告警做合理的收敛。
告警收敛手段:
分组(group):将类似性质的警报分类为单个通知 (相同组中的告警合并到一封邮件中进行发送 - alert: InstanceDown)
抑制(Inhibition):当警报发出后,停止重复发送由此警报引发的其他警报
静默(Silences):是一种简单的特定时间静音提醒的机制
抑制
# vim /usr/local/alertmanager/alertmanager.yml
inhibit_rules: # 抑制 告警收敛 发送关键告警
- source_match:
severity: 'critical' # 如果是此级别的告警,就会忽略下面warning级别告警邮件的发送
target_match:
severity: 'warning'
equal: ['app', 'instance'] # 根据标签来判断主机静默
特定的时间内不再发送告警,访问IP:9093端口在WEB页面进行配置,一般用来在维护阶段组止预期的告警通知。

触发告警的流程
Prometheus Server监控目标主机上暴露的http接口(这里假设接口A),通过上述Promethes配置的'scrape_interval'定义的时间间隔,定期采集目标主机上监控数据。
当接口A不可用的时候,Server端会持续的尝试从接口中取数据,直到"scrape_timeout"时间后停止尝试。这时候把接口的状态变为"DOWN"。
Prometheus同时根据配置的"evaluation_interval"的时间间隔,定期(默认1min)的对Alert Rule进行评估;当到达评估周期的时候,发现接口A为DOWN,即UP=0为真,激活Alert,进入“PENDING”状态,并记录当前active的时间;
当下一个alert rule的评估周期到来的时候,发现UP=0继续为真,然后判断警报Active的时间是否已经超出rule里的"for" 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则alert的状态变为"FIRING";同时调用Alertmanager接口,发送相关报警数据。
AlertManager收到报警数据后,会将警报信息进行分组,然后根据alertmanager配置的"group_wait"时间先进行等待。等wait时间过后再发送报警信息。
属于同一个Alert Group的警报,在等待的过程中可能进入新的alert,如果之前的报警已经成功发出,那么间隔"group_interval"的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个group的报警信息会汇总在一个邮件里进行发送。
如果Alert Group里的警报一直没发生变化并且已经成功发送,等待"repeat_interval"时间间隔之后再重复发送相同的报警邮件;如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待group_interval时间间隔后重复发送。
同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里有alertmanager的route路由规则进行配置。5、自定义告警
自定义磁盘、CPU、内存大于80%的告警
# vim /usr/local/prometheus/rules/node.yml
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用过高"
description: "{{$labels.instance}}: {{$labels.mountpoint }} 分区使用大于 80% (当前值: {{ $value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 内存使用过高"
description: "{{$labels.instance}}: 内存使用大于 80% (当前值: {{ $value }})"
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: CPU使用过高"
description: "{{$labels.instance}}: CPU使用大于 80% (当前值: {{ $value }})"
# /usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml
Checking /usr/local/prometheus/prometheus.yml
SUCCESS: 2 rule files found
Checking /usr/local/prometheus/rules/general.yml
SUCCESS: 1 rules found
Checking /usr/local/prometheus/rules/node.yml
SUCCESS: 3 rules found
# systemctl restart prometheus.service服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
