

在刚刚过去的北京Doris Summit Asia 2023,玖章算术技术副总裁陈长城受邀参加并做了《NineData面向Doris实时数仓集成的技术实践》报告。

玖章算术技术副总裁陈长城
多云多源企业数据管理的挑战
从业界的报告中我们知道超过81%的企业使用了多云或混合云架构,超过70%的企业使用了多种数据类型,而对基础架构、数据架构运用娴熟的企业其创新速度远高于同行。当然多云多源也带来了很多挑战,导致基础架构管理复杂、数据孤岛、开发效率下降等挑战增加。
面向这些问题,玖章算术研发了NineData云原生智能数据管理平台,底层基于统一数据源和IaaS层抽象,对接各个云厂商和多种数据源,基于之上建立了数据复制、数据对比、SQL开发、数据备份四大功能模块,并与企业的托管数据库PaaS、搜索平台、消息队列和大数据平台形成良好的互动,帮助企业实现多云多源统一的数据管理能力。
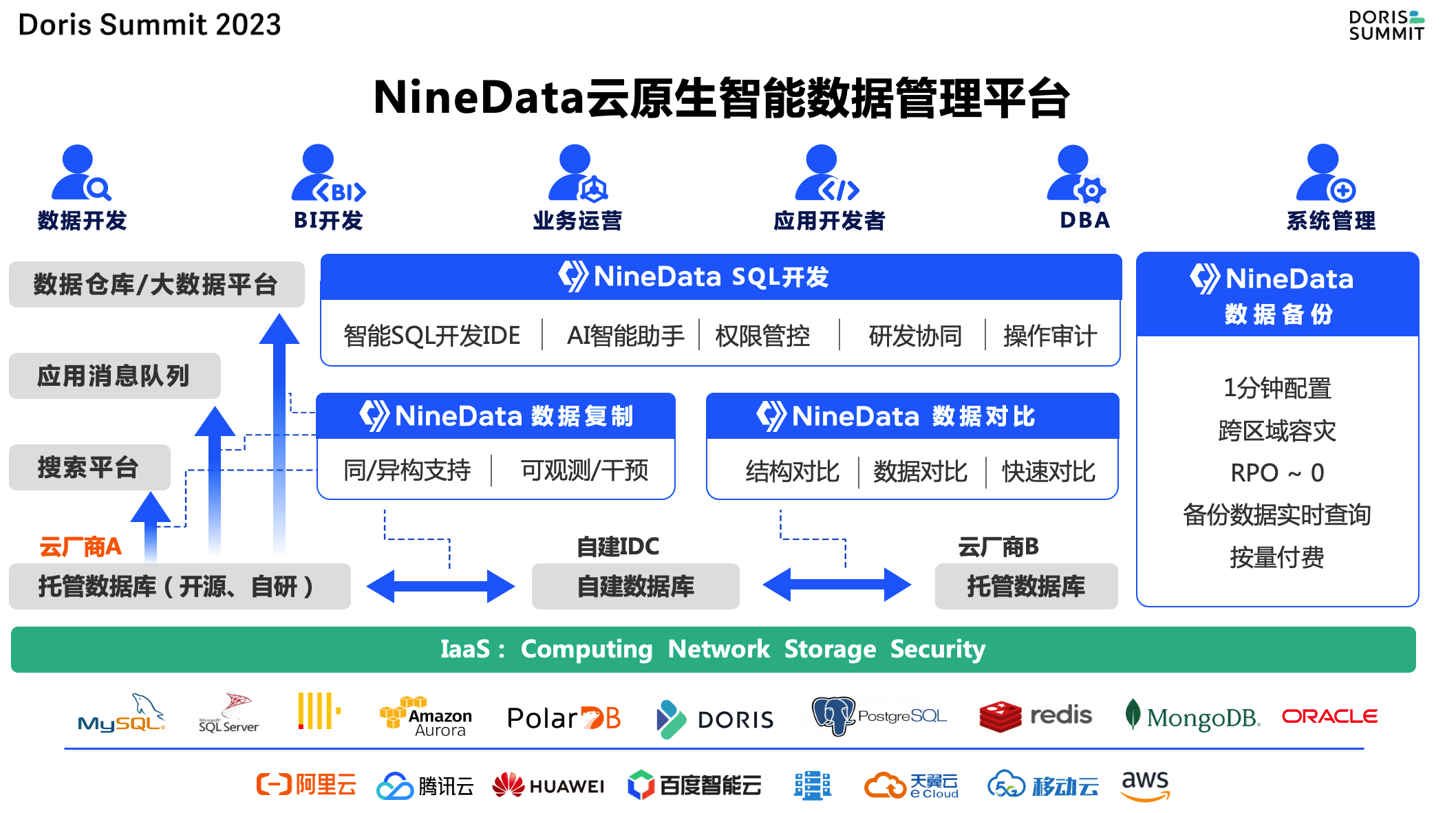
NineData数据管理平台架构图
云原生数据复制架构
在多云多源下的数据集成,企业面临多种数据源的数据抽取、多云厂商数据互通的需求,对于多数据中心和出海企业,也必然面临跨地域长周期的数据同步的挑战。NineData认为一个云原生的数据复制架构,需要具备四个特征:
(1)Scalable(可扩展性,实现多种数据源快速接入)
(2)Resilient(适配各种环境,各厂商和复杂的网络环境)
(3)Manageable(可管理性,大量环境和链路管理及一致性对比)
(4)Observable(可观测可干预)
NineData在多云方面的目标是实现AnyWhere、AnyNetwork、AnyDatabase的数据库接入和管理能力,通过统一的控制台,帮助用户管理各个地方的数据源。NineData的worker会部署到离用户最近的地方,实现数据链路在本地运行,而任务状态汇报到中心控制台的架构。worker可以通过私网VPC或公网与用户数据源打通,对于数据库不暴露公网的可以使用NineData数据库网关实现本地接入,远程复制和管理。同时NineData也支持金融企业客户的专属集群部署需求。
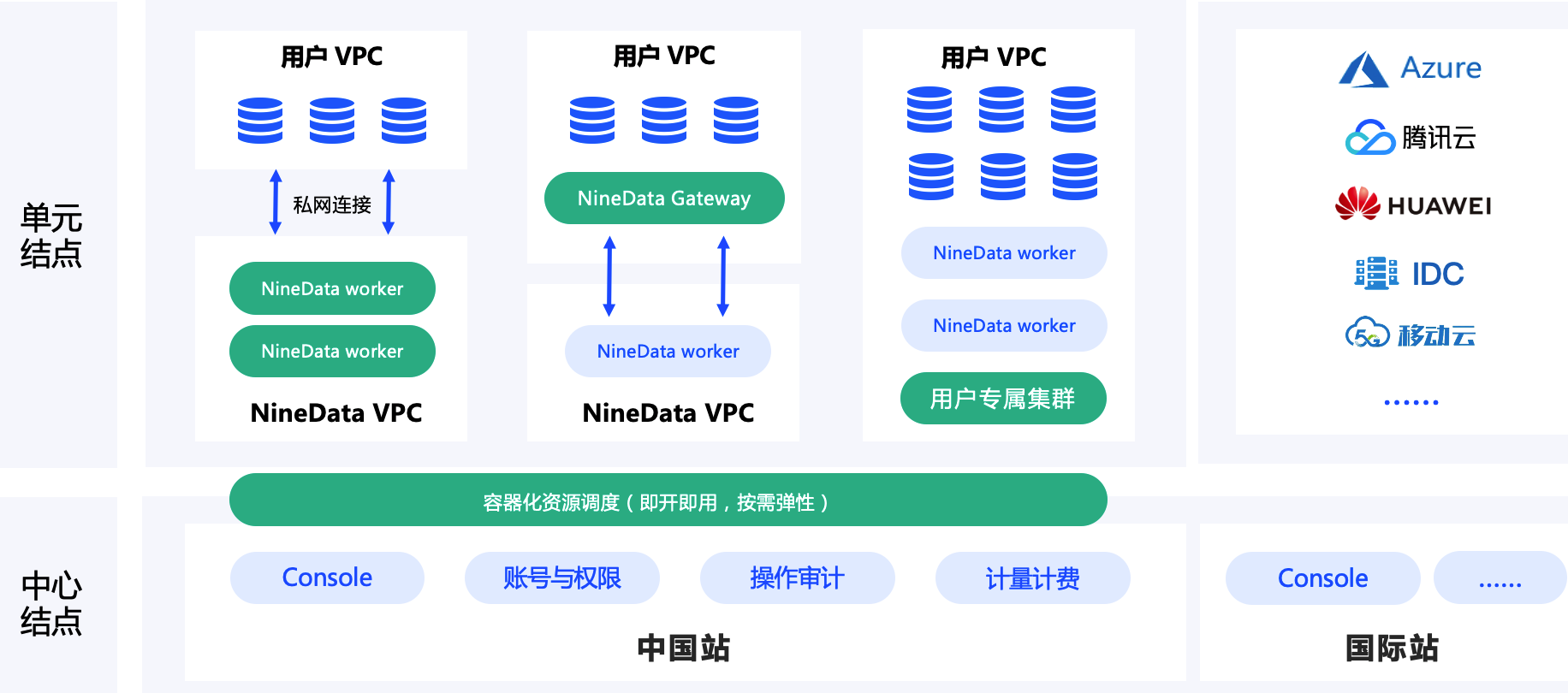
NineData云原生数据复制架构
在多数据源方面,NineData通过统一数据源的抽象,将数据库连接属性、账密、连接池管理、网络连接方式等统一管理起来,一个数据源注册完后,就可以使用NineData提供的所有功能,包括SQL开发、数据复制、数据对比、数据备份等。
实时数仓Doris数据集成实践
NineData在实时数仓Doris数据集成实践上, 重点围绕一致性、高吞吐、低延迟、可观测可干预这几个方面,当前NineData已经支持了60多种数据源。在数仓实时数据集成中,我们会考虑到这几个方面:
(1)DDL自适应,实现结构迁移初始化,以及后续新的增量DDL的自动同步。对于Doris,其结构和MySQL兼容性比较高,主要是对distribute key自适应和跨库CREATE TABLE LIKE的兼容,distribute key的选择NineData会自动按主键、唯一键的顺序自动填充,也允许用户下拉指定,来达到顺畅的体验。
(2)数据类型映射,包括数据类型映射(如BIGINT UNSIGNED -> LARGEINT等),字符集映射(Doris主要是utf8),以及当多个地域不同时区的生产库汇聚到Doris 时,需要做时区自适应。
(3)数据ETL转换,当使用MySQL同步到Doris时,我们希望表结构原样同步过来,其实更多的是ETL,先保障数据快速、准确、稳定的持续同步过来,再基于这些原始数据ODS之上去构建数仓的维表、物化视图等。但生服务器托管网产库也会有一些数据是不需要同步到数仓的,因此需要过滤掉、或者做一些简单的计算和标记再同步到数仓,这个就是EtLT。
(4)提交性能,这个是数仓集成大家普遍关注的,后面将单独介绍。
下面分别介绍几个实践中的要点:
3.1 一致性
在做实时日志CDC的时候,其实要把数据正确解析出来,需要两个部分。以MySQL为例,你需要拿到数据库的binlog日志(里面包含数据前后镜像),同时拿到MySQL产生这条日志那一刻的表结构,才能正确地拼出响应的DML语句。因此在DML/DDL混合执行的时候,正确地拿到那一刻的表结构就比较困难,而这在生产库中经常遇见。因此NineData实现了一个DDLParser,将每一条DDL日志在同步模块中模拟MySQL的DDL执行,更新同步模块中的Meta缓存,并实现了版本化存储。这样就可以获得每张表任意时刻的表结构元数据。
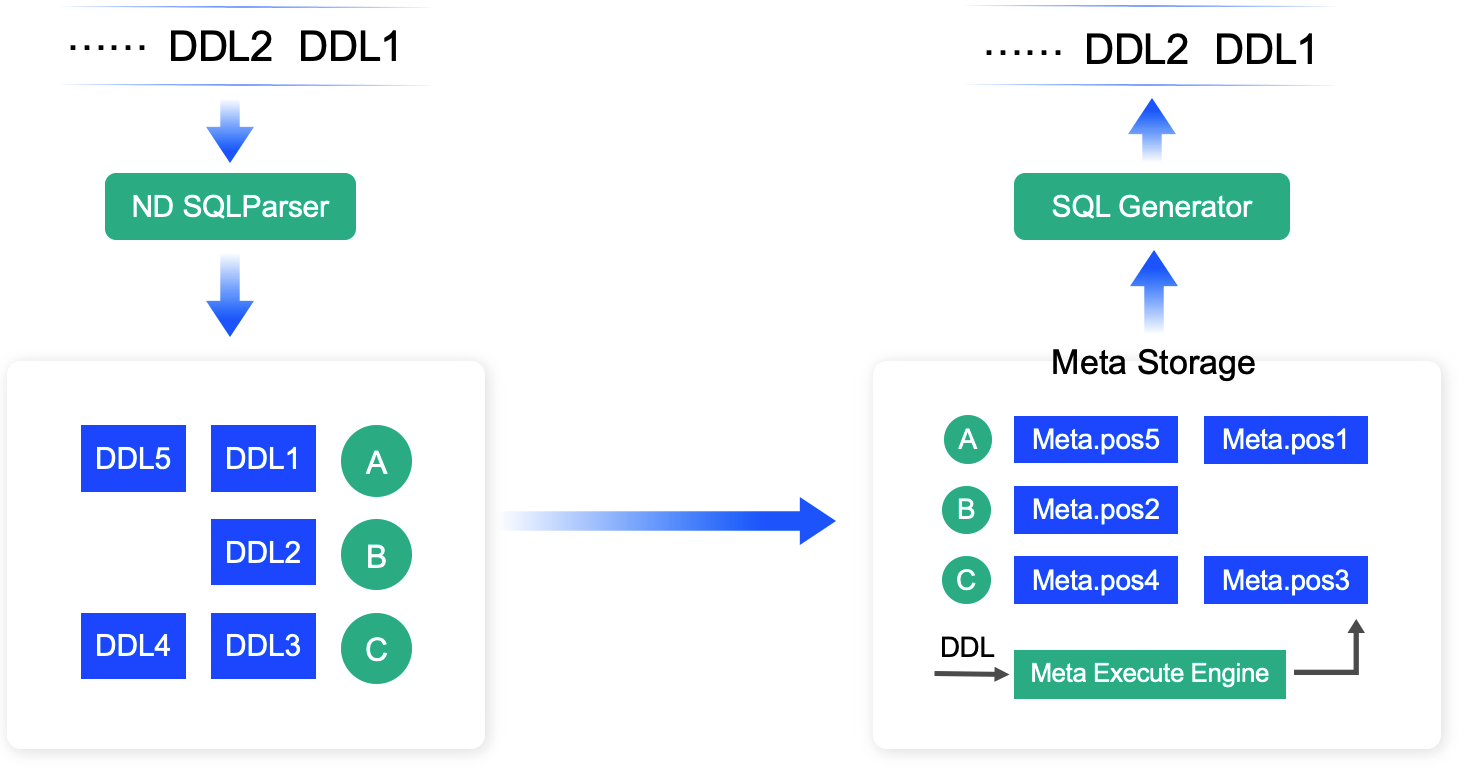
NineData的数据一致性
3.2 高吞吐
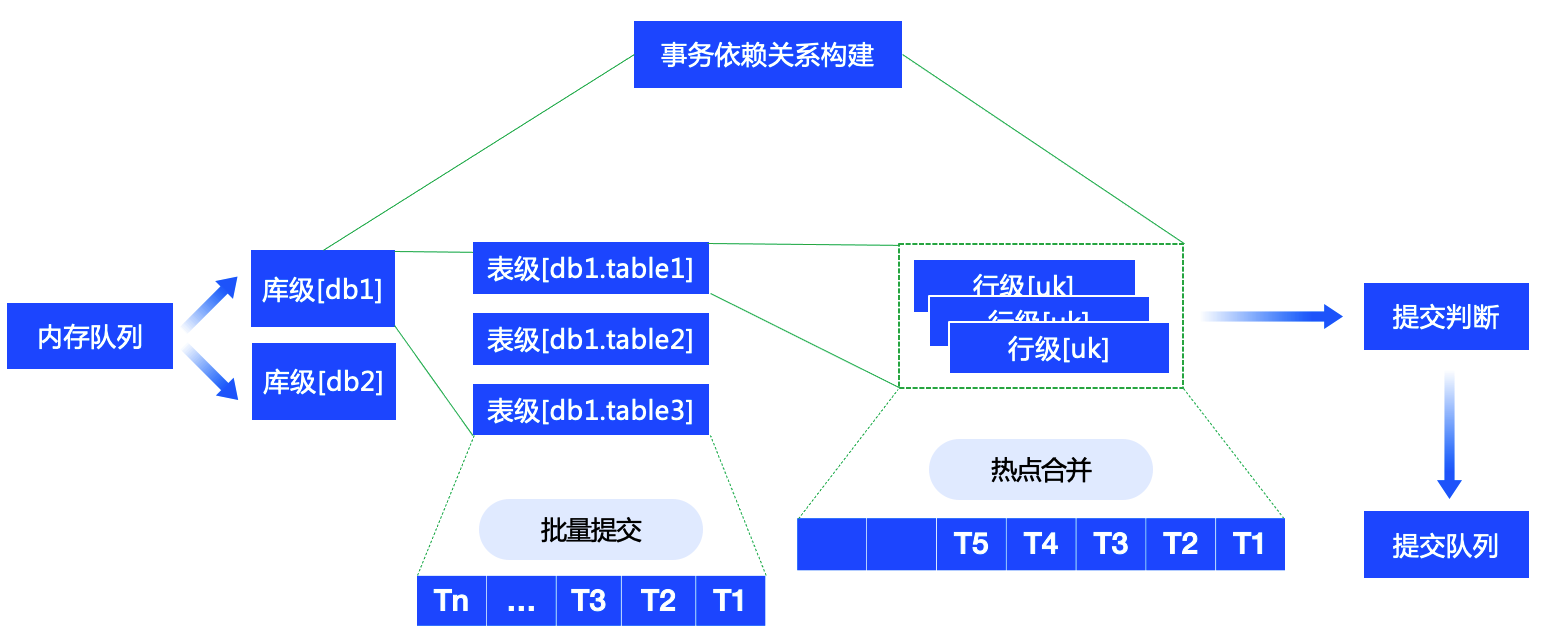
全量同步性能是数仓集成比较重要的地方,往往涉及到多个数据源往一个数仓同步数据,NineData的工作包括以下三个部分:
(1)在全量同步数据到Doris的过程中,由于生产库存在多张大小不一样的表,如果有很多小表和1-2张大表的情况下,就容易出现小表都同步完了,最后几张大表一直没有完成。因此我们要进行单表并发切片,并且保障切片足够均匀,才能最大化使用并发度让大家同时完成。NineData会根据表的主键、唯一键、非空索引等顺序进行切片,同时做到切片粒度的断点续传。
(2)在内存方面针对全量同步这种一过性数据场景对JVM内存进行优化。
(3)服务器托管网进行批量提交合并,同时针对Doris的特点,进行Stream模型的全量和增量写入,在实测中30并发能够跑到209MB/S、88W RPS的性能。
3.3 低延时
NineData从多个维度建设,以实现低延时能力。包括链路中热点更新数据合并、表级别的安全位点减少数据回退,云原生RDS备份日志自动回拉,主动运维时的优雅退出(clean shutdown)等能力,以保障运行中的链路最小受到各种情况造成的延时影响。
3.4 链路内置ETL能力
包括对象名映射(库、表、列名均支持名称映射)、数据过滤(如支持通过配置SQL Expression,使用函数计算和过滤数据示例:gmt_create>=‘2019-09-09 11:11:11)、操作类型过滤(如支持通过配置增量复制需要复制的操作类型,细粒度控制复制操作,示例:只复制Insert/Delete/Update/Create Table/Alter Table,其他操作都不需要)。
3.5 可扩展性
数仓集成涉及的数据源众多,为了方便支持扩展更多的数据源,我们对结构转换、数据转换做了中间数据类型的抽象,能够做到多源异构的快速转换,同时抽象了复制框架,基于复制框架进行插件化开发可以实现新数据源的快速接入。
NineData数据管理平台架构图
3.6 可观测可干预
(1)数据对比作为NineData重点建设的功能,对数仓集成复制的数据一致性有很好的观测能力。NineData全量对比会将计算下推以减少数据库网络消耗并提升性能,支持限流保护生产库。快速对比会对数据的行数、MAX、MIN、AVG取值以更准确判断数据一致性。

NineData数据对比功能
在结果呈现上,NineData会将每一行每个字段的不一致部分以颜色标记出来,并生成订正SQL。
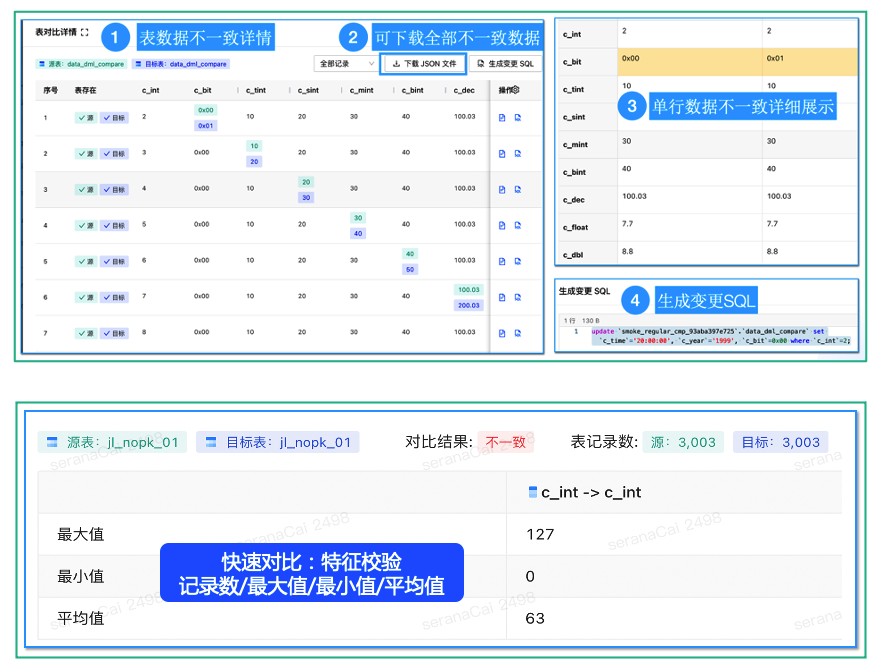
NineData支持智能校验数据并生成订正SQL
(2)在传统监控告警之外,NineData做了两个有特色的功能,一个是在同步模块运行中,可以查看每个线程当前在提交什么SQL,比如遇到DDL特别慢,当前已经执行了多少时间。另一个是针对每一个正在复制的命令,如果抛错了,允许客户进行SQL语句级别的修改和重试,或跳过,快速干预和恢复链路。
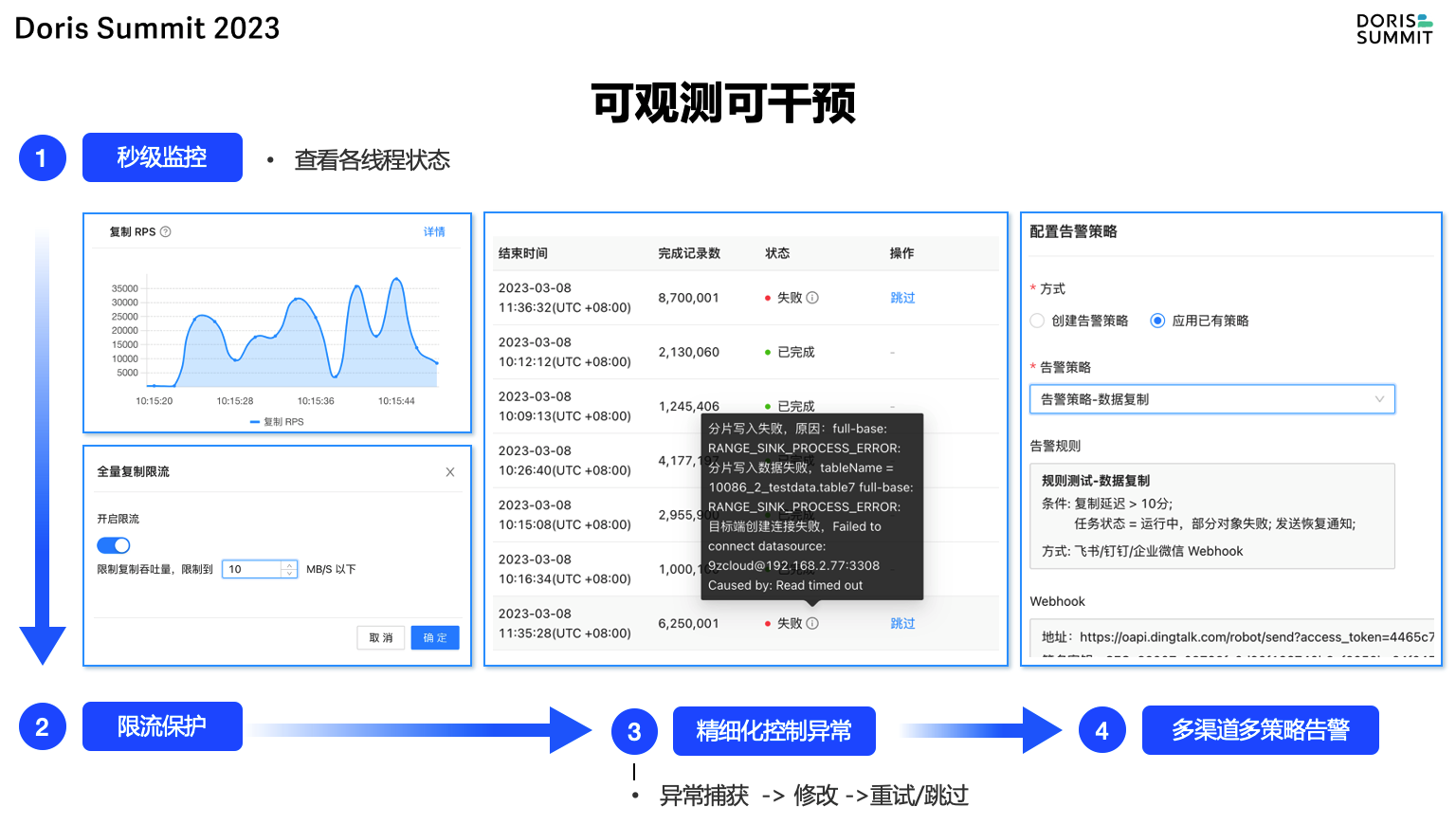
NineData的可观测可干预能力
典型业务场景和技术展望
我们认为,在多云多源的背景下,随着云原生数仓的快速发展,只有云原生化的实时数据集成能够适应时代的要求,能够快速提供各个厂商、各种数据类型的快速汇聚,具备按需使用,即开即用的特性。

实时数据集成技术趋势
Metadata-Driven能够将企业多种数据源统一管理,构建统一的元数据和数据目录,让企业有个完整的数据生产资料视角也特别重要。NineData的SQL开发能够帮助企业补充这部分能力。同时,传统先建数据中台进行大数据集中,再考虑产出效果的方式无法满足企业的需要,Purpose-Driven更多受到企业用户的喜欢,让用户的数仓集成投入有明确的目标效果预估。通过提前构建联邦查询或逻辑视图,预览数仓集成后的报表效果,以及评估相关链路和存储成本,再进行投入。而且实时数据集成平台应该提供自助化的服务让用户进行尝试和决策。
随着当下AIGC能力的发展,我们相信大模型在帮助企业进行数据管理的智能辅助方面有不错的应用前景。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 夜莺监控之Categraf监控VMwareVSphere
之前一直在使用开源的虚拟化软件PVE(Proxmox VE),突然有一天网桥莫名其妙的出幺蛾子,周末鼓捣了半天,谷歌百度也找不到对应的解决方案,重新安装烦的不行,后来一怒之下就换了VMware的VSphere7.0,不得不说,VMware的稳定性与实用性是真的…
