以lexfridman的官方网站为例,https://lexfridman.com/podcast/,如何批量下载网页呢?
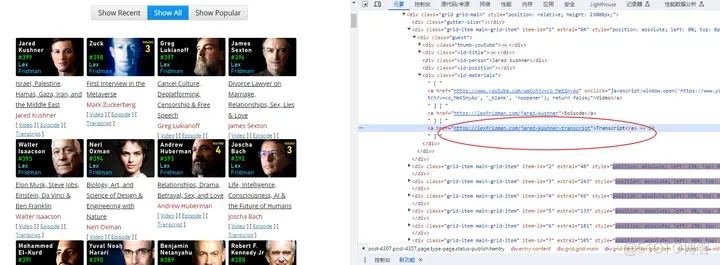
查看网页源文件,播客transcript的链接是:
https://lexfridman.com/jared-kushner-transcript“>Transcript
文件标题在这里:
Transcript <a href="https://www.fwqtg.net">服务器托管网</a>for Jared Kushner: Israel, Palestine, Hamas, Gaza, Iran, and the Middle East | Lex Fridman Podcast #399 – Lex Fridman
所以,在ChatGPT中输入提示词如下:
你是一个Python编程专家,要完成一个批量下载网页的任务,具体步骤如下:
在本地电脑D盘新建一个文件夹:lexfridman-podtext;
打开网页https://lexfridman.com/podcast/,解析网页源代码;
提取网页源代码中所有标签的内容;
如果标签的内容为“Transcript”,就提取标签的href属性值,作为网页下载地址;
然后解析这个网页源代码,提取其
标签内容,作为网页的文件标题名;</p>
<p>下载这个网页,保存到文件夹lexfridman-podtext;</p>
<p>注意:</p>
<p><title>标签内容提取后,要将其中的“: ”、“ | ”等Windows系统中不允许作为文件名的特殊符号替换为符号”-”;</p>
<p>每一步都要输出相关信息;</p>
<p>ChatGPT生成源代码如下:</p>
<p>import os</p>
<p>import requests</p>
<p>from bs4 import BeautifulSoup</p>
<p># 函数用于清理文件名中的非法字符</p>
<p>def clean_filename(filename):</p>
<p>return filename.replace(‘:’, ‘-‘).replace(‘|’, ‘-‘)</p>
<p># 在D盘新建文件夹</p>
<p>folder_path = “D:lexfridman-podtext”</p>
<p>if not os.path.exists(folder_path):</p>
<p>os.makedirs(folder_path)</p>
<p>print(f”新建文件夹:{folder_path}”)</p>
<p># 打开并解析网页</p>
<p>source_url = “<span style="color: #000000"><span style="background-color: #000000">https://</span></span>lexfridman.com/podcast/<span style="color: #000000"><span style="background-color: #000000"></span></span>“</p>
<p>print(f”打开并解析网页:{source_url}”)</p>
<p>response = requests.get(source_url)</p>
<p>soup = BeautifulSoup(response.text, ‘html.parser’)</p>
<p># 提取所有标签</p>
<p>a_tags = soup.find_all(‘a’)</p>
<p># 遍历标签,找出内容为“Transcript”的</p>
<p>for a_tag in a_tags:</p>
<p>if a_tag.text == “Transcript”:</p>
<p># 提取标签的href属性值</p>
<p>href = a_tag[‘href’]</p>
<p>print(f”找到Transcript网页地址:{href}”)</p>
<p># 打开并解析Transcript网页</p>
<p>transcript_response = requests.get(href)</p>
<p>transcript_soup = BeautifulSoup(<a href="https://www.fwqtg.net">服务器托管网</a>transcript_response.text, ‘html.parser’)</p>
<p># 提取</p>
<p><title>标签内容</p>
<p>title_tag = transcript_soup.find(‘title’)</p>
<p>if title_tag:</p>
<p>title = clean_filename(title_tag.text)</p>
<p>print(f”找到Transcript网页标题:{title}”)</p>
<p># 下载网页并保存到文件</p>
<p>filename = os.path.join(folder_path, title + “.html”)</p>
<p>with open(filename, ‘w’, encoding=’utf-8′) as f:</p>
<p>f.write(transcript_response.text)</p>
<p>print(f”网页已保存到:{filename}”)</p>
<p style="text-align:center"><img decoding="async" src="/wp-content/uploads/2023/11/frc-e124ef3b44d7a38b0928a427343a250f.jpg"></p>
<p>运行程序,全部网页下载保存到本地:</p>
<p style="text-align:center"><img decoding="async" src="/wp-content/uploads/2023/11/frc-f58934670ae5f226ee1e123c9ec48315.jpg"></p>
<p>
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: Nacos 配置中心:微服务架构的利器
1.本次文章主要介绍如何使用Nacos作为项目的配置中心。 研发环境如下: SpringCloud、SpringBoot和spring-cloud-alibaba本版如下 spring-cloud:2021.0.6 spring-cloud-alibaba: …

