
三、数据定义
1、DDL分类
DDL (Data Definition Language数据定义语言),用于定义或修改数据库中的对象,主要分为三种类型
语句:CREATE、ALTER和DROP
CREATE用来创建数据库对象
ALTER用来修改数据库对象的属性
DROP则是用来删除数据库对象2、数据库对象
什么是数据库对象
数据库对象是数据库的组成部分,数据库对象主要包含:表,索引,视图,存储过程,缺省值,规则,触发器,用户,函数等
表
表是数据库中的一种特殊数据结构,用于存储数据对象以及对象之间的关系,由行和列组成的
索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息
视图
视图是从一个或几个基本表中导出的虚表,可用于控制用户对数据访问
存储过程
存储过程是一组为了完成特定功能的SQL语句的集合,一般用于报表统计、数据迁移等
缺省值
缺省值是当在表中创建列或插入数据时,对没有指定其具体值的列或列数据项赋予事先设定好的值
规则
规则是对数据库表中数据信息的限制,它限定的是表的列
触发器
触发器是一种特殊类型的存储过程,通过指定的事件触发执行,一般用于数据审计、数据备份等
函数
函数是对一些业务逻辑的封装,以完成特定的功能,函数执行完成服务器托管网后会返回执行结果3、定义表
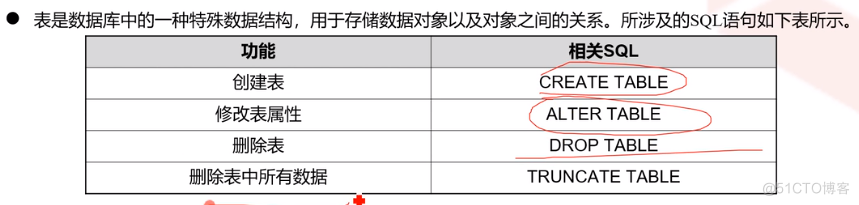
4、创建表


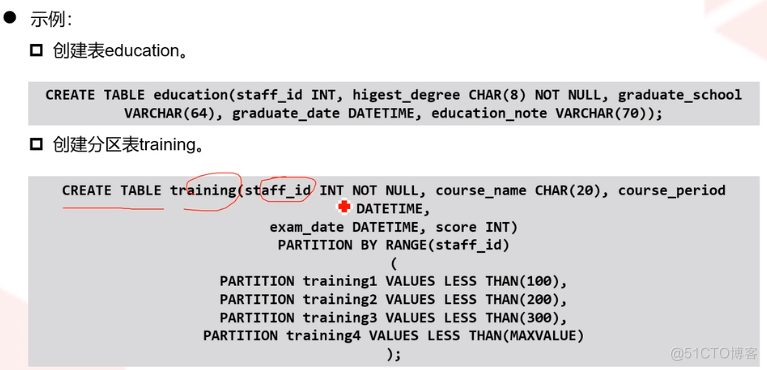
5、修改表属性
ALTER TABLE功能指通过更改、添加、删除列和约束来更改表的定义,功能包括
列的添加、删除、修改、重命名
约束的添加、删除
约束的启动和禁用
修改分区的名称
修改分区的表空间
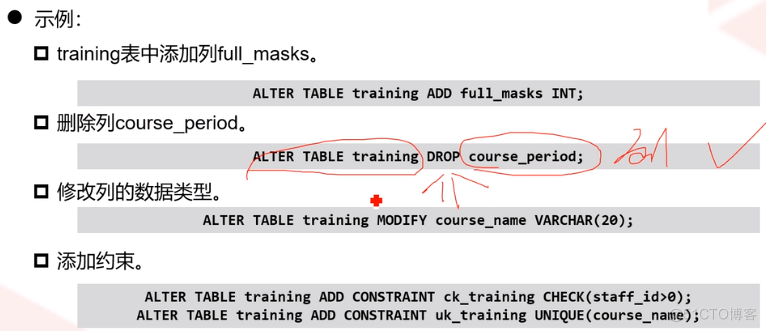
6、删除表


7、定义索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息,所涉及的SQL语句,如下表所示
索引按照索引列数分为单列索引和多列索引,按照索引使用方法可以分为普通索引、唯一索引、函数索引、分区索引
8、创建索引
功能描述
在指定的表上创建一个索引,索引可以用来提高数据库查询性能,但是不恰当的使用将导致性能下降
注意
执行该语句的用户需要有CREATE INDEX、CREATE ANY INDEX系统权限,普通用户不可以创建系统用户对象
语法格式
CREATE [ UNIQUE ] INDEX [ IF NOT EXISTS ] [ schema_name. ]index_name ON table_index_clause [ CRMODE { PAGE | ROW } ]
table_index_clause子句
[ schema_name.]table_name ( { [function_name()]column_name [ ASC | DESC ]} [ ,... ] )
参数说明
UNIQUE
创建唯一性索引,每次添加数据时检测表中是否有重复值,如果插入或更新的值会导致重复的记录时将生成一个错误
INDEX_NAME
要创建的索引名
TABLE_NAME
要创建索引的表名,可以有用户修饰
ONLINE
在线创建索引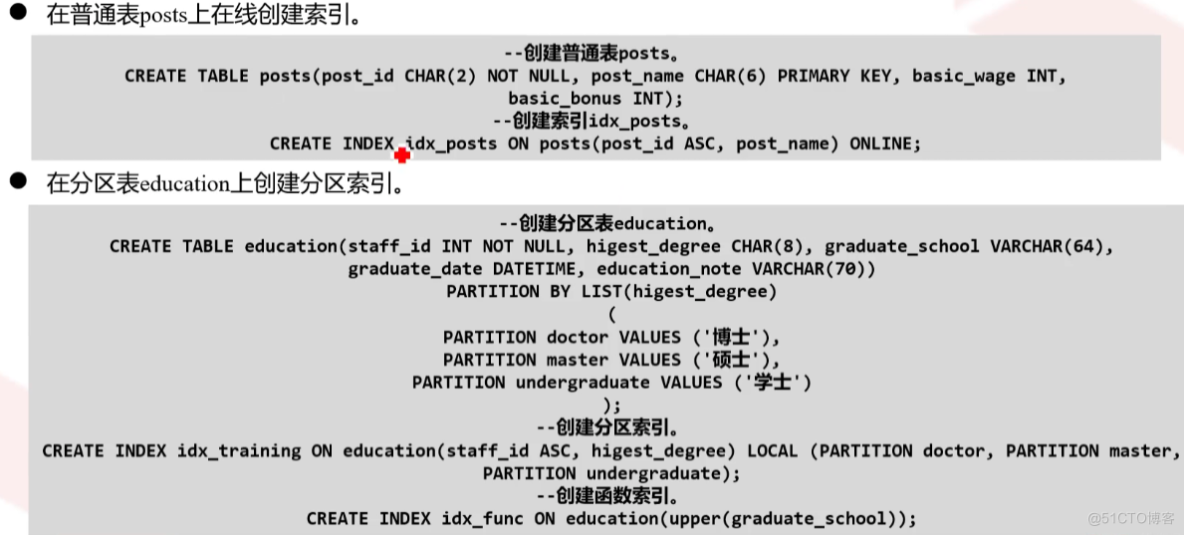
9、修改索引属性
语法格式
ALTER INDEX [ schema_name. ]index_name [ ON [ schema_name.] table_name ] { rebuild_clauses | rename_clauses }
rebuild_clauses
REBUILD ONLINE
在线创建或重建索引,这个功能的主要作用是在创建和重建索引过程中,大幅度减少对表加排它锁的时间,从而不阻塞在线业务的运行
REBUILD TABLESPACE tablespace_name
复制索引数据到其他表空间
rename_clauses
RENAME TO [schema_name.]index_name_new
待重命名的索引名
示例
创建索引idx服务器托管网_posts
CREATE INDEX idx_posts ON posts(post_id ASC,post_name) ONLINE;
在线重建索引
ALTER INDEX idx_posts REBUILD ONLINE;
重命名索引
ALTER INDEX idx_posts RENAME TO idx_posts_temp;10、删除索引
语法格式
DROP INDEX [ IF EXISTS ] [ schema_name. ]index_name [ ON [schema_name.]table_name ]
参数说明
IF EXISTS #索引不存在时,直接返回成功
[ schema_name. ]index_name #待删除索引名
ON [schema_name.]table_name
开启ENABLE_IDX_CONFS_NAME_DUPL配置项后,不同表支持索引名重名,删除索引时必须指定表名
示例
DROP INDEX IF EXISTS idx_posts ON posts;11、定义视图
视图是从一个或几个基本表中导出的虚表,可用于控制用户对数据访问,所涉及的SQL语句,如下表所示
视图与基本表不同,数据库中仅存放视图的定义,而不存放视图对应的数据,这些数据仍存放在原来的基本表中
若基本表中的数据发生变化,从视图中查询出的数据也随之改变,从这个意义上讲,视图就像一个窗口,通过它可以看到数据库中用户感兴趣的数据及变化
12、创建视图
语法格式
CREATE [ OR REPLACE ] VIEW [ schema_name. ]view_name [(alias [ ,... ])] AS subquery
参数说明
[ OR REPLACE ] #创建视图时,若视图存在则更新
[ schema_name. ]view_name #视图名
[(alias [ ,... ])] #视图列别名,若不给出,将根据后面子查询自动推导列名
AS subquery #子查询
13、删除视图
删除视图
语法格式
DROP VIEW [ IF EXISTS ] [ schema_name. ]view_name
参数说明
IF EXISTS
视图存在,则执行删除
[ schema_name. ]view_name
待删除的视图
示例
DROP VIEW IF EXISTS privilige_view;14、定义序列
序列可以产生一组等间隔的数值,能自增,主要用户表的主键,所涉及的SQL语句,如下表所示
15、创建序列
如果没有声明该子句或者声明了NOMAXVALUE,则使用默认值
递增序列的缺省最大值为263-1
递减序列的缺省最大值为-1
MINVALUE bigint|NOMINVALUE
MINVALUE声明序列的最小值
NOMINVALUE声明序列无最小值
如果没有声明该子句或者声明为NOMINVALUE,则使用默认值
递增序列的缺省最小值为1
递减序列的缺省最小值为-263+1
功能描述
向当前数据库中增加一个新的序列生成器,当前用户为该生成器的所有者
语法格式
CACHE bigint|NOCACHE
CACHE bigint表示为快速访问而在内存里预先存储序列号的个数,默认值是20,最小值是1
此处在存在约束:如果向上取整(( MAXVALUE - MINVALUE )/INCREMENT )示例
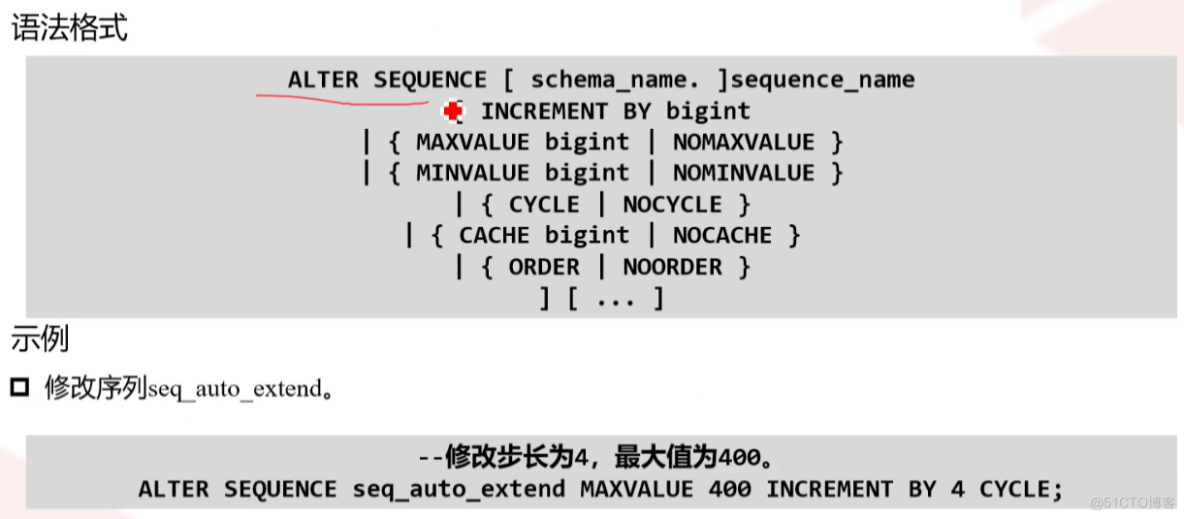
创建序列seq_auto_extend,序列起点为10,步长为2,最大值为200,序列到达最大值时可循环
create sequence seq_auto_extend start with 10 maxvalue 200 increment by 2 cycle;
得到序列的下一个值或当前值
select sea_auto_extend { nextval | currval } from dual;
通过序列实现id的自增
create table test (id number(6),name varchar(20),constraint ts_id primary key(id));
insert into test values(seq_auto_extend.nextval,'weifan');16、修改序列属性


17、删除序列
语法格式
DROP SEQUENCE [ IF EXISTS ] [ schema_name. ] sequence_name
参数说明
IF EXISTS 序列不存在时,删除也会成功
[ schema_name. ] sequence_name 待删除序列名
示例
删除序列seq_auto_extend
drop sequence if exists seq_auto_extend;服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: Kubernetes 学习总结(38)—— Kubernetes 与云原生的联系
一、什么是云原生? 伴随着云计算的浪潮,云原生概念也应运而生,而且火得一塌糊涂,大家经常说云原生,却很少有人告诉你到底什么是云原生,云原生可以理解为“云”+“原生”,Cloud 可以理解为应用程序部署在云中;Native 可以理解为应用程序从设计之初就是原生为…
