文章目录
- 1.awk简介
- 2.awk工作原理
- 3.awk的格式化输出
- 4.awk模式和动作
- 5.awk脚本编程
1.awk简介
- 作用:统计,分割,sed是直接修改文件
- awk是一种编程语言,用于在linux/unix下对文本和数据进程处理。
数据可以来自标准输入,一个或者多个文件,或者其它命令的输出。
他支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。
他在命令行中使用,但是更多是作为脚本来使用。
- awk处理文本和数据的方式是这样,他逐行扫描文件,从第1行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作 (这里与sed一样)
如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕)上;
如果没有指定模式,则所有被操作所指定的行都被处理;
gawk是awk的GUN版本。
- awk的语法形式
awk [options] 'commands' filenames
options:
-F:定义输入字段分隔符,默认的分隔符是空格或者制表符(tab)
commands:
BEGIN{} {} END{}
行处理前 行处理 行处理后
注意:
BEGIN() 通常用于定义一些变量,eg:输入时,修改字段分隔符FS=":",输出结果时,按照OFS="---"分割
[root@jiwang]# awk 'BEGIN{FS=':';OFS='---'}' {print $1,$2} passwd
root---x
bin---x
BEGIN{}发生在读文件之前,看下面的执行结果eg;
[root@jiwang]# awk 'BEGIN{print 2/5}'
0.4
[root@jiwang]# awk 'BEGIN{print 2/5} {print "ok"} END{print "----"}' /etc/hosts
0.5
ok
ok
ok
----
(1)pattern类似正则,awk 'pattern' filename
awk '/root/' passwd
(2)行处理:awk '{action}' filename
awk -F: '{print $1}' passwd
(3)awk 'pattern {action}' filename
awk 'BEGIN{FS=":"} /root/{print $1 $2}' /etc/passwd
(4)command|awk 'pattern {action}'
df -P|grep '/'|awk '$4>23000 {print $4}'
-P:表示posix,逻辑卷不会换行
2.awk工作原理
- awk -F: ‘{print $1,$3}’ /etc/passwd
-F:等价于FS=”:”
,会映射成OFS=”,”
$0可以用暂存空间来理解
(1)awk使用1行作为输入,并将这1行赋值给内部变量$0,每一行也可称之为一个记录,以换行符结束
(2)然后,行被:(默认为空格或者制表符)分解成字段(或者域) , 每个字段存储在已编号的变量中,从$1开始, 最多达到100个字段
(3)awk如何知道用空格来分隔字段的呢?因为有1个内部变量FS来确定字段分隔符。初始时,FS赋为空格
(4)awk打印字段时,将以设置的方法使用print函数打印,awk在打印的字段间加上空格,因为$1,$3之间有一个逗号。 逗号比较特殊,他映射为另一个内部变量,称之为输出字段分隔符OPS ,OPS默认为空格
(5)awk输出之后,将从文件中获取另一行,并将其存储在$0中,覆盖掉原来的那个,然后将新的字符串分隔成字段并进行处理。该过程持续到所有行处理完毕。
- 记录与字段相关的内部变量:man awk
$0:awk变量$0保存当前记录的内容
eg:awk -F : '{print $9}' /etc/passwd
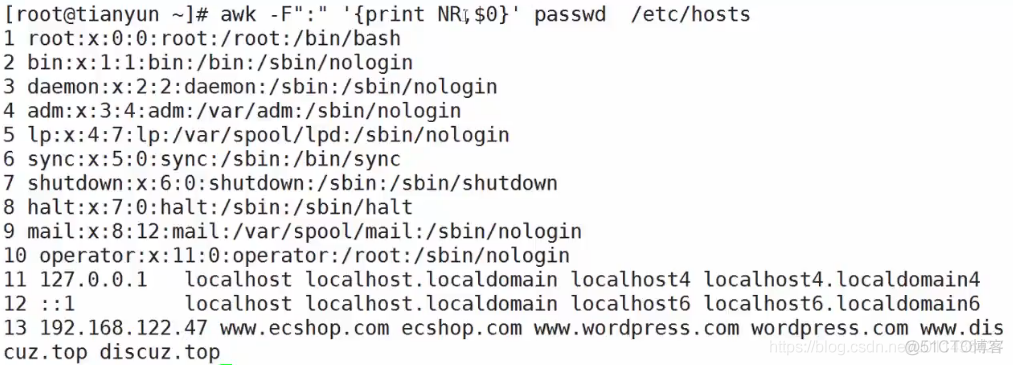
NR:the total number of input records seen so far
eg:awk -F : '{print NR, $0}' /etc/passwd /wtc/hosts
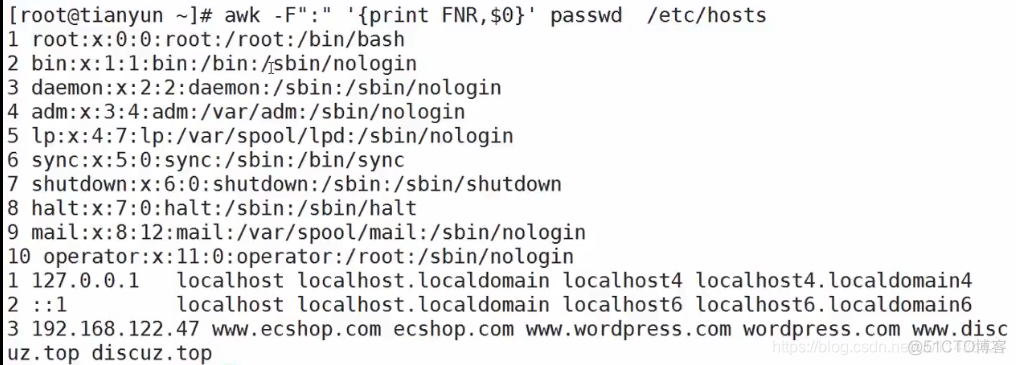
FNR:the input record number in the current input file
eg:awk -F : '{print FNR, $0}' /etc/passwd /wtc/hosts
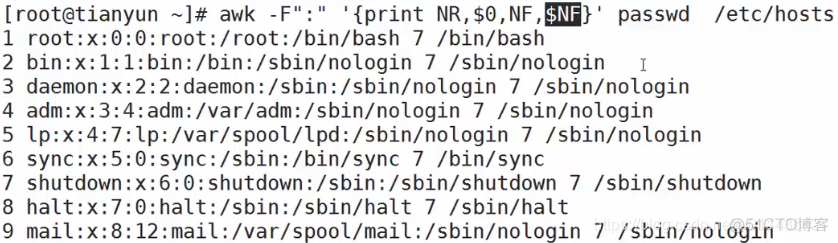
NF:保存记录的字段数,$1,$2,。。。$100,$NF指的是最后一个字段的内容
eg:awk -F: '{print $0,NF,$NF}' /etc/passwd
FS:输入字段分隔符,默认空格
eg:
awk -F: '/alice/{print $1,$3}' /etc/passwd
awk -F'[ :t]' '{print $1,$2,$3}' /etc/passwd 按照空格,tab,:分隔
awk 'BEGIN{FS=":"} {print $1}' /etc/passwd
OFS:输出字段分隔符
eg:
awk -F: '/alice/{print $1,$2}' /etc/passwd
awk 'BEGIN{FS=":"{print $1,$3}}' /etc/passwd
awk 'BEGIN{FS=":";OFS="+++"} /^root/{print $1,$2}' /etc/passwd
3.awk的格式化输出
data|awk '{print "Month: "}' $2 "nYear: " $NF
awk -F: '{print "username is:" $1 "t uid is:" $3}' /etc/passwd
%-15s:表示第1个字段占15个字符,-表示左对齐,s表示字符串
,表示OFS变量的默认值
awk -F: '{printf "%-15s %-10s %-15sn", $1,$2,$3}' /etc/passwd
%s字符类型
%d数值类型
%f浮点类型
- 表示左对齐。默认死右对齐
- printf默认不会在行尾自动换行,加n
4.awk模式和动作
- 任何awk语句都由模式和动作组成。
模式部分决定动作语句何时触发及触发事件。处理即对数据进行的操作。
如果省略模式部分,动作将时刻保持执行状态。
模式可以是任何条件语句或者复合语句或者正则表达式。
模式包括2个特殊字段BEGIN和END,使用BEGIN语句设置计数和打印头。
BEGIN语句使用在任何文本浏览动作之前,之后文本浏览动作依据输入文本开始执行。
END语句用来在awk完成文本浏览动作后,打印输出文本总数和结尾状态。
- 模式可以是:
匹配记录整行:
$0表示整行,~表示正则匹配,!表示不匹配
awk '/^alice/' /etc/passwd 等价于awk '$0 ~ /^alice/' /etc/passwd
awk '!/alice/' /etc/passwd
匹配字段:匹配操作符~,!~
awk -F: '$1 ~ /^alice/' /etc/passwd
不是以bash结尾
awk -F: '$NF !~/bash$/' /etc/passwd
- 比较表达式
(1)比较表达式采用对文本进行比较,只有当条件为真,才执行指定的动作。
比较表达式使用关系运算符,用于比较数字与字符串”XXXXX”。
(2)关系运算符
awk -F: '$3 == 0' /etc/passwd
awk -F: '$3 awk -F: '$NF == "/bin/bash"' /etc/passwd 字符串匹配,要完全一样
awk -F: '$1 ~ /alic/' /etc/passwd 模式匹配,可以匹配alice,alices
df -P|grep '/'|awk '$4 > 25000'
条件表达式
awk -F: '{if(){}}' /etc/passwd
awk -F: '{if(){} else{}}' /etc/passwd
大于300的打印整行
awk -F: '{if($3>300){print $0}}' /etc/passwd 大于300的打印整行
awk -F: '{if($3>300){print $3} else{print $1}}' /etc/passwd
算数运算:可以在模式中执行计算,awk都将按照浮点数方式执行算数运算
awk -F: '{if($3*10 > 500){print $0}}' /etc/passwd
逻辑操作符和复合模式
&& 逻辑与
|| 逻辑或
! 逻辑非
awk -F: '$1~/root/ && $3awk -F: '$1~/root/ || $3
范围模式:从哪到哪
awk '/Tom/,/Suzanne/' filename
awk '/west/' datafile 匹配west
awk '/^north/' datafile 匹配north开头
awk '$3 ~ /^north/' datafile $3匹配不是以north开头的
awk '/^(no|so)/' datafile 打印整行以no或者so开头的
awk '{print $3,$2}' datafile OFS=空格
awk '{print $3 $2}' datafile 挨在一起
awk '{print $0}' /etc/passwd 整行
awk '{print "Number of fields:"NF}' /etc/passwd 字段数量,变量不带$
awk '/northeast/{print $3,$2}' datafile 满足/northeast/才print
awk '/E/' datafile 只要带有E就打印
awk '/^[ns]/{print $1}' datafie 以n或者s开头才print
awk '$5 ~ /.[7-9]+/' datafile 匹配.7到9的1到多个
awk '$2 !~ /E/{print $1,$2}' datafile $2不匹配E,才print
awk '$3 ~ /^Joel/{print $3 "is anice boy."}' datafile $3匹配/^Joel/才print
awk '$8 ~ /[0-9][0-9]$/{print $8}' datafile /[0-9][0-9]$/表示以数字结尾
awk '$4 ~ /Chin$/{print "The price is $" $8 "."}' datafile 匹配Chin结尾的才print,$8代表第8列
awk '/Tj/{print $0}' datafile 匹配Tj才print
awk '{print $1}' /etc/passwd 打印整行,因为默认分隔是空格和tab
awk -F: '{print $1}' /etc/passwd 打印第一列
awk -F"[ :]" '{print NF}' /etc/passwd 以空格或者:分隔
111 222::yy
结果是:一根木头据两段,切1次,数空格和:数量即可,最后+1
print 4
awk '$7 == 5' datafile 数字
awk '$2 == "CT" {print $1,$2}' datafile 字符串
awk '$7 != 5' datafile
awk '$7 awk '$2 == "NW" || $1 ~ /south/ {print $1,$2}' datafile 条件1或条件2满足,才print
awk '$3 == "Chris"{ $3= "Christian";print $0}' datafile 赋值运算符
awk '/Derek/{$8+=12;print $8}' datafile //$8+=12等价于$8=$8+12
5.awk脚本编程
awk -F":" 'BEGIN{} {} END{}' passwd
只保留行处理,所以是:
awk -F":" '{}' passwd
格式:
{if(表达式){语句;语句;......}}
awk -F: '{if($3>0 && $3
格式:
{if(表达式){语句} else{语句}}
awk -F: '{if($3==0){count++} else{i++}} END{print "管理员个数:"count;print "系统用户数:"i}}' /etc/passwd /etc/passwd
格式:
{if(表达式){语句} else if(表达式){语句} else if(表达式){语句} else {语句}}
awk -F: '{if($3==0){i++} else if($3>999){k++} else{j++}} END{print i;print k;print j}}' /etc/passwd
行处理之前
awk 'BEGIN{i=1;while(i
行处理
awk -F: '{/^root/{i=1;while(i

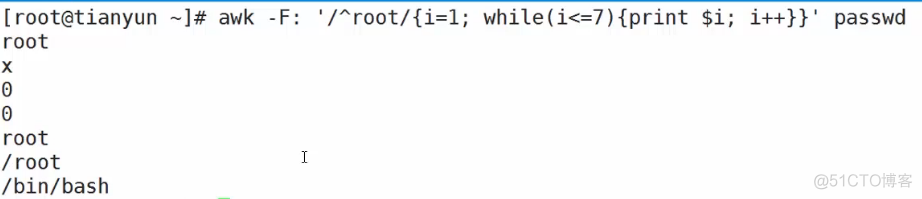
cat b.txt
111 222
333
awk '{i=1;while(i111
222
333
C风格
awk 'BEGIN{for(i=1;i111
222
333
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net

