
文章目录
-
- 创建Worker分组-指定执行机器使用
- 创建执行脚本用户
- 执行脚本
-
- 执行Shell脚本
- 执行Spark任务
-
- 执行Spark任务可能的报错
-
- Storage service config does not exist!
- 执行Hive任务
- 执行HTTP任务
-
- 创建任务
- 任务参数
- 任务样例
- 参数使用
-
- 内置参数
-
- 基础内置参数
- 衍生内置参数
- 画布中引用方法
-
- 方法一:通过自定义参数赋值引用
- 方法二:直接在脚本中使用
- 全局参数
-
- 作用域
- 使用方式
-
- 创建 Shell 任务
- 保存工作流,并设置全局参数
- 任务实例查看执行结果
- 本地参数
-
- 作用域
- 使用方式
- 任务样例
-
- 通过自定义参数使用
- 通过 `setValue` export 本地参数
- 通过 `setValue` 和自定义参数 export 本地参数
- 通过 `setValue` 和 Bash 环境变量参数 export 本地参数(根据接口返回结果赋值给下流)
- 参数传递
-
- 本地任务引用全局参数
- 上游任务传递给下游任务
- 任务样例
-
- 创建 SHELL 任务并设置参数
- 创建 SQL 任务并使用参数
- 保存工作流并设置全局参数
- 查看运行结果
- Python 任务传递参数
- 参数优先级
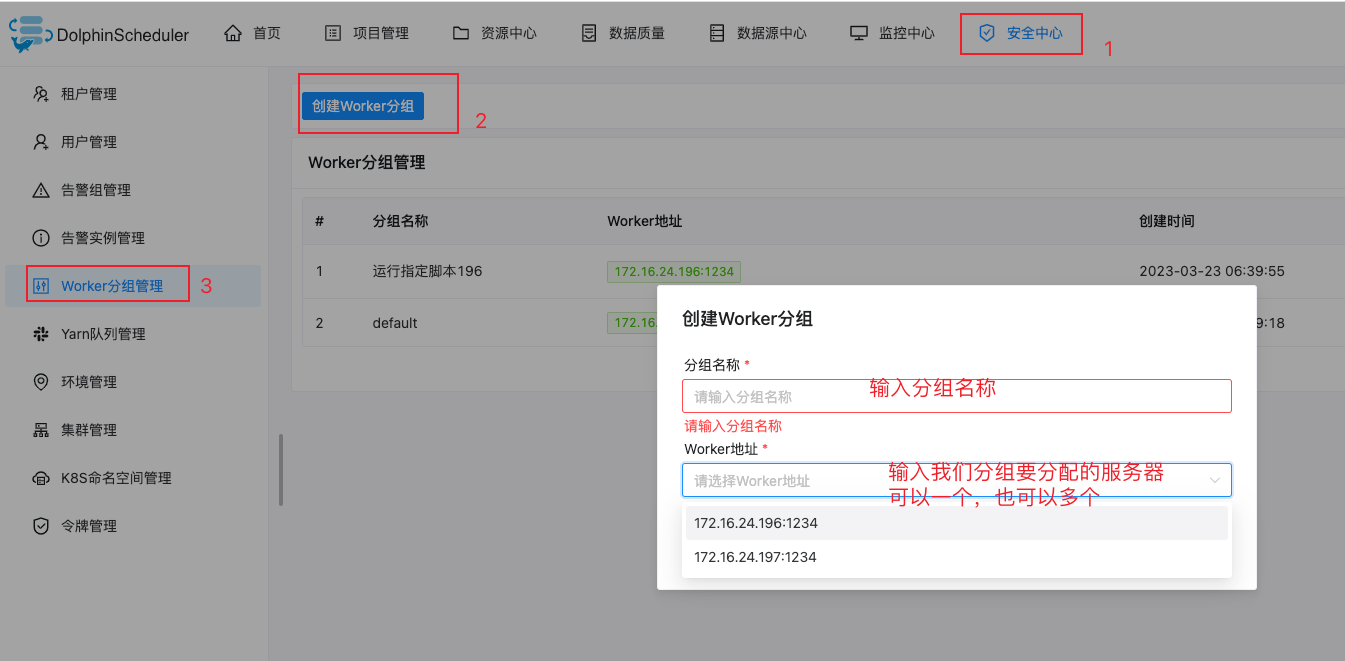
创建Worker分组-指定执行机器使用
在这里设置分组后,执行程序时选择需要执行在哪个分组内的程序执行程序
创建执行脚本用户
在安全中心->租户管理->创建用户
这里创建的用户就是对应Linux操作系统的用户,在任务调度执行时选择在Linux中执行脚本的用户

执行脚本
执行Shell脚本
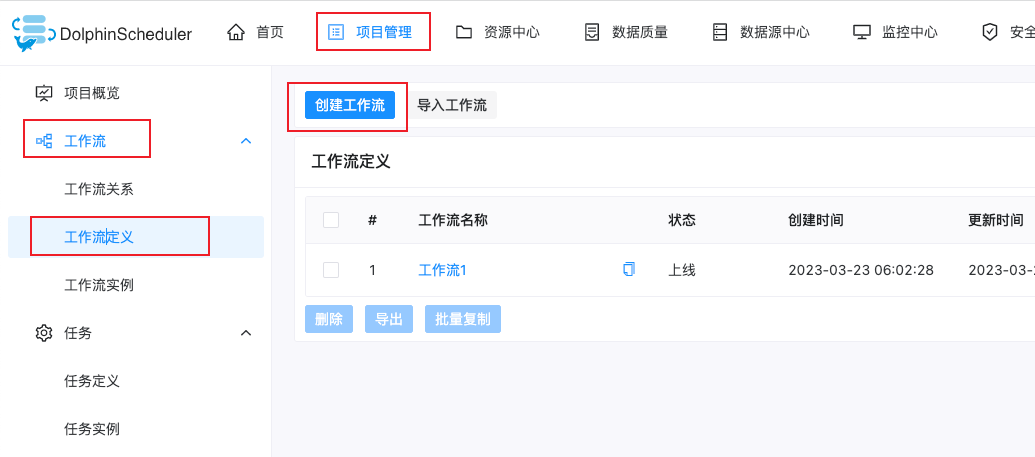
项目管理->工作流->工作流定义->创建工作流
点击创建工作流
参数说明:
- 任务名称:设置任务的名称。一个工作流定义中的节点名称是唯一的。
- 运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关。
- 描述:描述该节点的功能。
- 任务优先级:worker 线程数不足时,根据优先级从高到低依次执行,优先级一样时根据先进先出原则执行。
- Worker 分组:任务分配给 worker 组的机器机执行,选择 Default,会随机选择一台 worker 机执行。
- 环境名称:配置运行脚本的环境。
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填。
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填。
- 超时告警:勾选超时告警、超时失败,当任务超过”超时时长”后,会发送告警邮件并且任务执行失败.
- 脚本:用户开发的 SHELL 程序。
- 资源:是指脚本中需要调用的资源文件列表,资源中心-文件管理上传或创建的文件。
- 自定义参数:是 SHELL 局部的用户自定义参数,会替换脚本中以
${变量}的内容。 - 前置任务:选择当前任务的前置任务,会将被选择的前置任务设置为当前任务的上游。
将SHELL拖入画布
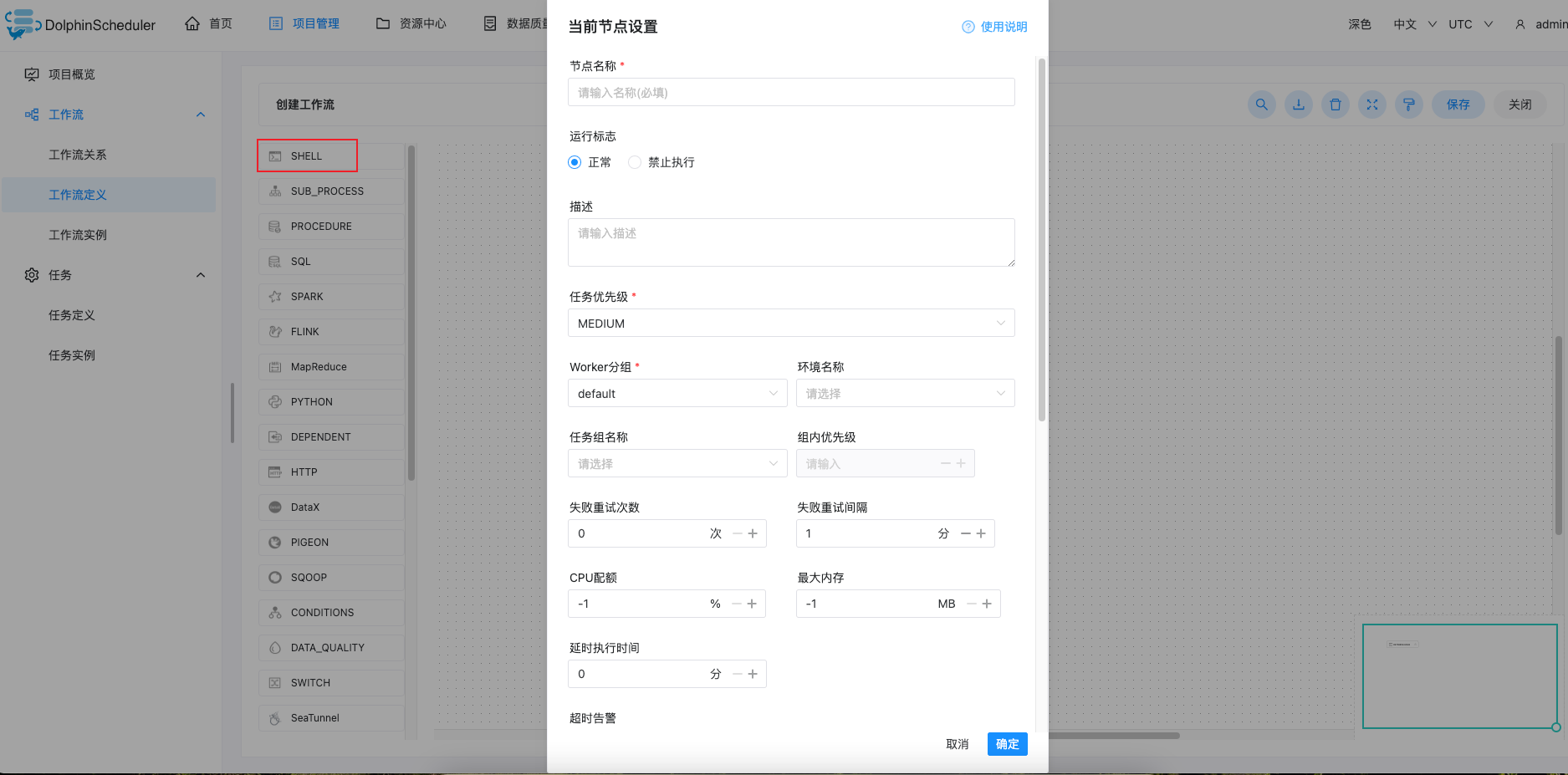
输入节点名称(命名为我们要做的内容)

输入脚本要执行的内容
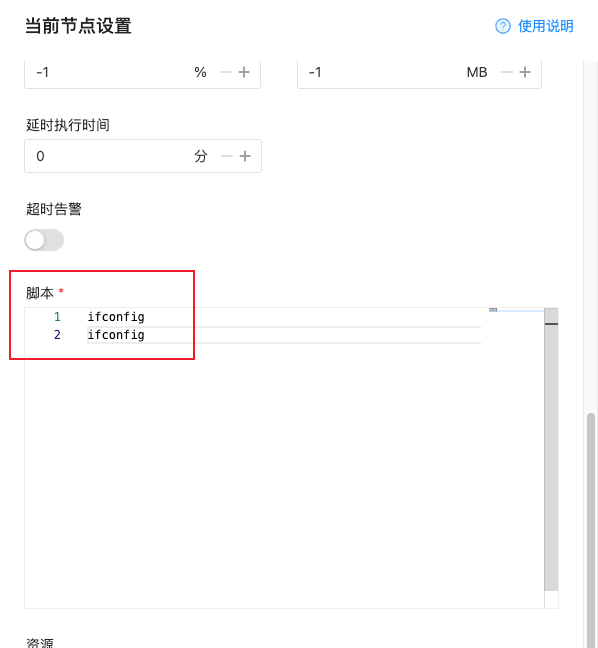
需要执行多行内容回车换行就行,这里使用相同命令执行两次来验证多行命令
再拖一个SHELL到画布,名称为:查看北京时间,内容为curl http://worldtimeapi.org/api/timezone/Asia/Shanghai
将两个任务连起来,即:执行完查看IP后,再执行查看北京时间,点击右上角保存

为工作流命名,租户选择我们配置的租户(可在安全中心->租户管理设置),并设置执行策略为串行等待
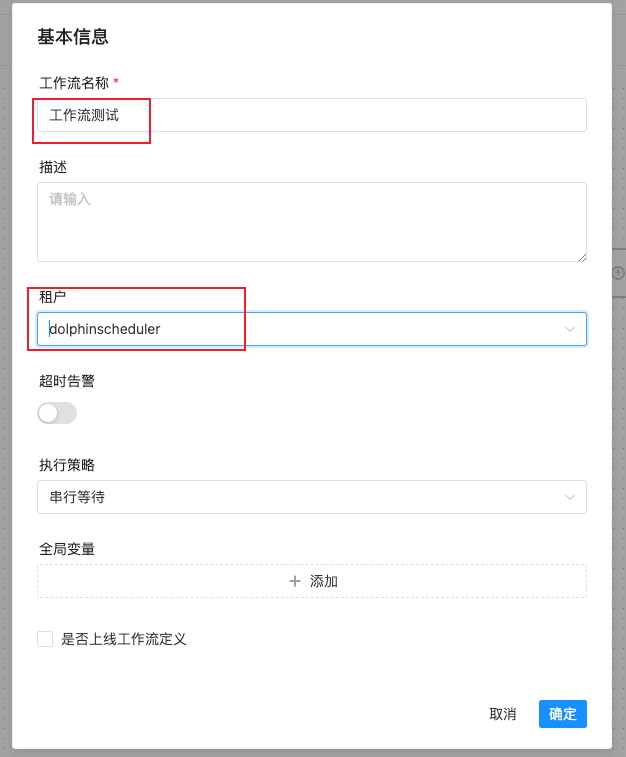
在工作流定义中可以看到我们创建的工作流
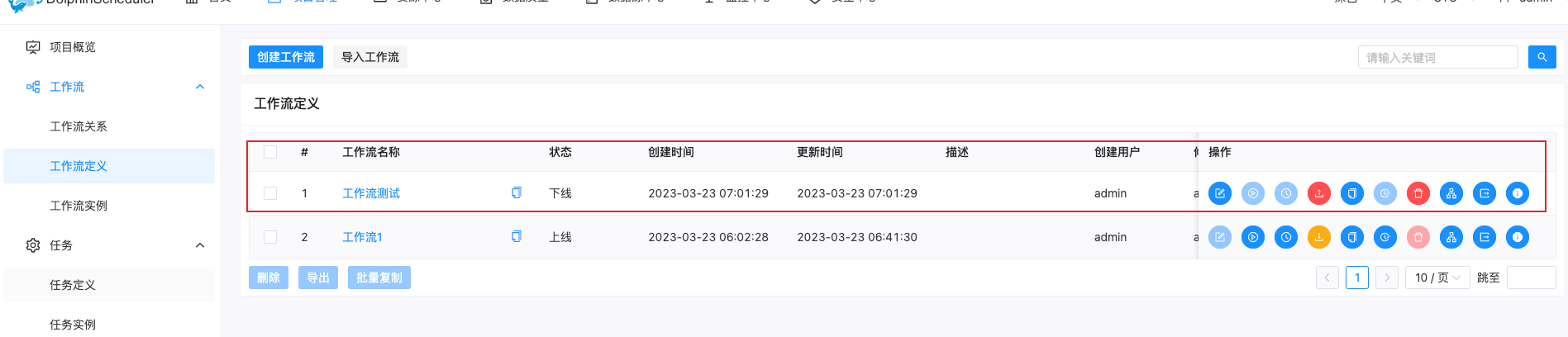
点击上线按钮后才可以执行
再点击执行

配置启动参数,保存
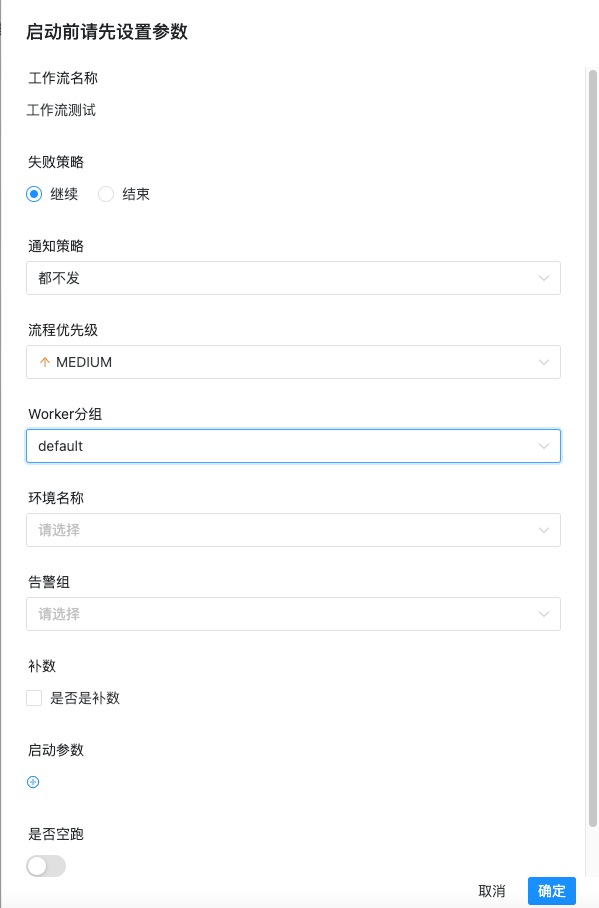
说明:
Worker分组:DolphinScheduler的Worker节点可以在安全中心->Worker分组管理将服务器进行分组,程序在执行时配置Worker分组即可在相对应的分组机器执行
执行后,在任务示例中可以看到我们执行的记录与状态,如下:
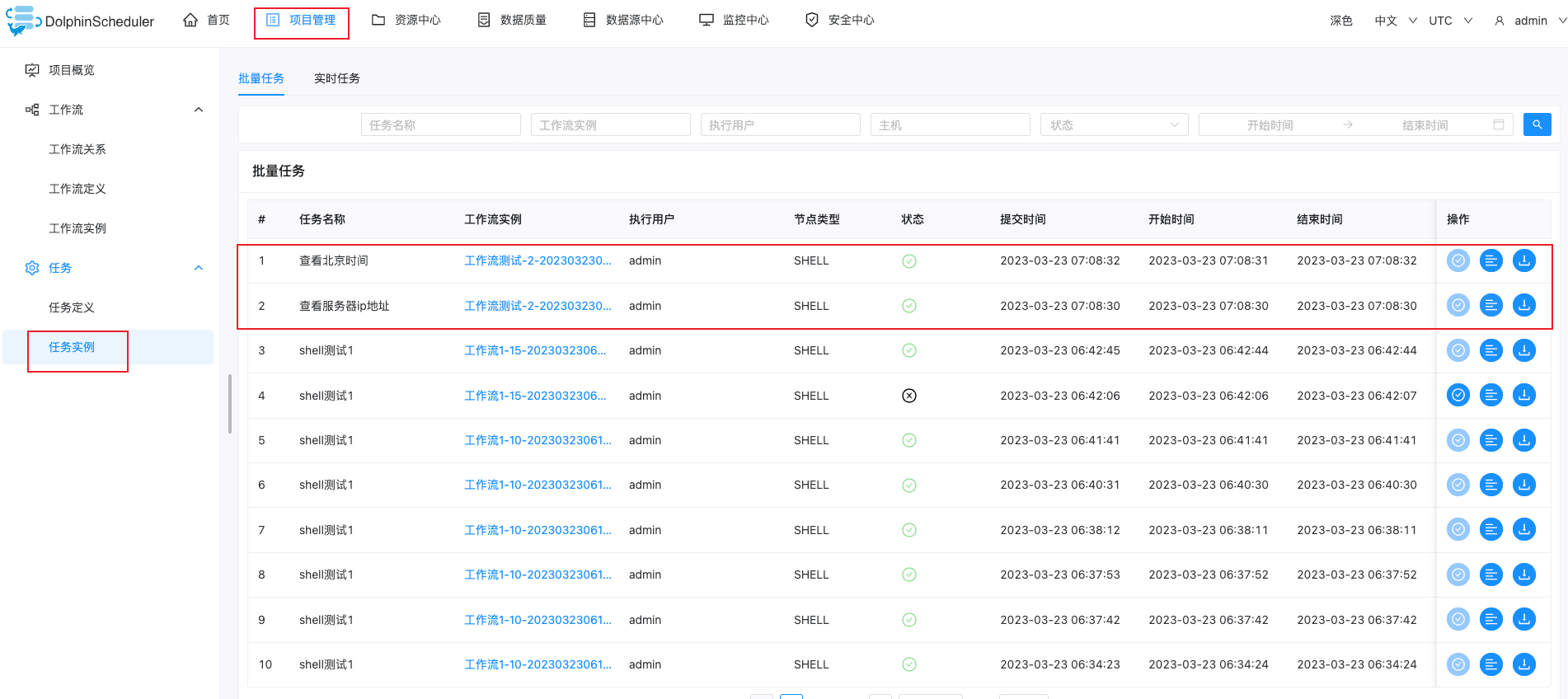
查看执行日志
查看IP的日志

查看北京时间日志
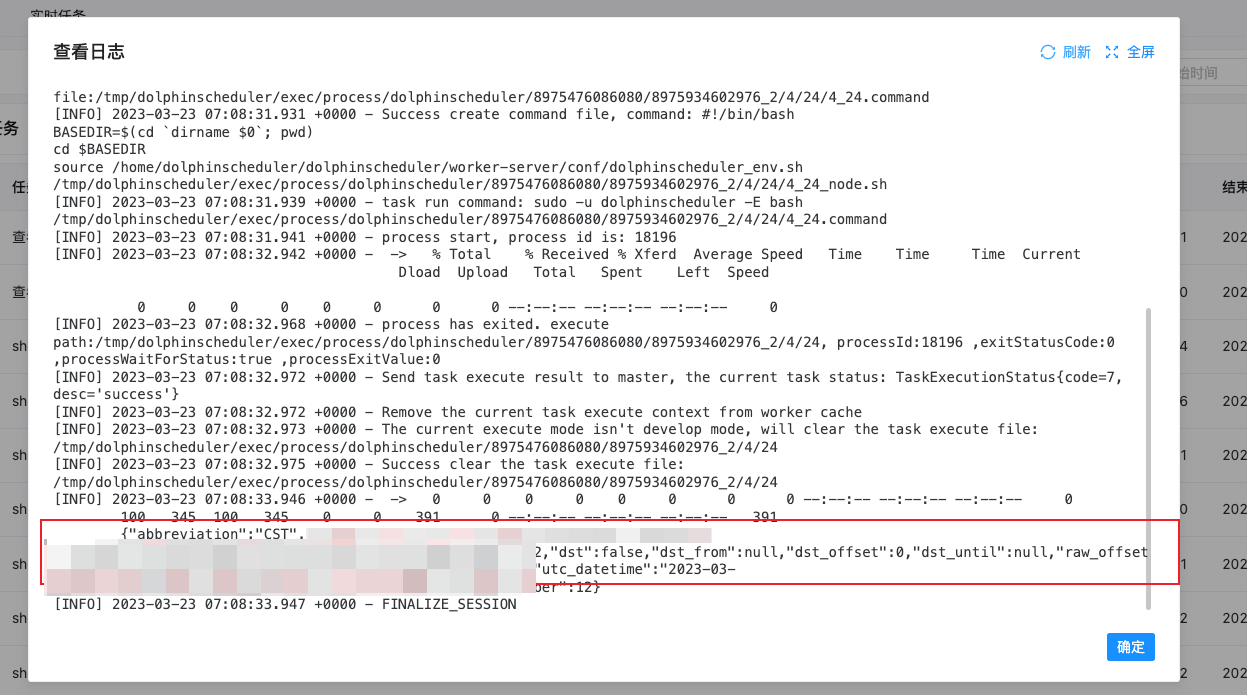
补充说明:
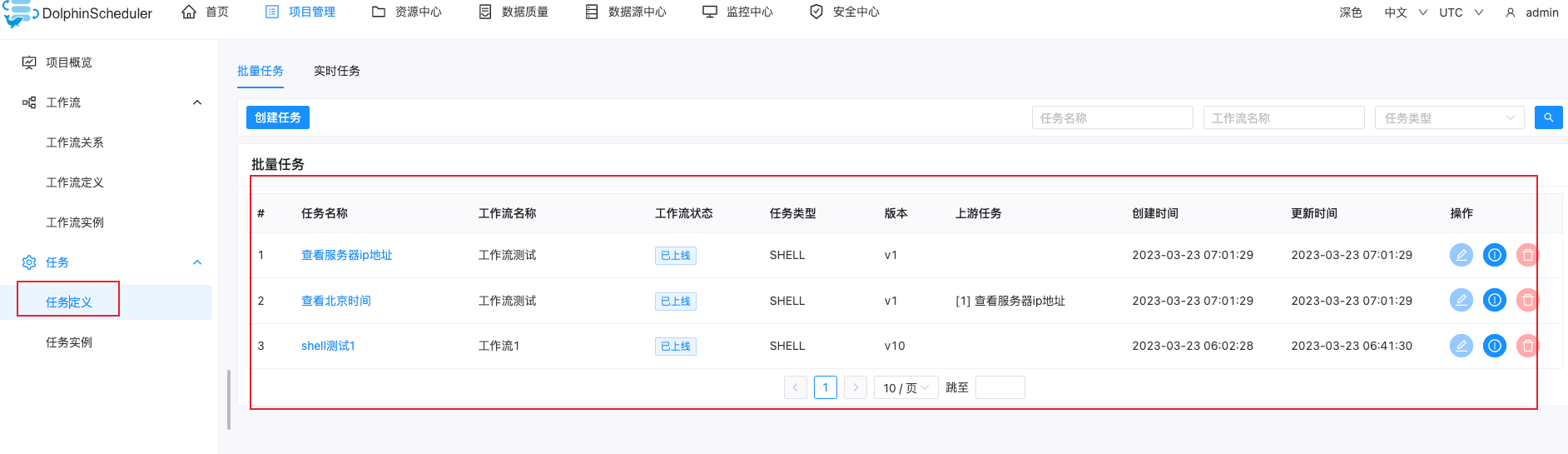
在任务定义中可以看到我们刚刚创建的所有任务
到此SHELL基础调度介绍到这里
执行Spark任务
在工作流定义中拖入Spark到画布
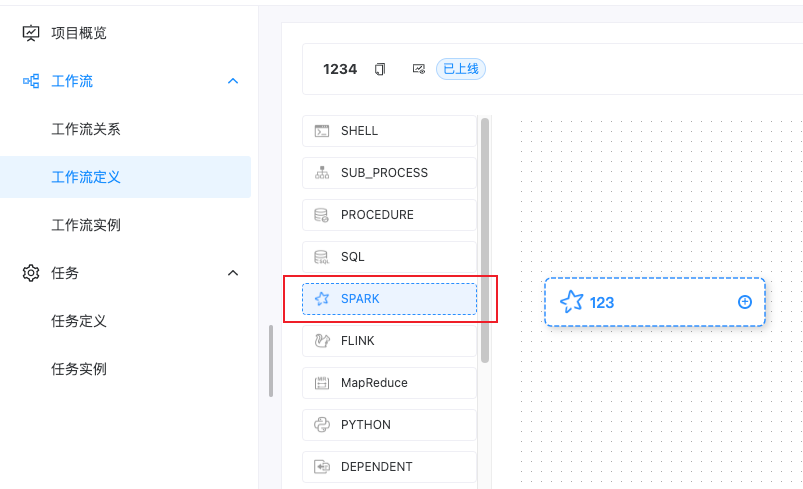
填写相关参数,参数说明:
| 参数名称 | 说明 |
|---|---|
| 节点名称 | 在画布和任务定义中显示任务的名称 |
| 运行标志 | 正常/禁止运行,禁止运行后任务不会启动不会运行 |
| 描述 | |
| 任务优先级 | |
| Worker分组 | 任务执行在哪个分组的机器 |
| 环境名称 | |
| 任务组名称 | |
| 组内优先级 | |
| 失败重试次数 | |
| 失败重试间隔 | |
| 延时执行时间 | |
| 超时警告 | 设置程序多久未执行完,未完成进行告警或失败 |
| 程序类型 | 选择Scala、Java、Python、SQL |
| Spark版本 | Spark1,Spark2 具体执行脚本为我们安装集群配置的Spark的环境变量 |
| 主函数的Class | 需要执行的类 |
| 主程序包 | 需要执行的程序Jar包,在资源中心上传后可以在这里选择 |
| 集群部署方式 | cluster/client/local |
| 任务名称 | 对应 –name |
| Driver核心数 | 对应 –driver-cores |
| Driver内存数 | 对应 –driver-memory |
| Executor数量 | 对应 –num-executors |
| Executor内存数 | 对应 –executor-memory |
| Executor核心数 | 对应 –executor-cores |
| 主程序参数 | 程序入口传入的参数 |
| 选项参数 | 自定义传入参数如:–jars $(echo /data/spark-job/label-offline/lib/*.jar –files /data/spark-job/cdp-label-offline/env.properties |
| 资源 | |
| 自定义参数 | |
| 前置任务 |
执行Spark任务可能的报错
Storage service config does not exist!
[ERROR] 2023-03-23 09:51:50.024 +0000 - Task execute failed, due to meet an exception
org.apache.dolphinscheduler.common.exception.StorageOperateNoConfiguredException: Storage service config does not exist!
at org.apache.dolphinscheduler.server.worker.utils.TaskExecutionCheckerUtils.downloadResourcesIfNeeded(TaskExecutionCheckerUtils.java:115)
at org.apache.dolphinscheduler.server.worker.runner.WorkerTaskExecuteRunnable.beforeExecute(WorkerTaskExecuteRunnable.java:216)
at org.apache.dolphinscheduler.server.worker.runner.WorkerTaskExecuteRunnable.run(WorkerTaskExecuteRunnable.java:170)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:131)
at com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:74)
at com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:82)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
[INFO] 2023-03-23 09:51:50.026 +0000 - Get a exception when execute the task, will send the task execute result to master, the current task execute result is TaskExecutionStatus{code=6, desc='failure'}
原因:
配置资源中心时worker-server/conf/common.properties忘记配置HDFS配置了,只配置了api-server/conf/common.properties
解决方法:
在worker-server/conf/common.properties配置文件中添加HDFS配置,重新部署服务sh bin/install.sh
# user data local directory path, please make sure the directory exists and have read write permissions
data.basedir.path=/tmp/dolphinscheduler
# resource storage type: HDFS, S3, OSS, NONE
resource.storage.type=HDFS
# if resource.storage.type=HDFS, the user must have the permission to create directories under the HDFS root path
resource.hdfs.root.user=hdfs
# if resource.storage.type=S3, the value like: s3a://dolphinscheduler; if resource.storage.type=HDFS and namenode HA is enabled, you need to copy core-site.xml and hdfs-site.xml to conf dir
resource.hdfs.fs.defaultFS=hdfs://172.16.24.194:8020
# resourcemanager port, the default value is 8088 if not specified
resource.manager.httpaddress.port=8088
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single, keep this value empty
yarn.resourcemanager.ha.rm.ids=
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single, you only need to replace ds1 to actual resourcemanager hostname
yarn.application.status.address=http://172.16.4.194:%s/ws/v1/cluster/apps/%s
# job history status url when application number threshold is reached(default 10000, maybe it was set to 1000)
yarn.job.history.status.address=http://172.16.24.195:19888/ws/v1/history/mapreduce/jobs/%s
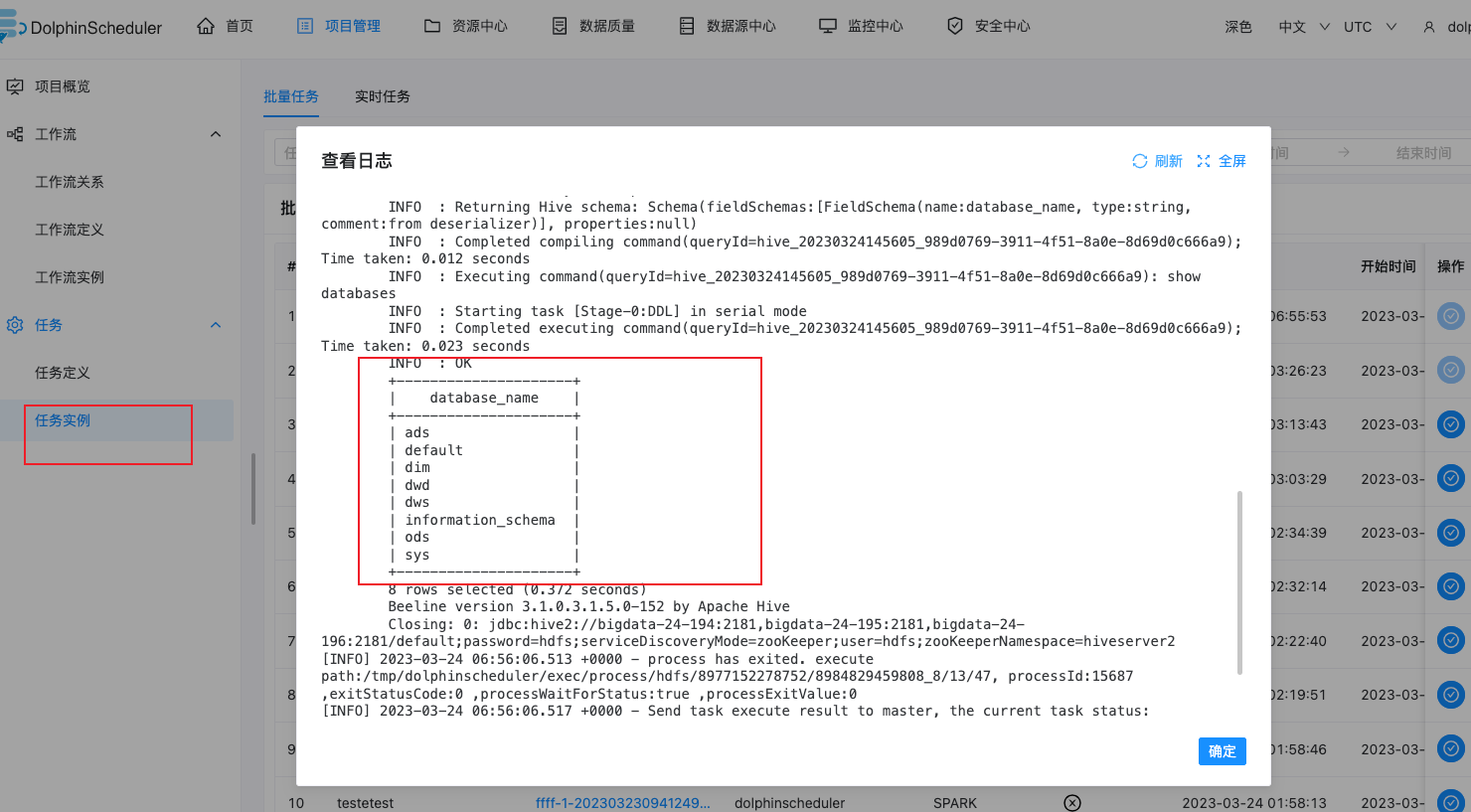
执行Hive任务
拖入Hive到画布,填写节点名称,Hive Clie任务类型,Hive SQL脚本

保存执行,在任务实例查看日志,可以查看到我们执行的命令结果
执行HTTP任务
该节点用于执行 http 类型的任务,例如常见的 POST、GET 等请求类型,此外还支持 http 请求校验等功能。
创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击”创建工作流”按钮,进入 DAG 编辑页面:
- 拖动工具栏的
 任务节点到画板中。
任务节点到画板中。
任务参数
- 节点名称:设置任务的名称。一个工作流定义中的节点名称是唯一的。
- 运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关。
- 描述:描述该节点的功能。
- 任务优先级:worker 线程数不足时,根据优先级从高到低依次执行,优先级一样时根据先进先出原则执行。
- Worker 分组:任务分配给 worker 组的机器机执行,选择 Default,会随机选择一台 worker 机执行。
- 环境名称:配置运行任务的环境。
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填。
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填。
- 延迟执行时间:任务延迟执行的时间,以分为单位。
- 超时告警:勾选超时告警、超时失败,当任务超过”超时时长”后,会发送告警邮件并且任务执行失败。
- 请求地址:http 请求 URL。
- 请求类型:支持 GET、POST、HEAD、PUT、DELETE。
- 请求参数:支持 Parameter、Body、Headers。
- 校验条件:支持默认响应码、自定义响应码、内容包含、内容不包含。
- 校验内容:当校验条件选择自定义响应码、内容包含、内容不包含时,需填写校验内容。
- 自定义参数:是 http 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。
- 前置任务:选择当前任务的前置任务,会将被选择的前置任务设置为当前任务的上游。
任务样例
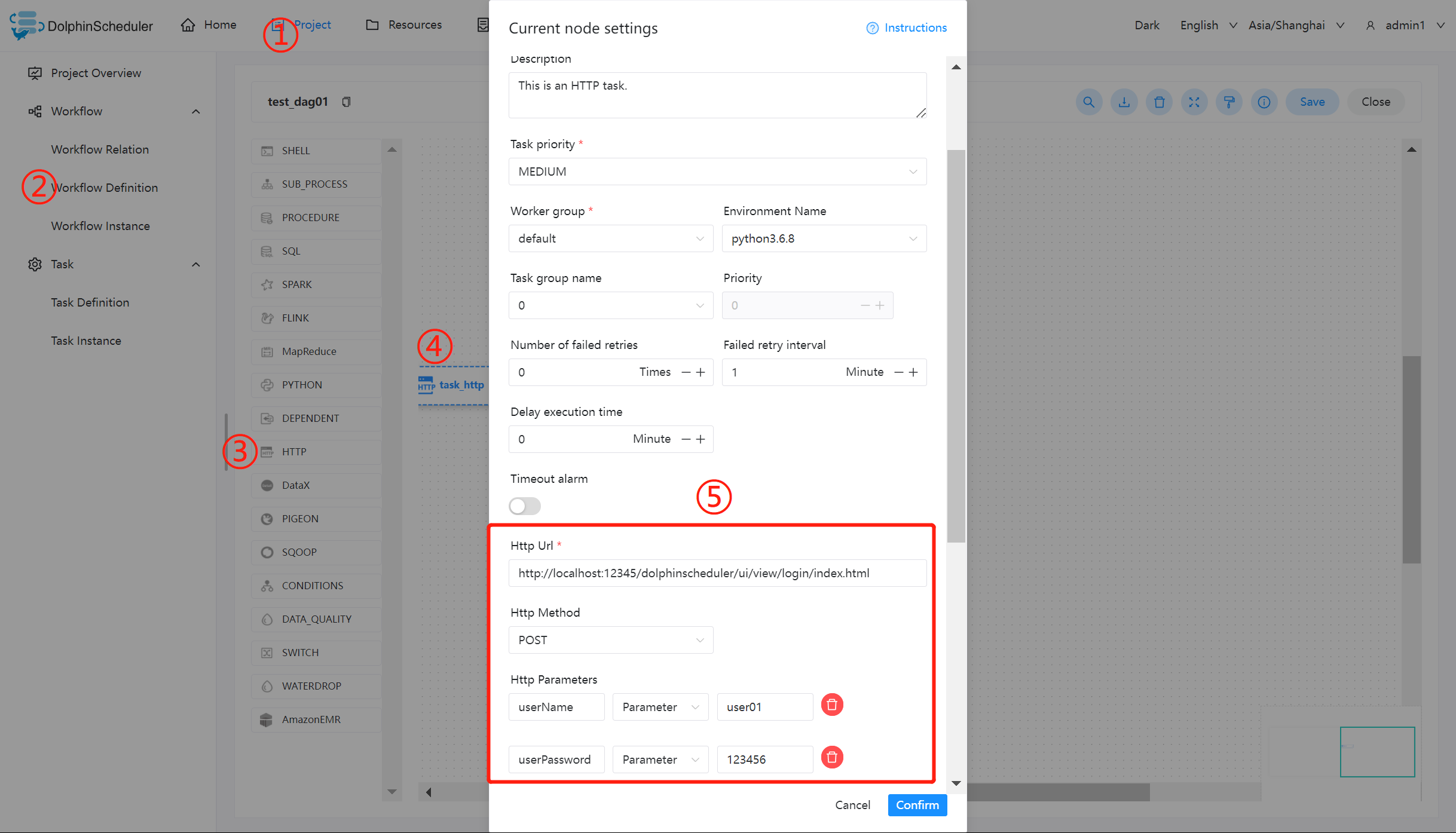
HTTP* 定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。这里我们使用 http 任务节点,演示使用 POST 向系统的登录页面发送请求,提交数据。
主要配置参数如下:
- URL:访问目标资源的地址,这里为系统的登录页面。
- HTTP Parameters
- userName:用户名;
- userPassword:用户登录密码。
参数使用
内置参数
基础内置参数
| 变量名 | 声明方式 | 含义 |
|---|---|---|
| system.biz.date | ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd |
| system.biz.curdate | ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd |
| system.datetime | ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss |
衍生内置参数
-
支持代码中自定义变量名,声明方式:${变量名}。可以是引用 “系统参数”
-
我们定义这种基准变量为
[
…
]
格式的,
[…] 格式的,
[…]格式的,[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
-
也可以通过以下两种方式:
1.使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
- 后 N 年:$[add_months(yyyyMMdd,12*N)]
- 前 N 年:$[add_months(yyyyMMdd,-12*N)]
- 后 N 月:$[add_months(yyyyMMdd,N)]
- 前 N 月:$[add_months(yyyyMMdd,-N)]
2.直接加减数字 在自定义格式后直接“+/-”数字
- 后 N 周:$[yyyyMMdd+7*N]
- 前 N 周:$[yyyyMMdd-7*N]
- 后 N 天:$[yyyyMMdd+N]
- 前 N 天:$[yyyyMMdd-N]
- 后 N 小时:$[HHmmss+N/24]
- 前 N 小时:$[HHmmss-N/24]
- 后 N 分钟:$[HHmmss+N/24/60]
- 前 N 分钟:$[HHmmss-N/24/60]
画布中引用方法
方法一:通过自定义参数赋值引用
IN 是在当前运行脚本中生效
OUT 是在DAG图的下一个脚本生效
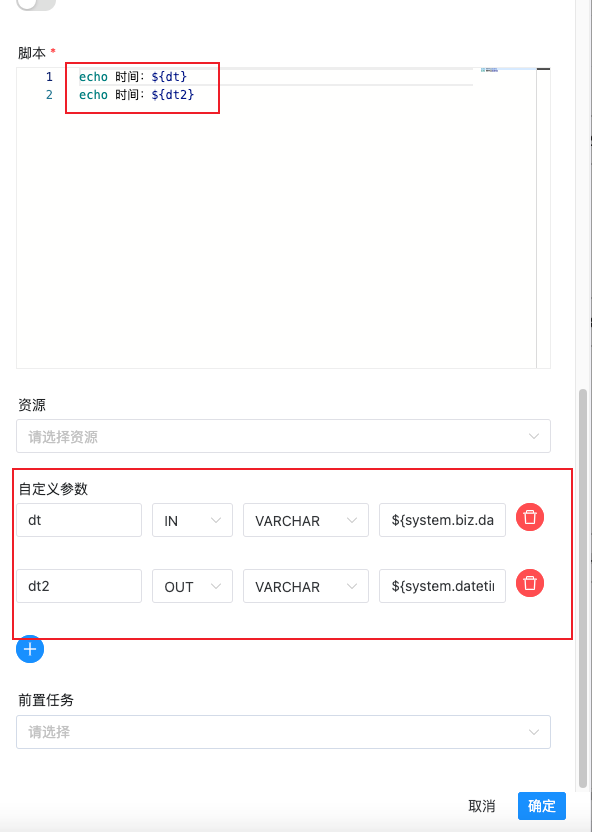
方法二:直接在脚本中使用

全局参数
作用域
全局参数是指针对整个工作流的所有任务节点都有效的参数,在工作流定义页面配置。
使用方式
具体的使用方式可结合实际的生产情况而定,这里演示为使用 Shell 任务打印出前一天的日期。
创建 Shell 任务
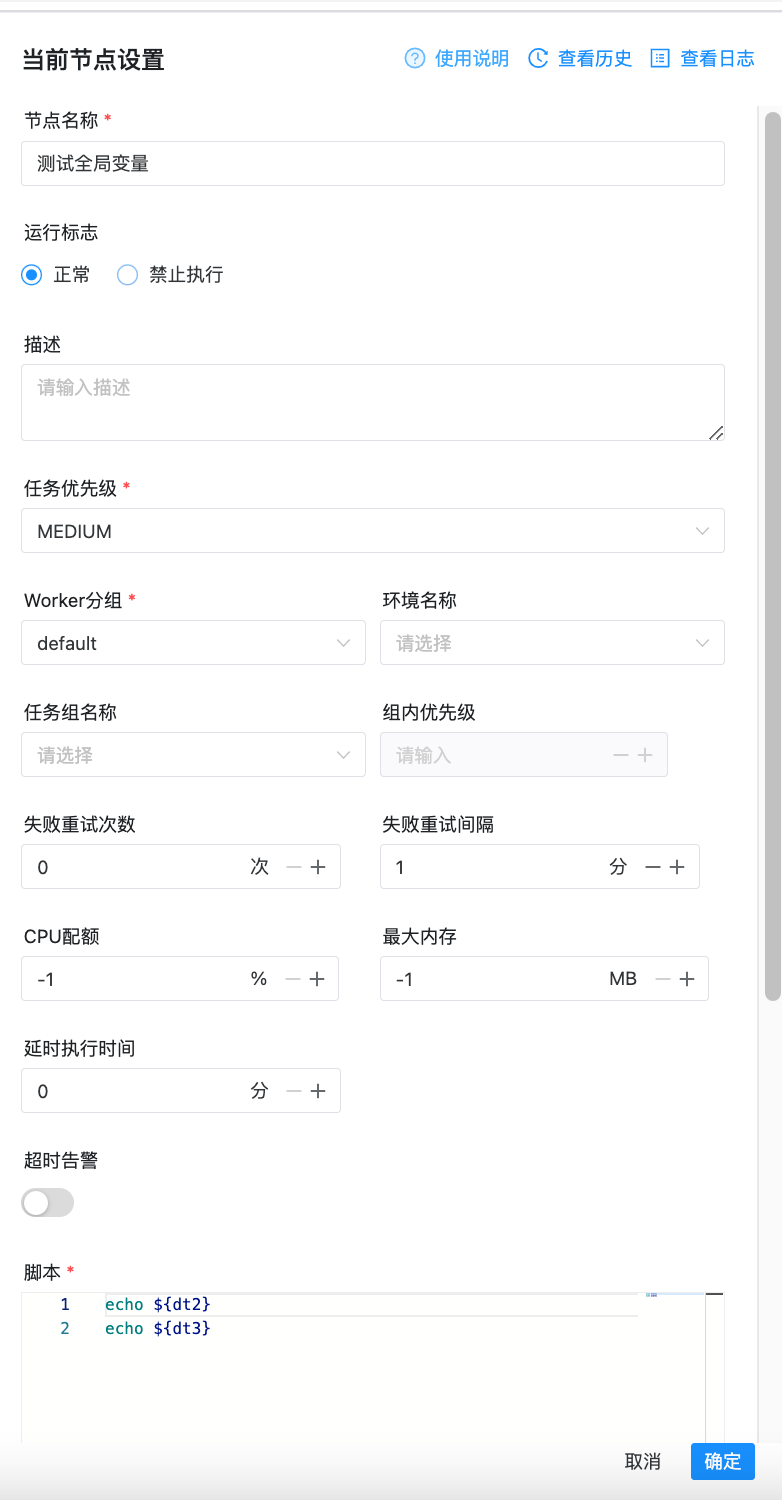
创建一个 Shell 任务,并在脚本内容中输入 echo ${dt2}。此时 dt2 则为我们需要声明的全局参数。如下图所示:
保存工作流,并设置全局参数
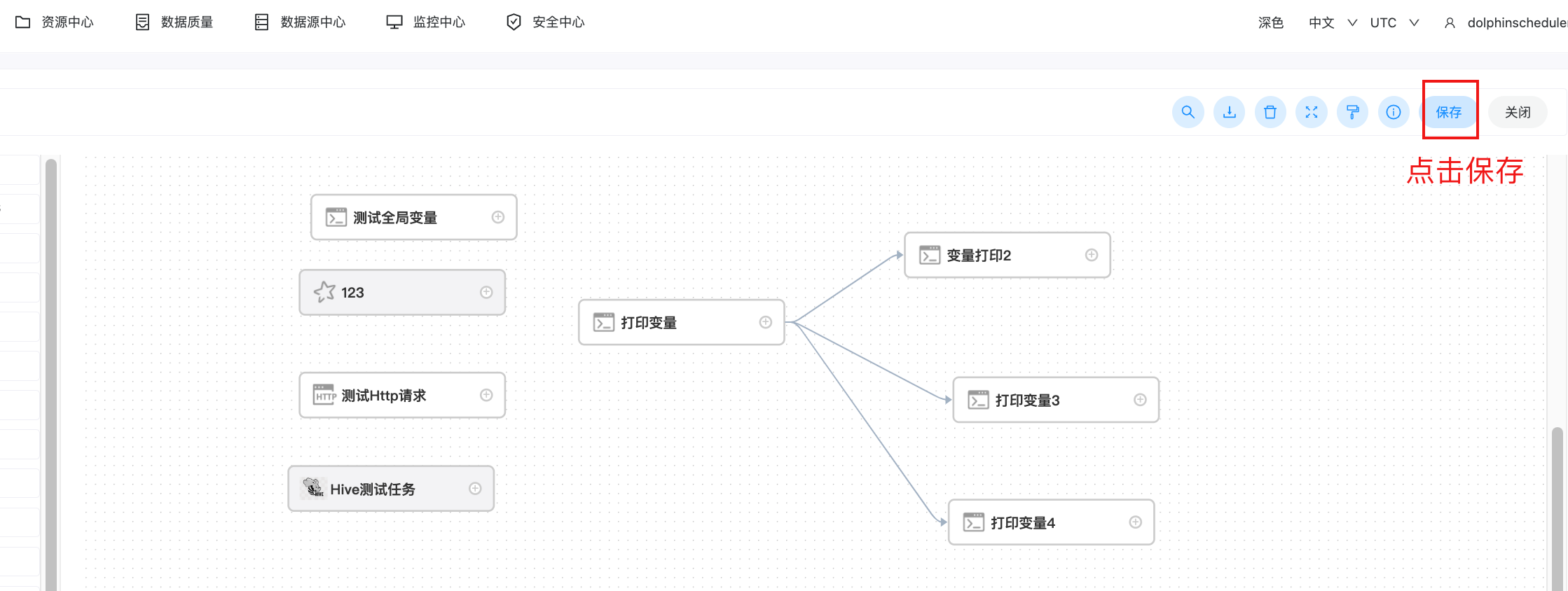
全局参数配置方式如下:在工作流定义页面,点击“设置全局”右边的加号,填写对应的变量名称和对应的值,保存即可。如下图所示:

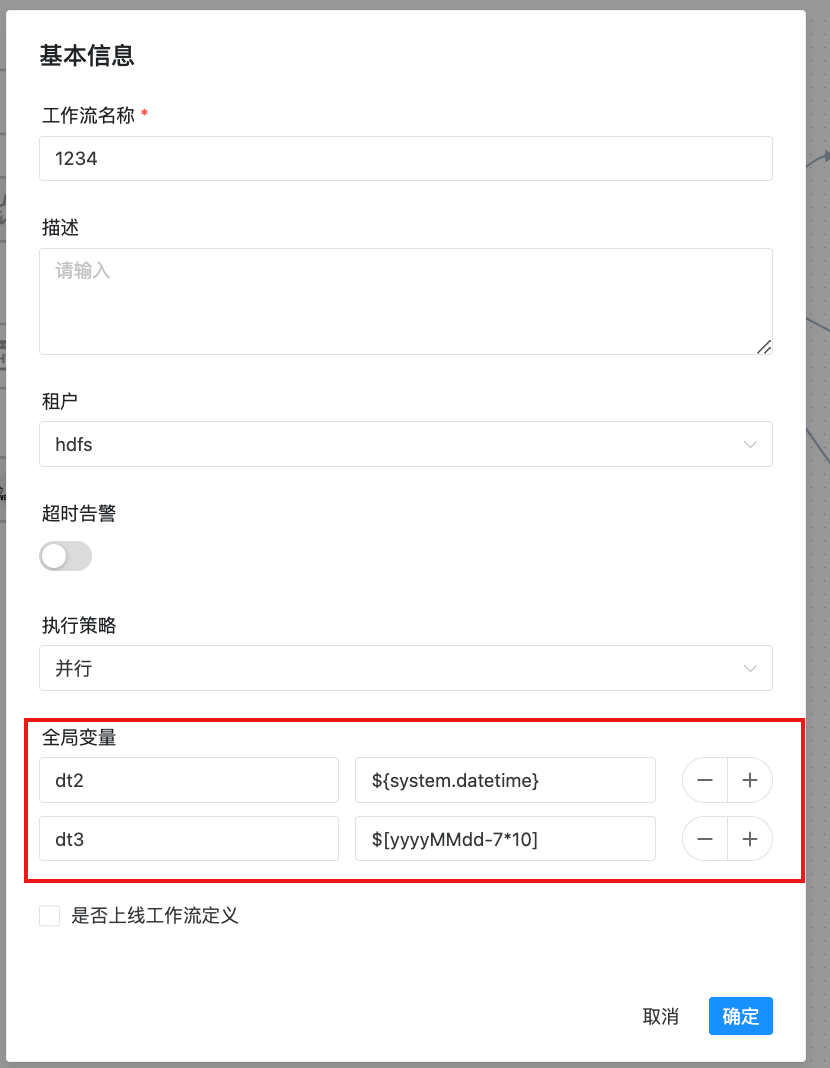
注:这里定义的 dt2,dt3 参数可以被其它任一节点的局部参数引用。
任务实例查看执行结果
进入任务实例页面,可以通过查看日志,验证任务的执行结果,判断参数是否有效。

本地参数
作用域
在任务定义页面配置的参数,默认作用域仅限该任务,如果配置了参数传递则可将该参数作用到下游任务中。
使用方式
本地参数配置方式如下:在任务定义页面,点击“自定义参数”右边的加号,填写对应的变量名称和对应的值,保存即可。
- 如果要在单个任务中使用参数,请参阅通过自定义参数使用
- 如果要在任务中使用配置参数并在下游任务中使用它们:
- 如果你只是想要简单使用,且不使用自定义参数, 请参阅 通过
setValue和自定义参数 export 本地参数 - 如果想要使用自定义参数, 请参阅 通过
setValue和自定义参数 export 本地参数 - 如果想要使用 Bash 参数, 请参阅 通过
setValue和 Bash 环境变量参数 export 本地参数
- 如果你只是想要简单使用,且不使用自定义参数, 请参阅 通过
任务样例
通过自定义参数使用
本样例展示了如何使用本地参数,打印输出当前日期。创建一个 Shell 任务,并编写脚本内容为 echo ${dt}。点击配置栏中的自定义参数,配置如下图所示:
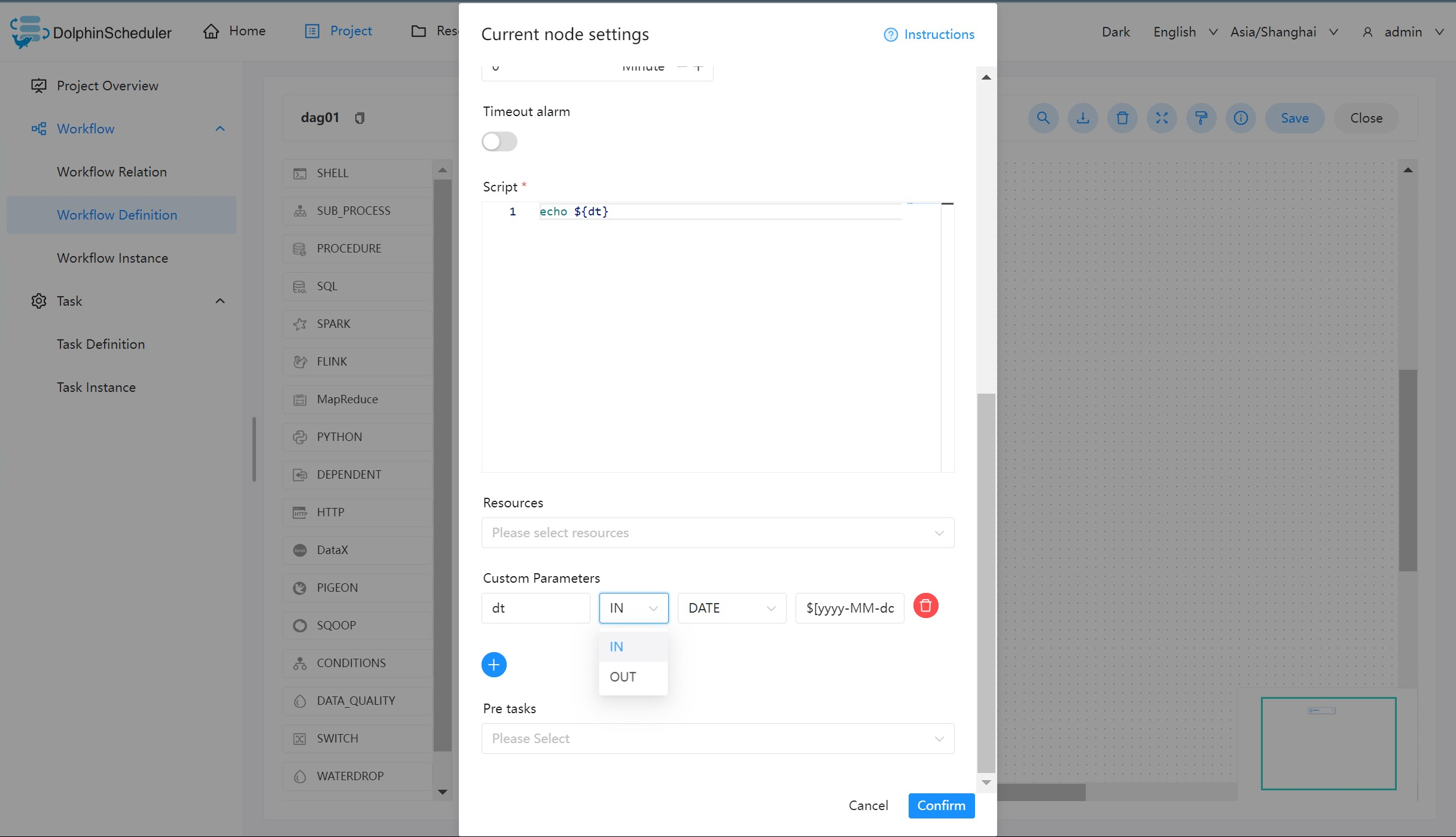
参数说明:
- dt:参数名
- IN:IN 表示局部参数仅能在当前节点使用,OUT 表示局部参数可以向下游传递
- DATE:数据类型,日期
- $[yyyy-MM-dd]:自定义格式的衍生内置参数
保存工作流并运行,查看 Shell 任务输出日志。

注:本地参数可以在当前任务节点的工作流中,设置其为 OUT 则可以传递给下游的工作流使用,可以参考:参数传递
通过 setValue export 本地参数
如果你想简单 export 参数然后在下游任务中使用它们,你可以在你的任务中使用 setValue,你可以将参数统一在一个任务中管理。在 Shell 任务中使用语法 echo '${setValue(set_val=123)}'(不要忘记单引号) 并添加新的 OUT 自定义参数来 export 它。
注意:
echo '${setValue(set_val=123)}'不会再shell脚本中输出内容,就是做的赋值操作

你可以在下游任务中使用语法 echo '${set_val}' 在获取设定的值。
通过 setValue 和自定义参数 export 本地参数
如果你想用自定义参数而不是常量值来实现参数 export,并下游任务中使用它们,你可以在通过 setValue 和 自定义参数实现,当你想改变参数的值时可以直接改变 “自定义参数”模块中的值,这让程序更加容易维护。您可以在 Shell 任务中使用语法 echo "#{setValue(set_val_param=${val})}"(如果你想要将任何 变量赋值给 setValue 请不要忘记使用双引号)并添加新的 IN 自定义参数用于输入变量 val 和 OUT 自定义参数用于 export 参数 set_val_param。

你可以在下游任务中使用语法 echo '${set_val_param}' 在获取设定的值。
通过 setValue 和 Bash 环境变量参数 export 本地参数(根据接口返回结果赋值给下流)
如果你想用 bash 变量而不是常量值 export 参数,并在下游任务中使用它们,你可以在通过 setValue 和 Bash 变量实现,它更灵活,例如你动态获取现有的本地 或 HTTP 资源获取设定变量。 您可以使用类似的语法。
lines_num=$(wget https://raw.githubusercontent.com/apache/dolphinscheduler/dev/README.md -q -O - | wc -l | xargs)
echo "#{setValue(set_val_var=${lines_num})}"
在 Shell 任务中(如果你想要将任何变量赋值给 setValue 请不要忘记使用双引号)和 OUT 自定义参数用于 export 参数 set_val_var。 .

你可以在下游任务中使用语法 echo '${set_val_var}' 在获取设定的值。
参数传递
DolphinScheduler 提供参数间相互引用的能力,包括:本地参数引用全局参数、上下游参数传递。因为有引用的存在,就涉及当参数名相同时,参数的优先级问题,详见参数优先级
本地任务引用全局参数
本地任务引用全局参数的前提是,你已经定义了全局参数,使用方式和本地参数中的使用方式类似,但是参数的值需要配置成全局参数中的 key。
上游任务传递给下游任务
DolphinScheduler 允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
- Shell
- SQL
- Procedure
- Python
当定义上游节点时,如果有需要将该节点的结果传递给有依赖关系的下游节点,需要在【当前节点设置】的【自定义参数】设置一个方向是 OUT 的变量。目前我们主要针对 SQL 和 SHELL 节点做了可以向下传递参数的功能。
上游传递的参数可以在下游节点中被更新,更新方法与设置参数相同。
如果定义了同名的传递参数,上游节点的参数将被覆盖。
注:若节点之间没有依赖关系,则局部参数无法通过上游传递。
任务样例
本样例展示了如何使用参数传递的功能,通过 SHELL 任务来创建本地参数并赋值传递给下游,SQL 任务通过获得上游任务的参数完成查询操作。
创建 SHELL 任务并设置参数
用户需要传递参数,在定义 SHELL 脚本时,需要输出格式为 ${setValue(key=value)} 的语句,key 为对应参数的 prop,value 为该参数的值。
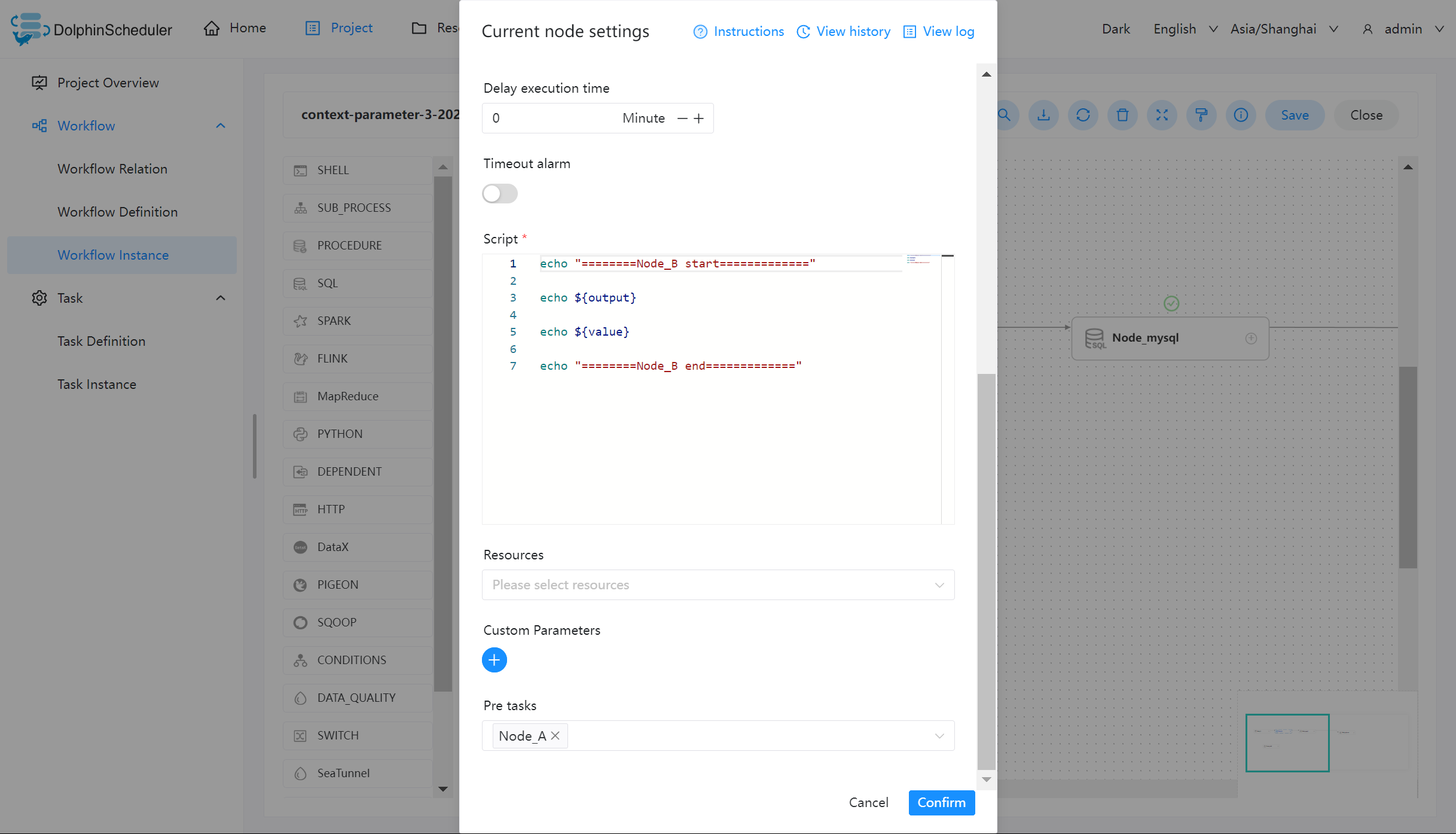
创建 Node_A 任务,在自定义参数中添加 output 和 value 参数,并编写如下脚本:

参数说明:
- value:方向选择为 IN,并赋值为 66
- output:方向选择为 OUT,通过脚本
'${setValue(output=1)}'赋值,并传递给下游参数
SHELL 节点定义时当日志检测到 ${setValue(output=1)} 的格式时,会将 1 赋值给 output,下游节点便可以直接使用变量 output 的值。同样,您可以在【工作流实例】页面,找到对应的节点实例,便可以查看该变量的值。
创建 Node_B 任务,主要用于测试输出上游任务 Node_A 传递的参数。
创建 SQL 任务并使用参数
完成上述的 SHELL 任务之后,我们可以使用上游所传递的 output 作为 SQL 的查询对象。其中将所查询的 id 重命名为 ID,作为参数输出。
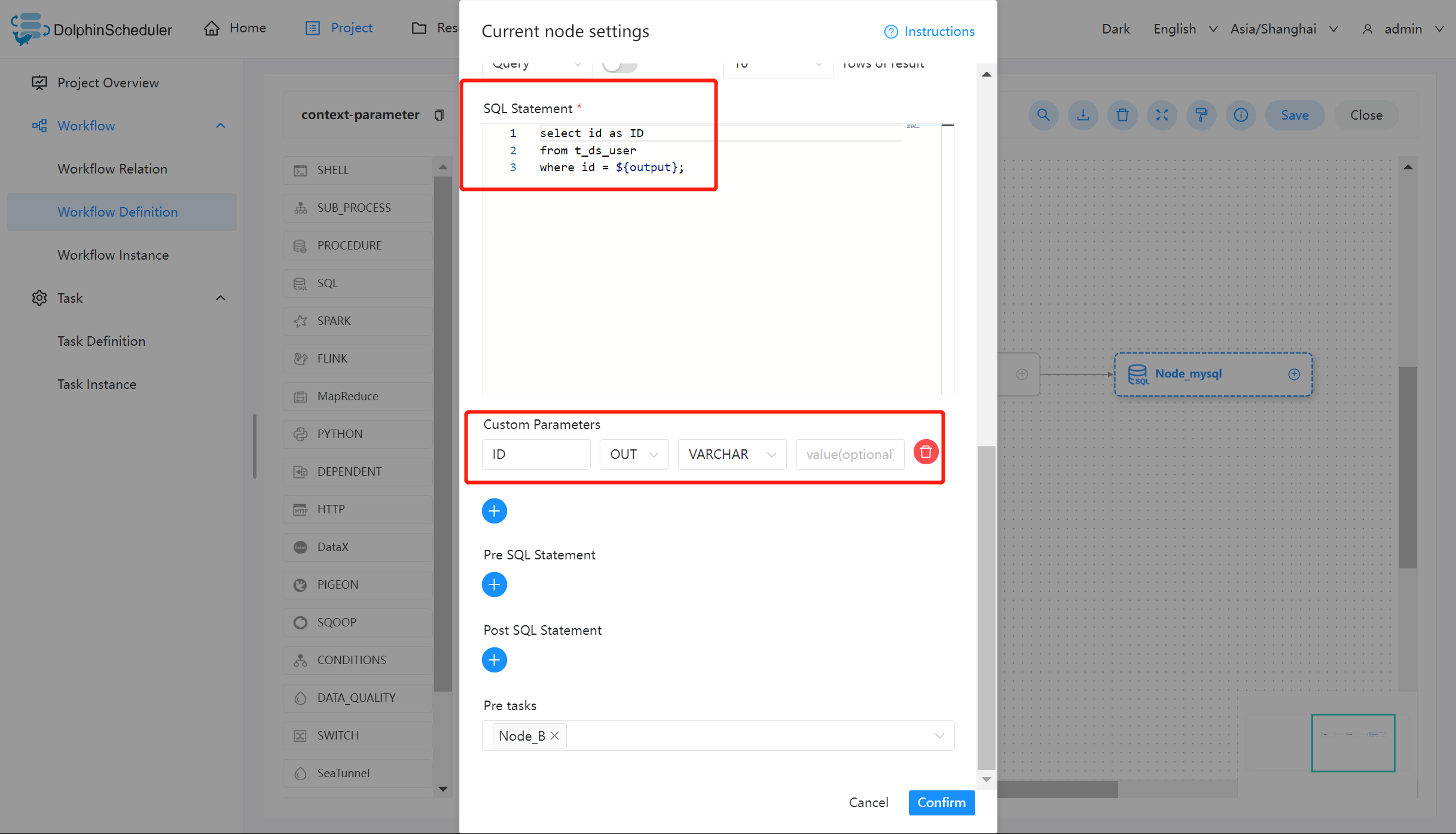
注:如果 SQL 节点的结果只有一行,一个或多个字段,参数的名字需要和字段名称一致。数据类型可选择为除 LIST 以外的其他类型。变量会选择 SQL 查询结果中的列名中与该变量名称相同的列对应的值。
如果 SQL 节点的结果为多行,一个或多个字段,参数的名字需要和字段名称一致。数据类型选择为 LIST。获取到 SQL 查询结果后会将对应列转化为 LIST,并将该结果转化为 JSON 后作为对应变量的值。
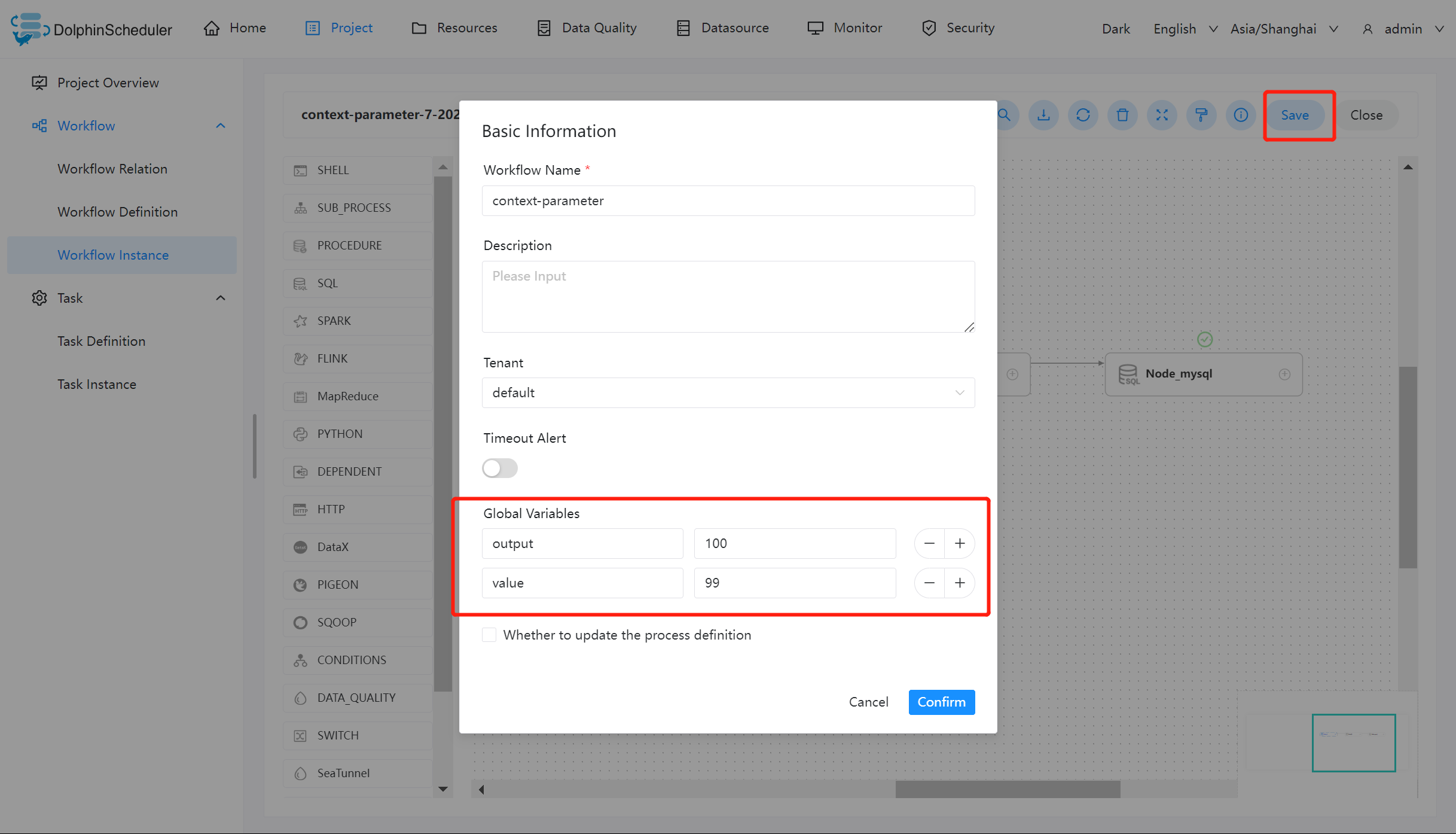
保存工作流并设置全局参数
点击保存工作流图标,并设置全局参数 output 和 value。
查看运行结果
创建完成工作流之后,上线运行该工作流,查看其运行结果。
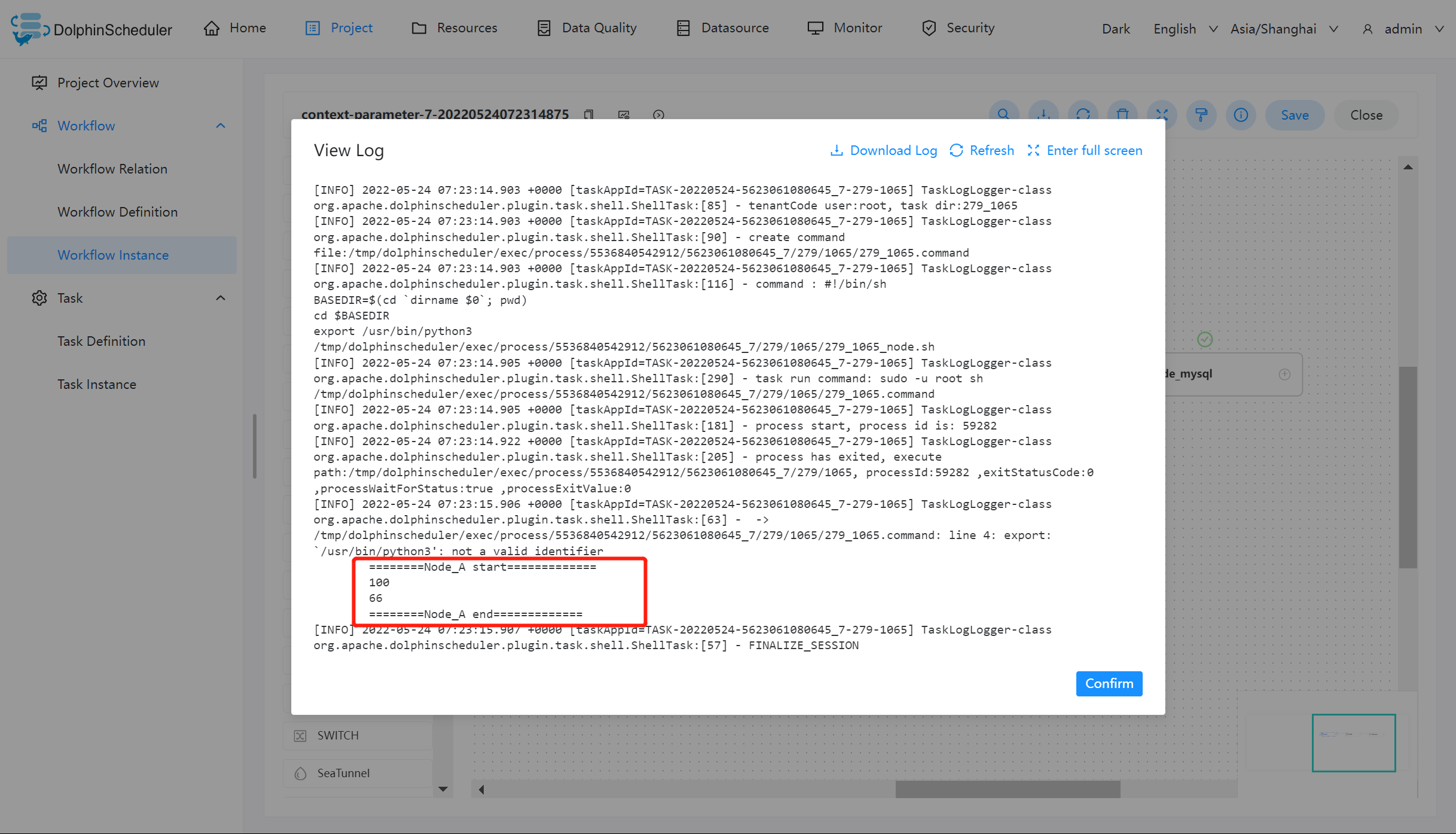
Node_A 运行结果如下:
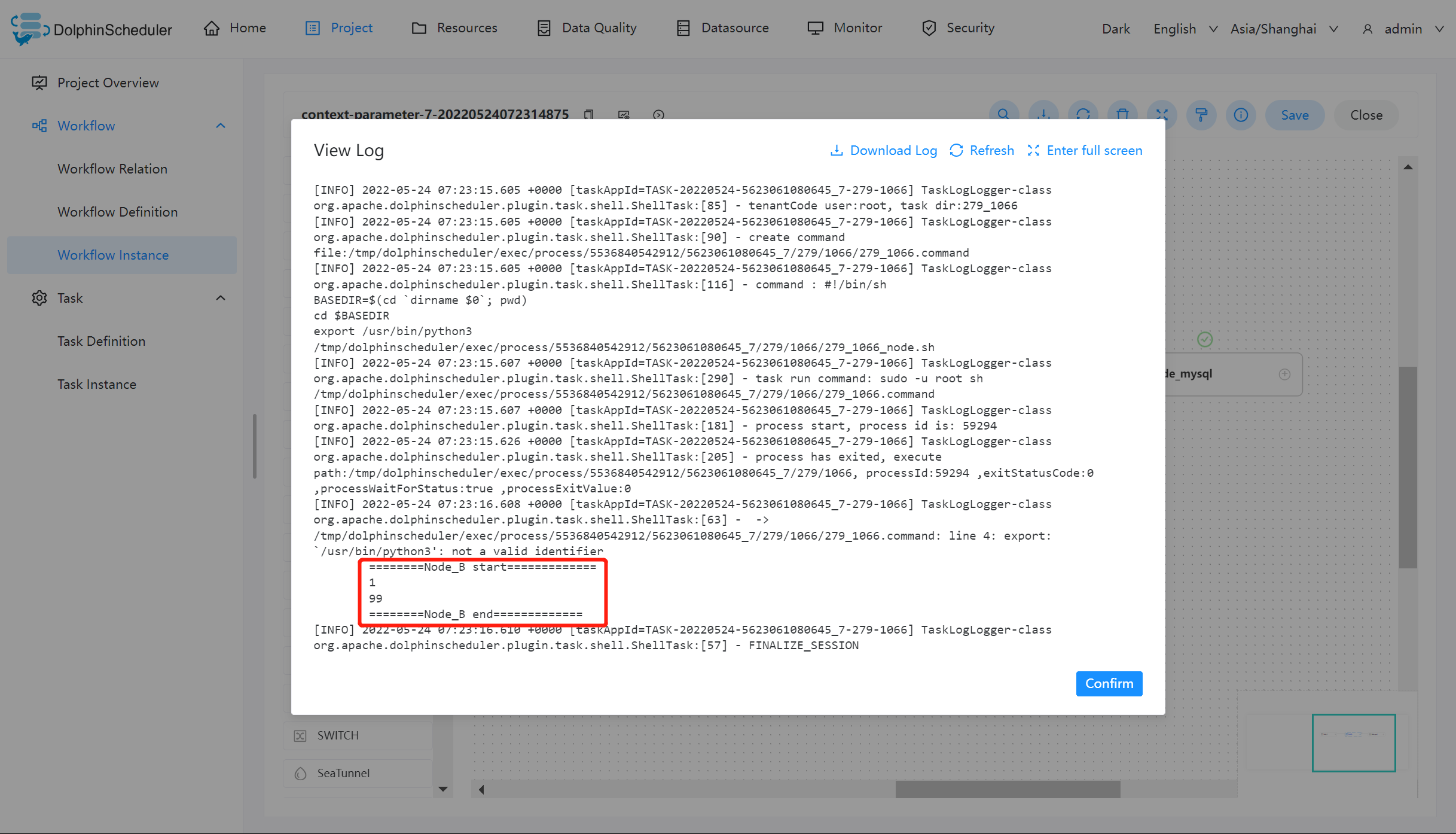
Node_B 运行结果如下:
Node_mysql 运行结果如下:
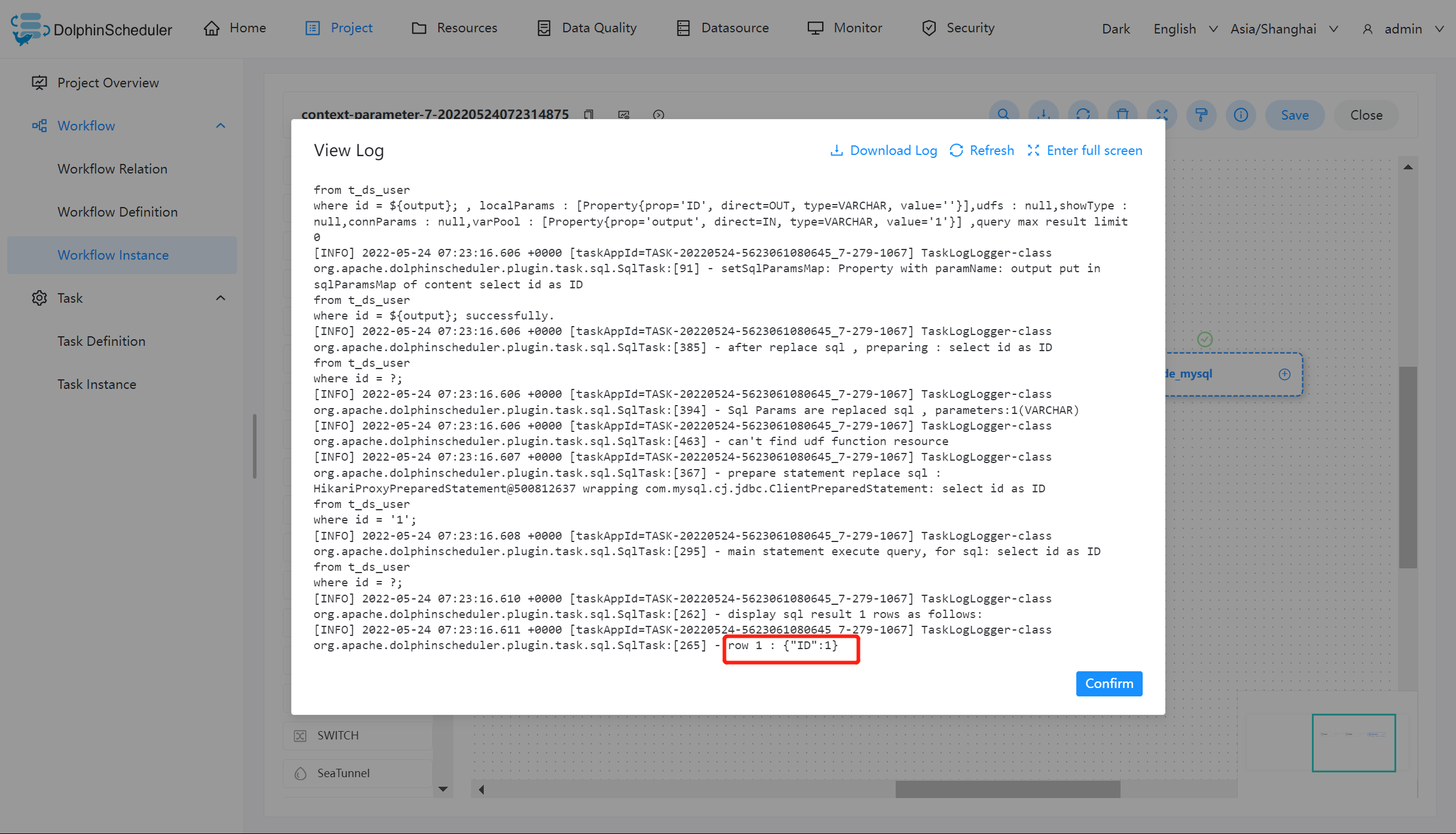
虽然在 Node_A 的脚本中为 output 赋值为 1,但日志中显示的值仍然为 100。但根据参数优先级的原则:本地参数 > 上游任务传递的参数 > 全局参数,在 Node_B 中输出的值为 1。则证明 output 参数参照预期的值在该工作流中传递,并在 Node_mysql 中使用该值完成查询操作。
但是 value 的值却只有在 Node_A 中输出为 66,其原因为 value 的方向选择为 IN,只有当方向为 OUT 时才会被定义为变量输出。
Python 任务传递参数
使用 print('${setValue(key=%s)}' % value),DolphinScheduler会捕捉输出中的 ${setValue(key=value}来进行参数捕捉,从而传递到下游

参数优先级
DolphinScheduler 中所涉及的参数值的定义可能来自三种类型:
- 全局参数:在工作流保存页面定义时定义的变量
- 上游任务传递的参数:上游任务传递过来的参数
- 本地参数:节点的自有变量,用户在“自定义参数”定义的变量,并且用户可以在工作流定义时定义该部分变量的值
因为参数的值存在多个来源,当参数名相同时,就需要会存在参数优先级的问题。DolphinScheduler 参数的优先级从高到低为:本地参数 > 上游任务传递的参数 > 全局参数
在上游任务传递的参数中,由于上游可能存在多个任务向下游传递参数,当上游传递的参数名称相同时:
- 下游节点会优先使用值为非空的参数
- 如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
