
1.认识网络爬虫
-
- 网络爬虫
- 爬虫的合法性
- HTTP协议
- 请求与响应(重点)
网络爬虫
爬虫的全名叫网络爬虫,简称爬虫。他还有其他的名字,比如网络机器人,网络蜘蛛等等。爬虫就好像一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。

你可以这样理解,每个爬虫都是你的分身。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样。
你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后等你来检索。
爬虫的合法性
爬虫本身没有违法这一说法,它只是一种工具,一种技术。
详情请参考 中国网信网发布的网络爬虫的法律规制。
在使用爬虫时候,我们需要谨记三点:
1、 遵守 Robots 协议(君子协议):
robots是搜索引擎爬虫协议,也就是你网站和爬虫的协议。
简单的理解:robots是告诉搜索引擎,你可以爬取收录我的什么页面,你不可以爬取和收录我的那些页面。robots很好的控制网站那些页面可以被爬取,那些页面不可以被爬取。
主流的搜索引擎都会遵守robots协议。并且robots协议是爬虫爬取网站第一个需要爬取的文件。爬虫爬取robots文件后,会读取上面的协议,并准守协议爬取网站,收录网站。
2、不能造成对方服务器瘫痪。
但不是说只要遵守 Robots 协议的爬虫就没有问题,还涉及到两个因素,第一不能大规模爬虫导致对方服务器瘫痪,这等于网络攻击。
3、不能非法获利
恶意利用爬虫技术抓取数据,攫取不正当竞争的优势,甚至是牟取不法利益的,则可能触犯法律。实践中,非法使用爬虫技术抓取数据而产生的纠纷其实数量并不少,大多是以不正当竞争为由提请诉讼。
爬虫为什么选择python:
Python语言具有简单、易学、易读、易维护、用途广泛、速度快、免费、开源等诸多优点。正是因为其中的一些优点让众多程序大佬选择用Python来爬虫:
1、简单易学。Python作为动态语言更适合初学者。Python可以让初学者把精力集中在编程对象和思维方法上,而不用去担心语法、类型等,并且Python语法清晰简洁,调试起来比Java简单的多。
2、稳定。Python的强大架构可以使爬虫程序高效平稳地运行。
3、免费开源。Python是FLOSS(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。
4、速度快。Python的底层是用C语言写的,很多标准库和第三方库也都是用C写的,运行速度非常快。
5、可拓展性。如果需要一段关键代码运行得更快,可以部分程序用C或C++编写,然后在Python程序中使用它们,因此Python适合一些可扩展的后台应用。
6、多线程。爬虫是一个典型的多任务处理场景,请求页面时会有较长的延迟,总体来说更多的是等待。Python多线程或进程会更优化程序效率,提升整个系统下载和分析能力。
HTTP协议
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
工作原理:
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。


请求与响应(重点)
HTTP请求过程
我们在浏览器中输入一个URL,回车之后便会在浏览器中观察到页面内容。实际上,这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器接受到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器。响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来。
'''
请求
请求行 请求方式 (get,post)请求地址(url)-》 协议(http)
请求头 -》 放在服务器上要使用的信息,爬虫需要的重要内容(头部,cookie,)
请求体 -》一般放一些参数(get,post)
响应
状态行 -》协议 状态码 (100)
响应头 -》放在客户端上要使用的信息
响应体 —》返回客户端上的数据(html页面,json数据等)
'''
以淘宝网页版举例:
打开一个网页:

如何鼠标右键,点击检查,或者查看页面源代码,就可以查看页面的源代码。

接着点击网络,然后刷新,点击文档,选择文档
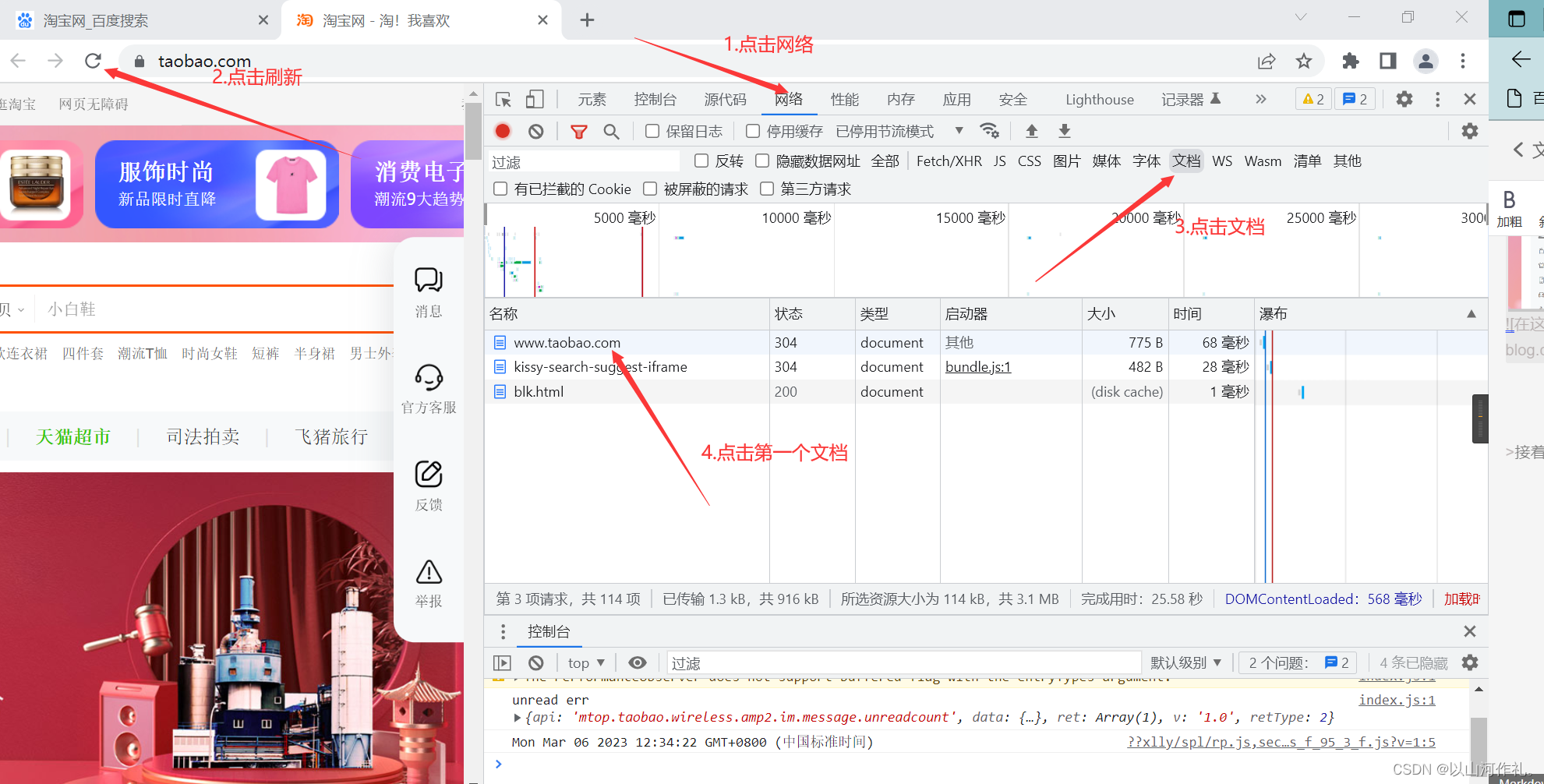
文档名字和链接基本上是相同的。
然后右键点击文档。出现下列数据:

响应体:

状态码:
http爬虫常返回的状态码以及解决方法
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL(永久重定向,重要)
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL(临时重定向,重要)
304:请求的资源未更新 处理方式:丢弃,使用本地缓存文件(没有发送请求,用的是本地缓存文件,重要)
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
405:请求方式不对
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。(服务器问题,代码有问题,重要)
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
cookie与session id
cookie
指某些网站为了辨别用户身份、进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。也就是说如果知道一个用户的Cookie,并且在Cookie有效的时间内,就可以利用Cookie以这个用户的身份登录这个网站。
session id
SessionID 的途:
1、sessionID用来判断是同一次会话,至于会话用来做什么,看需求.
2、session是保存在服务器端的,它有一个生命期,客户端的cookie只是保存了id信息,关闭浏览器时,服务器端的session只要还在同一个生命期内还是同一次会话。
保存SessionID的方式:
1、一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把session id传递回服务器。
2、保存session id的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发送给服务器。
3、由于cookie可以被人为的禁止,必须有其它的机制以便在cookie被禁止时仍然能够session id传递回服务器,经常采用的一种技术叫做 URL重写,就是把session id附加在URL路径的后面,附加的方式也有两种,一种是作为URL路径的附加信息,另一种是作为查询字符串附加在 URL后面。网络在整个交互过程中终保持状态,就必须在每个客户端可能请求的路径后面都包含这个session id。
悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
