
1 Kafka
-
Kafka是一个分布式流式数据平台,它具有三个关键特性
- Message System: Pub-Sub消息系统
- Availability & Reliability:以容错及持久化的方式存储数据记录流
- Scalable & Real time
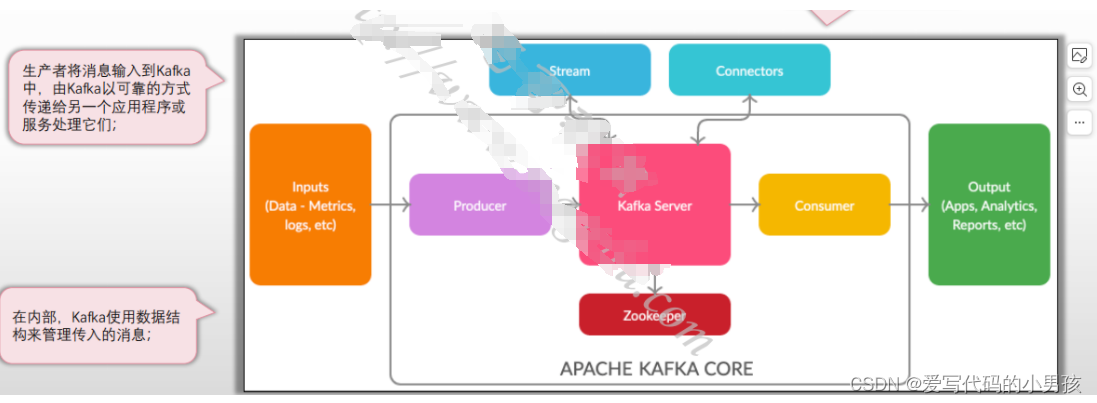
1.1 Kafka架构体系
-
Kafka系统中存在5个关键组件
- Producer
- Consume
- Kafka Cluster
- Broker:Kafka Server,或Kafka Node
- Zookeeper: 集群状态存储
- Connector:连接应用程序和Topic
- Stream Processor:流处理器,从一个Topic接收并处理流式数据,并将结果存入另一个Topic
-
还有两个重要逻辑组件
- Topic
- Partition
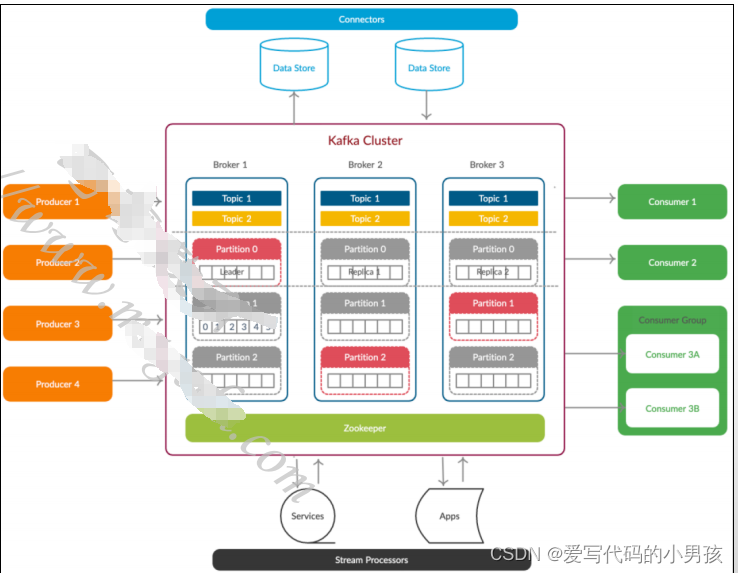
1.2 Topic和Partition
-
关于Topic和Partition
-
Topic分类的消息流,相关的消息保存于Partition中
- 一个Topic中的数据,可以分布保存于一至多个Partition中
- 每个Partition中,通常存在一个leader,以及一至多个replicas/followers
-
Topic是Producer发布消息,以及consumer消费消息使用的端点
-
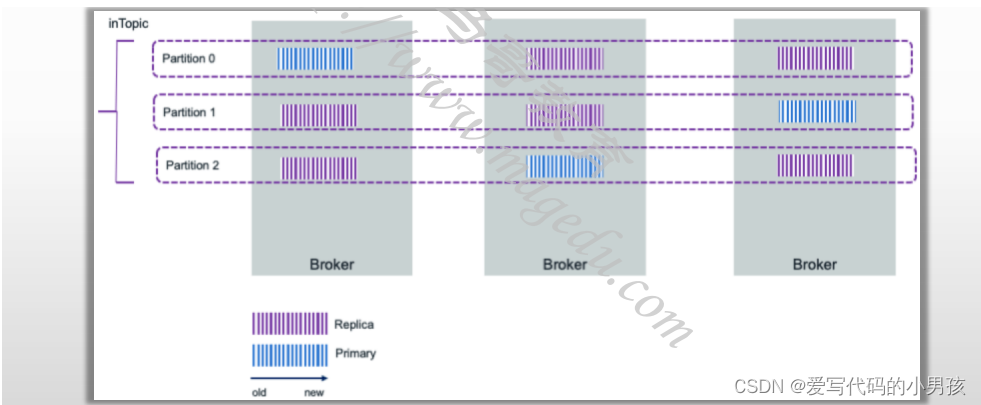
1.3 Topic中的消息记录
-
消息及存储方式
- Kafka中,每个消息记录(record)的标准格式通常由key、value、timestamp和一些metadata组成;
- 待存入Topic的消息记录未明确指定目标Partition时,Kafka会根据记录的key的hash码选择一个Partition;未明确指定timestamp时,Producer将会使用当前时间(创建时间或附加到日志的时间)作为其时间戳;
- Kafka将数据持久存储在log.dir参数指定 的目录中,而各topic会映射进该目录的子目录中;
- Kafka会保留所有记录,无论它们是否已被消费
- 记录在服务器托管网broker配置中定义的retention period内保留,默认时长为7天(168小时)
- Kafka基于Pub/Sub和Queue模型构建Topic,它使用消费者组(Consumer Group)的概念将处理任务划分为一组消费者进程并行运行,并且可以将消息广播到多个组中;
1.4 Partition
-
Partition代表Topic中的数据分片,在其它数据库系统中,通常称为replica或shard
- 每个Partition都是一个按时间排序的不可变记录序列,该序列存储于日志中;
- 消费者按照记录在日志中的存储顺序读取消息;
- 每个消息都有一个称为offset的id
-
能够将一个Topic中的数据并行存储于多个broker上;
-
支持以冗余机制(复制因子大于1)存储多个副本,并能容忍最多N-1个服务器故障,N为复制
因子数量;
-
消费者读取一个Topic时,它将从所有Partition中读取数据
服务器托管,北京服务器托管,服务器租用 http://www.fw服务器托管网qtg.net
引言 组合模式是一种结构型设计模式,你可以使用它将对象组合成树状结构,并且能像使用独立对象一样使用它们。 问题 如果应用的核心模型能用树状结构表示,在应用中使用组合模式才有价值。 例如,你有两类对象:产品和盒子。一个盒子中可以包含多个产品或者几个较小的盒子。…
