


10月30日,昆仑万维集团正式发布国内首个全面开源最强百亿级模型Skywork-13B系列。昆仑万维集团的此次同时推出两款天工130亿参数的开源模型,可谓是业内开源最彻底的百亿高质量商用模型:除了开源模型和开源训练数据外,同时支持无需要申请即可商用。
Skywork-13B系列的开源将为大模型的场景应用和社区开源的蓬勃发展提供最佳的技术支持。昆仑万维的算法和模型等开源项目将使得各行业的研究人员和企业的工作达到事半功倍的效果,同时为社会各界对大模型技术的商业落地提供了最诚意的支持。
此次开源的130亿参数模型提供两个版本的大模型:Skywork-13B-Base模型、Skywork-13B-Math模型,以及每个模型的量化版模型,以支持用户在消费级显卡进行部署和推理。
Skywork开源项目的特点有:
Skywork-13B-Base模型
Skywork-13B-Base模型是在经过高质量清洗过滤的3.2万亿个多语言(主要是中文和英文)和代码数据上进行训练的,它在多种评测和各种基准测试上都展现了同等规模模型的最佳效果。
Skywork-13B-Math模型
Skywork-13B-Math服务器托管网模型经过专门的数学能力强化训练,在13B规模中,Skywork-13B-Math模型在GSM8K评测上得分第一,同时 MATH数据集上表现也很好,在 out-of-domain 数据集 CMATH上表现也很优秀,处于13B模型顶尖水平。
Skypile-150B数据集
该数据集是根据我们经过精心过滤的数据处理流程从中文网页中筛选出的高质量数据。本次开源的数据集大小约为600GB,总的token数量约为150B,目前开源最大的中文数据集之一。
除此之外,我们还公开了在训练Skywork-13B模型中使用的评估方法、数据配比研究和训练基础设施调优方案等。我们希望这些开源内容能够进一步启发社区对于大型模型预训练的认知,并推动人工智能通用智能(AGI)的实现。
高质量中文数据集在Huggingface即可下载,详情请见Github官方空间⬇️
Skywork-13B下载地址(Github):
https://github.com/Sky服务器托管网workAI/Skywork
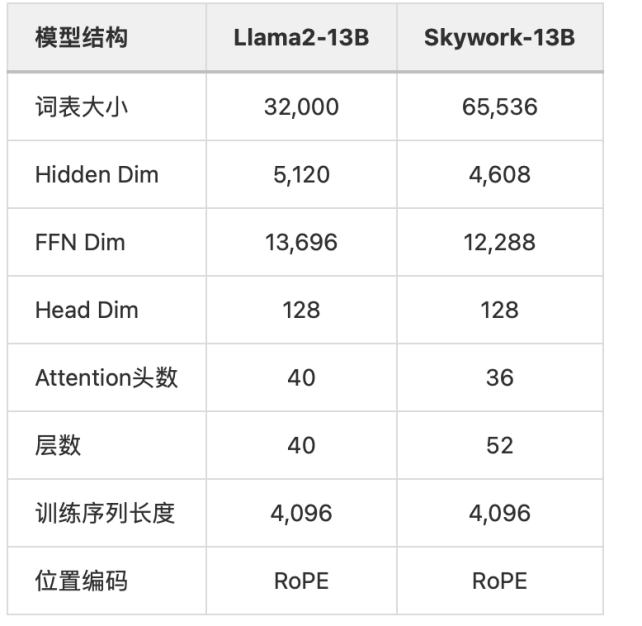
模型结构
与LLaMA2-13B模型对比,天工Skywork-13B模型采用相对更加瘦长的网络结构,层数为52层,同时将FFN Dim和Hidden Dim缩小到12288和4608,从而保证模型参数量和原始LLaMA-13B模型相当。根据我们前期实验对比,相对瘦长的网络结构在大Batch Size训练下可以取得更好的泛化效果。Skywork-13B和LLaMA-2-13B模型的对比如下:
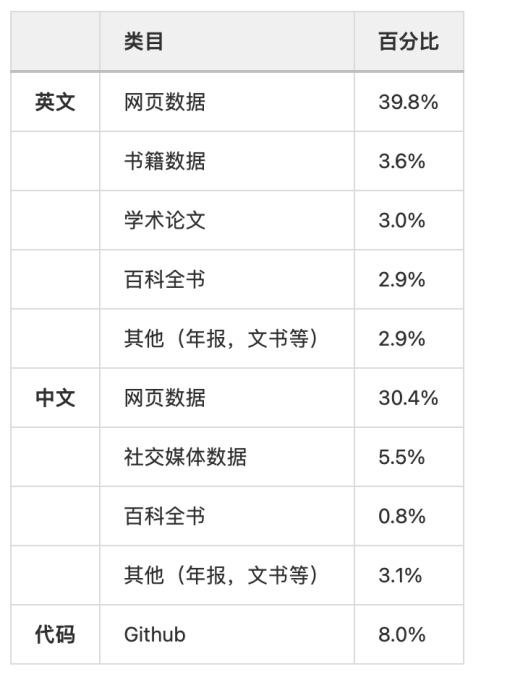
训练数据
英文网页数据 39.8% 书籍数据 3.6% 学术论文 3.0% 百科全书 2.9% 其他(年报,文书等) 2.9%中文网页数据 30.4% 社交媒体数据 5.5% 百科全书 0.8% 其他(年报,文书等) 3.1%代码Github 8.0%
训练方法:
此次 Skywork-13B 开源系列模型同时开放了整个模型的训练方法。为了更加精细化利用数据,采用两阶段训练方法,第一阶段使用通用语料进行模型通用能力学习,第二部分加入STEM(科学,技术,工程,数学)相关数据进一步增强模型的推理能力、数学能力、问题解决能力。(详细信息,参考开源社区下载文档)
模型评估
- 领域数据困惑度评估
语言模型训练的本质上是让预测下一个词更准确。基于这个认知,我们认为评估基础大模型一个重要的方式是评估在各大领域上语言模型生成文章的概率。在模型训练中预测下一个词的概率一般使用Cross Entropy损失函数,整体的损失函数为每个位置预测真实词损失的平均,则有:
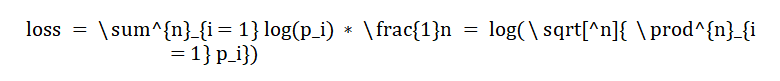
其中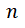 是文档的长度,即token数,
是文档的长度,即token数,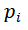 是位置i上真实词的概率,我们知道文档中每一个位置上真实词的概率的联乘则为生成该文档的概率,如此我们就将loss和生成文章的概率联系在了一起。而不同模型因为使用的分词器不同,具有不同的token数,因此对损失函数乘以token数目
是位置i上真实词的概率,我们知道文档中每一个位置上真实词的概率的联乘则为生成该文档的概率,如此我们就将loss和生成文章的概率联系在了一起。而不同模型因为使用的分词器不同,具有不同的token数,因此对损失函数乘以token数目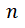 ,这样就仅考虑生成文章的概率部分,不同模型也可以进行比较。我们将标准化后loss取指数转换成perplexity,使得模型的差异更加可读。为了阅读方面后续提到的loss和ppl为模型标准化后的loss和perplexity。
,这样就仅考虑生成文章的概率部分,不同模型也可以进行比较。我们将标准化后loss取指数转换成perplexity,使得模型的差异更加可读。为了阅读方面后续提到的loss和ppl为模型标准化后的loss和perplexity。
基于上述分析,我们对多个领域筛选出2023年10月份新发布的几百到上千篇高质量文章,并人工进行了核对。保证所有的测试数据不在天工模型以及其他所有模型的训练集中,并且测试数据的来源也足够广泛,质量也高。我们可以选取当前最新的文章评测不同模型的ppl,模型很难作弊。下图列出了不同开源模型,天工Skywork-13B-Base取得最优效果,证明了天工Base模型的基础能力处于国内开源模型中文最强水平。

- Benchmark评估
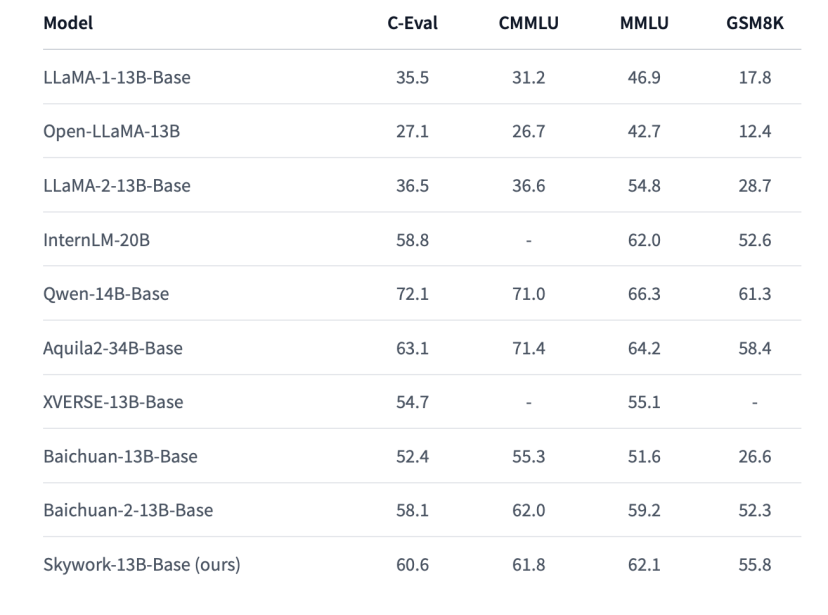
我们评估了各大权威评测benchmark上的结果作为参考,包括C-Eval,MMLU,CMMLU,GSM8K。遵循之前的评估流程,C-Eval、MMLU、CMMLU测试5-shot结果,GSM8K测试8-shot结果。可以看到Skywork-13B-Base模型在中文开源模型中处于前列,在同等参数规模下为最优水平。
最有诚意的支持开源商用:无需申请,即可实现商用
目前开源社区中的中文大模型多数并非是完全可商用, 一般开源社区用户通常需要进行复杂的商用授权申请流程, 在某些情况, 甚至有对公司规模、所在行业、用户数等维度有明确规定不给予商业授权。昆仑万维对Skywork-13B开源的开放性和可商用性高度重视,将授权流程做到极简,取消对行业、公司规模、用户等方面的限制, 目的是帮助更多对中文大模型感兴趣的用户和企业在行业中不断探索和进步。因此,此次Skywork-13B开源的同时我们将全面开放Skywork-13B大模型的商用许可,用户在下载模型后同意并遵守《Skywork模型社区许可协议》后, 无需再次申请授权即可将大模型进行商业用途, 目的是希望用户能够更便捷的去利用Skywork-13B去进行测试并且探索在不同场景下的商业化应用。

注册开放平台 了解更多13B产品信息
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
#include “STC12C5A60S2.H” //run sbit left_go=P2^1; sbit left_xia=P2^2; sbit right_go=P2^4; sbit right_xia=P2^3; sbit Left_motor_pw…
