
事务的基本原理
在学习 Spring 的事务之前,你首先要了解数据库的事务原理,我们以 MySQL 5.7 为例,讲解一下数据库事务的基础知识。
我们都知道 当 MySQL 使用 InnoDB 数据库引擎的时候,数据库是对事务有支持的。而事务最主要的作用是保证数据 ACID 的特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),下面来一一解释。
原子性: 是指一个事务(Transaction)中的所有操作,要么全部完成,要么全部回滚,而不会有中间某个数据单独更新的操作。事务在执行过程中一旦发生错误,会被回滚(Rollback)到此次事务开始之前的状态,就像这个事务从来没有执行过一样。
一致性: 是指事务操作开始之前,和操作异常回滚以后,数据库的完整性没有被破坏。数据库事务 Commit 之后,数据也是按照我们预期正确执行的。即要通过事务保证数据的正确性。
持久性: 是指事务处理结束后,对数据的修改进行了持久化的永久保存,即便系统故障也不会丢失,其实就是保存到硬盘。
隔离性: 是指数据库允许多个连接,同时并发多个事务,又对同一个数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时,由于交叉执行而导致数据不一致的现象。而 MySQL 里面就是我们经常说的事务的四种隔离级别,即读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
由于隔离级别是事务知识点中最基础的部分,我们就简单介绍一下四种隔离级别。但是它特别重要,你要好好掌握。
四种 MySQL 事务的隔离级别
Read Uncommitted(读取未提交内容):此隔离级别,表示所有正在进行的事务都可以看到其他未提交事务的执行结果。不同的事务之间读取到其他事务中未提交的数据,通常这种情况也被称之为脏读(Dirty Read),会造成数据的逻辑处理错误,也就是我们在多线程里面经常说的数据不安全了。在业务开发中,几乎很少见到使用的,因为它的性能也不比其他级别要好多少。
Read Committed(读取提交内容): 此隔离级别是指,在一个事务相同的两次查询可能产生的结果会不一样,也就是第二次查询能读取到其他事务已经提交的最新数据。也就是我们常说的不可重复读(Nonrepeatable Read)的事务隔离级别。因为同一事务的其他实例在该实例处理期间,可能会对其他事务进行新的 commit,所以在同一个事务中的同一 select 上,多次执行可能返回不同结果。这是大多数数据库系统的默认隔离级别(但不是 MySQL 默认的隔离级别)。
Repeatable Read(可重读): 这是 MySQL 的默认事务隔离级别,它确保同一个事务多次查询相同的数据,能读到相同的数据。即使多个事务的修改已经 commit,本事务如果没有结束,永远读到的是相同数据,要注意它与Read Committed 的隔离级别的区别,是正好相反的。这会导致另一个棘手的问题:幻读 (Phantom Read),即读到的数据可能不是最新的。这个是最常见的,我们举个例子来说明。
第一步:用工具打开一个数据库的 DB 连接,如图所示。

查看一下数据库的事务隔离级别。

然后开启一个事务,查看一下 user_info 的数据,我们在 user_info 表里面插入了三条数据,如下图所示。

第二步:我们打开另外一个相同数据库的 DB 连接,删除一条数据,SQL 如下所示。

当删除执行成功之后,我们可以开启第三个连接,看一下数据库里面确实少了一条 ID=1 的数据。那么这个时候我们再返回第一个连接,第二次执行 select * from user_info,如下图所示,查到的还是三条数据。这就是我们经常说的可重复读。

Serializable(可串行化):这是最高的隔离级别,它保证了每个事务是串行执行的,即强制事务排序,所有事务之间不可能产生冲突,从而解决幻读问题。如果配置在这个级别的事务,处理时间比较长,并发比较大的时候,就会导致大量的 db 连接超时现象和锁竞争,从而降低了数据处理的吞吐量。也就是这个性能比较低,所以除了某些财务系统之外,用的人不是特别多。
数据库的隔离级别我们了解完了,并不复杂,这四种类型中,你能清楚地知道Read Uncommitted 和 Read Committed就可以了,一般这两个用得是最多的。
下面看一下数据的事务和连接是什么关系呢?
MySQL 事务与连接的关系
我们要搞清楚事务和连接池的关系,必须要先知道二者存在的前提条件。
- 事务必须在同一个连接里面的,离开连接没有事务可言;
- MySQL 数据库默认 autocommit=1,即每一条 SQL 执行完自动提交事务;
- 数据库里面的每一条 SQL 执行的时候必须有事务环境;
- MySQL 创建连接的时候默认开启事务,关闭连接的时候如果存在事务没有 commit 的情况,则自动执行 rollback 操作;
- 不同的 connect 之间的事务是相互隔离的。
知道了这些条件,我们就可以继续探索二者的关系了。在 connection 当中,操作事务的方式只有两种。
MySQL 事务的两种操作方式
第一种:用 BEGIN、ROLLBACK、COMMIT 来实现。
- BEGIN开始一个事务
- ROLLBACK事务回滚
- COMMIT事务确认
第二种:直接用 SET 来改变 MySQL 的自动提交模式。
- SET AUTOCOMMIT=0禁止自动提交
- SET AUTOCOMMIT=1开启自动提交
MySQL 数据库的最大连接数是什么?
而任何数据库的连接数都是有限的,受内存和 CPU 限制,你可以通过
show variables like ‘max_connections’ 查看此数据库的最大连接数、通过 show global status like ‘Max_used_connections’ 查看正在使用的连接数,还可以通过 set global max_connections=1500 来设置数据库的最大连接数。
除此之外,你可以在观察数据库的连接数的同时,通过观察 CPU 和内存的使用,来判断你自己的数据库中 server 的连接数最佳大小是多少。而既然是连接,那么肯定会有超时时间,默认是 8 小时。
这里我只是列举了 MySQL 数据库的事务处理原理,你可以用相同的思考方式看一下你在用的数据源的事务是什么机制的。
那么学习完了数据库事务的基础知识,我们再看一下 Spring 中事务的用法和配置是什么样的。
Spring 里面事务的配置方法
由于我们使用的是 Spring Boot,所以会通过 TransactionAutoConfiguration.java 加载 @EnableTransactionManagement 注解帮我们默认开启事务,关键代码如下图所示。

Spring 里面的事务有两种使用方式,常见的是直接通过 @Transaction 的方式进行配置,而我们打开 SimpleJpaRepository 源码类的话,会看到如下代码。
复制代码
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository implements JpaRepositoryImplementation {
...
@Transactional
@Override
public void deleteAll(Iterable extends T> entities) {
.....
我们仔细看源码的时候就会发现,默认情况下,所有 SimpleJpaRepository 里面的方法都是只读事务,而一些更新的方法都是读写事务。
所以每个 Respository 的方法是都是有事务的,即使我们没有使用任何加 @Transactional 注解的方法,按照上面所讲的 MySQL 的 Transactional 开启原理,也会有数据库的事务。那么我们就来看下 @Transactional 的具体用法。
默认 @Transactional 注解式事务
注解式事务又称显式事务,需要手动显式注解声明,那么我们看看如何使用。
按照惯例,我们打开 @Transactional 的源码,如下所示。
复制代码
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
@AliasFor("transactionManager")
String value() default "";
@AliasFor("value")
String transactionManager() default "";
Propagation propagation() default Propagation.REQUIRED;
Isolation isolation() default Isolation.DEFAULT;
int timeout() default TransactionDefinition.TIMEOUT_DEFAULT;
boolean readOnly() default false;
Class extends Throwable>[] rollbackFor() default {};
String[] rollbackForClassName() default {};
Class extends Throwable>[] noRollbackFor() default {};
String[] noRollbackForClassName() default {};
}
针对 @Transactional 注解中常用的参数,我列了一个表格方便你查看。

其他属性你基本上都可以知道是什么意思,下面重点说一下隔离级别和事务的传播机制。
隔离级别 Isolation isolation() default Isolation.DEFAULT:默认采用数据库的事务隔离级别。其中,Isolation 是个枚举值,基本和我们上面讲解的数据库隔离级别是一样的,如下图所示。

propagation:代表的是事务的传播机制,这个是 Spring 事务的核心业务逻辑,是 Spring 框架独有的,它和 MySQL 数据库没有一点关系。所谓事务的传播行为是指在同一线程中,在开始当前事务之前,需要判断一下当前线程中是否有另外一个事务存在,如果存在,提供了七个选项来指定当前事务的发生行为。我们可以看 org.springframework.transaction.annotation.Propagation 这类的枚举值来确定有哪些传播行为。7 个表示传播行为的枚举值如下所示。
复制代码
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
}
- REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这个值是默认的。
- SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
- NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 REQUIRED。
设置方法:通过使用 propagation 属性设置,例如下面这行代码。
复制代码
@Transactional(propagation = Propagation.REQUIRES_NEW)
虽然用法很简单,但是也有使用 @Transactional 不生效的时候,那么在哪些场景中是不可用的呢?
@Transactional 的局限性
这里列举的是一个当前对象调用对象自己里面的方法不起作用的场景。
我们在 UserInfoServiceImpl 的 save 方法中调用了带事务的 calculate 方法,代码如下。
复制代码
@Component
public class UserInfoServiceImpl implements UserInfoService {
@Autowired
private UserInfoRepository userInfoRepository;
/**
* 根据UserId产生的一些业务计算逻辑
*/
@Override
@Transactional(transactionManager = "db2TransactionManager")
public UserInfo calculate(Long userId) {
UserInfo userInfo = userInfoRepository.findById(userId).get();
userInfo.setAges(userInfo.getAges()+1);
//.....等等一些复杂事务内的操作
userInfo.setTelephone(Instant.now().toString());
return userInfoRepository.saveAndFlush(userInfo);
}
/**
* 此方法调用自身对象的方法,就会发现calculate方法上面的事务是失效的
*/
public UserInfo save(Long userId) {
return this.calculate(userId);
}
}
当在 UserInfoServiceImpl 类的外部调用 save 方法的时候,此时 save 方法里面调用了自身的 calculate 方法,你就会发现 calculate 方法上面的事务是没有效果的,这个是 Spring 的代理机制的问题。那么我们应该如何解决这个问题呢?可以引入一个类 TransactionTemplate,我们看下它的用法。
TransactionTemplate 的用法
此类是通过 TransactionAutoConfiguration 加载配置进去的,如下图所示。

我们通过源码可以看到此类提供了一个关键 execute 方法,如下图所示。

这里面会帮我们处理事务开始、rollback、commit 的逻辑,所以我们用的时候就非常简单,把上面的方法做如下改动。
复制代码
public UserInfo save(Long userId) {
return transactionTemplate.execute(status -> this.calculate(userId));
}
此时外部再调用我们的 save 方法的时候,calculate 就会进入事务管理里面去了。当然了,我这里举的例子很简单,你也可以通过下面代码中的方法设置隔离级别和传播机制,以及超时时间和是否只读。
复制代码
transactionTemplate = new TransactionTemplate(transactionManager);
//设置隔离级别
transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_REPEATABLE_READ);
//设置传播机制
transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
//设置超时时间
transactionTemplate.setTimeout(1000);
//设置是否只读
transactionTemplate.setReadOnly(true);
我们也可以根据 transactionTemplate 的实现原理,自己实现一个 TransactionHelper,一起来看一下。
自定义 TransactionHelper
第一步:新建一个 TransactionHelper 类,进行事务管理,代码如下。
复制代码
/**
* 利用spring进行管理
*/
@Component
public class TransactionHelper {
/**
* 利用spring 的机制和jdk8的function机制实现事务
*/
@Transactional(rollbackFor = Exception.class) //可以根据实际业务情况,指定明确的回滚异常
public R transactional(Function function, T t) {
return function.apply(t);
}
}
第二步:直接在 service 中就可以使用了,代码如下。
复制代码
@Autowired
private TransactionHelper transactionHelper;==
/**
* 调用外部的transactionHelper类,利用transactionHelper方法上面的@Transaction注解使事务生效
服务器托管网 */
public UserInfo save(Long userId) {
return transactionHelper.transactional((uid)->this.calculate(uid),userId);
}
上面我介绍了显式事务,都是围绕 @Transactional 的显式指定的事务,我们也可以利用 AspectJ 进行隐式的事务配置。
隐式事务 / AspectJ 事务配置
只需要在我们的项目中新增一个类 AspectjTransactionConfig 即可,代码如下。
复制代码
@Configuration
@EnableTransactionManagement
public class AspectjTransactionConfig {
public static final String transactionExecution = "execution (* com.example..service.*.*(..))";//指定拦截器作用的包路径
@Autowired
private PlatformTransactionManager transactionManager;
@Bean
public DefaultPointcutAdvisor defaultPointcutAdvisor() {
//指定一般要拦截哪些类
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression(transactionExecution);
//配置advisor
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor();
advisor.setPointcut(pointcut);
//根据正则表达式,指定上面的包路径里面的方法的事务策略
Properties attributes = new Properties();
attributes.setProperty("get*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("add*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("save*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("update*", "PROPAGATION_REQUIRED,-Exception");
attributes.setProperty("delete*", "PROPAGATION_REQUIRED,-Exception");
//创建Interceptor
TransactionInterceptor txAdvice = new TransactionInterceptor(transactionManager, attributes);
advisor.setAdvice(txAdvice);
return advisor;
}
}
这种方式,只要符合我们上面的正则表达规则的 service 方法,就会自动添加事务了;如果我们在方法上添加 @Transactional,也可以覆盖上面的默认规则。
不过这种方法近两年使用的团队越来越少了,因为注解的方式其实很方便,并且注解 @Transactional 的方式更容易让人理解,代码也更简单,你了解一下就好了。
上面的方法介绍完了,那么一个方法经历的 SQL 和过程都有哪些呢?我们通过日志分析一下。
通过日志分析配置方法的过程
大致可以分为以下几个步骤。
第一步,我们在数据连接中加上 logger=Slf4JLogger&profileSQL=true,用来显示 MySQL 执行的 SQL 日志,如图所示。

第二步,打开 Spring 的事务处理日志,用来观察事务的执行过程,代码如下。
复制代码
# Log Transactions Details
logging.level.org.springframework.orm.jpa=DEBUG
logging.level.org.springframework.transaction=TRACE
logging.level.org.hibernate.engine.transaction.internal.TransactionImpl=DEBUG
# 监控连接的情况
logging.level.org.hibernate.resource.jdbc=trace
logging.level.com.zaxxer.hikari=DEBUG
第三步,我们执行一个 saveOrUpdate 的操作,详细的执行日志如下所示。

通过日志可以发现,我们执行一个 saveUserInfo 的动作,由于在其中配置了一个事务,所以可以看到 JpaTransactionManager 获得事务的过程,图上黄色的部分是同一个连接里面执行的 SQL 语句,其执行的整体过程如下所示。
- get connection:从事务管理里面,获得连接就 begin 开始事务了。我们没有看到显示的 begin 的 SQL,基本上可以断定它利用了 MySQL 的 connection 初始化事务的特性。
- set autocommit=0:关闭自动提交模式,这个时候必须要在程序里面 commit 或者 rollback。
- select user_info:看看 user_info 数据库里面是否存在我们要保存的数据。
- update user_info:发现数据库里面存在,执行更新操作。
- commit:执行提交事务。
- set autocommit=1:事务执行完,改回 autocommit 的默认值,每条 SQL 是独立的事务。
我们这里采用的是数据库默认的隔离级别,如果我们通过下面这行代码,改变默认隔离级别的话,再观察我们的日志。
复制代码
@Transactional(isolation = Isolation.READ_COMMITTED)
你会发现在开始事务之前,它会先改变默认的事务隔离级别,如图所示。

而在事务结束之后,它还会还原此链接的事务隔离级别,又如下图所示。

如果你明白了 MySQL 的事务原理的话,再通过日志分析可以很容易地理解 Spring 的事务原理。我们在日志里面能看到 MySQL 的事务执行过程,同样也能看到 Spring 的 TransactionImpl 的事务执行过程。这是什么原理呢?我们来详细分析一下。
Spring 事务的实现原理
这里我重点介绍一下 @Transactional 的工作机制,这个主要是利用 Spring 的 AOP 原理,在加载所有类的时候,容器就会知道某些类需要对应地进行哪些 Interceptor 的处理。
例如我们所讲的 TransactionInterceptor,在启动的时候是怎么设置事务的、是什么样的处理机制,默认的代理机制又是什么样的呢?
Spring 事务源码分析
我们在 TransactionManagementConfigurationSelector 里面设置一个断点,就会知道代理的加载类 ProxyTransactionManagementConfiguration 对事务的处理机制。关键源码如下图所示。

而我们打开 ProxyTransactionManagementConfiguration 的话,就会加载 TransactionInterceptor 的处理类,关键源码如下图所示。
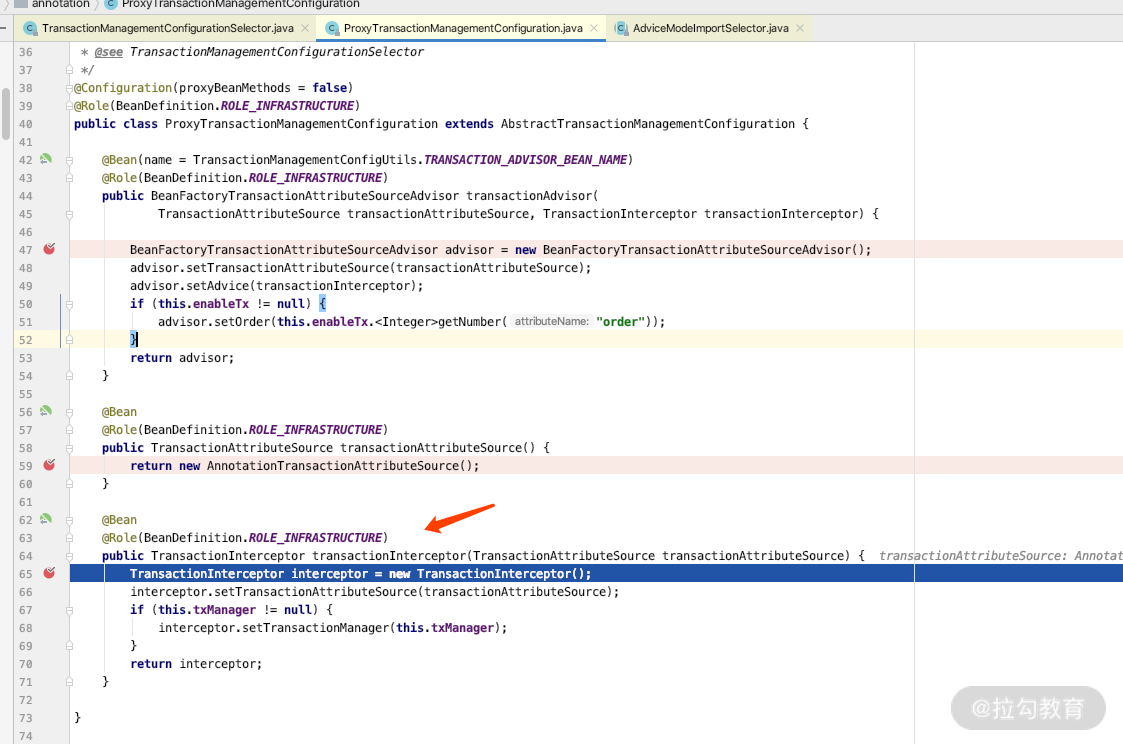
如果继续加载的话,里面就会加载带有 @Transactional 注解的类或者方法。关键源码如下图所示。

加载期间,通过 @Trnsactional 注解来确定哪些方法需要进行事务处理。
复制代码
o.s.orm.jpa.JpaTransactionManager : Creating new transaction with name
而运行期间通过上面这条日志,就可以找到 JpaTransactionManager 里面通过 getTransaction 方法创建的事务,然后再通过 debuger 模式的 IDEA 线程栈进行分析,就能知道创建事务的整个过程。你可以一步一步地去断点进行查看,如下图所示。

如上图,我们可以知道 createTransactionIfNecessary 是用来判断是否需要创建事务的,有兴趣的话你可以点击进去看看,如下图所示。

我们继续往下面 debug 的话,就会找到创建事务的关键代码,它会通过调用 AbstractPlatformTransactionManager 里面的 startTransaction 方法开启事务,如下图所示。

然后我们就可以继续往下断点进行分析了。断点走到最后的时候,你就可以看到开启事务的时候,必须要从我们的数据源里面获得连接。看一下断点的栈信息,这里有几个关键的 debug 点。如下图所示。

其中,
第一处:是处理带 @Transactional 的注解的方法,利用 CGLIB 进行事务拦截处理;
第二处:是根据 Spring 的事务传播机制,来判断是用现有的事务,还是创建新的事务;
第七处:是用来判断是否现有连接,如果有直接用,如果没有就从第八处的数据源里面的连接池中获取连接,第七处的关键代码如下。

到这里,我们介绍完了事务获得连接的关键时机,那么还需要知道它是在什么时间释放连接到连接池里面的。我们在 LogicalConnectionManagedImpl 的 releaseConnection 方法中设置一个断点,如下图所示。

然后观察断点线性的执行方法,你会发现,在事务执行之后,它会将连接释放到连接池里面。
我们通过上面的 saveOrUpdate 的详细执行日志,可以观察出来,事务是在什么时机开启的、数据库连接是什么时机开启的、事务是在什么时机关闭的,以及数据库连接是在什么时机释放的,如果你没服务器托管网看出来,可以再仔细看一遍日志。
所以,Spring 中的事务和连接的关系是,开启事务的同时获取 DB 连接;事务完成的时候释放 DB 连接。通过 MySQL 的基础知识可以知道数据库连接是有限的,那么当我们给某些方法加事务的时候,都需要注意哪些内容呢?
事务和连接池在 JPA 中的注意事项
我们在“17 | DataSource 为何物?加载过程是怎样的?”中对数据源的介绍时,说过数据源的连接池不能配置过大,否则连接之前切换就会非常耗费应用内部的 CPU 和内存,从而降低应用对外提供 API 的吞吐量。
所以当我们使用事务的时候,需要注意如下 几个事项:
- 事务内的逻辑不能执行时间太长,否则就会导致占用 db 连接的时间过长,会造成数据库连接不够用的情况;
- 跨应用的操作,如 API 调用等,尽量不要在有事务的方法里面进行;
- 如果在真实业务场景中有耗时的操作,也需要带事务时(如扣款环节),那么请注意增加数据源配置的连接池数;
- 我们通过 MVC 的应用请求连接池数量,也要根据连接池的数量和事务的耗时情况灵活配置;而 tomcat 默认的请求连接池数量是 200 个,可以根据实际情况来增加或者减少请求的连接池数量,从而减少并发处理对事务的依赖。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客!!! 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等…
