
大家好,我是宁一
这篇我们来看看各大厂出的高频实战题~
选择题、问答题可以参考上一篇文章:2022年SQL经典面试题总结(带解析)
实战题相对比较复杂,需要一定的耐心,主要学习解题思路。
一、聚合函数
聚合函数,顾名思义,就是会将数据记录聚合到一起的函数,比如MAX、MIN、SUM、AVG、COUNT,都是将多条记录汇总为一条记录。通常与GROUP BY语句、HAVING语句结合使用。
我们来看看问题:
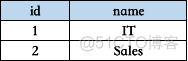
Employee 员工信息表表包括,每个员工对应的工号 Id,姓名 Name , 工资 Salary 和部门编号 DepartmentId 。
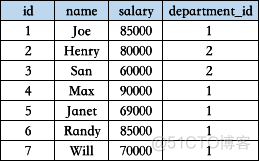
Department 部门信息表包含部门对应的编号ID和部门名称Name。
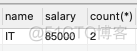
编写一个SQL查询,查找 Employee 表中,每个部门重复的工资记录,以及重复的个数。
例如上面示例应返回:
解题思路:通过join函数连接Department表,显示出部门名称,通过GROUP BY 对部门进行分组,使用COUNT聚合函数进行计数,最后通过HAVIGN判断重复的记录。
SELECT
de.name,
em.salary,
count(*)
FROM Employee em
JOIN Department de
ON em.department_id = de.id
GROUP BY de.name,em.salary
HAVING count(*)>1二、JOIN连接
- INNER JOIN: 内连接,也可以只写JOIN。只有进行连接的两个表中都存在与连接标准相匹配的数据才会被保留下来。
- LEFT JOIN: 左连接,操作符左边表中符合 WHERE 子句的所有记录将会被 返回,操作符右边表中如果没有符合 ON 后面连接条件的记录时,那么从右边表 指定选择的列的值将会是 NULL。
- RIGHT JOIN: 右连接,会返回右边表所有符合 WHERE 语句的记录。左表 中匹配不上的宇段值用 NULL 代替。
- FULL JOIN:外连接,返回所有表中符合 WHERE 语句条 件的所有记录。如果任一表的指定宇段没有符合条件的值的话,那么就使用 NULL 替代。
经典问题解析:
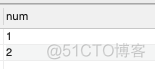
编写一个 SQL 查询,查找所有至少连续出现三次的数字,表名为:Num,表结构如下:
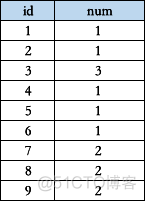
解题思路:通过id+1的方式查找id下一次出现的数字,通过id+2的方式查找下下次出现的数字,只要下一次及下下次出现的数字和当前出现的数字相同,即为满足连续出现至少三次的数字。
SELECT DISTINCT a.num
FROM Num a
JOIN Num b
ON a.id+1 = b.id
JOIN Num c
ON a.id+2 = c.id
where a.num = b.num
AND a.num = c.num结果如下:
三、窗口函数
窗口函数,也叫OLAP(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
窗口函数是数据分析师常用的语法函数,几乎是大厂的必考题。
下面给大家准备了两道经典的窗口函数题目。并准备了清晰的解题思路,我们来一起看看。
第一题:求连续天数
下面表格是用户访问表users,记录了用户id(usr_id)和访问日期(log_date),求出连续3天以上访问的用户id。
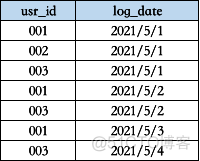
解题思路:我们需要根据这么一个简单的表,求出连续3天以上访问的用户。我们可以按照用户id给访问日期排名,然后再用访问日期减去排名,得到一个时间。如果用户是连续访问的,这个时间就是一样的。一个用户的这个时间如果出现3次及以上,说明这个用户连续访问了3天。
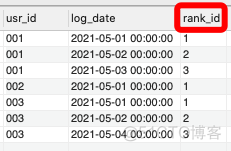
(1)先按照用户id(usr_id)对访问日期(log_date)进行排名,这里要用到DENSE_RANK() 这个窗口函数,给出排名序号。这个函数经常应用于给学生成绩进行排名。
SELECT usr_id,log_date,
DENSE_RANK() OVER (PARTITION BY usr_id order_by log_date) AS rank_id
FROM users查看结果,多了一个rank_id的列
(2)得到排名后,我们用访问日期减去排名,得到一个时间flg_date。这个时间
SELECT
usr_id,
DATE_SUB(log_date,INTERVAL rank_id DAY) AS flg_date
FROM (
SELECT
usr_id,
log_date,
DENSE_RANK() OVER (PARTITION BY usr_id ORDER BY log_date) AS rank_id
FROM users
) AS A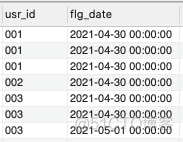
(3)同一个用户有3个及以上flg_date相同,说明用户连续访问了3天,所以我们对上面查出的这个结果进行分组,并统计判断是否大于3
SELECT
usr_id,
DATE_SUB(log_date,INTERVAL rank_id DAY) AS flg_date
FROM (
SELECT
usr_id,
log_date,
DENSE_RANK() OVER (PARTITION BY usr_id ORDER BY log_date) AS rank_id
FROM users
) AS A
GROUP BY usr_id,flg_date
HAVING COUNT(flg_date) >=3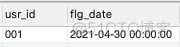
(4)这样就已经得出最终结果了,因为题目只想知道usr_id,我们最后再将usr_id展示出来就可以了。
最终具体代码如下:
SELECT DISTINCT usr_id
FROM(
SELECT
usr_id,
DATE_SUB(log_date,INTERVAL rank_id DAY) AS flg_date
FROM (
SELECT
usr_id,
log_date,
DENSE_RANK() OVER (PARTITION BY usr_id ORDER BY log_date) AS rank_id
FROM users
) AS A
GROUP BY usr_id,flg_date
HAVING COUNT(flg_date) >=3
) AS B
如果想要自己创建表格来测试,可以通过下面语句创建表格
drop table Users;
create table if not exists Users(usr_id varchar(10),log_date datetime);
insert into Users values('001' , '2021.5.1');
insert into Users values('002' , '2021.5.1');
insert into Users values('003' , '2021.5.1');
insert into Users values('001' , '2021.5.2');
insert into Users values('003' , '2021.5.2');
insert into Users values('001' , '2021.5.3');
insert into Users values('003' , '2021.5.4');第二题:找出工资前3高的员工,相同工资并列排名
现在有 Employee 员工信息表和Department部门信息表,分别如下:
Employee 员工信息表包括,每个员工对应的工号 Id,姓名 Name , 工资 Salary 和部门编号 DepartmentId 。
Department 部门信息表包含部门对应的编号ID和部门名称Name。
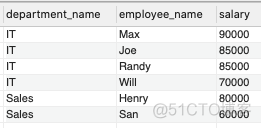
编写一个SQL查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
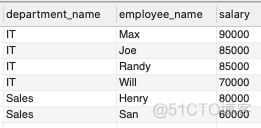
解题思路 :这里要注意是细节是,最终结果输出的是前三高工资的所有员工,有些员工的工资是一样的,每个部门可能不止3名员工符合这个要求。
我们可以按照部门id(department_id)给员工工资(salary)排名,然后找出每个部门前三高工资对应的所有员工。
(1)先按照部门id(department_id)对员工工资(salary)进行排名,这里要用到DENSE_RANK() 这个窗口函数,得到每个部门的工资排名序号。
SELECT
de.name AS department_name,
em.name AS employee_name,
em.salary,
DENSE_RANK() OVER(PARTITION BY de.name ORDER BY em.salary DESC) AS salary_rank
FROM Employee em
JOIN Department de
ON em.department_id = de.id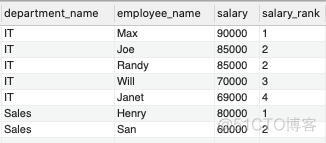
(2)再将上面的查询作为子查询,查找salary_rank字段
SELECT
A.department_name,
A.employee_name,
A.salary
FROM
(
SELECT
de.name AS department_name,
em.name AS employee_name,
em.salary,
DENSE_RANK() OVER(PARTITION BY de.name ORDER BY em.salary DESC) AS salary_rank
FROM Employee em
JOIN Department de
ON em.department_id = de.id
) AS A
WHERE salary_rank 最终结果如下
四、留存问题
留存率:是用户分析的核心指标之一,留存问题也是一个经常考的题目。
现场写一道SQL:给定用户表Users,求出每个日期对应的活跃用户数、次日留存用户数、次日留存率
指标定义:
某日活跃用户数,某日活跃的去重用户数。
N日留存用户数,某日活跃的用户在之后的第N日活跃用户数。
N日活跃留存率,N日留存用户数/某日活跃用户数
例:20210501日去重用户数为10000,这批用户20210503日仍有7000人活跃,则3日活跃留存率为7000/10000=70%
(1)N日活跃留存率 = N日留存用户数/某日活跃用户数。我们先得到每日活跃用户数
SELECT log_date AS '日期',COUNT(DISTINCT usr_id) AS '活跃用户数'
FROM Users
GROUP BY log_date;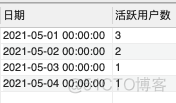
(2)在得到次日留存用户数
SELECT a.log_date AS 日期,COUNT(DISTINCT b.usr_id) AS '次日留存'
FROM Users a
LEFT JOIN Users b
ON a.usr_id = b.usr_id
AND
DATEDIFF(b.log_date,a.log_date)=1
GROUP BY a.log_date;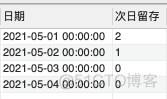
次日留存,3日留存,7日留存等只需要更改日期相差的天数即可。DATEDIFF(b.log_date,a.log_date)=1改成=3或者=7
(3)我们最终用一条sql语句得到结果
SELECT
a.log_date AS 日期,
COUNT(DISTINCT a.usr_id) AS '活跃用户数',
COUNT(DISTINCT CASE WHEN DATEDIFF(b.log_date,a.log_date)=1 THEN b.usr_id END) AS '次日留存',
CONCAT(COUNT(DISTINCT CASE WHEN DATEDIFF(b.log_date,a.log_date)=1 THEN b.usr_id END)/COUNT(DISTINCT a.usr_id)*100,'%') AS '次日留存率'
FROM Users a
LEFT JOIN Users b
ON a.usr_id = b.usr_id
GROUP BY a.log_date;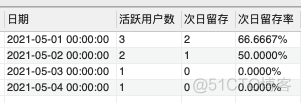
(4)扩展得到3日留存率
SELECT
a.log_date AS 日期,
COUNT(DISTINCT a.usr_id) AS '活跃用户数',
COUNT(DISTINCT CASE WHEN DATEDIFF(b.log_date,a.log_date)=1 THEN b.usr_id END) AS '次日留存',
COUNT(DISTINCT CASE WHEN DATEDIFF(b.log_date,a.log_date)=3 THEN b.usr_id END) AS '三日留存',
CONCAT(COUNT(DISTINCT CASE WHEN DATEDIFF(b.log_date,a.log_date)=1 THEN b.usr_id END)/COUNT(DISTINCT a.usr_id)*100,'%') AS '次日留存率',
CONCAT(COUNT(DISTINCT CASE WHEN DATEDIFF(b.log_date,a.log_date)=3 THEN b.usr_id END)/COUNT(DISTINCT a.usr_id)*100,'%') AS '三日留存率'
FROM Users a
LEFT JOIN Users b
ON a.usr_id = b.usr_id
GROUP BY a.log_date;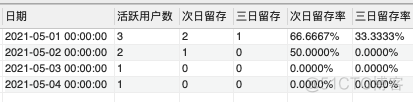
五、列转行
列转行,这个也是大厂经常考的题目,在mysql中我们可以通过union语句将查询结果合并,在hive中可以使用Lateral View与UDTF函数(explode,split)结合使用来实现。我们举两个例子
第一题:
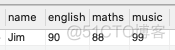
将上表格式转换为下表格式
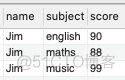
解题思路:先将每一行单独提取出来,再通过union合并结果
select name,'english' as subject,english as score from a1
union
select name,'maths' as subject,maths as score from a1
union
select name,'music' as subject,music as score from a1;快速建表语句,可以自己测试。
create table a1 (
name varchar(20),
english int,
maths int,
music int);
insert into a1 values
("Jim",90,88,99);第二题:
Movie表记录了各大电影的类型情况,数据如下:
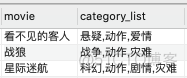
需要转换成以下格式:
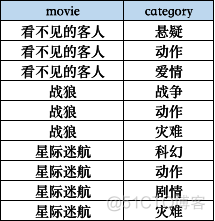
解题思路:在hive中,lateral view用于和split, explode等UDTF函数一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
lateral view首先为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
语法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias (‘,’ columnAlias)
本题只需要借助Lateral View进行拆解重组即可:
SELECT movie,category
FROM Movies
LATERAL VIEW explode(category_list)tt AS category有不完善的地方可以留言我们一起探讨~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 富文本编辑器 VUE-QUILL-EDITOR 使用教程 (最全)
VUE-QUILL-EDITOR 基于 QUILL、适用于 VUE 的富文本编辑器,支持服务端渲染和单页应用,非常高效简洁。 一.基础用法 1、NPM 导入 VUE-QUILL-EDITOR npm install vue-quill-editor –sav…
