
文章目录
-
- 环境准备
- 部署步骤
-
- 配置 airflow.cfg
- 启动 airflow statsd 服务
- 重启 airflow scheduler 和 worker 服务
- 配置 prometheus
- grafana 导入 airflow dashboard
- 重要指标分析
- 总结
环境准备
- 部署好的 airflow(包括 scheduler, worker)
- grafana 和 prometheus
使用 statsd 服务采集 airflow 的 metrics 然后推送至 prometheus,再通过 grafana 配置 prometheus 数据源,导入 airflow 的 dashboard 显示对应的 metrics 监控。
部署步骤
配置 airflow.cfg
[metrics]
statsd_on = True
statsd_host = localhost
statsd_port = 8125
statsd_prefix = test-airflow
statsd_allow_list = scheduler,executor,dagrun
-
statsd_host: airflow 暴露 metrics 的 statsd 服务,后边接入 prometheus 的时候需要配置该地址
-
statsd_allow_list: 暴露的 metrics 信息,为空会暴露所有的 metrics,不为空只暴露指定的 metrics 信息
airflow v2.6 已有的 metrics 可以查看官方文档:https://airflow.apache.org/docs/apache-airflow/stable/administration-and-deployment/logging-monitoring/metrics.html
启动 airflow statsd 服务
version: '2.1'
services:
webserver:
image: prom/statsd-exporter:v0.22.3
restart: always
volumes:
# 注意确认 /data/statsd_export/statsd_mapping.yml 存在
- /data/statsd_export/statsd_mapping.yml:/tmp/statsd_mapping.yml
ports:
- 9102:9102
- 9125:9125
- 9125:9125/udp
command: "--statsd.mapping-config=/tmp/statsd_mapping.yml"
statsd_mapping.yml是 metric 转换后的映射信息:
mappings:
# Map dot separated stats to labels
- match: airflow.dagrun.dependency-check.*.*
name: "airflow_dagrun_dependency_check"
labels:
dag_id: "$1"
- match: airflow.operator_successes_(.*)
match_type: regex
name: "airflow_operator_successes"
labels:
operator: "$1"
- match: airflow.operator_failures_(.*)
match_type: regex
name: "airflow_operator_failures"
labels:
operator: "$1"
- match: airflow.scheduler_heartbeat
match_type: regex
name: "airflow_scheduler_heartbeat"
labels:
type: counter
- match: airflow.dag.*.*.duration
name: "airflow_task_duration"
labels:
dag_id: "$1"
task_id: "$2"
- match: airflow.dagrun.duration.success.*
name: "airflow_dagrun_duration"
labels:
dag_id: "$1"
- match: airflow.dagrun.duration.failed.*
name: "airflow_dagrun_failed"
labels:
dag_id: "$1"
- match: airflow.dagrun.schedule_delay.*
name: "airflow_dagrun_schedule_delay"
labels:
dag_id: "$1"
- match: airflow.dag_processing.last_runtime.*
name: "airflow_dag_processing_last_runtime"
labels:
dag_file: "$1"
- match: airflow.dag_processing.last_run.seconds_ago.*
name: "airflow_dag_processing_last_run_seconds_ago"
labels:
dag_file: "$1"
- match: airflow.pool.open_slots.*
name: "airflow_pool_open_slots"
labels:
pool: "$1"
- match: airflow.pool.used_slots.*
name: "airflow_pool_used_slots"
labels:
pool: "$1"
- match: airflow.pool.starving_tasks.*
name: "airflow_pool_starving_tasks"
labels:
pool: "$1"
重启 airflow scheduler 和 worker 服务
statsd 服务启动成功后,需要重新启动 airflow 的 scheduler 和 worker 服务,才会将 metrics 信息推至 statsd 服务,访问前边配置的 statsd_host: statsd_port/metrics 地址查看:
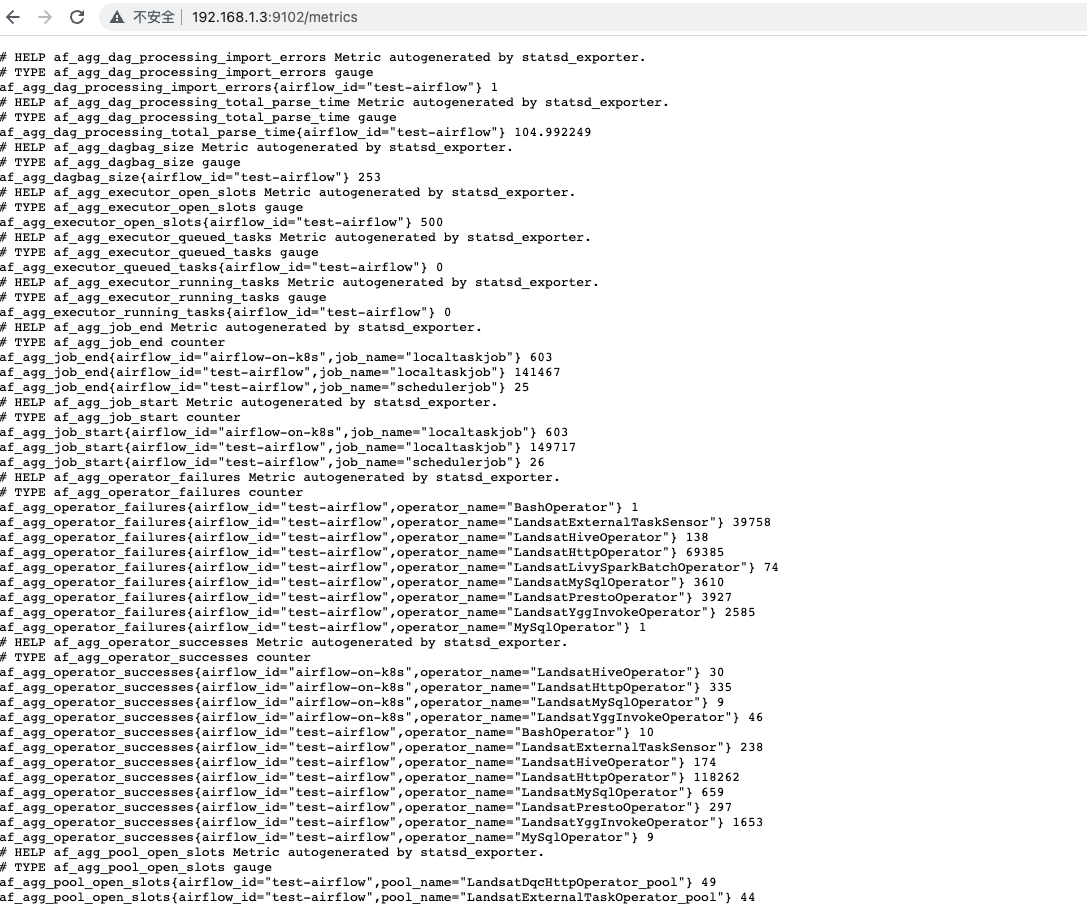
出现上边的内容说明 statsd 服务以及 airflow metrics 配置成功。
配置 prometheus
在 prometheus 的 scape_configs 中配置:
- job_name: airflow
static_configs:
# 地址填写 airflow.cfg 中配置的 statsd 地址
- targets: ['192.168.1.3:8125']
grafana 导入 airflow dashboard
grafana 导入 dashboard 并配置 prometheus 数据源已经是很成熟的方案,网上有很多教程,此处就不在赘述。
airflow dashboard 下载地址:https://github.com/databand-ai/airflow-dashboards/
grafana 导入 dashboard 参考:https://blog.csdn.net/Jailman/article/details/78919704
grafana 数据源配置参考:https://blog.csdn.net/qq_23598037/article/details/99850396
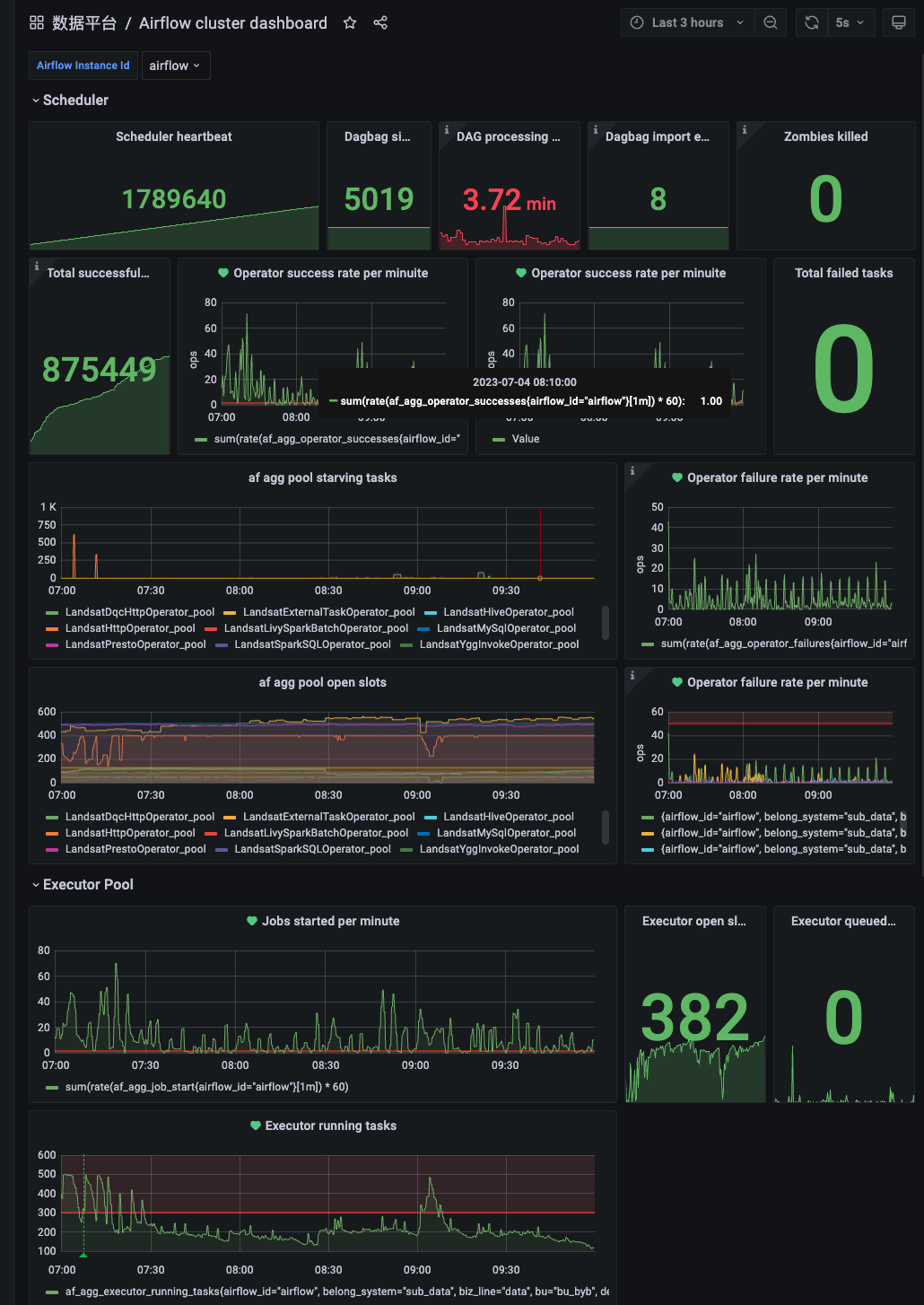
重要指标分析
grafana 除了查看监控指标外,还有一个重要的功能就是监控告警。
在生产环境的实践中,airflow 有几个重要的指标需要监控:
-
DAG processing total parse time
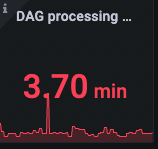
这个是 scheduler 扫描完所有DAG 需要的时间,时间越长任务延迟的可能性就越大,如果 airflow 部署所在的环境资源充足,可以在 airflow.cfg 中增大 dag 扫描相关的配置,可以有效降低延迟。
在使用过程中,有很多DAG 可能是下线无效的,也要及时清理。 -
pool starving tasks
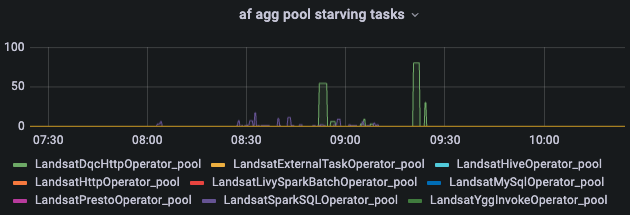
当任务的计划执行时间到了,但是对应的 operator pool 是满的,那么就会该任务实例就会处于等待执行状态,同时会记录一条 starving task。
当 starving task 过多时,说明 pool 资源不足了,需要扩大 pool 数量,pool 数量可以通过 webserver 界面增加,也可以通过修改 airflow 的 slots_pool 表增加。 -
pool open slots
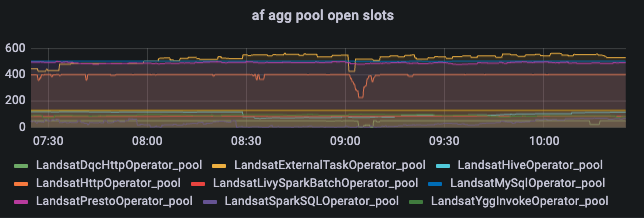
这个可以和 starving tasks 指标一起看,是互补的,当 open slots 为0的时候就会出现 starving tasks。
pool open slots 是一个比较重要的指标,当 airflow 的任务出现延迟时,第一反应应该是查看是否出现了太多的 starving tasks, 对应时间段是否有空闲的 pool open slots。 -
operator failure rate per minute
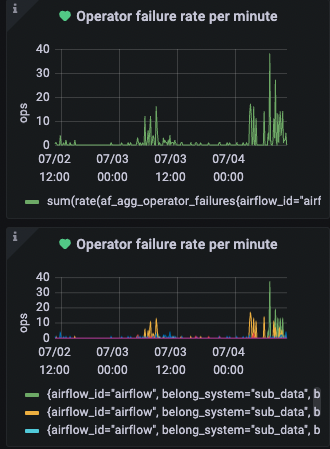
这个也是比较重要的指标,当出现大量失败的时候,就是有问题的。比如说大量 hive 任务执行失败,如果不查看日志,通过查看 airflow 监控指标,大概率就是 hive 提交的计算集群出现了问题导致的。 -
Executor running tasks
该指标反应的是 airflow 运行的任务数量,如果对应的任务没有大量增加或者减少,运行的任务数量每天应该都是差不多的。当突然出现大量运行的任务数量的时候,就需要保证 airflow 的资源是充足的。
总结
指标监控是一项很重要的工作,做的越早,收益越早。
举个最现实的例子,有一天 airflow 系统突然出现了大量的任务延迟,如果你没有对应的指标监控,那么排查问题原因是比较复杂且耗时的。如果有指标监控,那么排查问题的效率会非常迅速且高效。
而且在微服务作为当下主流的开发模式下,系统的可观测性变得更加重要,而指标监控就是一项很重要的必做的事情。
还有比较重要的一点就是重要指标监控告警,grafana 可以很好的支持将自定义告警信息发送至企业微信群或者打告警电话。
如今 statsd + prometheus + grafana 作为指标监控的解决方案,已经是非常成熟的方案了,网上教程也很多,因此在本片文章中就没有赘述。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
目录 前言:类的6个默认成员函数 一, 构造函数 1. 概念 2. 特性 二, 析构函数 2.1 概念 2.2 特性 2.3 牛刀小试 三, 拷贝构造函数 3.1概念 3. 2 特点 四, 赋值运算符重载 4. 1 运算符重载 五, const成员函数 六…
