
1. Amazon MSK介绍
Kafka作为老牌的开源分布式事件流平台,已经广泛用于如数据集成,流处理,数据管道等各种应用中。
亚马逊云科技也于2019年2月推出了Apache Kafka的云托管版本,Amazon MSK(Managed Streaming for Apache Kafka)。相较于传统的自建式Kafka集群,MSK有如下几点优势:
- 快速部署:作为完全托管的云服务,Amazon MSK提供了原生多可用区(AZ)的Apache Kafka集群部署模式,可以帮助客户快速配置并部署高度可用的Apache Kafka集群
- 降低运维复杂度:Amazon MSK会自动检测底层服务器,并在出现故障时进行替换。也会编排服务器的补丁与升级。同时还确保数据得到长久存储和保护,方便快捷地查看监控指标并设置警报
- 弹性扩展:充分利用云服务的资源弹性能力,可以根据负载变化自动进行扩展
- 与其他AWS服务紧密集成:Amazon MSK 与 AWS Identity and Access Management (IAM) 和 AWS Certificate Manager 集成以实现安全性;与 AWS Glue Schema Registry 集成用于schema管理;与 Amazon Kinesis Data Analytics 和 AWS Lambda 集成用于流式传输处理,等等。使应用程序的开发更简单
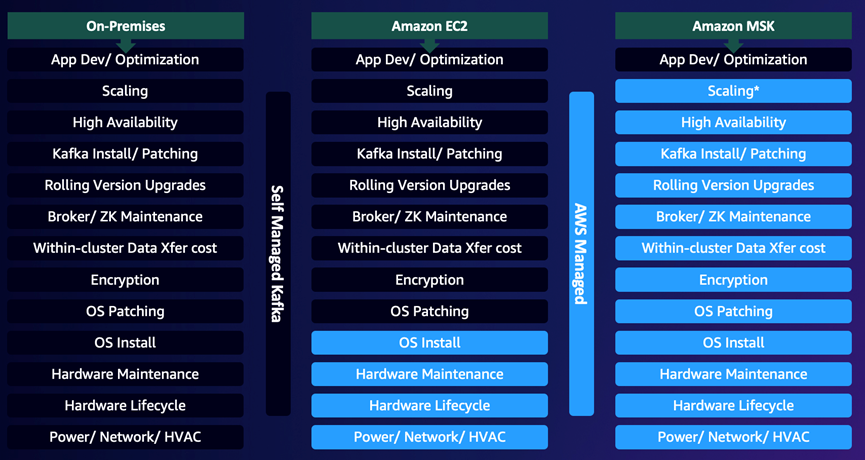
下面对比图很清晰地描述了在本地、EC2部署Apache Kafka以及Amazon MSK的对比。使用Amazon MSK服务,可以让用户将更多的时间与精力关注在应用开发与运行上。
2. 构建可靠的消息队列平台
Amazon MSK作为托管服务,除了上面提到的优势外,还提供了基础设施稳定运行的保障(例如底层的EC2,EBS卷等,分别有其对应的SLA保障)。但是,对于底层硬件,达到0%的故障率是非常难以企及的事情,我们无法忽视这部分不确定性对业务带来的影响。所以在构建Apache Kafka的消息队列平台时,仍需根据不同场景,调整Kafka相关参数,达到可靠性要求。而在我们提到可靠性时,往往表示的是整个系统的可靠性,而非单个组件的可靠性。所以在调整时,除了集群本身的参数外,还包括客户端的参数。
为避免歧义,我们定义在本文中提到的“可靠”的含义。其表示的是:在出现不同的系统故障时,Kafka消息队列系统仍能正常对外提供服务,不影响业务的正常运行且尽可能减少数据丢失的风险。
下面我们会首先介绍Kafka提供的基本保障,以及基于这几个基本保障之上,Kafka集群、生产者客户端,以及消费者客户端如何进行配置,以达到不同的保障性需求。
注意,下面文字内容较多,可以优先参考文档第5部分的配置总结进行相关参数配置。
2.1. Kafka提供的保障
首先,我们先看看Kafka提供的4个基本保障:
- 同一partition内消息的顺序在写入后不再变化
- 一条消息在写入到其partition对应的所有in-sync replicas(不一定已经flush到disk)后,此消息才视为committed。而Producer可以配置是否接受ack以及ack级别
- 被committed消息,只要有至少一个replica存活,则消息不会丢失
- Consumer只能读取到committed的消息
在这4个基本保障中,与可靠性相关的部分主要为第2条,其中涉及到的Replication(副本)是Kafka提供可靠性保障的一个重要功能。也是Kafka实现高可用与数据高持久性的核心要素。
首先简单地介绍Replication的功能(若希望了解更多细节,请参考文档[2]):在Kafka中,每个partition可以有多个replica,其中1个为leader,其他的为in-sync replica。Leader replica负责写入,以及消费。其他的in-sync replica只需要与leader保持同步状态并实时复制消息(也可以配置消费者从replica消费数据)。如果leader 不可用,则其他replica会选举为新的leader。
下面我们围绕此机制展开,介绍构建可靠的Kafka消息队列平台时,需要考虑的相关要点。
2.2. Broker配置
在broker层面,与可靠性相关的配置主要有3个,分别为default.replication.factor,unclean.leader.election.enable以及min.insync.replicas。
Replication Factor
Replication factor控制的是消息备份数,topic级别的配置项为 replication.factor,broker级别的配置项为 default.replication.factor。在MSK中,default.replication.factor默认为3 for 3-AZ clusters, 2 for 2-AZ clusters。
Replication factor设置为N时,可以允许N-1 个broker丢失时还能正常提供topic的读写服务。所以此参数的值越高,系统的可用性、可靠性越高,故障容忍度也更高。但另一方面,我们需要的broker数(至少N个broker),磁盘量也会更多(N倍的数据存储量),同时broker之间的流量也会增加(N-1倍的复制流量)。所以这里在可用性与硬件设施上需要有所权衡。
另一方面,在数据冗余方面,Kafka会确保同一个partition的各个replica分布在不同的broker上。但仅有这点是不够的安全的,最好还将broker分布在不同的机架甚至不同的数据中心,达到更高的数据持久型保障。而Amazon MSK便是将broker跨多个可用区进行部署。
对于replication factor参数,常规调整准则为:
l 以3为起始(当然至少需要有3个brokers,同时也不建议一个Kafka 集群中节点数少于3个节点)
l 如果由于replication 导致性能成为了瓶颈,则建议使用一个性能更好的broker,而不是降低RF的值
l 永远不要在生产环境中设置RF为1
Unclean Leader 选举
对于1个partition来说,如果其leader replica出现故障且不再可用,则会在其in-sync replicas中选举一个新的leader replica。对于这个过程,我们称为一个“clean”选举,因为这个过程没有committed数据丢失,committed数据存在于所有in-sync replica上。
与“clean”选举相反的为“unclean”选举,其表示的含义是:并不一定要强制从in-sync replica中选举leader,也允许out-of-sync replica选举成为leader。Out-of-sync replica,如字面意思,表示此replica与leader中间存在同步落后的情况(落后的原因可能包括网络延迟,broker故障等)。
为什么需要考虑允许out-of-sync replica选举成为leader?举一个例子,假设一个partition有3个replica,有2个in-sync replica已经出现故障,仅有leader在正常工作。过了一会儿,leader出现故障,并很快有1个replica恢复。此时,这个replica为out-of-sync replica(因为中间有一段时间未与leader同步数据)。
若是不允许out-of-sync replica选举成为leader,则此partition将无法继续提供服务,除非等到leader恢复正常。若是允许out-of-sync replica选举成为leader,则此时partition可以继续提供服务,但是会有部分数据丢失(之前未同步的数据)。所以,这里也涉及到可用性与数据持久型的权衡。
控制此行为的参数为unclean.leader.election.enable,在broker级别(实际一般在集群级别配置)适用。在MSK中默认为true,也即是说允许“unclean”选举。在使用时,需要根据实际场景,在可用性与数据持久性之间进行权衡。
最少In-Sync Replicas
从我们上面的例子可以看到,造成数据丢失的主要原因是:leader与replica之间存在同步落后,且允许选举out-of-sync replica为leader。这里的问题在于:in-sync replica故障后,仍可以往leader正常写入,导致了同步落后。
在Kafka提供的保障中,消息在写入leader及其所有in-sync replicas后,才视为committed。但是这里“所有in-sync replicas”仅包含in-sync replicas,并不考虑out-of-sync replica。也就是说,如果当前partition有leader以及2个out-of-sync replica,则消息在写入leader后,便视为committed。
如果需要保证消息至少写入到多个in-sync replicas后才视为committed,则可以通过参数 min.insync.replicas 进行控制(可以在broker级别或是topic级别设置)。
举个例子,假设我们MSK使用3 broker,default.replication.facto=3,min.insync.replicas=2。则至少有2个replica为in-sync状态时(包括leader),此topic的partition才能被生产者正常写入。如果1个replica发生故障(例如AZ宕机,broker故障等等),topic仍能正常进行读写。而若是有2个replica同时发生故障时,broker会拒绝所有写入(Producer会收到NOT_ENOUGH_REPLICAS异常),topic转为只读。
我们再回看在“Unclean Leader选举”中的例子。在设置了min.insync.replicas=2后,若是有2个replica出现故障,则无法再进行写入,继而避免了后续更高的同步落后,数据持久性会更高。不过此时并非表示一定不会有数据丢失。举一个非常极端的例子,假设leader与1个in-sync replica A正常工作,另一个replica B出现故障,此时topic仍能对外提供服务。过了一会儿,replica B 恢复(此时为out-of-sync replica),但是马上leader与replica A 故障。若是unclean.leader.election.enable为true,则replica B 选举为leader。此时虽然producer无法继续写入,但是replica B 与原leader之间未同步的数据会丢失。
在MSK中,min.insync.replicas参数默认为2 for 3-AZ clusters, 1 for 2-AZ clusters。更高的值可以提供更高的数据持久性,但是会牺牲一定的可用性。
2.2. Producer配置
系统可靠性强调的是整体的可靠性,即使我们在broker端下足功夫调整配置,使其达到尽可能高的可靠性。但如果producer端发送消息的机制不够可靠,则整个系统仍有丢失数据的风险。
在Producer部分,实现可靠的Producer主要需要考虑2点:
- 根据可靠性需求,设置合理的acks参数值
- 妥善处理Producer异常
acks有3种模式,分别为:
l acks=0:producer在成功发送一条消息出去后,不需要broker端的response确认,即可认为写入成功。 如果消息发送到broker 端时,broker下线或是发生了故障,则Producer端无法感知,且这部分数据会丢失。这种模式下,由于不需要broker的确认,所以写入延迟较低。但是并非代表端到端延迟也低,因为只有消息从leader同步到所有in-sync replica后,consumer才能读取到这条消息
l acks=1:producer在成功发送一条消息出去后,需要等待leader成功后写入并返回ack后,才认为写入成功。但是如果leader在尚未将消息同步到in-sync replica前发生故障,则仍会丢失此消息
l acks=all:producer在成功发送一条消息出去后,需要等待leader及其所有的in-sync replicas 成功写入后,返回ack,才认为写入成功。此参数必须与前面介绍的min.insync.replicas一起使用(控制最小所需写入的in-sync replica数量)。此参数是最安全的选项,能够确保消息完全写入到多个replica。不过显而易见,也会引入更高的延迟
除了acks的配置外,Producer端还需要注意的一个点是异常的处理。为了防止一些瞬时的错误(例如NotEnoughReplicasException)影响整个应用,一般我们需要处理一些异常,以避免数据丢失。
Kafka里的异常分两种:
l 可重试异常(例如leader不可用):对这类异常Producer会自动进行重试。为了避免Producer端耗尽重试次数而导致数据丢失,建议配置Producer的重试次数为Integer.MAX_VALUE,并配置delivery.timeout.ms为最长的等待时间。让Producer可以在遇到此类异常时不断重试,直到写入成功
l 不可重试异常(例如配置参数不对,消息大小问题等):对这类问题,一般属于客户端问题,Producer也不会自动进行重试。从系统稳定性考量,开发人员需要根据业务场景,妥善处理这类异常,防止应用退出
最后,重试会带来的一个风险是消息的重复。重试可以保证消息传递的语义为at-least-once,而非exactly-once。启用enable.idempotence=true的配置可以使得Producer引入额外的信息到record中,并以次让Brokers可以过滤掉由于重试引入的重复消息。
2.3. Idempotent Producer
首先,什么叫做幂等(Idempotent)?其表示的是:对于一个操作,如果执行多次的结果和执行一次的结果都是完全一样的,这样的操作叫做幂等操作。
前面提到,在Kafka producer中,在通过重试做到消息传递的at least once语义后,同一条消息可能会多次传输,也就最终会导致可能的下游重复事件。
一个常见的情况是:producer发送一条消息到leader,leader在接收到后,将消息成功的复制到了replica,但是在leader向producer发送确认ack时,leader所在的broker宕机,导致没有正常将ack发送回producer。此时从producer的角度,它是没有收到确认消息的,所以会尝试重发消息。这条消息会到达一个新的leader,它本身已经包含了上一条发送的消息,所以这种情况下就导致了消息的重复。
在某些情况下,重复消息不会对下游带来影响(例如下游是put到nosql数据库),但在部分情况下会导致下游数据重复(例如下游是append到数据库)。
Kafka的idempotent producer(幂等生产者)功能可以解决这种问题,其方法是自动检测并解决这类重复消息。
2.3.1. 如何解决幂等问题
在启用Kafka幂等生产者的功能后,每条消息会带上一个唯一的标识id,称为PID(producer id),以及一个序列号。这个PID与序列号 加上 topic与partition信息,可以唯一标识一条消息。
Broker会用这个唯一标识消息的信息来跟踪最近5条(由参数max.inflight.requests来控制,默认值为5)发送到每个partition的消息。当broker收到一条之前已经收到过的消息时,会拒绝这条消息并返回producer一条提示报错信息。在producer端,这个信息会加入到record-error-rate的指标中。在broker端,这个报错会归类于ErrorsPerSec的指标,属于RequestMetrics类型。
2.3.2. 幂等producer的作用范围
Idempotent producer仅用于防止由于producer retry机制导致的消息重复。例如由于producer没收到ack,或者由于网络,broker问题导致的消息没有发送成功,从而producer自动尝试,并由此导致的可能的消息重复问题。但如果是应用层的重试,例如应用端发现消息未发送成功,把失败的消息放入重试队列,然后再次调用send()方法发送消息。这类重试的消息会有新的唯一标识信息,不在idempotent producer处理的范围内。
2.3.3. 如何配idempotent producer
在producer端加上配置enable.idempotence=true即可。在开启这个功能后,会有如下变化:
- 由于要从broker取producer ID,所以producer会在启动时额外调用一个API
- 每个发送的record batch会包含producer ID以及第1条消息的sequence ID(batch中第1条之后的消息的sequence ID是由第1条消息的sequence ID 加上一个delta增量得来)。这些新的字段会增加每个record batch 额外96bits(producer ID是long类型,sequence时integer类型)。
- Broker会验证每个producer发过来的消息中sequence number,并判断是否为重复消息
- Partition内的消息顺序仍能保持
2.4. Consumer配置
Consumer在消费Kafka数据时,主要需要确保的一点便是: 不漏消费消息。保障此行为的机制便是offset commit。
Consumer 在消费了目标topic的消息后,可以自动(按固定时间间隔)或手动的方式完成offset commit。Committed offset会记录在Kafka的__consumer_offsets topic内(服务器托管网由group.id的值进行hash并写入不同partition),下次消费会按照上次offset的位置继续消费。
与offset commit相关的有4个重要的配置:
- group.id:用于标识消费组
- auto.offset.reset:如果当前消费组对目标topic没有committed offset时(例如Consumer第一次消费),Consumer使用的offset位置(可配置为earliest或latest,默认为latest)
- enable.auto.commit:是否定期自动commit offset
- auto.commit.interval.ms:若是启用了自动commit offset,指定自动commit的时间间隔,默认为5s。一般来说,间隔更短,Consumer的资源开销会更大。但是在Consumer停止并重新启动后,处理的重复数据更少。
可以看到,在使用自动commit offset机制时,消息传递语义为at-most-once。会引入重复数据消费以及数据可能丢失的问题。例如,假设Consumer在拉取了Kafka的消息后,需要写入下游数据库。在写入数据库时发生异常,导致一直未能写入成功并最终失败。由于自动commit offset的机制,Consumer仍会自动将已消费消息的offset commit到Kafka端。若是这部分异常未能正常处理,则未能写入下游的数据便会丢失。
所以,在复杂场景下,需要更高的端到端一致性以及准确性时,建议手动做commit offset。因为自动commit offset的机制无法保证消息已被下游正确处理。
在执行手动commit offset时,常规考虑要点为:
- 在消息被下游完全处理后,再手动commit offset
- Commit offset是一个较为耗费资源的操作。更频繁的commit可以减少Consumer停止并重启后重复消费数据的概率,但是会带来更高的负载。此处需要对吞吐与可能的重复数据之间进行权衡。
- Consumers重试。例如上面介绍的Consumer消费数据并向下游数据库写数据的例子,Consumer可能会遇到处理一个批次消息时,部分消息写入下游数据库失败。此时Consumer端要做好重试的机制,例如将失败的消息进行缓存,并进行重试。在重试时,对消费Kafka消息的行为有2种处理方式:
a) 使用Consumer pause() 方法,确保polls不再返回新数据,优先将当前批次数据完全处理(一致性优先考量)
b) 将失败的消息写入到另一个重试topic,并使用另一个消费组来处理失败的消息。当前Consumer可以继续正常消费并处理(吞吐优先考量)
可以看到,手动执行commit offset的机制保证的消息传递语义为at-least-cone语义。也就是说,消息至少会被消费一次,但是仍可能会带来可能的数据重复消费的问题。例如在处理一个批次消息时Consumer发生异常退出,但是部分消息已经写入了下游。重启Consumer后,仍会从这个批次的offset起始位置消费,并再次处理同一批数据(包含上次已经写入下游的部分数据)。
针对这种at-least-once语义场景,常规的处理方式是:保证下游是幂等的(idempotent)。也就是说,重复数据在写入下游时,重复消息不会对下游应用的准确性产生影响。例如下游写入ElasticSearch时,使用_id字段唯一识别一条消息,重复数据写入时也是覆盖同一个文档。
2.4.1. 流处理引擎offset管理
最后,值得提到的一点是,在流处理引擎如Spark Structured Streaming以及Flink里,offset commit的行为有所不同。
在Spark Structured Streaming中,(即使指定了group.id的配置)Kafka Source也不会commit offset到Kafka的,而是使用其checkpoint机制进行管理并做故障恢复。每次在执行checkpoint时,会将当前消费的offset记录在其checkpoint文件内。
若是有需求监控消费组的lag,则需要手动做commit offset到Kafka的操作。其中开源社区提供了一个方法可以直接参考[4]。
在Flink中,如果未启用checkpoint,则使用的自动commit offset的方式,将offset定期提交到Kafka(仍通过enable.auto.commit与auto.commit.interval.ms进行配置)。
在启用checkpoint后,同样通过checkpoint机制进行管理并做故障恢复。在checkpoint完成后(offset已写入checkpoint文件),再将offset commit到Kafka。但是在故障恢复时,仅使用checkpoint内的offset。Kafka端的offset仅用于做消费lag监控。
3. 监控
对于平台的稳定运行,监控是必不可少的。关键指标监控与报警机制可以让我们及时地发现平台的问题,并以自动或手动的方式介入,避免对系统稳定造成进一步的影响。
对于AWS MSK,官方提供了2种查看监控指标的方式:CloudWatch与Prometheus。具体介绍可以参考文档[5]。
在监控指标方面,提供了不同级别的指标,包括4种级别,分别为:DEFAULT,PER_BROKER,PER_TOPIC_PER_BROKER, PER_TOPIC_PER_PARTITION。除了DEFAULT级别外,开启另外3个级别需要额外收费。所有可监控CloudWatch指标可以参考文档[6]。
常用集群负载与稳定性监控指标包括:
l ActiveControllerCount:应永远为1
l Broker的CPU User与CPU System:两者之和应低于60%
l Broker的KafkaDataLogsDiskUsed:使用率应低于85%
l HeapMemoryAfterGC:应持续保持在60%以下
l 消费者的Consumer Lag:消费是否能跟上
4. 验证
下面我们使用此配置验证Kafka的高可用。
首先创建一个3-AZ的MSK集群。
使用kakfa cli创建1个topic,为:
l ha-topic:RF=3,min.insync.replicas=2
# 创建ha-topic ./kafka-topics.sh --bootstrap-server b-1.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-2.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-3.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092 --config min.insync.replicas=2 --partitions 6 --replication-factor 3 --topic ha-topic --create
创建safe-producer.config 配置文件:
retries=2147483647 delivery.timeout.ms=604800000 acks=all
使用kafka-verifiable-consumer消费消息:
./kafka-verifiable-consumer.sh --bootstrap-server b-1.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-2.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-3.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092 --topic ha-topic --max-messages 10000 --verbose --reset-policy latest --group-id ha-consumer1
使用kafka-verifiable-producer生产消息:
./kafka-verifiable-producer.sh --bootstrap-server b-1.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-2.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-3.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092 --topic ha-topic --max-messages 100000 --throughput 100 --producer.config safe-producer.config
然后滚动重启broker。每次重启1个broker,并在重启完毕后再重启第2个broker(在本次测试环境中,重启一个broker约4分钟左右):
aws kafka reboot-broker --cluster-arn arn:aws:kafka:ap-northeast-1:113343415039:cluster/msk-tokyo/cff9d27e-6809-47c5-9f7a-a63f689ad026-4 --broker-ids 2 --profile global
可以看到在1个broker重启时,

在此过程中,Consumer未遇到任何报错。Producer遇到了以下报错:
{"timestamp":1675758285482,"name":"producer_send_success","key":null,"value":"1340","offset":209259,"topic":"ha-topic","partition":2}
WARN [Producer clientId=producer-1] Got error produce response with correlation id 1342 on topic-partition ha-topic-0, retrying (2147483646 attempts left). Error: NOT_LEADER_OR_FOLLOWER (org.apache.kafka.clients.producer.internals.Sender)
Received invalid metadata error in produce request on partition ha-topic-0 due to org.apache.kafka.common.errors.NotLeaderOrFollowerException: For requests intended only for the leader, this error indicates that the broker is not the current leader. For requests intended for any replica, this error indicates that the broker is not a replica of the topic partition.. Going to request metadata update now (org.apache.kafka.clients.producer.internals.Sender)
{"timestamp":1675758285692,"name":"producer_send_success","key":null,"value":"1342","offset":209260,"topic":"ha-topic","partition":2}
{"timestamp":1675758285798,"name":"producer_send_success","key":null,"value":"1341","offset":210908,"topic":"ha-topic","partition":0}
从报错前后的信息来看,数据 1340,1341,1342均写入了Kafka。并且可以在Consumer端打印的日志找到:
{"timestamp":1675758285482,"name":"record_data","key":null,"value":"1340","topic":"ha-topic","partition":2,"offset":209259}
{"timestamp":1675758285801,"name":"record_data","key":null,"value":"1341","topic":"ha-topic","partition":0,"offset":210908}
{"timestamp":1675758285815,"name":"record_data","key":null,"value":"1343","topic":"ha-topic","partition":1,"offset":207770}
{"timestamp":1675758285886,"name":"record_data","key":null,"value":"1344","topic":"ha-topic","partition":3,"offset":207459}
{"timestamp":1675758285890,"name":"record_data","key":null,"value":"1342","topic":"ha-topic服务器托管网","partition":2,"offset":209260}
且可以看到在partition级别,仍保持了有序。
5. 配置总结
根据以上介绍,总结在使用AWS MSK时,构建可靠高可用的MSK集群的配置为:
1. MSK多AZ
- 使用3-AZ集群
2. Broker/集群端配置
- default.replication.factor设置至少为3(MSK为3-AZ时,默认为3)
- min.insync.replicas设置为RF-1。例如在RF为3时,minISR设置为2
3. Producer端配置
- acks=all
- 对于可重试异常,配置无限次重试:retries=MAX_INT
- 配置delivery.timeout.ms为最长的等待时间
- 在连接串里填写所有broker地址
- (可选)基于是否需要处理由于重试导致的重复数据,配置enable.idempotence
4. Consumer端配置
- 使用主动commit offset的机制,在数据被下游正常处理后再commit offset到kafka
由于MSK会自动做底层硬件的维护以及软件的补丁、升级等工作。其工作方式是做滚动升级,也就是说,在执行过程中会每次下线一台broker,以滚动的方式进行维护。上述配置可以实现在这些场景下(包括替换broker)MSK的高可用,同时尽可能避免数据的丢失。
参考文档
[1] MSK特点介绍:https://aws.amazon.com/cn/msk/features/
[2] Kafka数据复制: https://developer.confluent.io/learn-kafka/architecture/data-replication/
[3] MSK默认配置:https://docs.aws.amazon.com/msk/latest/developerguide/msk-default-configuration.html
[4] Spark Structured Streaming commit offset: https://github.com/HeartSaVioR/spark-sql-kafka-offset-committer
[5] Monitoring an Amazon MSK cluster: https://docs.aws.amazon.com/msk/latest/developerguide/monitoring.html
[6] Amazon MSK metrics for monitoring with CloudWatch:https://docs.aws.amazon.com/msk/latest/developerguide/metrics-details.html
[7] Kafka The Definitive Guide:https://learning.oreilly.com/library/view/kafka-the-definitive/9781491936153/
[8] MSK Best Practice:https://docs.aws.amazon.com/msk/latest/developerguide/bestpractices.html
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 泰迪智能科技基于产业技能生态链学生学徒制的双创工作室–促进学生高质量就业
据悉,6月28日,广东省人力资源和社会保障厅在广东岭南现代技师学院举行广东省“产教评”技能生态链建设对接活动。该活动以“新培养、新就业、新动能”为主题,总结推广“产教评”技能人才培养新模式,推行“岗位+培养”学徒就业新形式,帮助青年掌握新技术新技能,打通青…
