

奇富科技(原360数科)是人工智能驱动的信贷科技服务平台,致力于凭借智能服务、AI研究及应用、安全科技,赋能金融机构提质增效,助推普惠金融高质量发展,让更多人享受到安全便捷的金融科技服务。作为国内领先的信贷科技服务品牌,累计注册用户数2亿多。
奇富科技之前使用的是自研的任务调度框架,基于Python研发的,经常面临着调度不稳定的状况,难以维护。后来引入了Apache DolphinScheduler作为公司的大数据任务调度系统,面对大量任务调度的考验,经历了半年磨合期,目前Apache DolphinScheduler在奇富科技运行非常稳定。本文将介绍该公司团队最近一年在开源版Apache DolphinScheduler基础上所做的优化和改进。
一、技术架构
在我们公司的大数据离线任务调度架构中,调度平台处于中间层。用户通过数据集成平台提交数据同步任务给调度平台,通过数据开发平台提交工作流给调度平台。用户不和调度平台直接交互,而是和数据集成平台和数据开发平台交互(图1)。
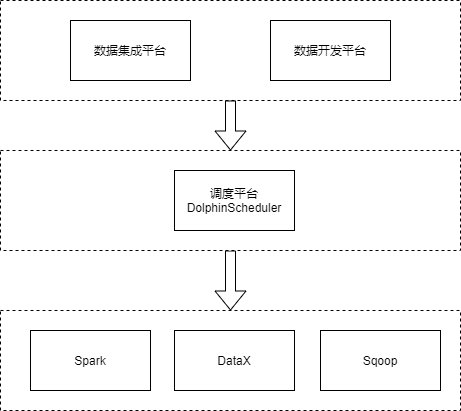
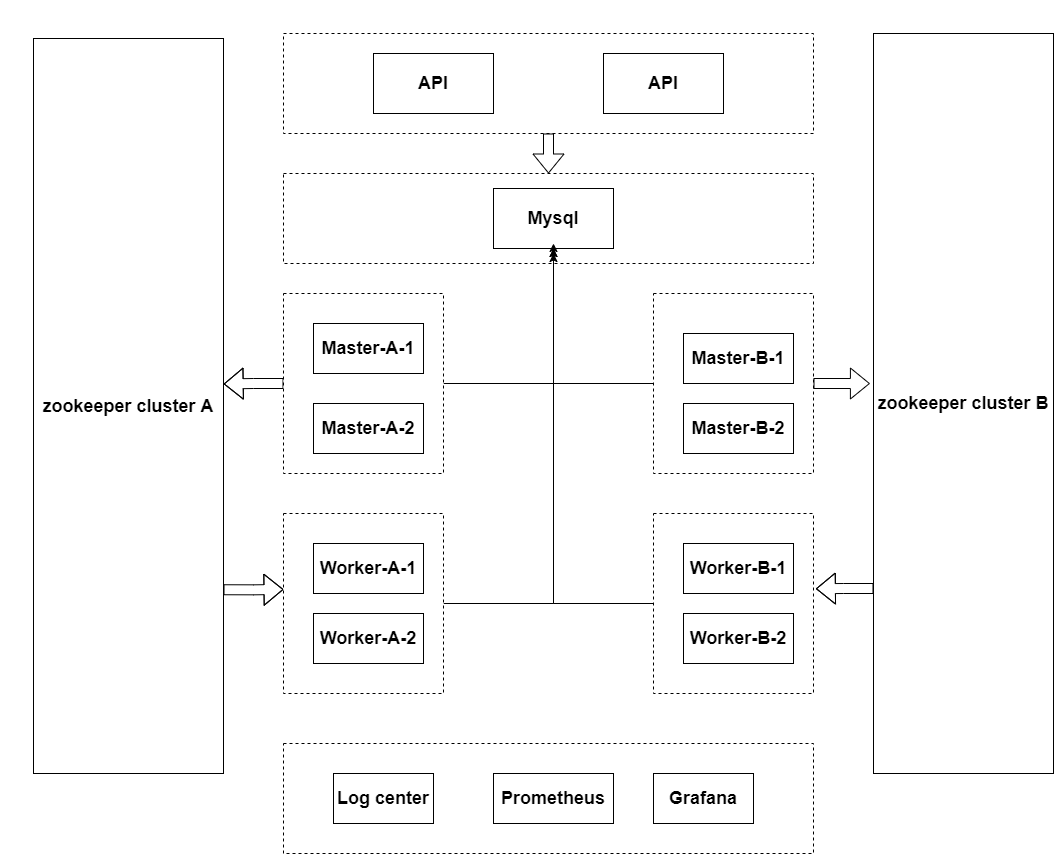
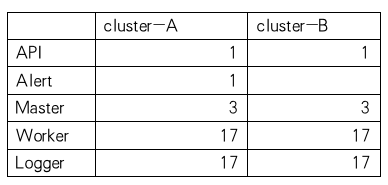
由于我们是一个金融相关业务的公司,业务需要保证高可用。因此,我们的调度平台是异地双机房架构,核心工作流会异地双机房运行。集群角色分为cluster A和cluster B,其中cluster A为主集群,cluster B为从集群(图2)。用户的工作流在A集群运行,其中核心关键工作流会在A和B集群双机房运行。以下是调度集群各服务个数。其中Api、Alter、Master服务在虚拟机部署,Worker和Logger部署在物理机上。
二、业务挑战
01 调度任务量大
我们目前每天调度的工作流实例在3万多,任务实例在14万多。每天调度的任务量非常庞大,要保障这么多任务实例稳定、无延迟运行,是一个非常大的挑战2
02 运维复杂
因为每天调度的任务实例非常多,我们经历了几次调度机器扩容阶段。目前2个调度集群有6台Master、34台Worker机器。而且调度机器处于异地2个城市,增加了很多管理运维复杂性。
03 SLA要求高
因为我们业务的金融属性,如果调度服务稳定性出问题,导致任务重复调度、漏调度或者异常,损失会非常大。
三、调度优化实践
我们在过去一年,对于调度服务稳定,我们做了如下2个方向的优化。第一,调度服务稳定性优化。第二、调度服务监控。
01 重复调度
在2023年初,用户大规模迁移工作流时,遇到了工作流重复调度问题。该问题,现象是同一个工作流会在同一个集群同一时间,生成2个工作流实例。经过排查,是因为用户在迁移时,会有工作流迁移项目的需求,比如从A项目迁移到B项目。在工作流上线时,用户通过提交工单,修改了调度数据库中工作流的项目ID,进行迁移。这么做会导致该工作流所对应的quartz元数据产生2条数据,进而导致该工作流重复调度。如图3所示,JOB_NAME为’job_1270’的记录,有2条数据,而JOB_GROUP不一样。查询源码job_name对应工作流的定时器ID,JOB_GROUP对应项目ID。因此修改工作流对应的项目ID,会导致quartz数据重复和重复调度。正确迁移工作流项目的方式是,先下线工作流,然后再修改项目ID。
 如何避免和监控此问题,我们根据这个逻辑,写了重复调度的监控sql,在最近一年中,数次提前发现了quartz的漏调度问题。
如何避免和监控此问题,我们根据这个逻辑,写了重复调度的监控sql,在最近一年中,数次提前发现了quartz的漏调度问题。
SELECT count(1)FROM (SELECT TRIGGER_NAME, count(1) AS num FROM QRTZ_TRIGGERS GROUP BY TRIGGER_NAME HAVING num > 1 )t
02 漏调度
在2023年初,在凌晨2点,有些工作流发生漏调度,我们排查后发现是凌晨2点0分调度太集中,调度不过来。因此我们优化了quartz参数,将org.quartz.jobStore.misfireThreshold从60000调整为600000。
如何监控和避免此问题,监控sql摘要如下:
select TRIGGER_NAME,NEXT_FIRE_TIME ,PREV_FIRE_TIME,NEXT_FIRE_TIME-PREV_FIRE_TIMEfrom QRTZ_TRIGGERSwhere NEXT_FIRE_TIME-PREV_FIRE_TIME=86400000*2
原理就是根据quartz的元数据表QRTZ_TRIGGERS的上一次调度时间PREV_FIRE_TIME和下一次调度时间NEXT_FIRE_TIME的差值进行监控。如果差值为24小时就正常,如果差值为48小时,就说明出现了漏调度。
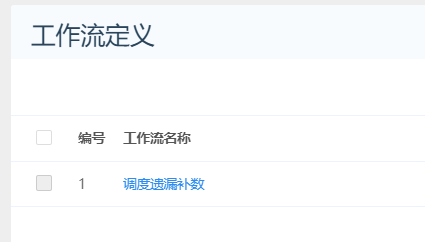
如果已经发生了漏调度如何紧急处理? 我们实现了漏调度补数逻辑通过自定义工作流进行http接口调用。如果监控到发生了漏调度情况,可以立即运行此工作流,就能把漏调度的工作流立即调度运行起来。
03 Worker服务卡死
这个现象是凌晨调度Worker所在机器内存占用飙升至90%多,服务卡死。
我们思考产生该问题的原因是,调度worker判断本机剩余内存时,有漏洞。比如我们设置worker服务剩余内存为25G时,不进行任务调度。但是,当worker本机剩余内存为26G时,服务判断本机剩余内存未达到限制条件,那么开始从zk队列中抓取任务,每次抓取10个。而每个spark的driver占用2G内存,那么本地抓取的10个任务在未来的内存占用为20G。我们可以简单计算得出本机剩余内存为26G-20G为6G,也就是说抓取了10个任务,未来的剩余内存可能为6G,会面临严重不足。
为了解决这个问题,我们参考Yarn,提出了”预申请”机制。预申请的机制是,判断本机剩余内存时,会减去抓取任务的内存,而不是简单判断本机剩余内存。
如何获取将要抓取任务的内存数呢? 有2种方式,第一种是在创建工作流时指定本任务driver占用的内存,第二种是给一个固定平均值。
我们综合考虑,采用了第二种方式,因为对于用户来说,是没有感知的。我们对要抓取的每个任务配置1.5G(经验值)内存,以及达到1.5G内存所需要的时间为180秒,抓取任务后,会放入缓存中,缓存过期时间为180(经验值)秒。剩余内存计算公式,本机剩余内存=本机真实物理剩余内存-缓存中任务个数1.5G+本次准备抓取的任务数1.5G 。
还是同样的场景,本机配置的剩余内存为25G,本机实际剩余内存为26G,要抓取的任务为10个。每个任务未来占用的driver内存为1.5G。简单计算一下,本机剩余内存=26G-10*1.5G。在“预申请”机制下,本机剩余内存为1G,小于25G,不会抓取,也就不会导致Worker机器的内存占用过高。那么会不会导致Worker服务内存使用率过低呢,比如shell、python、DataX等占用内存低的任务。结论是不会,因为我们有180秒过期机制,过期后,计算得到的本机剩余内存为变高。
根据同样的原理,CPU占用,我们也加上了同样的机制,给每个要抓取的任务分配一定的cpu负载值。
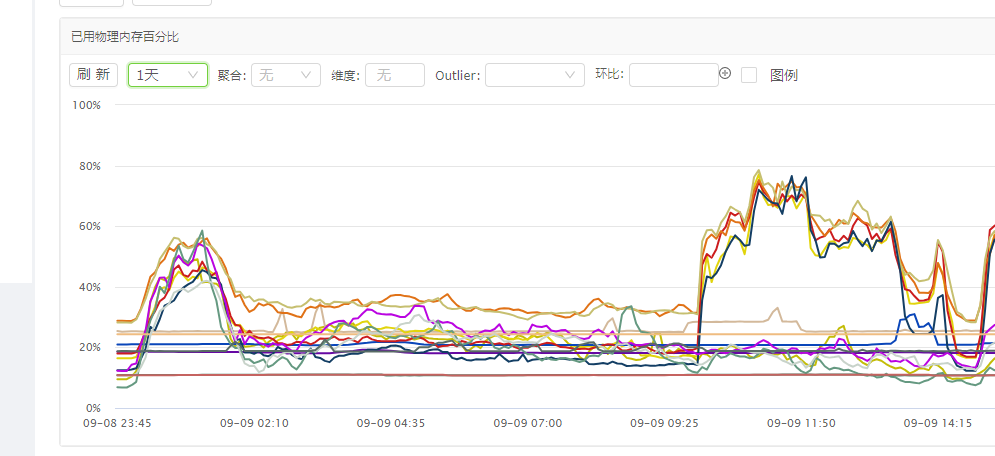
加上内存预申请后,最近半年,没有遇到由于内存占用过高导致worker服务卡死的问题。以下是我们加上内存预申请机制后,worker内存使用率情况,可以看见worker最大内存使用率始终稳定保持在80%以下。
04 任务重复运行
在worker服务卡死时,我们发现yarn上的任务没有被杀死,而master容错时导致任务被重复提交到yarn上,最终导致用户的数据异常。
我们分析后发现,任务实例有一个app_link字段,存放用户提交的yarn任务的app id,而第一次调度的任务的app id为空。排查代码发现worker在运行任务时,只有完成的yarn 任务,才会更新app_link字段。这样导致master在容错时,拿不到app id,导致旧任务没有被杀死,最终导致任务重复提交。
我们进行的第一个改进点为,在worker运行yarn任务时,从log中实时过滤出app id,然后每隔5秒将app id更新到app_link字段中。 这样yarn任务在运行时,也就能获取到app id,master容错时就能杀死旧任务。
第二个改进点为,在worker服务卡死从而自杀时,杀死本机上正在运行的调度服务,这样可能master就不需要进行容错了。
实施这个方案后,最近半年没有遇到重复调度的yarn任务了。
05 弱依赖

运营标签对于时效性要求很高,关系到广告投放效果。他们提出了一个需求,他们对于某些依赖工作流,不是强依赖的,如果该父工作流在服务器托管网约定的时间没有完成,那么就不进行依赖。为了实现这个需求,我们引入了弱依赖的机制。旧依赖模式,我们定义为强依赖,如果该工作流在约定周期没有运行完成,那么永远不能依赖成功。而弱依赖,会等待到某个时间,如果还没有完成,那么也会成功。
06 虚拟节点
我们调度集群是双机房运行的,因此有些核心工作流是运行在2个机房的。比如有些数仓ads相关工作流是输出hive数服务器托管网据到mysql表的,而mysql数据源来不及双数据源,只有一个mysql。因此主集群导入数据到mysql表,从集群就不应该导入数据到mysql表中。因此我们实现了虚拟节点的功能,实现的目标是,此节点在主集群真实运行,在从集群虚拟运行。
07 任务的yarn队列动态切换
我们的yarn队列是根据大业务线进行划分的,队列个数并不多。我们对于用户的调度任务稳定性需要保障,而经常需要到的一个情况是,yarn的队列经常被补数任务占用过多,导致用户正常的调度任务提交不上去。
因此,我们提出了任务的yarn队列动态切换方案。 原理就是当用户补数时,数据开发平台根据用户所属业务线,找到该用户所属的yarn队列名称,然后将该队列名称提交到全局变量中。调度worker在对该任务进行调度时,会判断该全局变量是否有值,如果有就进行替换。
通过该方案,我们实现了调度任务在正常队列中运行,而补数任务进入补数的小队列中运行。从而保证了正常调度任务的时效性和稳定性。
08 实例分页查询接口优化
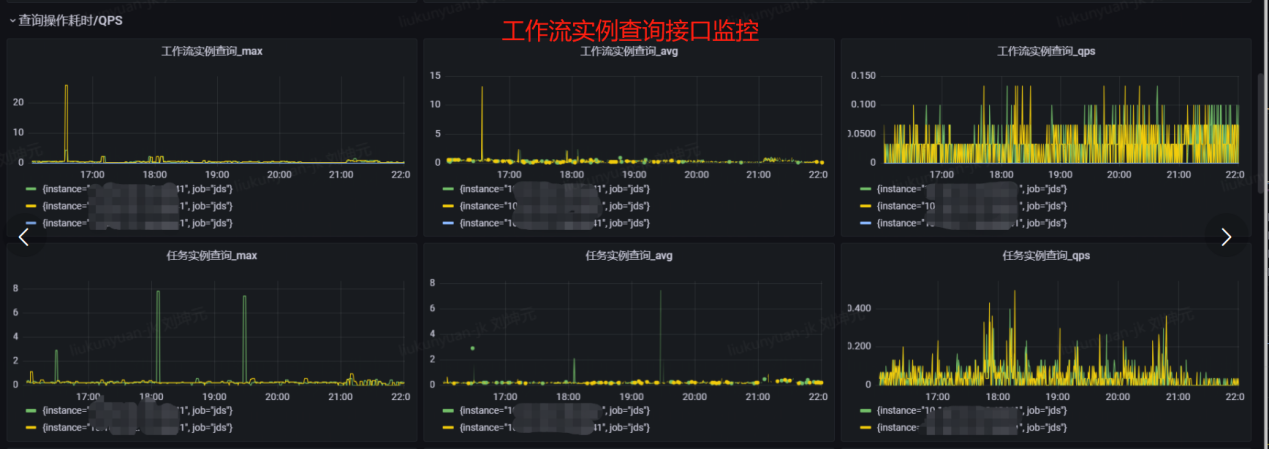
每天调度的任务实例有14万多,我们保留了2个月数据,那么任务实例的记录数约为1000多万条。而DolphinScheduler查询工作流实例和任务实例有join关系,需要通过join查询project_id,在查询一些大的项目的任务实例时,耗时最大为几分钟甚至直接卡死。
我们提出的解决方案是,通过字段冗余,在工作流实例和任务实例中存储project_id,将join分页查询改为单表分页查询。 优化后,大项目的任务实例分页查询p99耗时从几分钟降低到200ms。
09 Worker维护模式
在worker发版时,我们不应该影响用户调度的任务。因此,我们实现了worker的维护模式。当worker开启维护模式时,该worker不会再新抓取任务,而已经抓取的任务继续运行,从而不影响用户的调度任务。过4小时后,判断该worker上任务运行完成,再对该worker进行jar包替换和重启服务。通过这种方式,我们能够做到DolphinScheduler发版对用户的调度任务无影响,用户无感知。
10 worker和nodemanager混部
随着业务发展,公司每天调度的工作流实例越来越多,worker服务经常内存不足,需要申请大内存的机器作为worker调度机。不过,面临着降本增效的压力,我们思考DolphinScheduler的worker服务能不能和yarn的nodemanager进行混合部署,因为我们的yarn集群有1000多台机器。我们希望通过这种方式达到不用申请新的机器,从而降低成本的目标。
我们的解决方案如下,新扩容worker服务在nodemanager上,在晚上23点,通过yarn命令将该混部的nodemanager可用内存调低为1核4G,从而停止yarn将任务调度到该机器上,然后调用api接口,关闭该worker的维护模式,让该worker调度ds分配的任务。在早上10点,通过调用api接口,打开worker的维护模式,从而停止worker调度ds分配的任务,并通过yarn命令将nodemanager的内存和cpu恢复为正常值,从而让yarn分配任务到该机器上。
通过这种方案,我们实现了凌晨该机器给DolphinScheduler的worker使用,白天给yarn的nodemanager使用,从而达到降本增效的目标。 新扩容的worker,我们都采用了这种方式。
四、服务监控
一个稳定的系统,除了代码上的优化,一定离不开完善的监控。而DolphinScheduler服务在每天调度这么大量时,我们作为开发和运维人员需要提前知道调度系统和任务健康状况。因此根据我们的经验,我们在DolphinScheduler服务的监控方向做了如下事情。
01 方法耗时监控
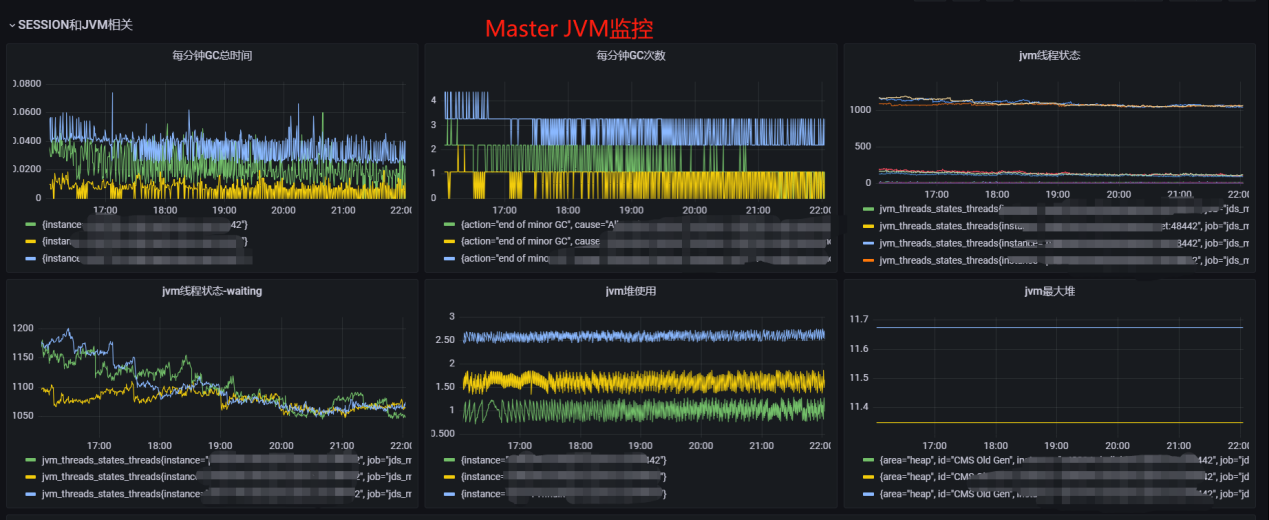
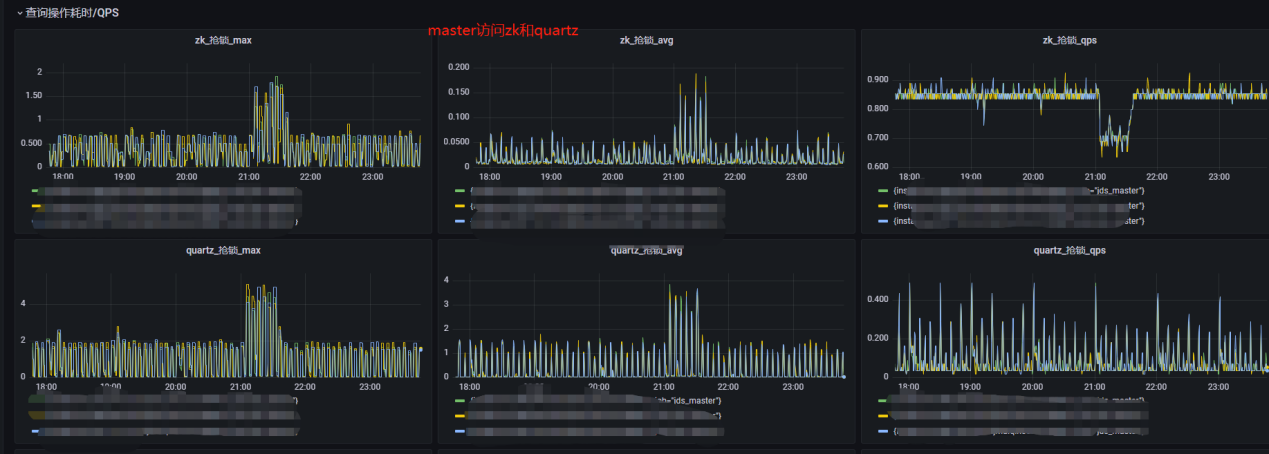
我们通过byte-buddy、micrometer等,实现了自定义轻量级java agent框架。这个框架实现的目标是监控java方法的最大耗时、平均耗时、qps、服务的jvm健康状况等。并把这些监控指标通过http暴露出来,然后通过prometheus抓取,最后通过grafana进行展示,并根据prometheus指标进行告警。以下是master访问zk和quartz的最大耗时,平均耗时,qps等。
以下是master服务的jvm监控指标

通过该java agent,我们做到了api、master、worekr、zookeeper等服务方法耗时监控,多次提前发现问题,避免将问题扩大到用户感知的状况。
02 任务调度链路监控
为了保障调度任务的稳定性,有必要对任务调度的生命周期进行监控。我们知道DolphinScheduler服务调度任务的全流程是先从quartz中产生command,然后从command到工作流实例,又从工作流实例再到任务实例。我们就对这个任务链路进行生命周期监控。
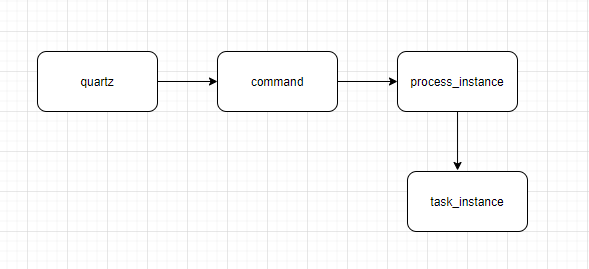
1)监控quartz元数据
前面已经讲了我们通过监控quartz元数据,发现漏调度和重复调度问题。
2)监控command表积压情况
通过监控command表积压情况,从而监控master是否服务正常,以及master服务的性能是否能够满足需求。
3)监控任务实例
通过监控任务实例等待提交时间,从而监控worker服务是否正常,以及worker服务的性能是否能够满足需求。 通过如上全生命周期监控,我们多次提前发现worker服务的性能问题,提前解决,成功避免影响到用户调度服务。
03 日志监控
前面我们通过java agent实现了方法耗时的监控,不过这还不够。因此,我们还通过filebeat采集了3台api、6台master、34台worker的服务日志到我们公司的日志中心,然后对日志进行异常突增告警。
五、用户收益
通过最近一年对DolphinScheduler代码的优化,我们获得的最大收益是近半年没有因为调度服务导致用户的SLA受影响,并多次在调度服务出现问题时,提前解决,没有影响到用户任务的SLA达成率。
六、用户简介
图片
奇富科技(原360数科)是人工智能驱动的信贷科技服务平台,秉承“始于安全、 恒于科技”的初心,凭借智能服务、AI研究及应用、安全科技,赋能金融机构提质增效,助推普惠金融高质量发展,让更多人享受到安全便捷的金融科技服务,助力实现共同富裕。作为国内领先的信贷科技服务品牌,累计注册用户数2亿多。
作者介绍
- 刘坤元
奇富科技数据平台部大数据开发工程师,19年入职奇富科技,目前负责大数据任务调度系统开发和任务治理工作。
- 王洁
奇富科技数据平台部大数据开发工程师,19年入职奇富科技,目前负责大数据任务调度系统开发工作。
本文由 白鲸开源科技 提供发布支持!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
