
一,引言
上一篇文字,我们初步对 Data Flow 有个简单的了解,也就是说可以使用 Data Flow 完成一些复杂的逻辑,如,数据计算,数据筛选,数据清洗,数据整合等操作,那我们今天就结合 Data Flow 中的常用数据转换逻辑拉演示在实际场景中如何实现。
Task1:将数据源的数据进行分组 去重
Task2:去重后的数据进行筛选,过滤
Task3:根据筛选、过滤后的数据派生出新的备注列
Task4:将以上处理过的数据写入到新的 CSV 文件中
——————–我是分割线——————–↳
1,Azure Data Factory(一)入门简介
2,Azure Data Factory(二)复制数据
3,Azure Data Factory(三)集成 Azure Devops 实现CI/CD
4,Azure Data Factory(四)集成 Logic App 的邮件通知提醒
5,Azure Data Factory(五)Blob Storage 密钥管理问题
6,Azure Data Factory(六)数据集类型为Dataverse的Link测试
7,Azure Data Factory(七)数据集验证之用户托管凭证
8,Azure Data Factory(八)数据集验证之服务主体(Service Principal)
9,Azure Data Factory(九)基础知识回顾
10,Azure Data Factory(十)Data Flow 组件详解
11,Azure Data Factory(服务器托管网十一)Data Flow 的使用解析
二,正文
准备数据源
登录到 Azure Portal ,在已有的 storage account 上的 sourcecontainer 上传 csv 文件,如下图所示

使用 DataFlow 进行数据筛选处理
点击 左侧 Data Flow … “new data flow” 创建新的 Data Flow
Name:“FromAzureBlob_DataFlow”
首先添加数据源 “source1”,Dataset 类型选择 “FormAzureBlob”(数据源来自 Azure Blob)

点击 ”Import projection“ 导入整个 csv 文件的架构
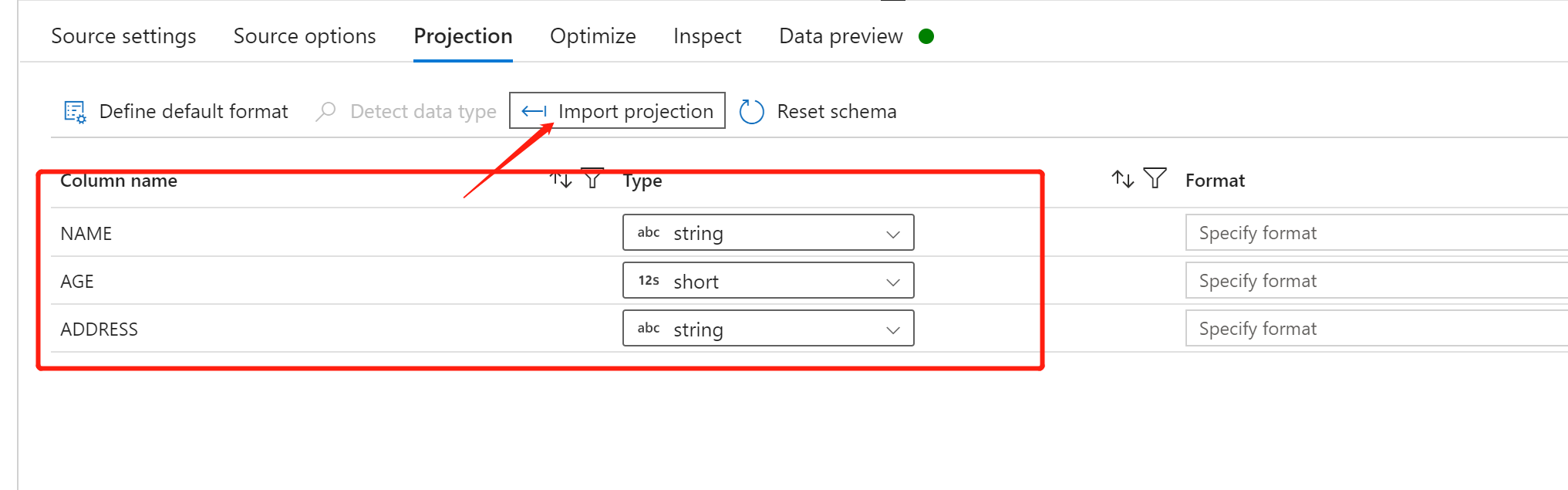
点击 “Refresh” 可以预加载数据

接下添加 “Aggregate” 分组组件,以 ”NAME“ 作为分组依据,其他字段取 max(value)
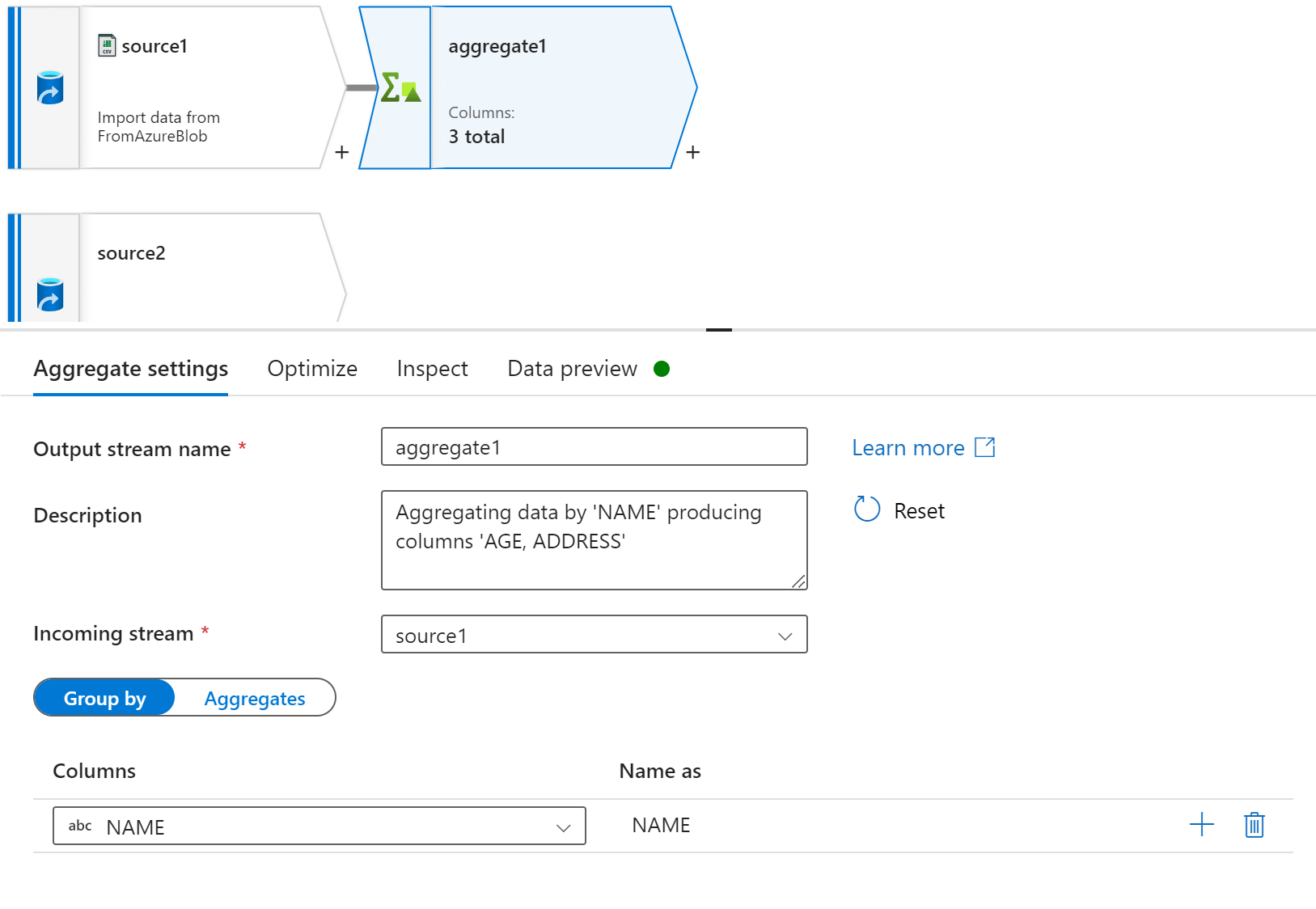
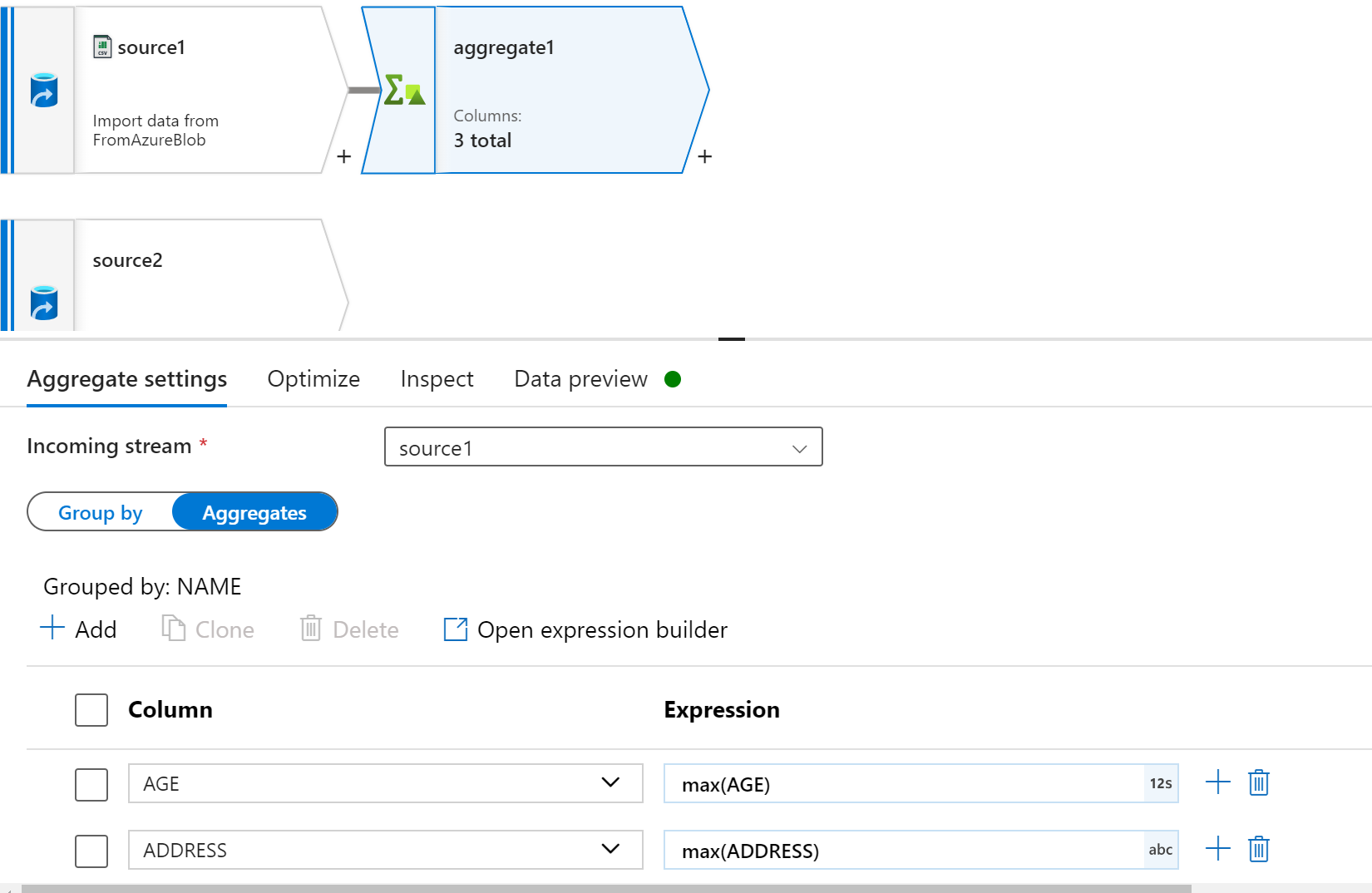
点击 Data preview 页面的 ”Refresh“ 进行刷新操作
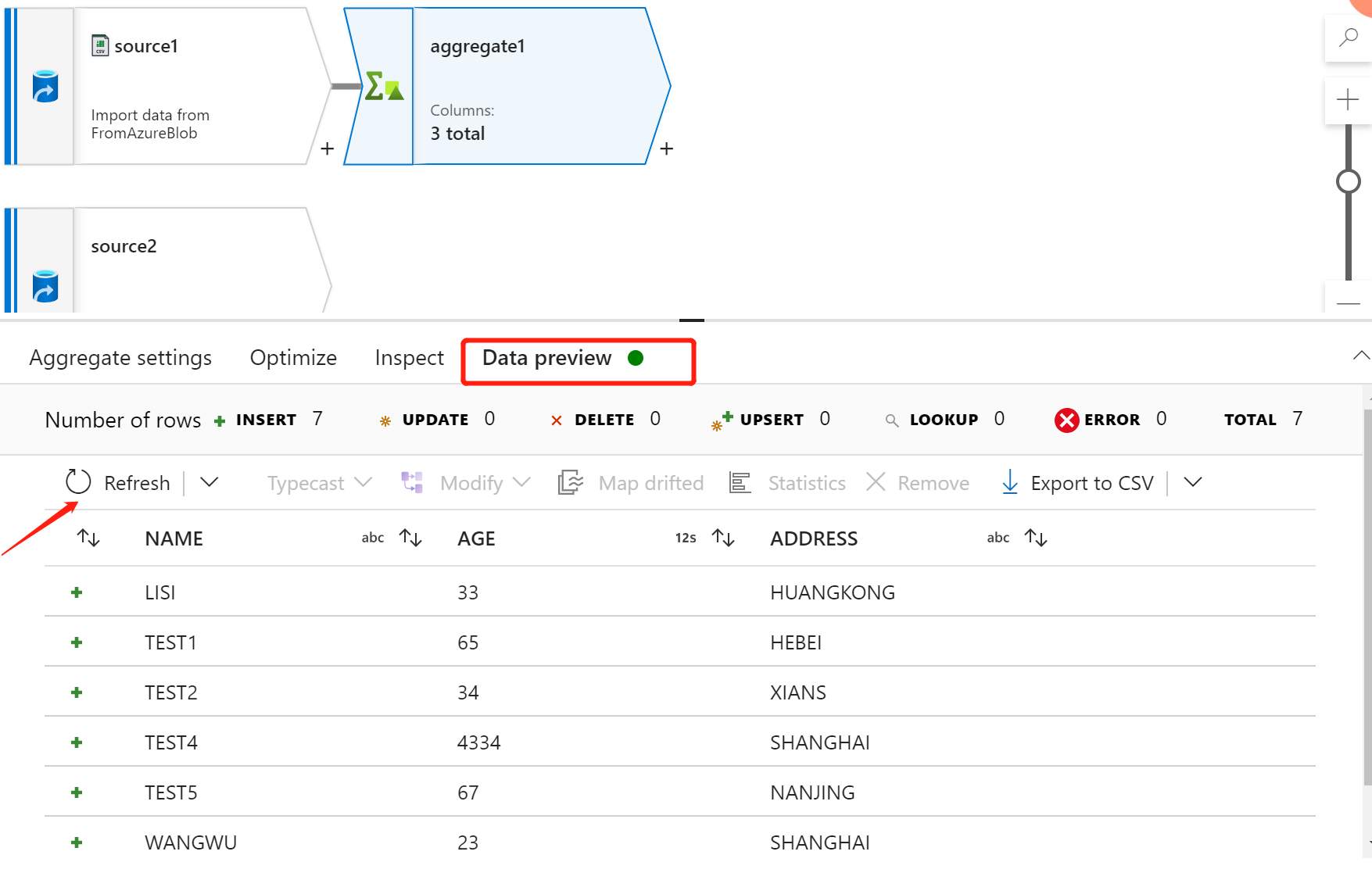
添加 ”Filter“ 组件进行过滤 AGE >30 & AGE
Incoming stream:aggregate1
Filter On:AGE > 30
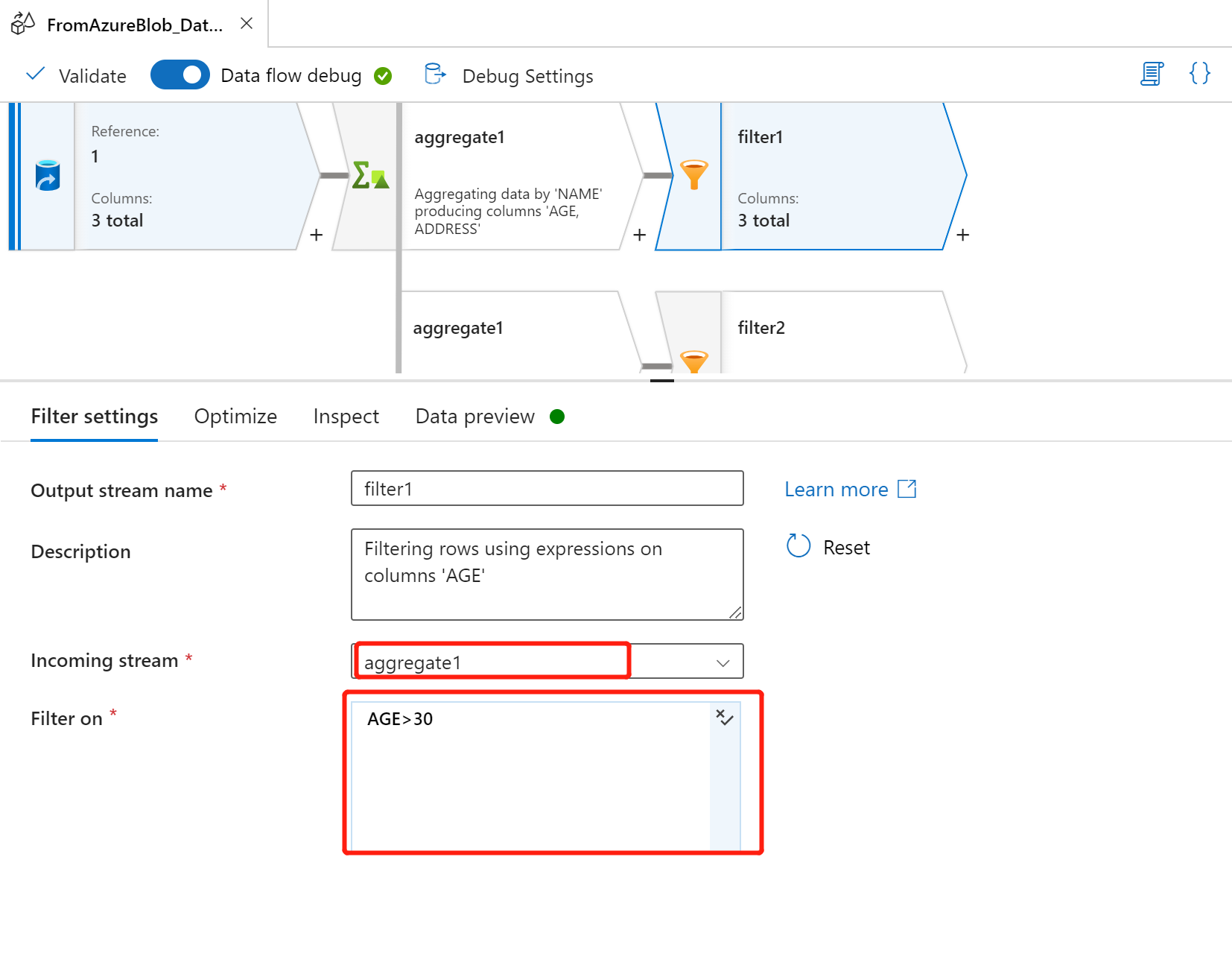
Incoming stream:aggregate1
Filter On:AGE
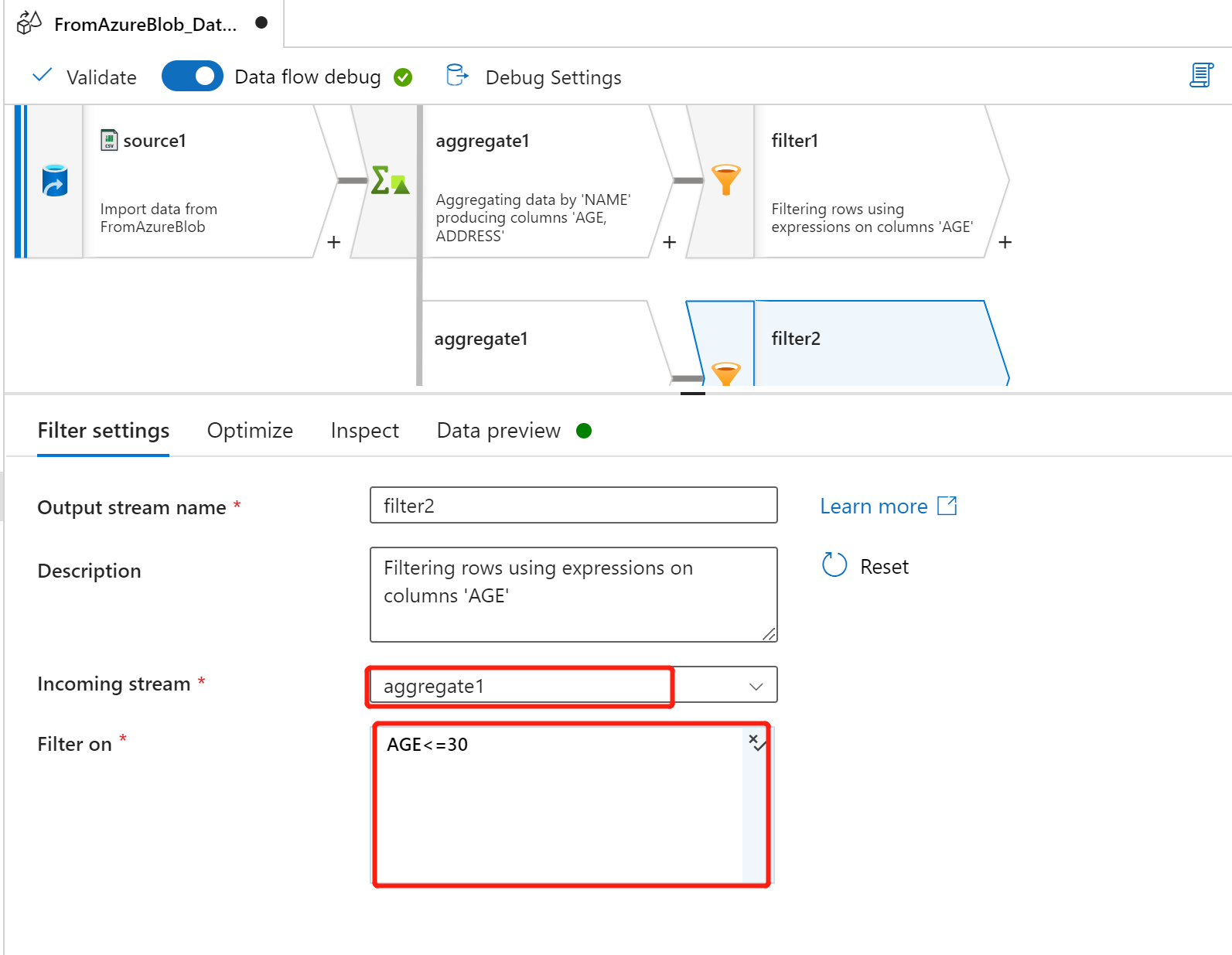
根据 AGE 派生出新的列 REMARK
AGE >30
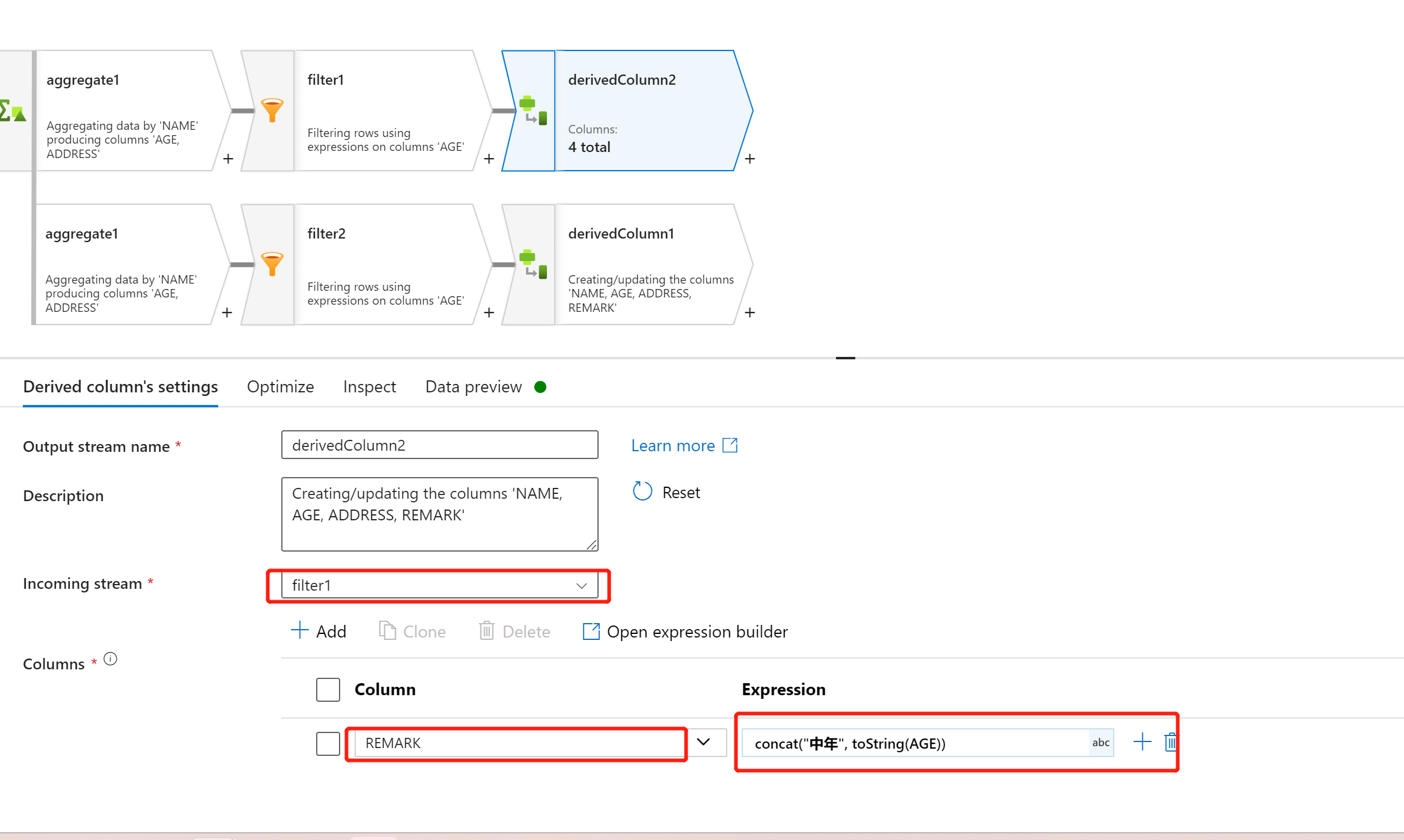
AGE
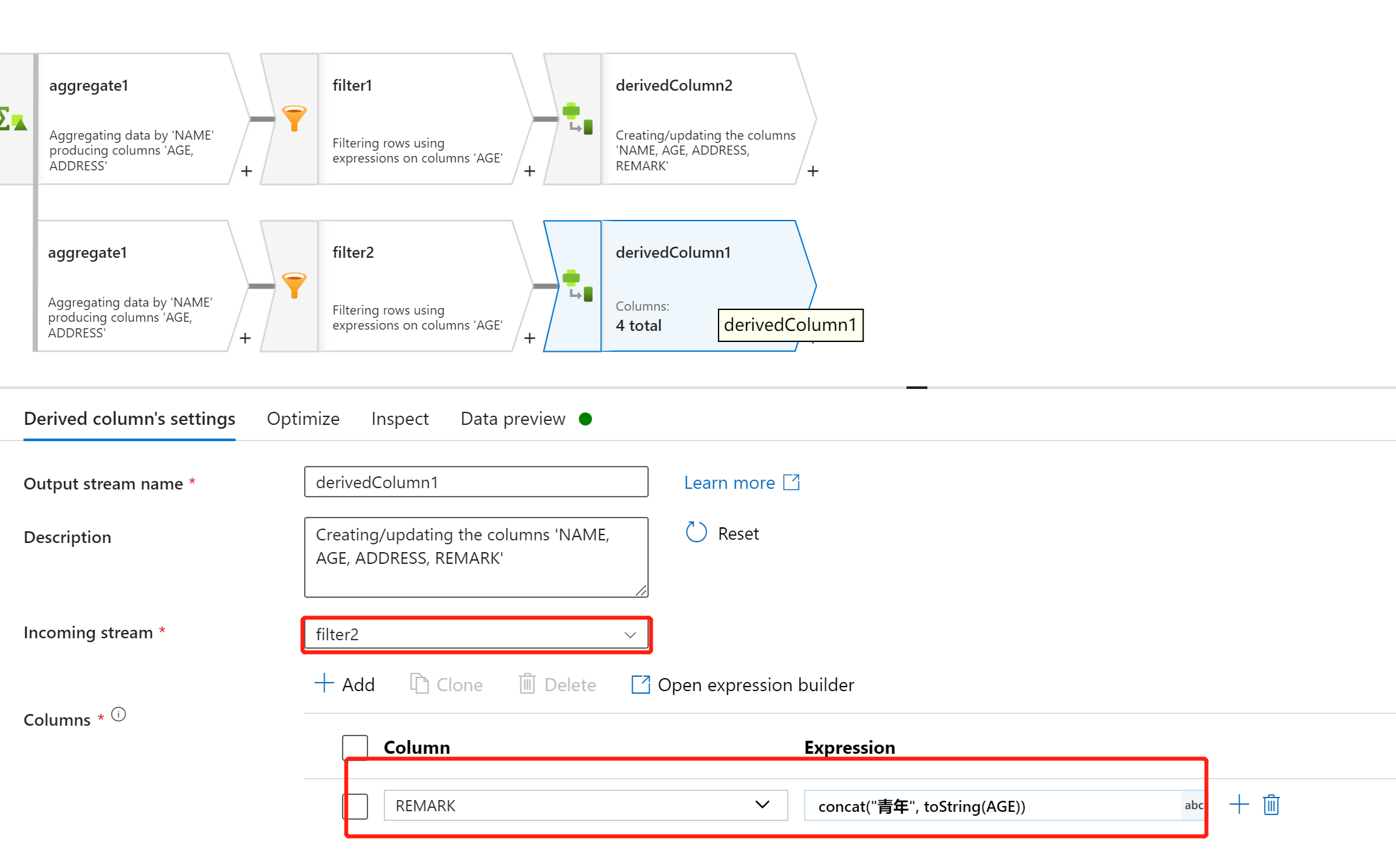
使用 ”union“ 将两组拆分计算好的逻辑的整合
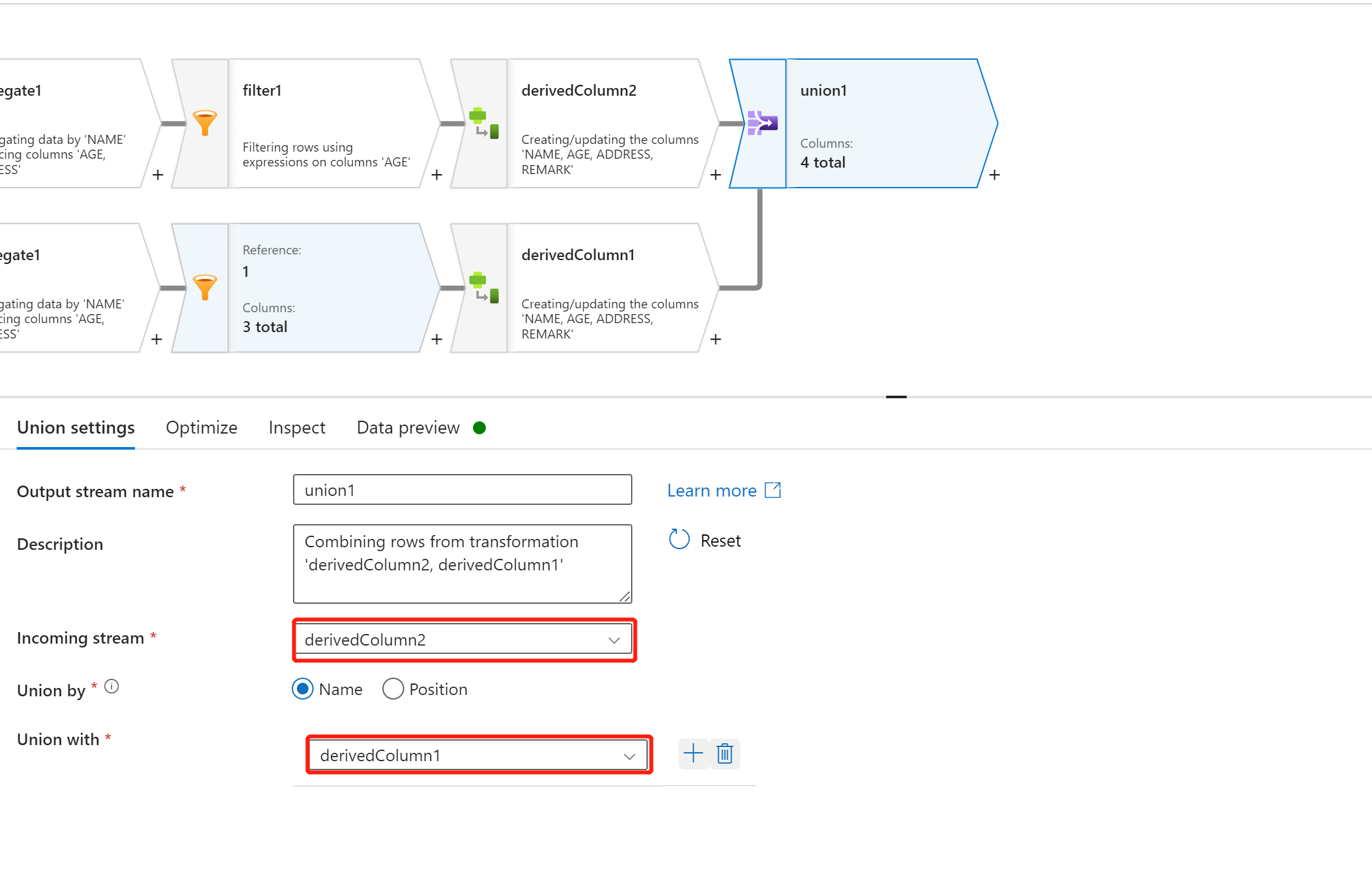
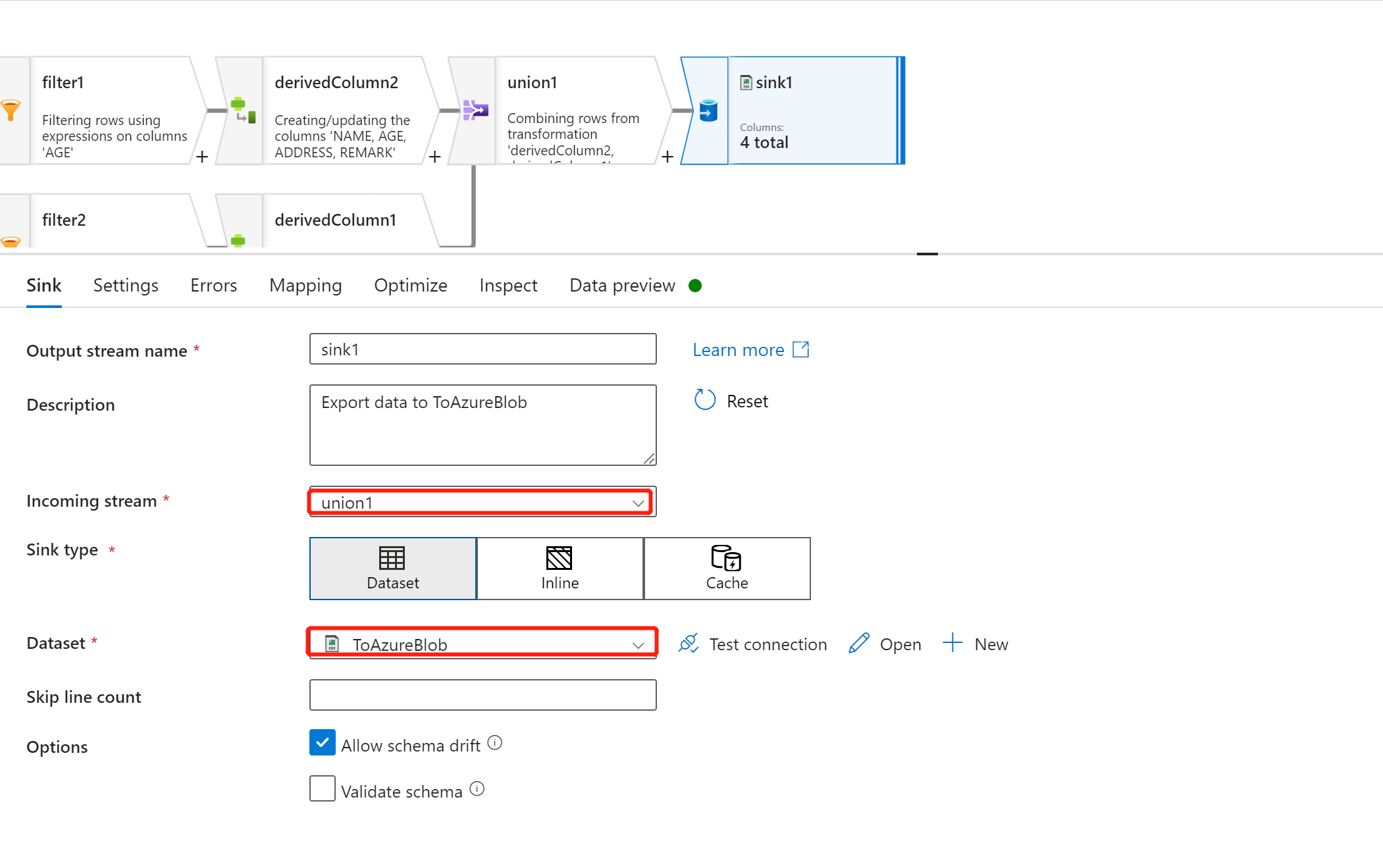
最后,使用 ”sink“ 将数据写入到新的目标数据集中
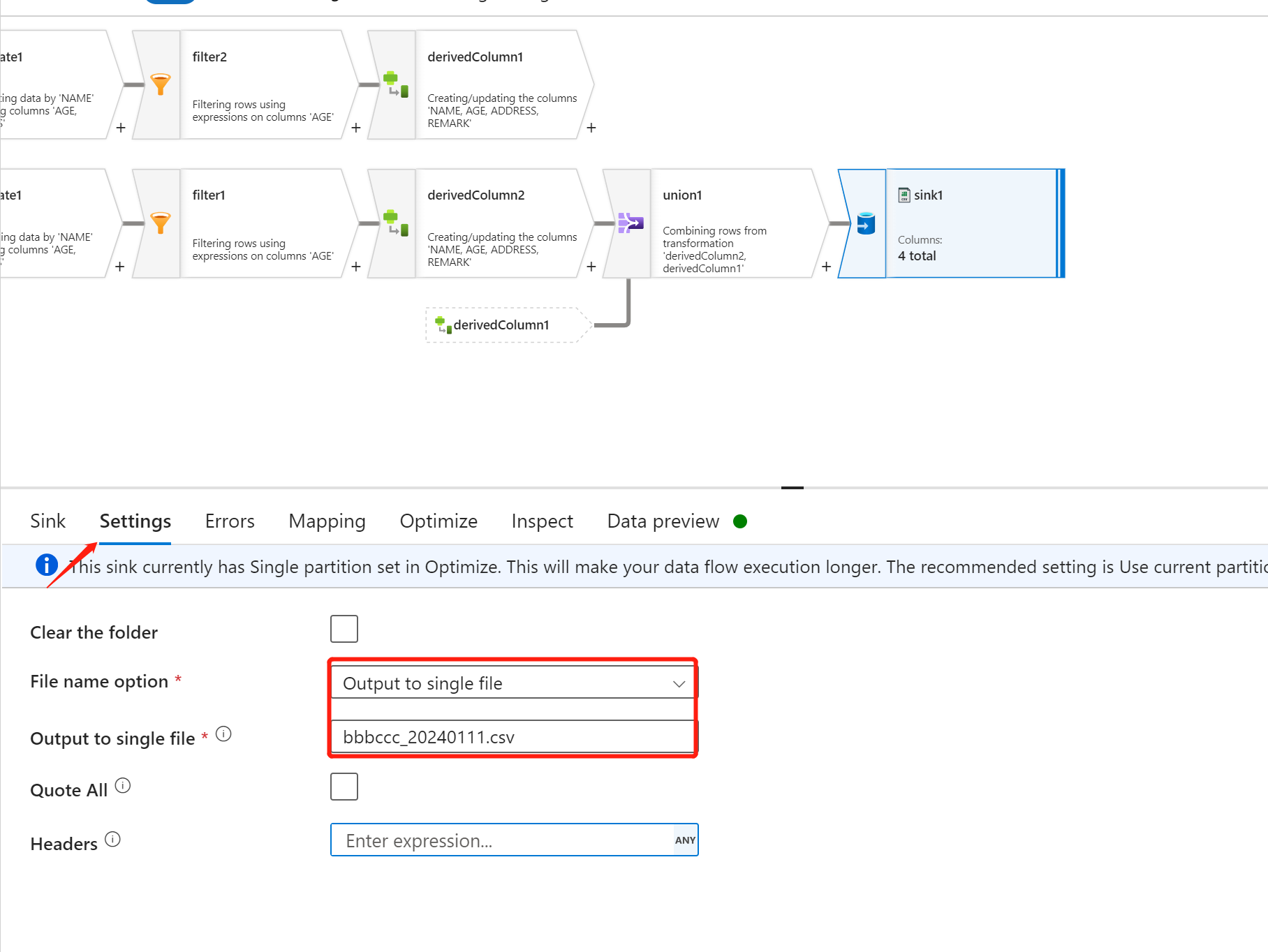
Settings 页面设置,将数据整合成一个文件输出
Mapping 关于如下图所示
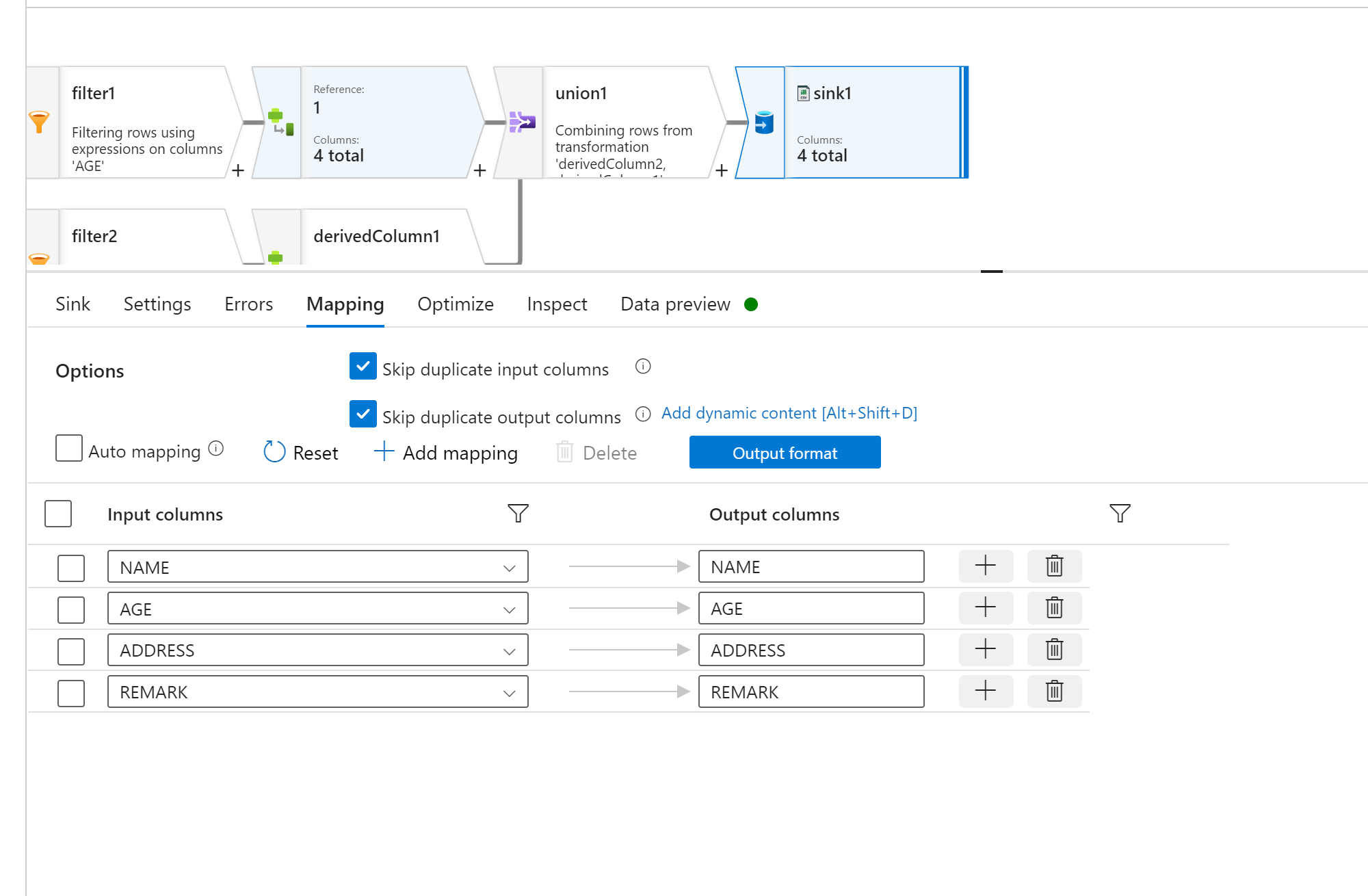
测试
新建 pipeline,添加 Data Flow 组件,输入以下参数
Settings =》Data flow 选择 ”FromAzureBlob_DataFlow“
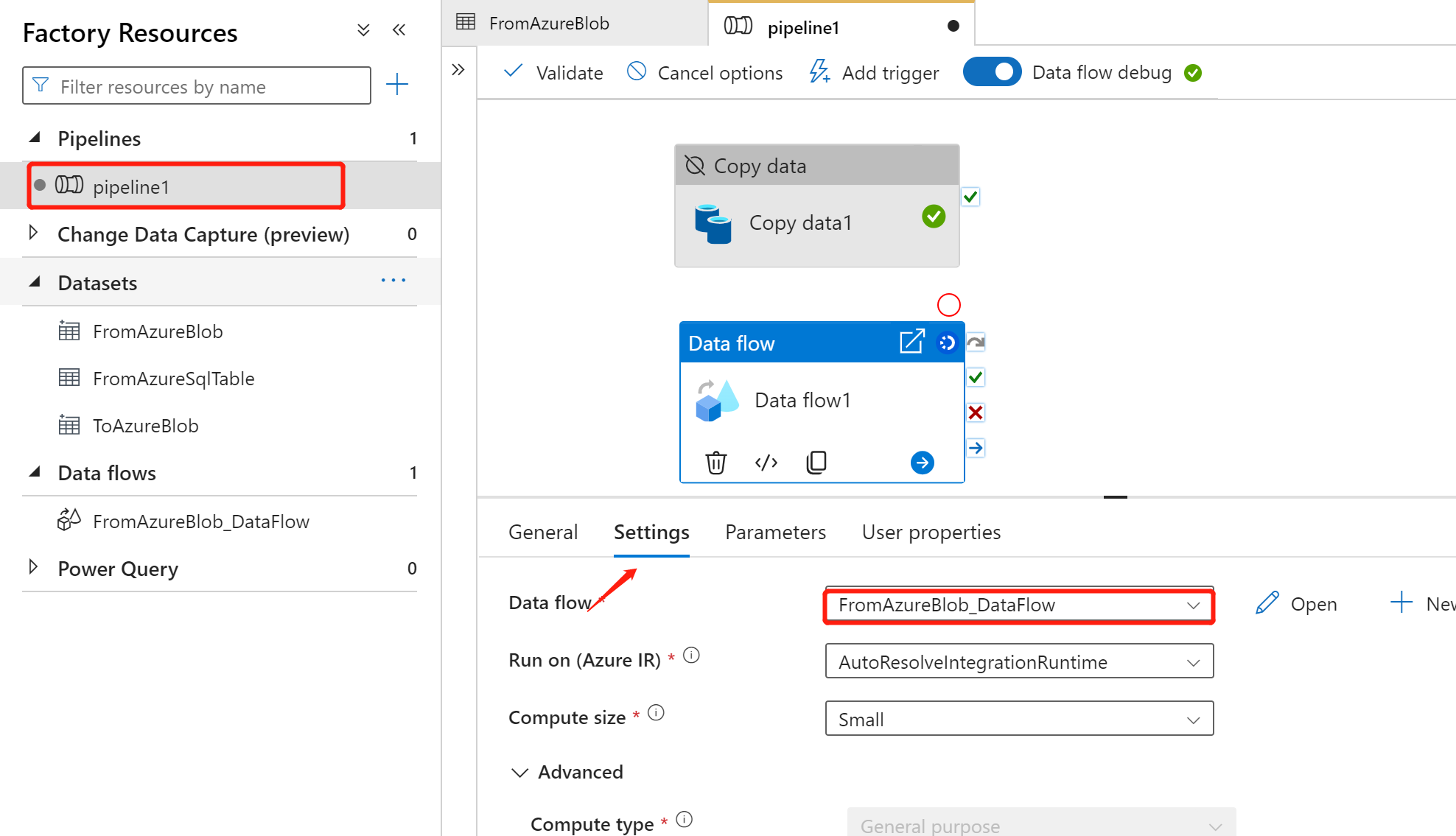
点击 ”Debug“ 进行调试,可以看到 ouput 输出中的 dataflow 允许程序
冷知识:Data Flow 所使用的 Azure IR 为 ”AutoResolveIntegrationRuntime“ 也就是微软托管机器,需要经历 创建、启动的过程

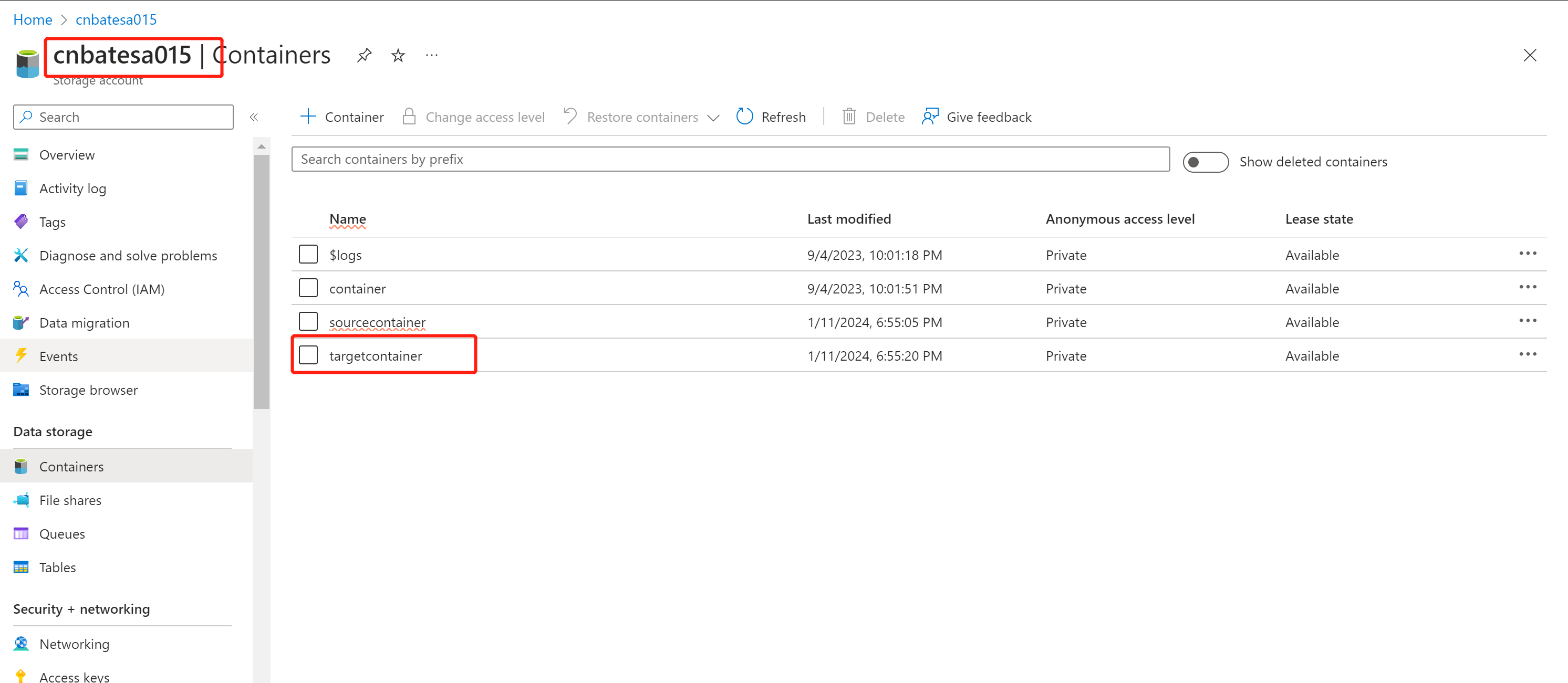
最后,我们打开新的 csv 文件,查询刚刚在 data flow 中编写的数据清洗的逻辑是否正常
找到 ”targetcontainer“ ,点击进去 container 内部
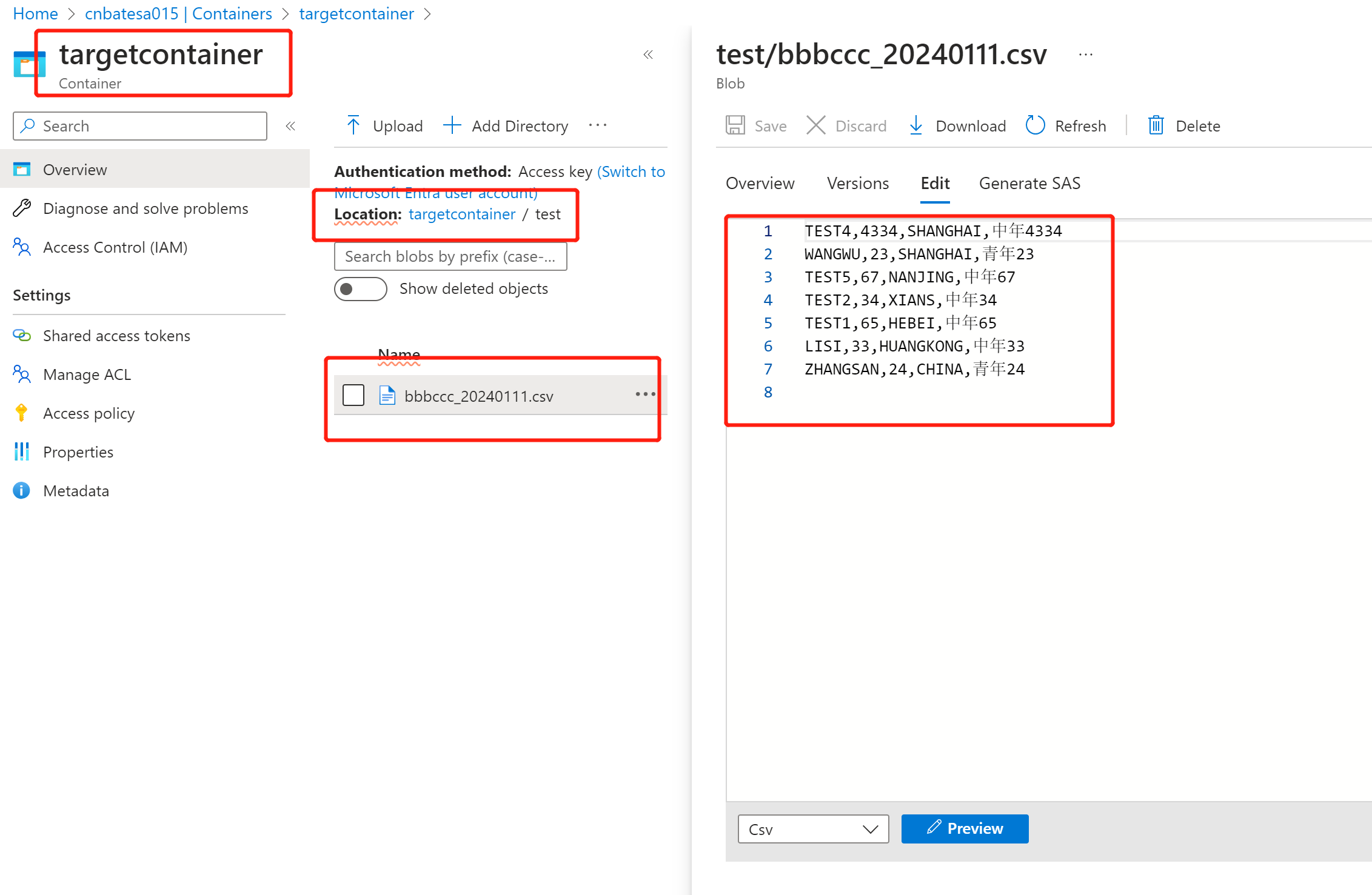
以下是输入的新的 csv 文件
三,结尾
今天我们通过一些了操作演示,展示了 Azure Data Flow 对数据的处理,绝大多数的数据处理,通过这些丰富的组件就可以轻松完成分析、计算任务。从而提高数据处理效率和质量
参考连接:Azure 数据工程中的的映射数据流
作者:Allen
版权:转载请在文章明显位置注明作者及出处。如发现错误,欢迎批评指正。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
1.为什么计算机内部采用二进制表示信息? 答:主要有3个方面的原因 (1)二进制系统只有两个基本符号:0和1所以,它的基本符号少,易于用稳态电路实现。 (2)二进制的编码、记数、运算等规则简单。 (3)二进制中的0和1与逻辑命题的“真”和“假”的对应关系简单,…
