
一、背景
为了解决应卡顿,分析耗时。
二、原理
Looper中的loop方法:
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("可以看到在执行消息的时候,如果有设置logging,那么它会在消息开始与结束的时候打印出相关信息。如果主线程卡住了,就是在dispatchMessage这里卡住,所以我们可以通过计算这两条log的时间差来判断消息的执行时间。
我们可以通过这个方法来设置Printer。
Looper.getMainLooper().setMessageLogging(mainLooperPrinter);
三、源码解析
application中调用初始化:
BlockCanary.install(this, AppBlockCanaryContext()).start()
最终会执行到:
private BlockCanary() {
BlockCanaryInternals.setContext(BlockCanaryContext.get());
mBlockCanaryCore = BlockCanaryInternals.getInstance();
mBlockCanaryCore.addBlockInterceptor(BlockCanaryContext.get());
if (!BlockCanaryContext.get().displayNotification()) {
return;
}
mBlockCanaryCore.addBlockInterceptor(new DisplayService());
}
核心就是mBlockCanaryCore = BlockCanaryInternals.getInstance();它会对BlockCanaryInternals进行初始化。
public BlockCanaryInternals() {
stackSampler = new StackSampler(
Looper.getMainLooper().getThread(),
sContext.provideDumpInterval());
cpuSampler = new CpuSampler(sContext.provideDumpInterval());
setMonitor(new LooperMonitor(new LooperMonitor.BlockListener() {
@Override
public void onBlockEvent(long realTimeStart, long realTimeEnd,
long threadTimeStart, long threadTimeEnd) {
// Get recent thread-stack entries and cpu usage
ArrayList threadStackEntries = stackSampler
.getThreadStackEntries(realTimeStart, realTimeEnd);
if (!threadStackEntries.isEmpty()) {
BlockInfo blockInfo = BlockInfo.newInstance()
.setMainThreadTimeCost(realTimeStart, realTimeEnd, threadTimeStart, threadTimeEnd)
.setCpuBusyFlag(cpuSampler.isCpuBusy(realTimeStart, realTimeEnd))
.setRecentCpuRate(cpuSampler.getCpuRateInfo())
.setThreadStackEntries(threadStackEntries)
.flushString();
LogWriter.save(blockInfo.toString());
if (mInterceptorChain.size() != 0) {
for (BlockInterceptor interceptor : mInterceptorChain) {
interceptor.onBlock(getContext().provideContext(), blockInfo);
}
}
}
}
}, getContext().provideBlockThreshold(), getContext().stopWhenDebugging()));
LogWriter.cleanObsolete();
}
- stackSampler:记录栈相关信息
- cpuSampler:记录CPU相关信息
- LooperMonitor:继承Printer
private void setMonitor(LooperMonitor looperPrinter) {
monitor = looperPrinter;
}
当我们调用BlockCanary的start方法的时候,便将其设给了Looper的printer,然后我们便可以在LooperMonitor的print方法里面去记录打印的log的时间。
public void start() {
if (!mMonitorStarted) {
服务器托管网 服务器托管网 mMonitorStarted = true;
Looper.getMainLooper().setMessageLogging(mBlockCanaryCore.monitor);
}
}
核心代码:
@Override
public void println(String x) {
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump();
}
}
在开始执行消息的时候去记录相关信息,结束消息的时候停止记录相关信息,并且判断消息执行的时间是否超过了我们设置的阈值,超过了的话便执行notifyBlockEvent(endTime);取出记录的相关消息提示用户。
说到此处,想到是不是可以用mainLooperPrinter来做更多事情呢?既然主线程都在这里,那只要parse出app包名的第一行,每次打印出来,是不是就不需要打点也能记录出用户操作路径? 再者,比如想做onClick到页面创建后的耗时统计,是不是也能用这个原理呢? 之后可以试试看这个思路(目前存在问题是获取线程堆栈是定时3秒取一次的,很可能一些比较快的方法操作一下子完成了没法在stacktrace里面反映出来)。
我们看一下怎么记录栈以及cpu的消息的。
private void startDump() {
if (null != BlockCanaryInternals.getInstance().stackSampler) {
BlockCanaryInternals.getInstance().stackSampler.start();
}
if (null != BlockCanaryInternals.getInstance().cpuSampler) {
BlockCanaryInternals.getInstance().cpuSampler.start();
}
}
StackSampler与CpuSampler都继承与AbstractSampler:
AbstractSampler里面的start方法:
public void start() {
if (mShouldSample.get()) {
return;
}
mShouldSample.set(true);
HandlerThreadFactory.getTimerThreadHandler().removeCallbacks(mRunnable);
HandlerThreadFactory.getTimerThreadHandler().postDelayed(mRunnable,
BlockCanaryInternals.getInstance().getSampleDelay());
}
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
doSample();
if (mShouldSample.get()) {
HandlerThreadFactory.getTimerThreadHandler()
.postDelayed(mRunnable, mSampleInterval);
}
}
};
long getSampleDelay() {
return (long) (BlockCanaryInternals.getContext().provideBlockThreshold() * 0.8f);
}
它其实是开了一个子线程每隔一定的时间就去记录。
四、流程图
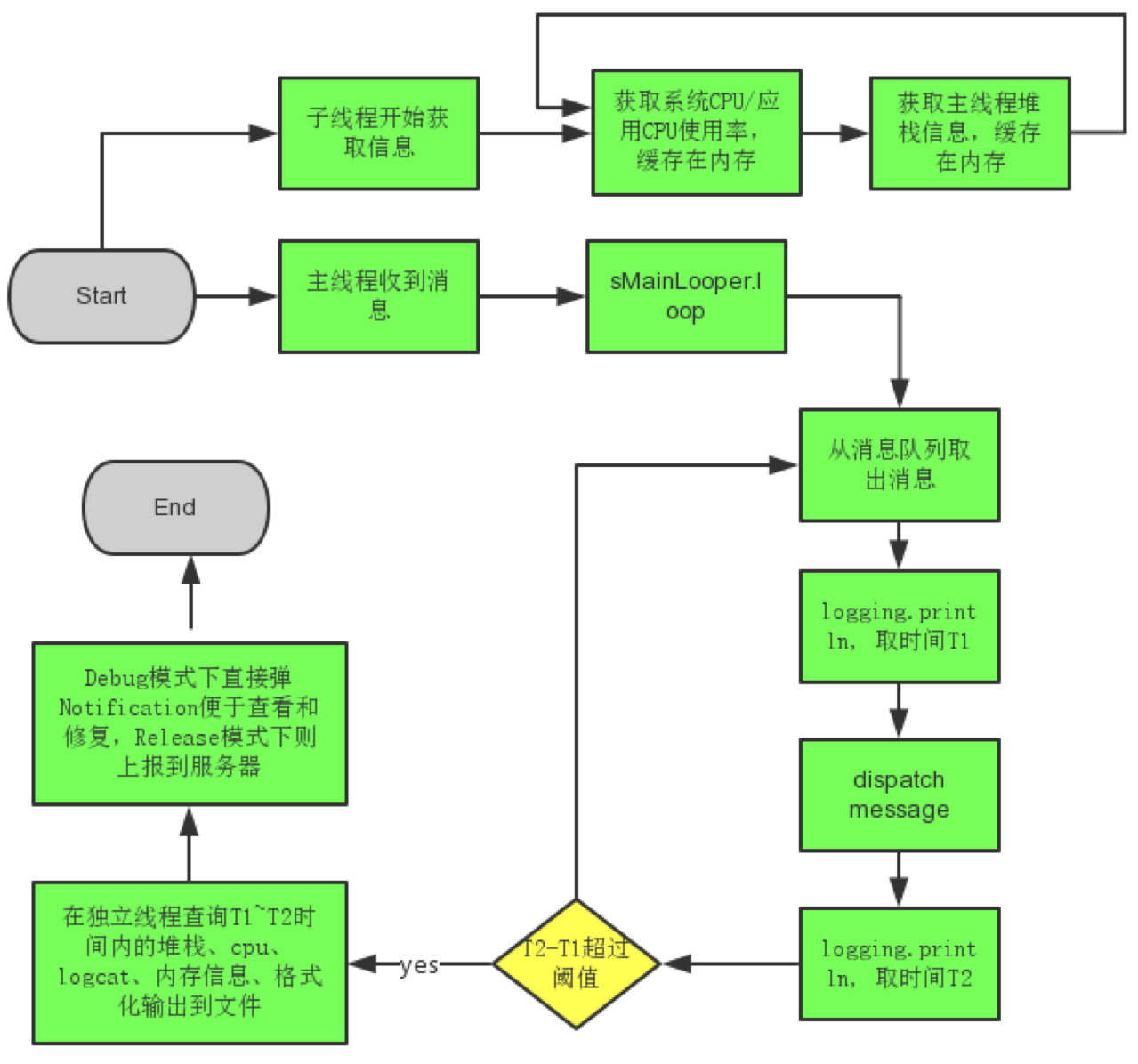
五、总结
BlockCanary作为一个Android组件,目前还有局限性,因为其在一个完整的监控系统中只是一个生产者,还需要对应的消费者去分析日志,比如归类排序,以便看出哪些卡慢更有修复价值,需要优先处理;又比如需要过滤机型,有些奇葩机型的问题造成的卡慢,到底要不要去修复是要斟酌的。扯远一点的话,像是埋点除了统计外,完全还能用来做链路监控,比如一个完整的流程是A -> B -> D -> E, 但是某个时间节点突然A -> B -> D后没有到达E,这时候监控平台就可以发出预警,让开发人员及时定位。很多监控方案都需要C/S两端的配合。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
核心操作:一棵树、一张表、三个接口 相关案例 #include #include #include #include #include #include #include #include #include #include #include /* Accor…
