
常用的无序关联容器
在实际问题场景中,除了常见的线性表结构,字符串,排序操作之外,散列表和红黑树也是非常常见的,有很多应用场景都会用服务器托管网到它们。
- 散列表虽然比较占空间,但是它的增删查的都很快,趋近于O(1);
- 红黑树也是一颗二叉排序树,所以入红黑树的数据都是经过排序的,它的增删查时间复杂度都是O(
 ) ,对数时间,比哈希表慢
) ,对数时间,比哈希表慢
但是如果问题场景对数据的有序性有所要求,而且增删查的操作都比较多,那么就适合用红黑树结构,哈希表里面的数据是无序的。
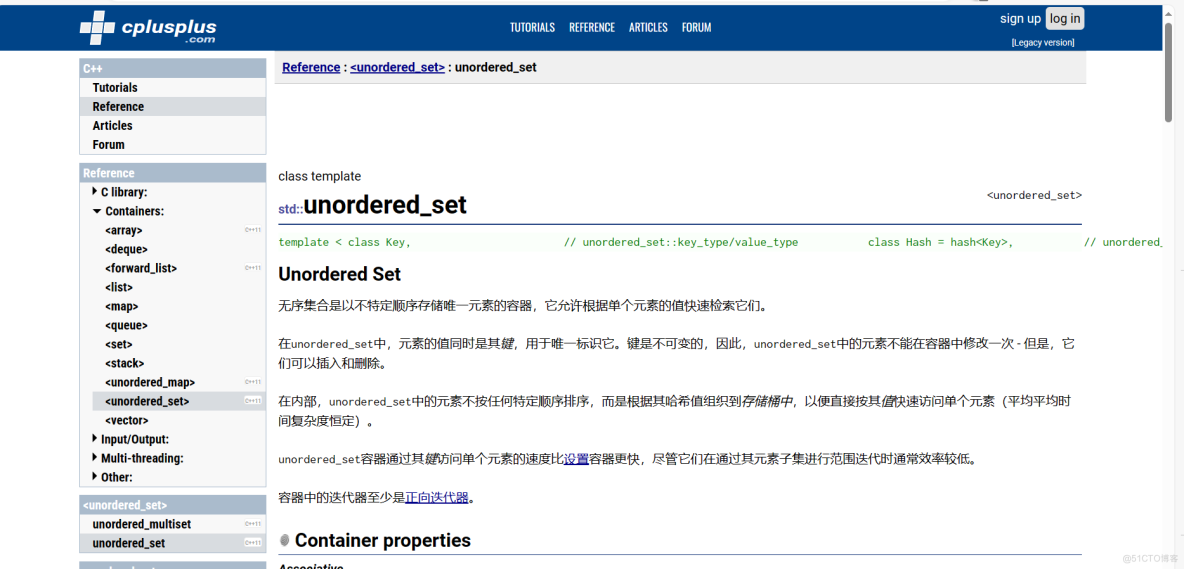
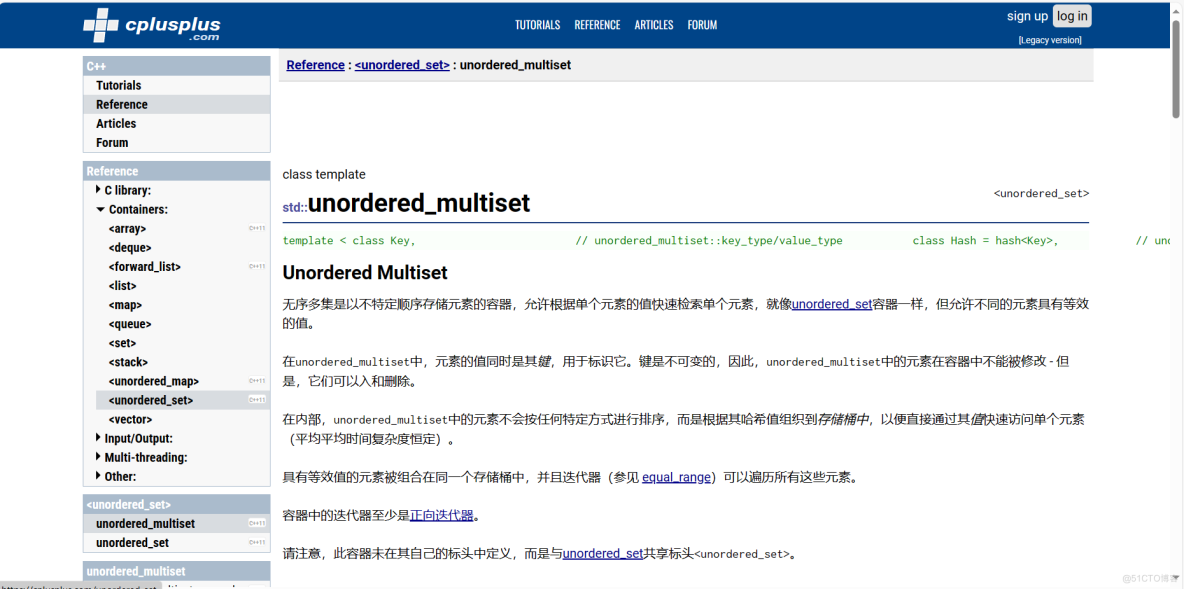
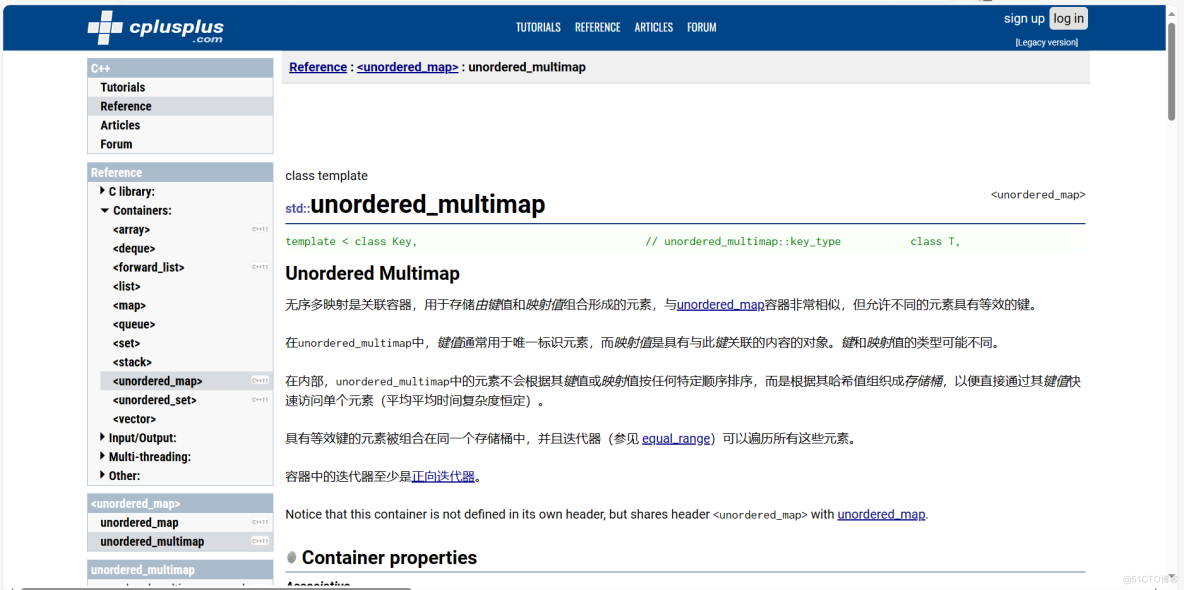
以链式哈希表作为底层数据结构的无序关联容器有:
unordered_set、unordered_multiset、unordered_map、unordered_multimap,对比如下:
|
容器名称 |
存储内容 |
备注 |
常用方法 |
|
unordered_set |
只存储key |
不允许key重复 |
insert(key), erase(key), find(key) |
|
unordered_multiset |
只存储key |
允许key重复 |
insert(key), erase(key), find(key) |
|
unordered_map |
存储key,value对 |
不允许key重复 |
insert({key,value}), erase(key), find(key) |
|
unordered_multimap |
存储key,value对 |
允许key重复 |
insert({key,value}), erase(key), find(key) |
set只存储key,底层是哈希表,经常用来大数据查重复值或者去重复值;
map存储key,value对,经常用来做哈希统计,统计大数据中数据的重复次数,当然它们的应用很广,不仅仅用在海量数据处理问题场景中。
下列代码以unordered_set和unordered_map做一些代码演示
#include
#include
#include
using namespace std;
int main(){
// 不允许key重复 改成unordered_multiset自行测试
unordered_set set1;
for (int i = 0; i 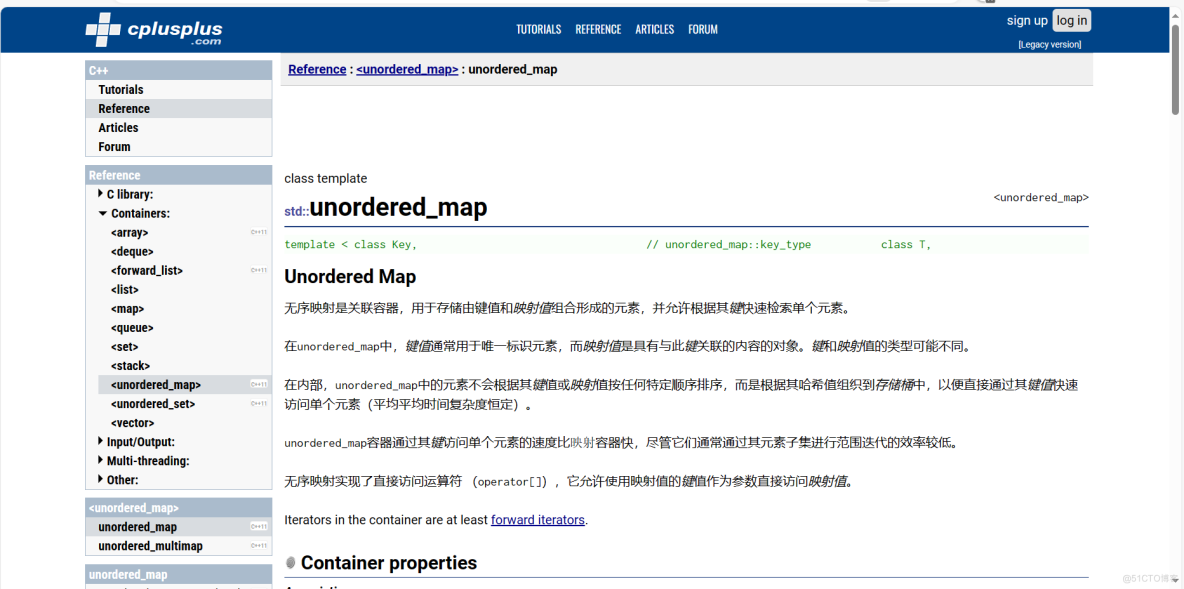
#include
#include
#include
using namespace std;
int main(){
// 定义一个无序映射表
unordered_map map;
// 无序映射表三种添加[key,value]的方式
map.insert({ 1000, "aaa" });
map.insert(make_pair(1001, "bbb"));
map[1002] = "ccc";
// 遍历map表1
auto it = map.begin();
for (; it != map.end(); ++it){
cout first second &pair : map服务器托管网){
cout #include
#include
#include
int main(){
std::unordered_map mymap =
{
{ "house", "maison" },
{ "apple", "pomme" },
{ "tree", "arbre" },
{ "book", "livre" },
{ "door", "porte" },
{ "grapefruit", "pamplemousse" }
};
unsigned n = mymap.bucket_count(); //获取哈希桶的个数
std::cout first second 服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: pytorch分布式数据训练结合学习率周期及混合精度
文章目录 1、SPAWN方式 2、torchrun 方式 正如标题所写,我们正常的普通训练都是单机单卡或单机多卡。而往往一个高精度的模型需要训练时间很长,所以DDP分布式数据并行和混合精度可以加速模型训练。混精可以增大batch size. 如下提供示例代码,…
