
atomic
参考:c++11 多线程(3)atomic 总结 – 简书.c++11 atomic Npgw的博客.C++11 并发指南系列 – Haippy – 博客园.
atomic_flag
atomic_flag看名字就能知道是一种flag类型,它是一种简单的原子布尔类型,只支持两种操作:test-and-set和clear。
创建atomic_flag对象时,如果不初始化,那么该对象的状态就是unspecified,未指定的。(C++11的,C++20后未初始化时为clear)
atomic_flag flag;
可以使用ATOMIC_FLAG_INIT标志初始化对象, 表示对象处于clear状态。转到定义,可以看到该tag的值为0
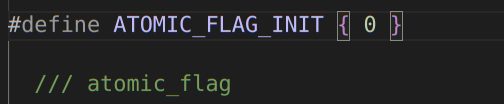
atomic_flag对象只有两种操作,test_and_set就是把atomic_flag的_M_i域置为1,clear则是置零。
功能
test_and_set()的作用是先test测试返回atomic_flag对象的状态,接着set,把对象设置为true。
clear()是直接设置为false,返回类型为void。
原子类型
原子类型需要引用头文件,一个原子类型就是原有类型加上atomic_表示。如int对应的原子类型atomic_int,也可以使用原始格式,是类模板实现的:atomic
其他原子类型还有:
| Typedefs | |
|---|---|
| std::atomic_bool | std::atomic |
| std::atomic_char | std::atomic |
| std::atomic_schar | std::atomic |
| std::atomic_uchar | std::atomic |
| std::atomic_short | std::atomic |
| std::atomic_ushort | std::atomic |
| std::atomic_int | std::atomic |
| std::atomic_uint | std::atomic |
| std::atomic_long | std::atomic |
| std::atomic_ulong | std::atomic |
| std::atomic_llong | std::atomic |
| std::atomic_ullong | std::atomic |
| std::atomic_char16_t | std::atomic |
| std::atomic_char32_t | std::atomic |
| std::atomic_wchar_t | std::atomic |
| std::atomic_int_least8_t | std::atomic |
| std::atomic_uint_least8_t | std::atomic |
| std::atomic_int_least16_t | std::atomic |
| std::atomic_uint_least16_t | std::atomic |
| std::atomic_int_least32_t | std::atomic |
| std::atomic_uint_least32_t | std::atomic |
| std::atomic_int_least64_t | std::atomic |
| std::atomic_int_fast8_t | std::atomic |
| std::atomic_uint_fast8_t | std::atomic |
| std::atomic_int_fast16_t | std::atomic |
| std::atomic_uint_fast16_t | std::atomic |
| std::atomic_int_fast32_t | std::atomic |
| std::atomic_uint_fast32_t | std::atomic |
| std::atomic_int_fast64_t | std::atomic |
| std::atomic_uint_fast64_t | std::atomic |
| std::atomic_intptr_t | std::atomic |
| std::atomic_uintptr_t | std::atomic |
| std::atomic_size_t | std::atomic |
| std::atomic_ptrdiff_t | std::atomic |
| std::atomic_intmax_t | std::atomic |
| std::atomic_uintmax_t | std::atomic |
可以看到主要是一些关于int,short,long,char等在内存中以整数存储的类型,没有float,double等浮点型的。
- 原子类型实现同步的例子:
多线程做累加,如果没有做同步,得到的结果可能是正确的,也可能小于预测值。
- 无同步,直接++计算
#include
#include
#include
using namespace std;
int count;
void counter(){
for(int i=1;i 得到的结果:
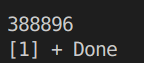
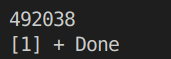
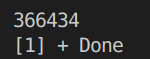
每次结果都不同。
- 使用锁进行同步:
#include
#include
#include
#include
using namespace std;
int count;
mutex l;
void counter(){
lock_guard locker(l);
for(int i=0;i 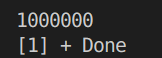
- 使用原子类型:
#include
#include
#include
#include
using namespace std;
atomic_int count;
void counter(){
for(int i=0;i 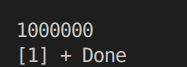
原子类型的实现原理
原子类型实现的原理是直接翻译成CPU指令,而对原子类型的操作,像+,-,*,,++等直接重载了运算符,编译时也直接翻译成CPU指令。每一个原子操作都是一条独立的CPU指令来完成,在其指令周期内,其他CPU无法对原子类型操作。
举例:
#include
#include
#include
#include
using namespace std;
atomic_int count;
void counter(){
for(int i=0;i 调试该程序,断点打在count++,
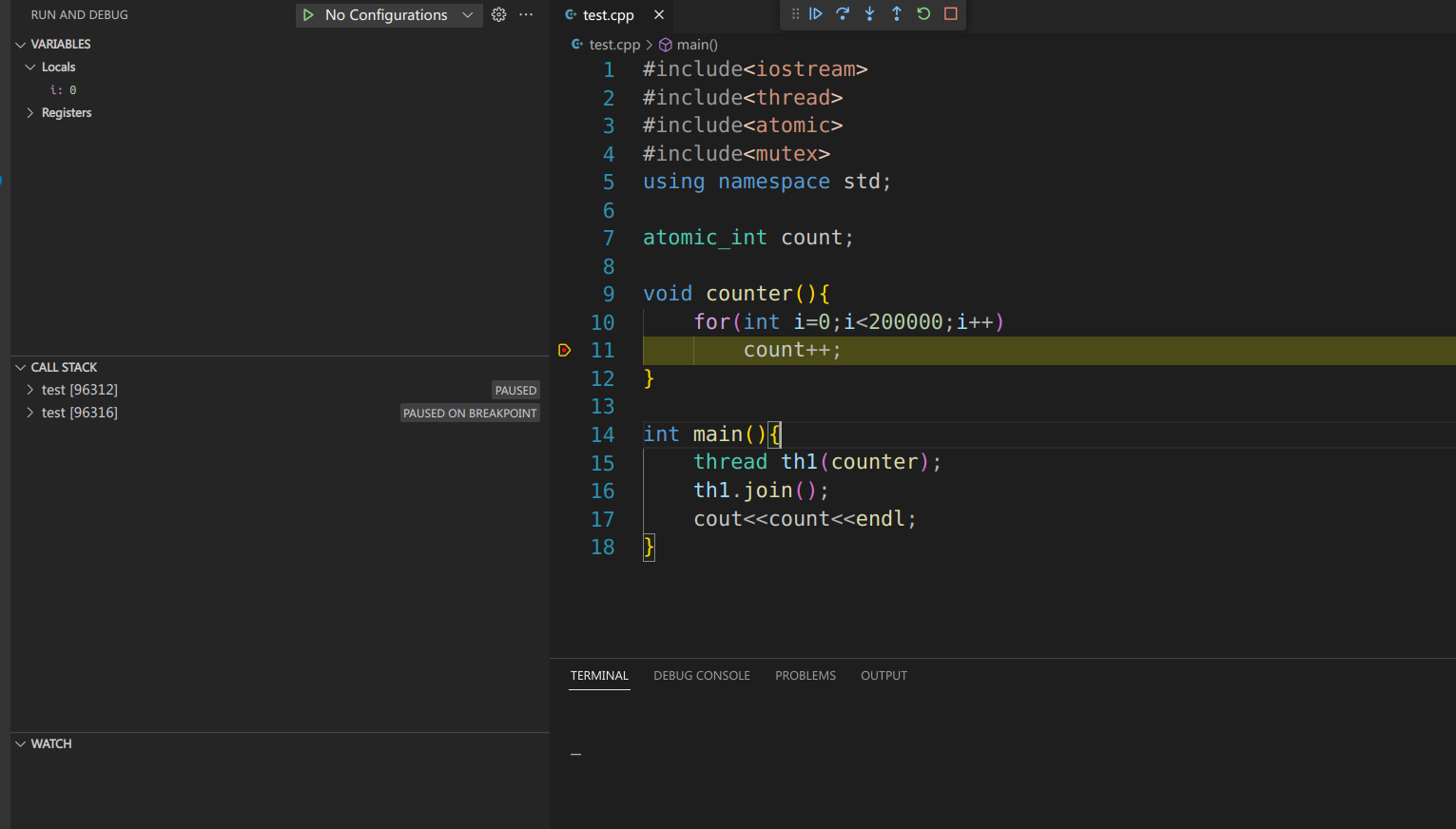
首先可以看到调用栈有两个test,也就是两个线程,main和th1。
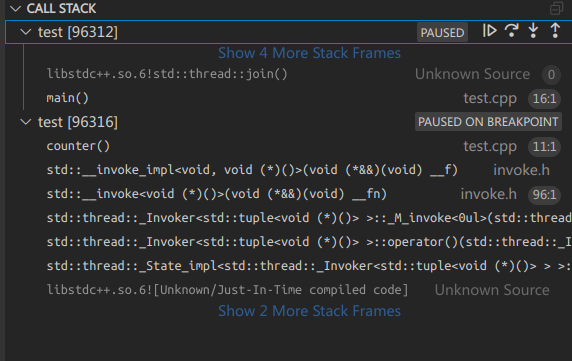
接着进入counter()的反汇编视图,open disassembly view:

call atomic_baseIiEppEi就是这条CPU指令用来给count++,它是原子性的,保证了不会被其他CPU操作。
并且在step into中也能看到跳转到了运算符重载的头文件:
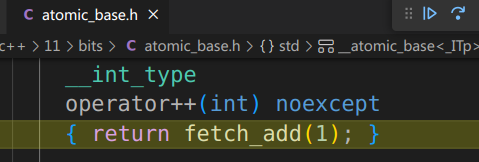

这就是atomic的实现机制
第二条add [rbp-0x4],0x1就是i++对应的CPU指令,i就存在bp基址寄存器的前面四个字节的位置。我们step over几次让i的值有变化,看寄存器相对寻址的值:就是0x7


第三条指令是CPU优化了for循环,本来应该先把i mov到寄存器,现在优化后直接比较i和19999的值,0x30d3f就是十进制的19999,也就是循环结束的条件。
如果给i加上volatile,就可以防止cpu优化
....
volatile int i;
for(i=0;i
原子类型的操作
上面的count++例子中,step into 跳转到了atomic类型的运算符重载定义中,实际上所有能够对原子类型的操作,都是重载了普通的意思,或添加了新的函数。
所有的原子操作:atomic a;
-
纵列 triv :针对std::atomic以及“其他普通类型之atomic”提供的操作
-
纵列 int type :针对std::atomic 且使用整型类型而提供的操作;
-
纵列 ptr type :针对std::atomic 且使用pointer类型 而提供的操作
| 操作 | triv | int type | ptr type | 效果 |
|---|---|---|---|---|
| atomic a = val | yes | yes | yes | 以val为a的初值(这个不是atomic 的操作) |
| atomic a; atomic_init(&a,val) | yes | yes | yes | 同上 (若无后面的atomic_init(),则a的初始化不完整) |
| a.is_lock_free() | yes | yes | yes | 如果内部不使用lock则返回true 用来检测atomic类型内部是否由于使用lock才成为atomic。如果不是,则硬件本身就拥有对atomic操作的固有支持 |
| a.store(val) | yes | yes | yes | 赋值 val (返回void) |
| a.load() | yes | yes | yes | 返回数值a的copy |
| a.exchange(val) | yes | yes | yes | 赋值val并返回旧值a的拷贝 |
| a.compare_exchange_strong(exp,des) | yes | yes | yes | cas操作 |
| a.compare_exchange_weak(exp,des) | yes | yes | yes | weak cas操作 |
| a = val | yes | yes | yes | 赋值并返回val的拷贝(copy) |
| a.operator atomic() | yes | yes | yes | 返回数值a的拷贝 |
| a.fetch_sub(val) | no | yes | yes | 不可切割值 a -= val 并返回新值得拷贝 |
| a += val | no | yes | yes | 等同于 t.fetch_add(val) |
| a -= val | no | yes | yes | 等同于 t.fetch_sub(val) |
| ++a a++ | no | yes | yes | 等同于 t.fetch_add(1) 并返回 a 或者a+1的拷贝 |
| –a a– | no | yes | yes | 等同于 t.fetch_sub(1) 并返回 a 或者a+1的拷贝 |
| a.fetch_and(val) | no | yes | no | 不可切割值 a &= val 并返回新值得拷贝 |
| a.fetch_or(val) | no | yes | no | 不可切割值 a |
| a.fetch_and(val) | no | yes | no | 不可切割值 a ^= val 并返回新值得拷贝 |
| a &= val | no | yes | no | 等同于 t.fetch_and(val) |
| a | = val | no | yes | no |
| a | = val | no | yes | no |
atomic中的模板除了整型,还可以是其他如浮点型,指针,但是他们可能没有+,-,*,/等运算符的重载或位运算重载。
CAS操作
a.compare_exchange_strong/weak是CAS操作(compare and swap),CPU提供这个操作用来比较“某内存的值”和“某给定的值”,当他们相同时,则把“该内存值”更新为”另一个给定的值“。如果不相同,则更新“某给定的值”为“某内存值”。
伪代码:
bool compare_exchange_strong(T & expected ,T desired)
{
if(this->load() == expected )
{
this->strore(desired)
return true;
}
else
{
expected = this->load();
return false;
}
}
this就是内存值的指针,expected是第一个给定的值,desired是另一个给定的值。
memory_order和内存模型
参考:C++11 内存模型。知乎:C++ memory_order.详解c++ atomic原子编程中的Memory Order.
C++11 中的原子类型的API大都需要提供一个std::memory_order(内存序,访存顺序)的枚举类型作为参数,如atomic_store, atomic_load, atomic_exchange, atomic_compare_exchange, atomic_flag, 以及还有test_and_set和clear等API都可以设置一个std::memory_order参数。在没有指定时,默认的参数是std::memory_order_seq_cst(顺序一致性)。
研究内存序,首先要研究C++的内存模型。
C++的内存模型一般可以分为静态内存模型和动态内存模型。静态内存模型主要涉及类的对象的在内存中是如何存放的,即从结构上来看一个对象在内存中的布局。和之前研究的内存对齐和排序(C温故补缺(九):字节对齐与排序)类似。
而动态内存模型,可以理解为存储一致性模型。主要是从行为上来看多个线程对同一个对象同时操作时所做的约束。和我们做线程同步的意义相似的:都是为了程序执行的正确性,避免未知结果。
std::memory_orderspecifies how memory accesses, including regular, non-atomic memory accesses, are to be ordered around an atomic operation. Absent any constraints on a multi-core system, when multiple threads simultaneously read and write to several variables, one thread can observe the values change in an order different from the order another thread wrote them. Indeed, the apparent order of changes can even differ among multiple reader threads. Some similar effects can occur even on uniprocessor systems due to compiler transformations allowed by the memory model.from cppreference
在cppreference.com中的简单解释中也说了:多核系统在没有任何约束的条件下,在多个线程同时读取和写入多个变量时,因为执行顺序的不同可能导致不同的值。在没有规定时,多线程并发执行时,指令是可能被CPU重排的,所以就有可能出现不同的结果。比如:
a,b两个共享变量,初始值都是0,通过两个改变值
线程 1 线程 2 a = 1; b = 2; R1 = b; R2 = a;
虽然对于每个线程每一步都是原子的,但是两个线程之前并没有规定先后顺序。就有可能出现6种情况。
| 情况 1 | 情况 2 | 情况 3 | 情况 4 | 情况 5 | 情况 6 |
|---|---|---|---|---|---|
| a = 1; | b = 2; | a = 1; | a = 1; | b = 2; | b = 2; |
| R1 = b; | R2 = a; | b = 2; | b = 2; | a = 1; | a = 1; |
| b = 2; | a = 1; | R1 = b; | R2 = a; | R1 = b; | R2 = b; |
| R2 = a; | R1 = b; | R2 = a; | R1 = b; | R2 = a; | R1 = b; |
| R1 == 0, R2 == 1 | R1 == 2, R2 == 0 | R1 == 2, R2 == 1 | R1 == 2, R2 == 1 | R1 == 2, R2 == 1 | R1 == 2, R2 == 1 |
常见的存储一致性模型包括:顺序一致性模型、处理器一致性模型、弱一致性模型、释放一致性模型、急切更新一致性模型、懒惰更新释放一致性模型、域一致性模型以及单项一致性模型。
因为C++中只有一下6种,所以只研究这几种访存次序。
| memory order | 作用 |
|---|---|
| memory_order_relaxed | 无fencing 作用,cpu和编译器可以重排指令 |
| memory_order_consume | 后面依赖此原子变量的访存指令勿重排至此条指令前 |
| memory_order_acquire | 后面的访存指令勿重排至此指令前 |
| memory_order_release | 前面的访存指令勿重排到此指令后 |
| memory_order_acq_rel | acquire+release |
| memory_order_seq_cst | acq_rel+所有使用seq_cst的指令有严格的全序关系 |
多线程编程时,通过这些标志位,来读写原子变量,可以组合成4种同步模型:
Relaxed ordering
在这种模型下,std::atomic的load和store都要带上memory_order_relaxed参数,Relaxed ordering仅仅保证load和store是原子的,除此之外无任何跨线程同步。
Release_Acquire ordering
这个模型下,store()使用memory_order_release,而load()使用memory_order_acquire。这个模型限制指令的重排:
-
在store()之前的读写操作,不允许重排到store()的后面。一般对应写操作
-
在load()之后的读写操作,不允许重排到load()前面,一般对应读操作
也就是store总是排在load前面,保证不会读到修改前的数据。
如一个打印机有两个模块,一个负责装载打印数据,一个用来打印。如果未装载新的数据,会直接打印上一次的信息:
如果没有规定线程之间的执行顺序,则可能会读到上一此的信息:
#include
#include
#include
using namespace std;
string printstr="old data";//上一此的信息
void load(string str){//装载
printstr=str;
}
void print(){//打印
cout 因为程序会被cpu优化,所以手动编译取消优化-O0
g++ test.cpp -O0 -o test;./test
每次的运行都是随机排序的,所以可能会出现old data

使用Release_acquire模型来规定线程间的执行顺序:
#include
#include
#include
using namespace std;
atomic ready{false};
string printstr="old data";//上一此的信息
void load(string str){//装载
printstr=str;
ready.store(true,memory_order_release);
}
void print(){//打印
while(!ready.load(memory_order_acquire))
;//循环等待
cout 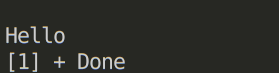 就得到了准确的结果
就得到了准确的结果
Release_Consume ordering
这个模型下 store()使用memory_order_release,而load()使用memory_order_consume。
-
在store前的所有读写,不允许被移动到store()后面
-
在load之后所有依赖此原子变量的读写,不允许被移动到load前面。
和上面Release-acquire模型的差别是load前可以出现不依赖该原子变量的读写
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
