
C++11
- 统一的列表初始化
-
- { }初始化
- std::initializer_list
- 声明
-
- decltype
- STL中的变化
- 右值引用
-
- 左值引用和右值引用
- 左值引用与右值引用比较
-
- 左值引用:
- 右值引用
- 右值引用使用场景和意义
- 完美转发
-
- 模板中的&&万能引用
- 新的类功能
-
- 默认成员函数
- 强制生成默认成员函数的关键字:default
- 禁止生成默认成员函数的关键字:delete
- 可变参数模板
-
- STL容器中的`emplace`相关接口函数
- lambda表达式
-
- C++98的栗子
- lambda表达式
- lambda表达式语法
- 函数对象与lambda表达式
- 包装器
-
- function包装器
- bind
统一的列表初始化
{ }初始化
C++98中,标准允许使用{ }对数组或者结构体对象进行统一的列表初始值设定
举个栗子
struct point
{
int _x;
int _y;
};
int main()
{
int arr[] = { 1,2,3,4,5 };
point p = { 1,2 };
return 0;
}
C++11扩大 { }符号的使用范围,使其可用于所有的内置类型和自定义类型;使用初始化列表时,可添加赋值符号(=),也可不添加
举个栗子
int main()
{
vectorint> v = { 1,2,3,4,5 };
int x = { 1 };
return 0;
}
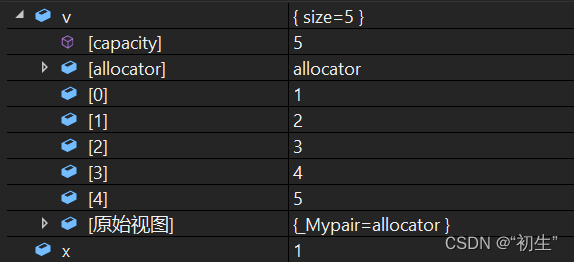
std::initializer_list
上面之所以可以使用{ }对vector进行列表初始化,其实是因为在其构造函数中包括了使用initializer_list的构造函数

initializer_list其本质是也是个容器,不同点在于并不存储数据,而是提供两个迭代器指向数据的头和尾;并且initializer_list存在于所有容器的构造函数中

举个栗子:判断数据类型
int main()
{
auto il = { 1,2,3,4,5 };
cout typeid(il).name() endl;
return 0;
}

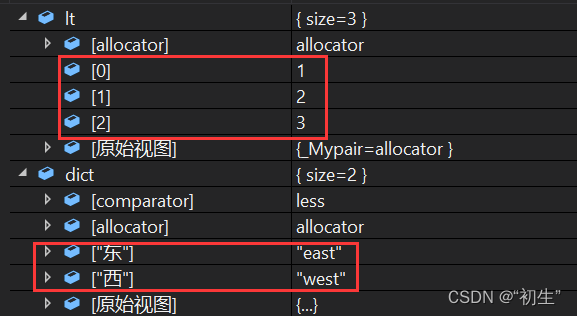
将initializer_list应用到其他容器中
int main()
{
listint> lt = { 1,2,3 };
mapstring, string> dict = { {"东","east"},{"西","west"} };
return 0;
}
声明
C++11提供了多种简化声明的方式,尤其是在使用模板时
decltype
关键字decltype将变量的类型声明为表达式指定的类型
举个栗子
int main()
{
int a = 0;
decltype(a) b;
cout typeid(b).name() endl;
return 0;
}
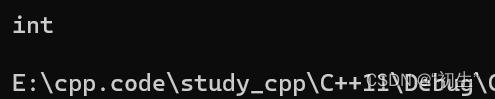
decltype将变量a的类型声明为int,之后创建变量b
STL中的变化
- 增加新容器:
unordered_map/multimap和unordered_set/multiset - 已有容器新接口函数:移动构造和移动赋值;
emplace_xxx插入接口或右值引用版本的插入接口
右值引用
左值引用和右值引用
左值是一个表示数据的表达式,可以通过获取它的地址/可以对它进行赋值;左值可以出现在赋值符号的左边或右边;左值引用就是给左值取别名
//p,a,b,*p都是左值
int* p = new int;
int a = 0;
const int b = 1;
右值也是表示数据的表达式,例如:字符常量,函数返回值;右值只能出现在赋值符号的右边;右值引用就是给右值取别名
C++中将右值分为两种:
- 纯右值:内置类型表达式的值
- 将亡值:自定义类型表达式的值
//0,0,i+j都是右值
int i = 0;
int j = 0;
int m = i + j;
注意:右值是不可以进行取地址的,但是给右值取别名后,会将右值存储到特定位置,并且可以取到该位置的地址
左值引用与右值引用比较
左值引用:
- 左值引用只能引用左值,不可以引用右值
- 被
const修饰的左值即可引用左值也可以引用右值
int main()
{
//左值只能引用左值
int i = 0;
int& ri = i;
//10是右值编译报错
int& rj = 10;
//const修饰的左值可以引用左值和右值
const int& ra = 10;
const int& rb = i;
return 0;
}

右值引用
- 右值引用只能引用右值
- 右值引用可以引用
move之后的左值
int main()
{
//右值引用只能引用右值
int&& ra = 10;
//i是左值,进行右值引用会报错
int i = 0;
int&& ri = i;
//右值引用可以引用move之后的左值
int&& rii = std::move(i);
return 0;
}

右值引用使用场景和意义
上文所述中,左值引用即可引用左值又可引用右值,那么C++11为什么要提出右值引用呢???为了解决这个疑问,先来了解左值引用的意义可能会有所帮助
左值引用的意义:函数传参/函数传返回值时使用左值引用可以减少拷贝;不过这里有个前提,就是在函数栈帧销毁之后任然存在的数据才能进行引用返回,所以当待返回的数据是临时创建的变量时,就不能进行引用返回;所以不难猜测,右值引用的提出就是为了解决这个问题
接下来通过一个模拟实现string类来学习右值引用
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
,_capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
//拷贝构造
string(const string& s)
{
cout "string(const string& s) 深拷贝" endl;
string tmp(s._str);
swap(tmp);
}
//赋值重载
string& operator=(const string& s)
{
cout "string& operator=(const string& s) 深拷贝" endl;
string tmp(s);
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
void reverse(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reverse(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '�';
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str()
{
return _str;
}
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;
};
通过一个函数先复习一下左值引用
string to_string(int value)
{
bool flag = 1;
if (value 0)
{
flag = -1;
value = 0 - value;
}
string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == -1)
{
str += '-';
}
reverse(str.begin(), str.end());
return str;
}
int main()
{
yjm::string ret = yjm::to_string(1234);
return 0;
}

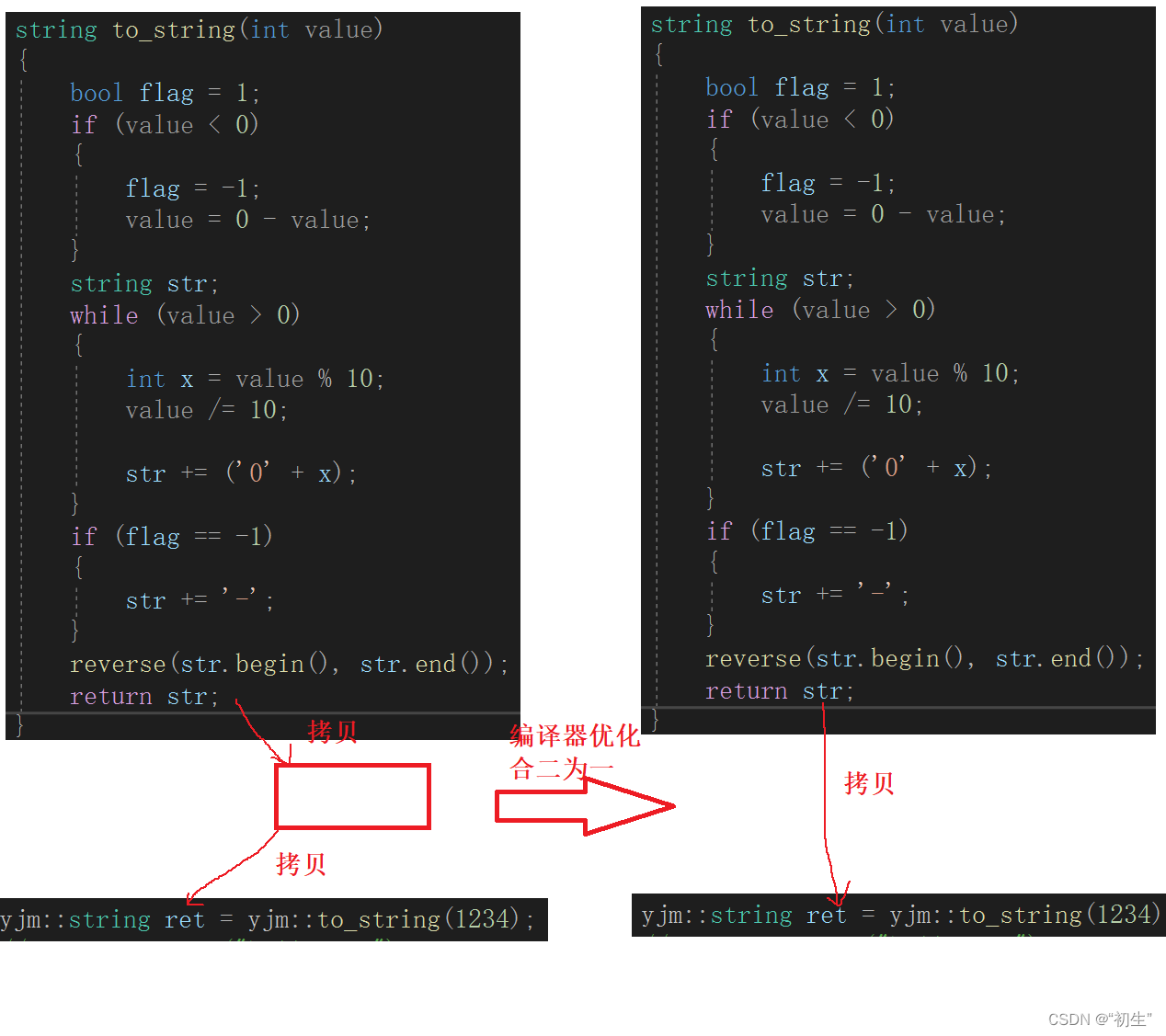
没有右值引用时,返回临时变量还是会进行深拷贝,接下来看看当加上右值引用之后的结果又该如何?
int main()
{
yjm::string s1("hello yjm");
yjm::string s2(s1);
//左值move之后变成右值
yjm::string s3(move(s1));
return 0;
}
在没有实现右值引用时,s2调用构造函数进行初始化;s3的参数虽然是右值,但是由于构造函数是const修饰的构造函数,所以也可以调用

如果加入参数是右值引用的构造结果会怎么样呢???
//移动构造
string(string&& s)
{
cout "string(string&& s) 移动构造" endl;
swap(s);
}
//移动赋值
string& operator=(string&& s)
{
cout "string& operator=(string&& s) 移动赋值" endl;
swap(s);
return *this;
}

由运行结果可知:s2中的参数是左值,故匹配参数是左值引用的构造函数即深拷贝;s3中的参数是右值,故匹配参数是右值引用的构造函数即移动构造;由于参数是自定义类型,也就是将亡值,所以进行资源转移
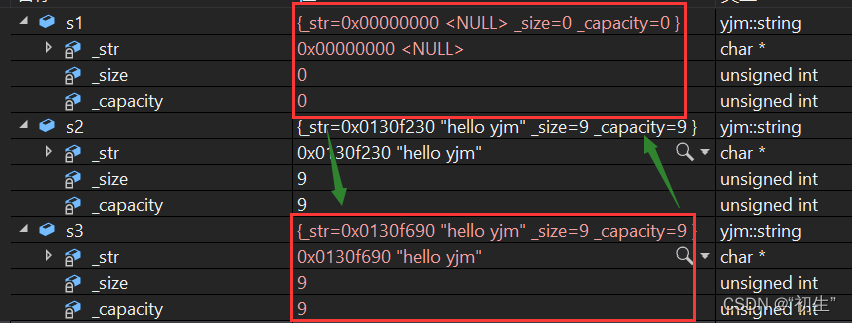
现在回头看上面遗留的问题,当加入右值引用之后,返回临时变量是否还需要进行深拷贝呢???

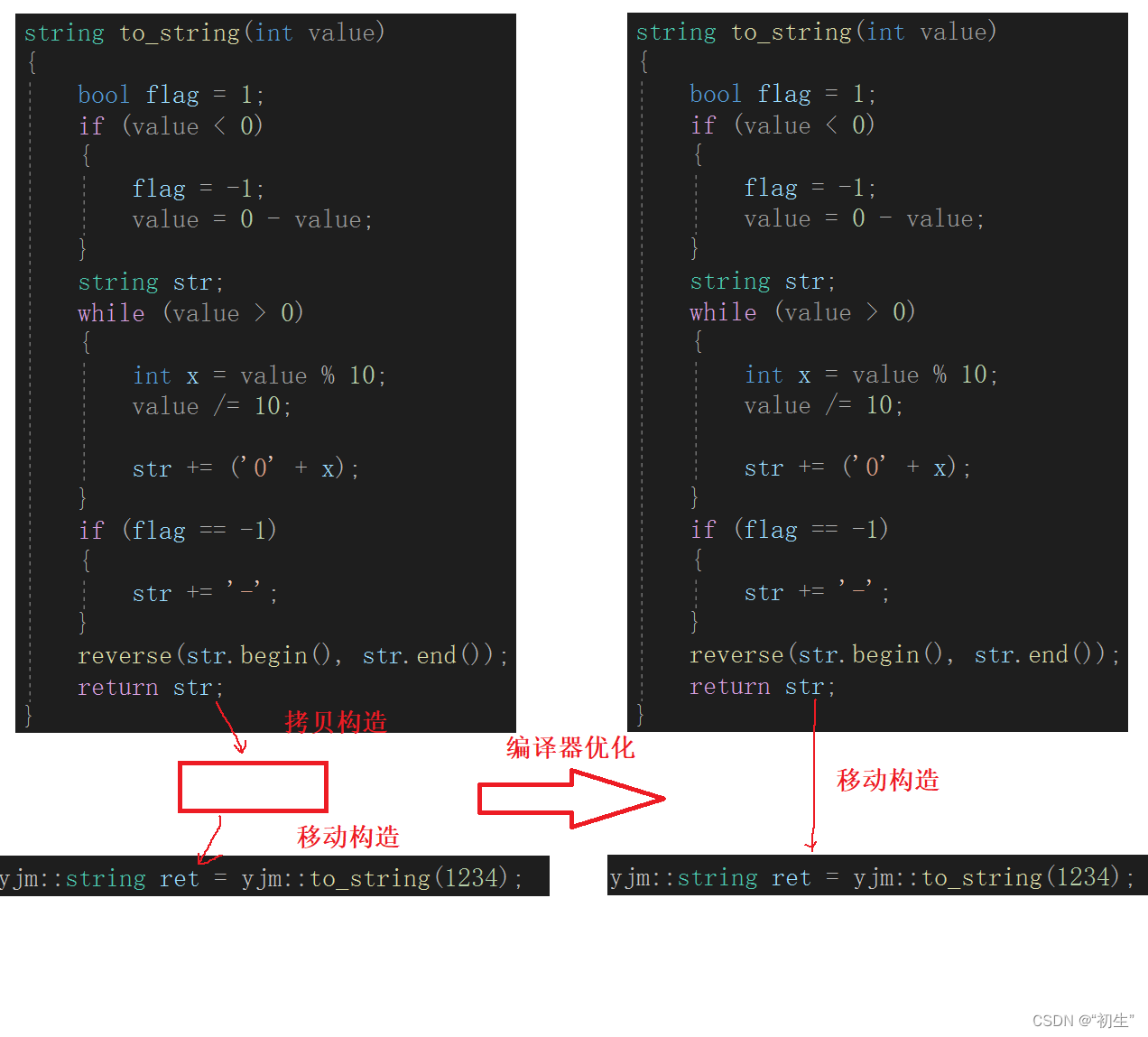
通过允许结果来看,并没有进行深拷贝,只是进行了移动构造;其中编译器也进行了优化:首先变量str先拷贝构造一份临时变量,临时变量作为右值进行移动构造,编译器进行优化,直接将str识别为右值进行移动构造
同理,参数为右值引用的赋值重载也是如此,不加赘述,直接看结果
int main()
{
yjm::string ret;
ret= yjm::to_string(1234);
return 0;
}

返回值先移动构造一个临时变量,临时变量作为右值再进行移动赋值
上面所学习的都是右值引用在函数返回值中的应用,其实它还可以应用到数据的插入中
举个栗子:
总结
右值引用和左值引用减少拷贝的原理不同
左值引用是取别名,直接起作用;右值引用是间接起作用,实现移动构造/移动赋值,在拷贝的过程中,如果右值是将亡值,则进行资源转移
完美转发
观察下面的代码
int main()
{
int x = 1;
int y = 2;
int&& rr1 = 0;
const int&& rr2 = x + y;
rr1++;
rr2++;
return 0;
}
通过上面的学习肯定知道,右值被引用之后会被存储到特定的位置,可以对特定的位置进行取地址,所以rr1++正确;rr2++错误,因为其引用的数据被const所修饰不能进行修改

运行结果与预期一致
既然右值被引用之后可以进行”修改“,是不是可以理解为其属性变为了左值;再结合上面当进行移动构造时,右值本身是不能进行修改的,但是经过右值引用之后,其属性变为了左值,资源交换也就可以进行;所以,当右值被右值引用之后,其属性变为了左值
观察下列代码
void Fun1(int& x)
{
cout "Fun1(int& x)" endl;
}
void Fun1(int&& x)
{
cout "Fun1(int&& x)" endl;
}
int main()
{
int i = 0;
Fun1(i);
Fun1(0);
return 0;
}
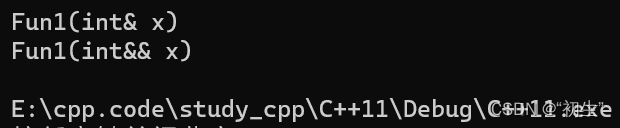
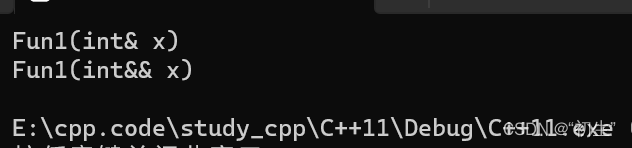
左值匹配左值引用,右值匹配右值引用没有什么问题,当只有右值引用结果会是怎么样呢???

有结果可知,当左值去匹配右值引用时,程序崩溃;那么是不是存在某种函数,既可以匹配左值同时也可以匹配右值呢???
模板中的&&万能引用
templateclass T>
void PerfectForward(T&& t)
{
Fun1(t);
}
万能模板可以匹配任何类型的数据,先检测上面的数据
int main()
{
int i = 0;
PerfectForward(i);
PerfectForward(0);
return 0;
}

程序正常运行,证明了万能模板可以匹配左值也可以匹配右值
图解:
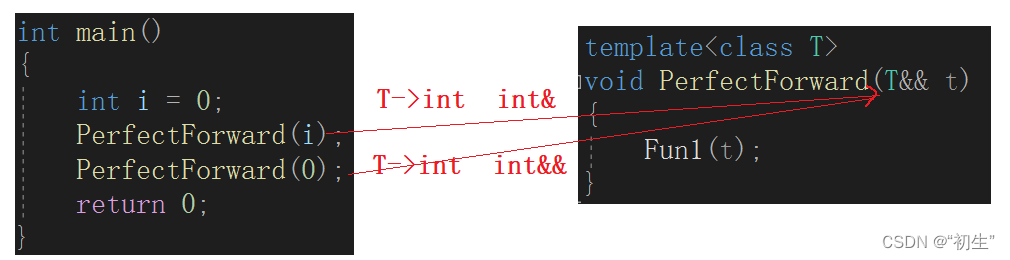
当左值i匹配模板时,模板会将其推演为int类型,实际类型是int&;当右值0匹配模板时,模板将其推演为int,实际类型是int&&
万能模板虽然解决了类型匹配的问题,但是又引出了一个新问题,为什么程序运行的结果都是左值引用呢???
解释起来也很简单,当右值被右值引用之后其属性变成了左值,所以全都调用的左值引用
为了解决这个问题,又引入了完美转发std::forward,在右值引用之后会保持其属性
templateclass T>
void PerfectForward(T&& t)
{
Fun1(std::forwardT>(t));
}
至此,以上有关属性改变的问题已经全部解决
新的类功能
默认成员函数
C++11新增了两个默认成员函数:移动构造和移动赋值重载
对于新增的成员函数需要注意如下点:
- 如果没有实现移动构造函数,且没有实现析构函数,拷贝构造和赋值重载中的任一个,则编译器会自动生成一个默认移动构造:对于内置类型变量会执行按字节拷贝;对于自定义类型需要看成员是否实现移动构造,如果已经实现就调用移动构造,否则就调用拷贝构造
- 移动赋值重载亦是如此
强制生成默认成员函数的关键字:default
C++11可以让使用者更好地使用默认成员函数,如果需要使用某个默认函数,但是并没有实现,那么可以使用关键字default显示指定函数生成
namespace yjm
{
class Person
{
public:
Person(const char* name = " ", int age = 0)
:_name(name)
, _age(age)
{
}
Person(const Person& p)
:_name(p._name)
,_age(p._age)
{
}
Person(Person&& p) = default;
private:
string _name;
int _age;
};
}
int main()
{
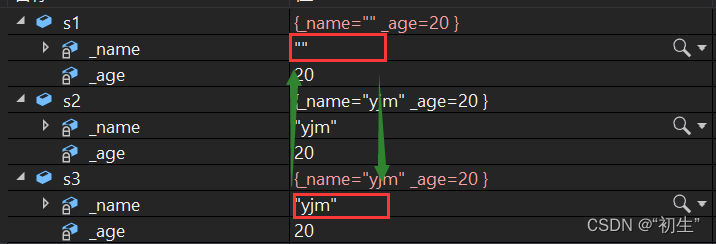
yjm::Person s1("yjm",20);
yjm::Person s2(s1);
//调用由关键字生成的右值引用构造函数
yjm::Person s3(std::move(s1));
return 0;
}
禁止生成默认成员函数的关键字:delete
既然存在强制生成,那么就会存在禁止生成;关键字delete便是为了禁止生成某种默认成员函数
复用上面的代码,运行结果如下

被关键字 delete修饰的默认成员函数是不可以被调用的
可变参数模板
C++11的新特征可变参数模板,可以创建接受可变参数的函数和类模板
如下就是一个可变参数的函数模板
//Args是模板参数包,args是函数形参参数包
//声明参数包Args... args,这个参数包可以包含0到任意个模板参数
templateclass ...Args>
void showlist(Args... args)
{}
上面的参数args前面有省略号,所以它就是一个可变模板参数,把带有省略号的参数称为参数包,其包含0到任意个模板参数;无法直接获取参数包args中的每个参数,只能通过展开参数包的方式来获取每个参数
递归函数方式展开参数包
templateclass T>
void showlist(const T& t)
{
cout t endl;
}
templateclass T,class ...Args>
void showlist(T value, Args... args)
{
cout value " ";
showlist(args...);
}
int main()
{
showlist(1);
showlist(1,1.1);
showlist(1, 1.1,string("hello world"));
return 0;
}
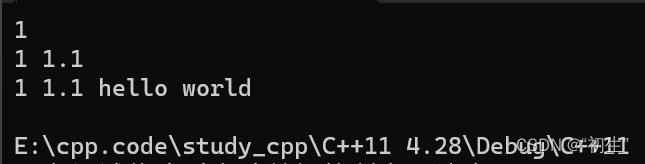
递归函数参数T value, Args... args;第一个参数接受传递的第一个参数,第二个参数接受剩余的剩余的传递参数;通过子递归函数将参数打印出来
逗号表达式展开参数包
仅供了解即可
templateclass T>
void printarg(T t)
{
cout t " ";
}
templateclass ...Args>
void showlist(Args... args)
{
int arr[] = { (printarg(args),0)... };
cout endl;
}
int main()
{
showlist(1);
showlist(1, 1.1);
showlist(1, 1.1, string("hello world"));
return 0;
}

STL容器中的emplace相关接口函数

templateclass ...Args>
void emplace_back(Args&&... args);
可以观察到容器list的emplace_back接口支持模板的可变参数;接下来就探索此接口有什么优点
int main()
{
pairint, yjm::string>kv(20, "sort");
std::liststd::pairint, yjm::string>>lt;
lt.emplace_back(kv);//左值
lt.emplace_back(make_pair(20, "sort"));//右值
lt.emplace_back(10, "sort");//构造pair参数包
cout endl;
lt.push_back(kv);//左值
lt.push_back(make_pair(30, "sort"));//右值
lt.push_back({ 40, "sort" });//右值
return 0;
}

由运行结果来看,emplace_back接口减少了拷贝提高效率
lambda表达式
C++98的栗子
在C++98中,如果要对数据进行排序,当待排数据类型是内置类型时:可以有多种选择,比如,冒泡,归并或者快排;如果待排数据是自定义类型,则需要创建相应的仿函数
举个栗子:将每种球类按照价格的升序进行排序
struct Goods
{
string _name;
double _price;
Goods(const char* str, double price)
:_name(str)
, _price(price)
{}
};
//按照降序进行排
struct Comparepriceless
{
bool operator()(const Goods& g1, const Goods& g2)
{
return g1._price g2._price;
}
};
int main()
{
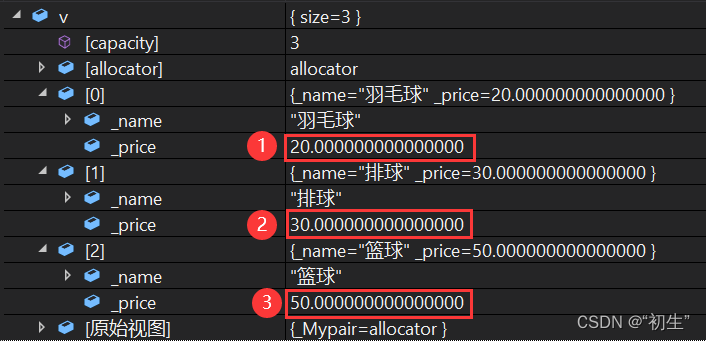
vectorGoods> v = {{"篮球",50 },{"排球",30},{"羽毛球",20}};
sort(v.begin(), v.end(), Comparepriceless());
return 0;
}
运行结果
随着语言的发展,人们觉得上面的方式太麻烦,每次为了实现一个仿函数都是要重新写一个类,如果比较的逻辑不同,还要去实现不同的类,带来了很大的不方便;因此,C++11中出现了lambda表达式来解决这个问题
lambda表达式
使用lambda表达式,修改上面的代码
struct Goods
{
string _name;
double _price;
Goods(const char* str, double price)
:_name(str)
, _price(price)
{}
};
int main()
{
vectorGoods> v = { {"篮球",50 },{"排球",30},{"羽毛球",20} };
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price g2._price; });
return 0;
}
运行结果与上面一致
lambda表达式语法
语法:[capture-list](parameters)multable->return-type{statement}
-
[capture-list]:捕捉列表,编译器根据捕捉列表中所捕捉的变量(上文)提供给lambda使用;必须写 -
(parameters):参数列表,与普通参数列表一致;可省略 -
multable:默认情况下,lambda函数总是一个const函数,multable可以取消其常量性;使用该修饰时,参数列表不可以省略;可省略 -
->return-type:返回值类型,可自动推导返回值类型从而声明函数的返回值类型;可省略 -
{statement}:函数体,在该函数体内,除了可以使用其参数外,还可以使用所捕捉的变量
举个栗子:
int main()
{
//最简单的lambda表达式,无任何意义
[] {};
auto compare = [](int x, int y) {return x > y; };
cout compare(1, 0) endl;
return 0;
}

lambda表达式实际上是一个对象,类型无法获得,只能通过auto去推演
捕捉列表说明
-
[var]:表示值传递方式捕捉变量var -
[=]:表示值传递方式捕捉所有父作用域中的变量;所谓父作用域便是lambda函数的语句块 -
[&var]:表示引用传递方式捕捉变量[var] -
[&]:表示引用传递方式捕捉所有父作用域中的变量
函数对象与lambda表达式
观察下列代码
class Rate
{
public:
Rate(double rate)
:_rate(rate)
{}
//仿函数
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
double rate = 0.4;
Rate r1(rate);
r1(10000, 5);
auto r2 = [=](double money, int year) {return money * rate * year; };
r2(10000, 5);
return 0;
}
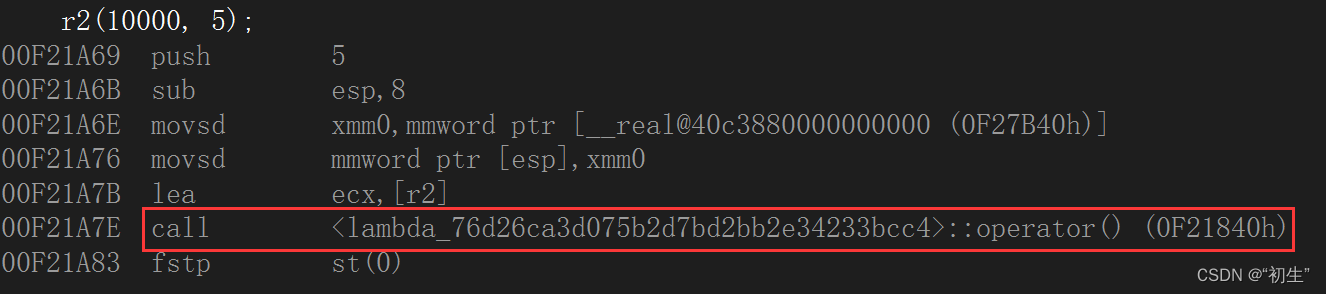
仿函数与lambda表达式完全一样;仿函数将rate作为其成员变量,在定义对象时给出初始值即可;lambda表达式通过捕获列表可以直接将该变量捕获到
仿函数反汇编

lambda表达式反汇编
包装器
function包装器
function本质是一个类模板,也是一个包装器
观察下列代码
templateclass F,class T>
T useF(F f, T x)
{
static int i = 0;
cout "i:" ++i endl;
cout "i:" &i endl;
return f(x);
}
double f(double d)
{
return d / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 2;
}
};
int main()
{
//函数名f
cout useF(f, 1.1) endl;
//仿函数Functor
cout useF(Functor(), 1.1) endl;
//lambda表达式
cout useF([](double d){ return d / 4; }, 1.1) endl;
return 0;
}
运行结果
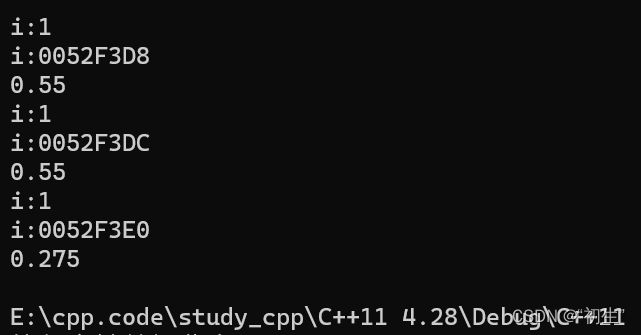
首先变量i是静态,本应该生成一份,但结果却是生成了三份,而且代码中调用的方式并不统一;接下来使用function统一调用方式
类模板原型如下
Ret:被调用函数的返回类型
Args...:被调用函数的形参
templateclass Ret,class... Args>
class functionRet(Args...)>
举个栗子:
int f(int a, int b)
{
return a + b;
}
struct Functor
{
int operator()(int a, int b)
{
return a + b;
}
};
int main()
{
//函数名/函数指针
functionint(int, int)> f1(f);
cout f1(1, 2) endl;
//仿函数
functionint(int, int)>f2=Functor();
cout f2(1, 2) endl;
//lambda表达式
functionint(int, int)>f3 = [](const int a, const int b) {return a + b; };
cout f3(1, 2) endl;
return 0;
}
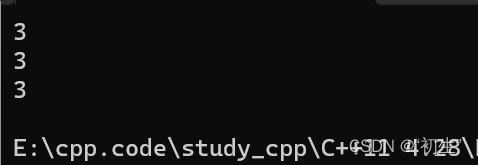
包装器的可以将函数指针/仿函数/lambda表达式进行类型统一,使用一种方式进行调用
bind
上面的function是类模板,这里的bind是一个函数模板,接受一个可调用对象,生成一个新的可调用对象来适配原对象的参数列表
原型如下
templateclass Ret,class... Args>
bind(Fn&& fn,Args&&... args)
这里的参数包是由命名空间placeholders构成

举个栗子:
int Plus(int a, int b)
{
return a + b;
}
int Sub(int a, int b)
{
return a - b;
}
int main()
{
//绑定函数Plus,参数分别调用func1的第一个,第二个参数
functionint(int, int)>func1 = bind(Plus, placeholders::_1, placeholders::_2);
cout func1(1, 2) endl;
//绑定函数Sub,参数分别调用func2的第一个,第二个参数
functionint(int, int)>func2 = bind(Sub, placeholders::_1, placeholders::_2);
cout func2(1, 2) endl;
return 0;
}
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
