
前脚刚研究了一轮GPT3.5,OpenAI很快就升级了GPT-4,整体表现有进一步提升。追赶一下潮流,研究研究GPT-4干了啥。
本文内容全部源于对OpenAI公开的技术报告的解读,通篇以PR效果为主,实际内容不多。主要强调的工作,是“Predictable Scaling”这个概念。
上一版ChatGPT的主要挑战是,因为模型的训练量极大,很难去进行优化(ChatGPT是fine-tuning的模式)。因此,OpenAI希望能够在模型训练初期,就进行优化,从而大幅提升人工调优迭代的效率。而想要进行调优,就得知道当前模型的效果如何。因此,这个问题就被转化为了:如何在模型训练初期,就能够预测最终训练完成后的实际效果。
从结果来看,ChatGPT实现了,仅仅执行千分之一到万分之一的训练量,就可以大致预测模型的结果。
实现原理相对简单,就是在某一个模型的不同训练阶段进行实际效果测量,然后做函数拟合,发现符合幂等曲线。然后再基于采样值,测算一下幂等函数的相关参数,下一轮就可以只进行少量训练,就去预测最终效果了。
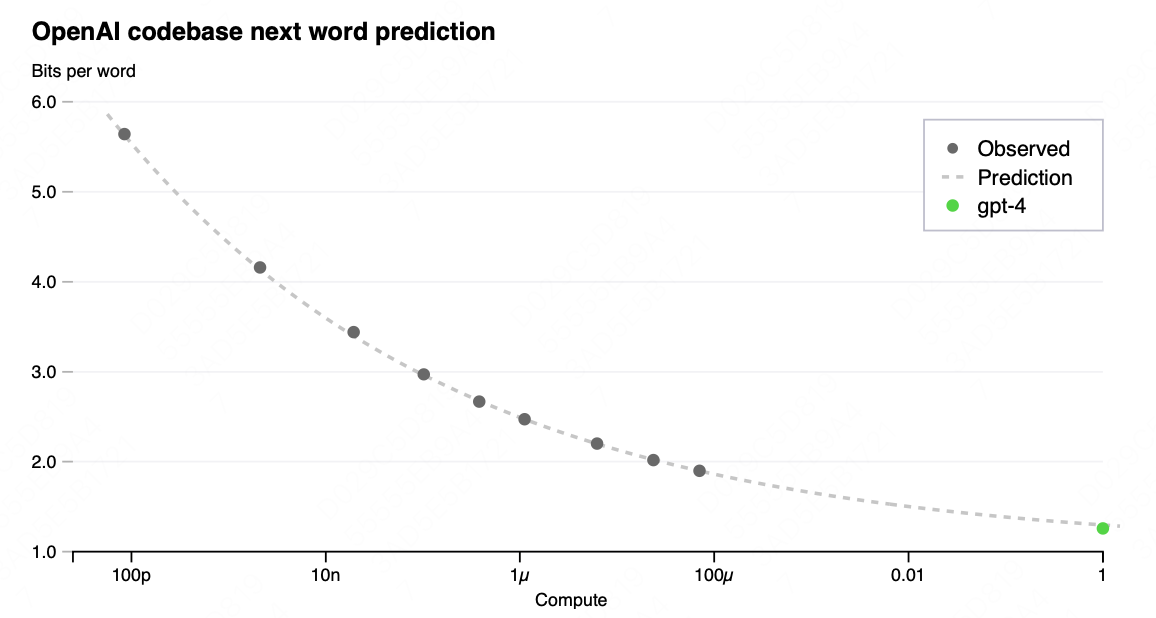
至于其他效果上的优化,OpenAI没有进一步解读原理,但整体应该还是基于“训练-奖励”的优化模型,去生成更针对性的奖励模型(比如增加法律、安全之类的奖励判断),以实现更优的效果。
原版内容如下:
3 Predictable Scaling
A large focus of the GPT-4 project was building a deep learning stack that scales predictably. The primary reason is that for very large training runs like GPT-4, it is not feasible to do extensive model-specific tuning. To address this, we developed infrastructure and optimization methods that have very predictable behavior across multiple scales. These improvements allowed us to reliably predict some aspects of the performance of GPT-4 from smaller models trained using 1, 000× – 10, 000× less compute.
3.1 Loss Prediction
The final loss of properly-trained large language models is thought to be well approximated by power laws in the amount of compute used to train the model [35, 36, 2, 14, 15].
To verify the scalability of our optimization infrastructure, we predicted GPT-4’s final loss on our internal codebase (not part of the training set) by fitting a scaling law with an irreducible loss term (as in Henighan et al. [15]): L(C) = aCb + c, from models trained using the same methodology but using at most 10,000x less compute than GPT-4. This prediction was made shortly after the run started, without use of any partial results. The fitted scaling law predicted GPT-4’s final loss with high accuracy (Figure 1).
3.2 Scaling of Capabilities on HumanEval
Having a sense of the capabilities of a model before training can improve decisions around alignment, safety, and deployment. In addition to predicting final loss, we developed methodology to predict more interpretable metrics of capability. One such metric is pass rate on the HumanEval dataset [37], which measures the ability to synthesize Python functions of varying complexity. We successfully predicted the pass rate on a subset of the HumanEval dataset by extrapolating from models trained with at most 1, 000× less compute (Figure 2).
For an individual problem in HumanEval, performance may occasionally worsen with scale. Despite these challenges, we find an approximate power law relationship −EP [log(pass_rate(C))] = α∗C−k
where k and α are positive constants, and P is a subset of problems in the dataset. We hypothesize that this relationship holds for all problems in this dataset. In practice, very low pass rates are difficult or impossible to estimate, so we restrict to problems P and models M such that given some large sample budget, every problem is solved at least once by every model.
We registered predictions for GPT-4’s performance on HumanEval before training completed, using only information available prior to training. All but the 15 hardest HumanEval problems were split into 6 difficulty buckets based on the performance of smaller models. The results on the 3rd easiest bucket are shown in Figure 2, showing that the resulting predictions were very accurate for this subset of HumanEval problems where we can accurately estimate log(pass_rate) for several smaller models. Predictions on the other five buckets performed almost as well, the main exception being GPT-4 underperforming our predictions on the easiest bucket.
Certain capabilities remain hard to predict. For example, the Inverse Scaling Prize [38] proposed several tasks for which model performance decreases as a function of scale. Similarly to a recent result by Wei et al. [39], we find that GPT-4 reverses this trend, as shown on one of the tasks called Hindsight Neglect [40] in Figure 3.
We believe that accurately predicting future capabilities is important for safety. Going forward we plan to refine these methods and register performance predictions across various capabilities before large model training begins, and we hope this becomes a common goal in the field.
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
