
一、Collectors类:
1.1、Collectors介绍
Collectors类,是JDK1.8开始提供的一个的工具类,它专门用于对Stream操作流中的元素各种处理操作,Collectors类中提供了一些常用的方法,例如:toList()、toSet()、toCollection()、toMap()、toConcurrentMap()方法,以及一些分组聚合的方法。
Stream操作流
1.2、常用方法
注意:Collectors类中的方法都是需要和Stream类中的collect()方法结合使用的。
(1)toList、toSet方法
toList、toSet方法是将Stream流中的数据,提取出来,转换成集合返回。
public static ListUser> getUserList() {
ListUser> list = new ArrayList>();
for (int i = 0; i 10; i++) {
list.add(new User(i+11, "name_00" + i, "test_0" + i));
}
return list;
}
public static void main(String[] args) {
ListUser> userList = getUserList();
// 转换 List 集合
ListString> list = userList.stream().map(User::getUname).collect(Collectors.toList());
System.out.println(list);
// 转换 Set 集合
SetString> list2 = userList.stream().map(User::getPassword).collect(Collectors.toSet());
System.out.println(list2);
}
(2)toMap方法
toMap、toConcurrentMap两个方法的作用是一样的,只不过toConcurrentMap方法是线程安全的。这两个方法在使用的时候,至少需要传递两个参数,分别是:
- 第一个参数:Function类型的参数,作为keyMapper,这是用于指定Map中的key的(必须传递)。
- 第二个参数:Funct服务器托管网ion类型的参数,作为valuesMapper,这是用于指定Map中的value的(必须传递)。
- 第三个参数:BinaryOperator类型的参数,这是用于当Map集合中的key重复的时候,执行的解决办法(可选,只有当key重复时候,才会执行这个操作)。
public static void main(String[] args) {
ListUser> userList = getUserList();
// 转换为map集合
MapInteger, User> userMap = userList.stream().collect(Collectors.toMap(User::getId, item -> item, (x, y) -> {
if (Objects.equals(x.getId(), y.getId())) {
System.out.println("key发生重复啦");
return x;
}
return y;
}));
System.out.println(userMap);
}
(3)joining方法
joining方法的作用就是将Stream流中的元素按照指定的格式拼接起来,该方法有哪个重载类型,分别如下所示:
- 第一个方法:joining()无参数方法,直接将所有元素拼接起来。
- 第二个方法:joining(delimiter)一个参数方法,按照指定的分隔符delimiter拼接元素。
- 第三个方法:joining(delimiter,prefix,suffix)三个参数方法,按照指定的分隔符delimiter拼接元素,并且在最终拼接结果的前后指定prefix前缀和suffix后缀。
public static void main(String[] args) {
ListUser> userList = getUserList();
// joining 连接
String join1 = userList.stream().map(User::getUname).collect(Collectors.joining());
String join2 = userList.stream().map(User::getUname).collect(Collectors.joining(","));
String join3 = userList.stream().map(User::getUname).collect(Collectors.joining(",", "[", "]"));
System.out.println(join1);
System.out.println(join2);
System.out.println(join3);
}
(4)counting方法
counting方法用于统计元素个数,一般不会单独使用,会和groupingBy结合使用。
// counting 统计
Long count = userList.stream().collect(Collectors.counting());
System.out.println(count);
(5)groupingBy方法
groupingBy方法用于将Stream流中的元素,按照某个分组规则将其分组。groupingBy方法返回值是一个Map集合,集合中的key表示分组的唯一标识,value则表示分组后的所有元素,默认是List集合。
groupingBy方法有多个参数的重载,如下所示:
- 一个参数的方法:groupingBy(Function key),接收一个Function类型的参数,主要是作为Map集合中的key,默认是返回List集合作为value。
- 两个参数的方法:groupingBy(Function key,Collector downstream),key是Map的key值,第二个则表示一个收集器,对分组中的所有元素进行收集,然后作为Map对象的value。(*groupingBy可以实现多个字段分组,也就是先按照某个字段分组之后,在对组内的集合按照某个字段继续分组*)

案例代码如下:
public static void main(String[] args) {
ListUser> userList = new ArrayList>();
服务器托管网 userList.add(new User(1001, "java", "123"));
userList.add(new User(1002, "html", "123"));
userList.add(new User(1003, "css", "123"));
userList.add(new User(1004, "js", "123"));
userList.add(new User(1005, "java", "123"));
userList.add(new User(1006, "css", "123"));
// 按照 name 分组
MapString, ListUser>> map = userList.stream().collect(Collectors.groupingBy(User::getUname));
System.out.println(map);
// 按照 name 分组,并且计算每一组中 id 平均值
MapString, Double> map1 = userList.stream().collect(Collectors.groupingBy(User::getUname, Collectors.averagingDouble(User::getId)));
System.out.println(map1);
}
(6)partitioningBy方法
partitioningBy方法是分区的,它是一种特殊的分组groupingBy,前面介绍了groupingBy是将数组按照某个key分组成多个集合,最终得到一个Map结果。
而这里的partitioningBy意味分区,它是将数据分为两组,一组是满足条件的分区,另外一组则是不满足条件的分组,最终返回的结果是一个Map的结果格式,其中boolean只有两个值:true和false。
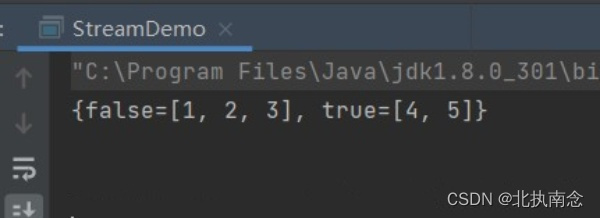
public static void main(String[] args) {
// 分区
Integer[] nums = new Integer[] { 1, 2, 3, 4, 5 };
// 将大于 3 的作为一组
MapBoolean, ListInteger>> map = Arrays.stream(nums).collect(Collectors.partitioningBy(item -> item > 3));
System.out.println(map);
}
运行结果如下所示:
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
