
本文主要通过例子介绍了CUDA异构编程模型,需要说明的是Grid、Block和Thread都是逻辑结构,不是物理结构。实现例子代码参考文献[2],只需要把相应章节对应的CMakeLists.txt文件拷贝到CMake项目根目录下面即可运行。
1.Grid、Block和Thread间的关系
GPU中最重要的2种内存是全局内存和共享内存,前者类似于CPU系统内存,而后者类似于CPU缓存,然后GPU共享内存可由CUDA C内核直接控制。GPU简化的内存结构,如下所示:
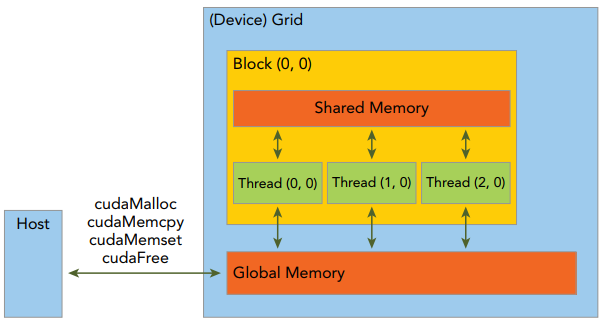
由一个内核启动所产生的所有thread统称为一个grid,同一个grid中的所有thread共享相同的全局内存空间。一个grid由多个block构成,一个block包含一组thread,同一block内的thread通过同步、共享内存方式进行线程协作,不同block内的thread不能协作。由block和grid构成的2层的thread层次结构,如下所示:
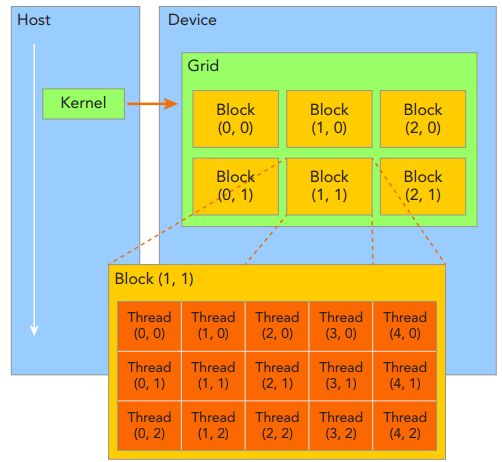
CUDA可以组织3维的grid和block。blockIdx表示线程块在线程格内的索引,threadIdx表示块内的线程索引;blockDim表示每个线程块中的线程数,gridDim表示网格中的线程块数。这些变量允许开发人员在编写CUDA代码时,从逻辑上管理和组织线程块和网格的大小,从而优化并行执行的效率。如下所示:

2.检查网格和块的索引和维度(checkDimension.cu)
确定grid和block的方法为先确定block的大小,然后根据实际数据大小和block大小的基础上计算grid维度,如下所示:
//检查网格和块的索引和维度
#include
#include
__global__voidcheckIndex(void){
//gridDim表示grid的维度,blockDim表示block的维度,grid维度表示grid中block的数量,block维度表示block中thread的数量
printf("threadIdx:(%d,%d,%d)blockIdx:(%d,%d,%d)blockDim:(%d,%d,%d)"
"gridDim:(%d,%d,%d)n",threadIdx.x,threadIdx.y,threadIdx.z,
blockIdx.x,blockIdx.y,blockIdx.z,blockDim.x,blockDim.y,blockDim.z,
gridDim.x,gridDim.y,gridDim.z);//printf函数只支持Fermi及以上版本的GPU架构,因此编译的时候需要加上-arch=sm_20编译器选项
}
intmain(intargc,char**argv){
//定义全部数据元素
intnElem=6;
//定义grid和block的结构
dim3block(3);//表示一个block中有3个线程
dim3grid((nElem+block.x-1)/block.x);//表示grid中有2个block
//检查grid和block的维度(host端)
printf("grid.x%dgrid.y%dgrid.z%dn",grid.x,grid.y,grid.z);
printf("block.x%dblock.y%dblock.z%dn",block.x,block.y,block.z);
//检查grid和block的维度(device端)
checkIndex>>();
//离开之前重置设备
cudaDeviceReset();
return0;
}
输出结果如下所示:
threadIdx:(0,0,0)blockIdx:(1,0,0)blockDim:(3,1,1)gridDim:(2,1,1)
threadIdx:(1,0,0)blockIdx:(1,0,0)blockDim:(3,1,1)gridDim:(2,1,1)
threadIdx:(2,0,0)blockIdx:(1,0,0)blockDim:(3,1,1)gridDim:(2,1,1)
threadIdx:(0,0,0)blockIdx:(0,0,0)blockDim:(3,1,1)gridDim:(2,1,1)
threadIdx:(1,0,0)blockIdx:(0,0,0)blockDim:(3,1,1)gridDim:(2,1,1)
threadIdx:(2,0,0)blockIdx:(0,0,0)blockDim:(3,1,1)gridDim:(2,1,1)
grid.x2grid.y1grid.z1
block.x3block.y1block.z1
3.在主机上定义网格和块的大小(defineGridBlock.cu)
接下来通过一个1维网格和1维块讲解当block大小变化时,gird的size也随之变化,如下所示:
#include
#include
intmain(intargc,char**argv){
//定义全部数据元素
intcElem=1024;
//定义grid和block结构
dim3block(1024);
dim3grid((cElem+block.x-1)/block.x);
printf("grid.x%dgrid.y%dgrid.z%dn",grid.x,grid.y,grid.z);
//重置block
block.x=512;
grid.x=(cElem+block.x-1)/block.x;
printf("grid.x%dgrid.y%dgrid.z%dn",grid.x,grid.y,grid.z);
//重置block
block.x=256;
grid.x=(cElem+block.x-1)/block.x;
printf("grid.x%dgrid.y%dgrid.z%dn",grid.x,grid.y,grid.z);
//重置block
block.x=128;
grid.x=(cElem+block.x-1)/block.x;
printf("grid.x%dgrid.y%dgrid.z%dn",grid.x,grid.y,grid.z);
//离开前重置device
cudaDeviceReset();
return0;
}
输出结果,如下所示:
grid.x1grid.y1grid.z1
grid.x2grid.y1grid.z1
grid.x4grid.y1grid.z1
grid.x8grid.y1grid.z1
4.基于GPU的向量加法(sumArraysOnGPU-small-case.cu)
#include
#include
#defineCHECK(call)
//{
//constcudaError_terror=call;
//if(error!=cudaSuccess)
//{
//printf("Error:%s:%d,",__FILE__,__LINE__);
//printf("code:%d,reason:%sn",error,cudaGetErrorString(error));
//exit(1);
//}
//}
voidcheckResult(float*hostRef,float*gpuRef,constintN)
{
doubleepsilon=1.0E-8;
boolmatch=1;
for(inti=0;i{
if(abs(hostRef[i]-gpuRef[i])>epsilon)
{
match=0;
printf("Arraysdonotmatch!n");
printf("host%5.2fgpu%5.2fatcurrent%dn",hostRef[i],gpuRef[i],i);
break;
}
}
if(match)printf("Arraysmatch.nn");
}
voidinitialData(float*ip,intsize)
{
//generatedifferentseedforrandomnumber
time_tt;
srand((unsignedint)time(&t));
for(inti=0;i{
ip[i]=(float)(rand()&0xFF)/10.0f;
}
}
voidsumArraysOnHost(float*A,float*B,float*C,constintN)
{
for(intidx=0;idx{
C[idx]=A[idx]+B[idx];
}
}
__global__voidsumArraysOnGPU(float*A,float*B,float*C)
{
//inti=threadIdx.x;//获取线程索引
inti=blockIdx.x*blockDim.x+threadIdx.x;//获取线程索引
printf("threadIdx.x:%d,blockIdx.x:%d,blockDim.x:%dn",threadIdx.x,blockIdx.x,blockDim.x);
C[i]=A[i]+B[i];//计算
}
intmain(intargc,char**argv){
printf("%sStarting...n",argv[0]);
//设置设备
intdev=0;
cudaSetDevice(dev);
//设置vectors数据大小
intnElem=32;
printf("Vectorsize%dn",nElem);
//分配主机内存
size_tnBytes=nElem*sizeof(float);
float*h_A,*h_B,*hostRef,*gpuRef;//定义主机内存指针
h_A=(float*)malloc(nBytes);//分配主机内存
h_B=(float*)malloc(nBytes);//分配主机内存
hostRef=(float*)malloc(nBytes);//分配主机内存,用于存储host端计算结果
gpuRef=(float*)malloc(nBytes);//分配主机内存,用于存储device端计算结果
//初始化主机数据
initialData(h_A,nElem);
initialData(h_B,nElem);
memset(hostRef,0,nBytes);//将hostRef清零
memset(gpuRef,0,nBytes);//将gpuRef清零
//分配设备全局内存
float*d_A,*d_B,*d_C;//定义设备内存指针
cudaMalloc((float**)&d_A,nBytes);//分配设备内存
cudaMalloc((float**)&d_B,nBytes);//分配设备内存
cudaMalloc((float**)&d_C,nBytes);//分配设备内存
//从主机内存拷贝数据到设备内存
cudaMemcpy(d_A,h_A,nBytes,cudaMemcpyHostToDevice);//d_A表示目标地址,h_A表示源地址,nBytes表示拷贝字节数,cudaMemcpyHostToDevice表示拷贝方向
cudaMemcpy(d_B,h_B,nBytes,cudaMe服务器托管网mcpyHostToDevice);//d_B表示目标地址,h_B表示源地址,nBytes表示拷贝字节数,cudaMemcpyHostToDevice表示拷贝方向
//在host端调用kernel
dim3block(nElem);//定义block维度
dim3grid(nElem/block.x);//定义grid维度
sumArraysOnGPU>>(d_A,d_B,d_C);//调用kernel,>>表示执行配置,d_A,d_B,d_C表示kernel参数
printf("Executionconfiguration>>n",grid.x,block.x);//打印执行配置
//拷贝device结果到host内存
cudaMemcpy(gpuRef,d_C,nBytes,cudaMemcpyDeviceToHost);//gpuRef表示目标地址,d_C表示源地址,nBytes表示拷贝字节数,cudaMemcpyDeviceToHost表示拷贝方向
//在host端计算结果
sumArraysOnHost(h_A,h_B,hostRef,nElem);
//检查device结果
checkResult(hostRef,gpuRef,nElem);
//释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
//释放主机内存
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return0;
}
输出结果如下所示:
threadIdx.x:0,blockIdx.x:0,blockDim.x:32
threadIdx.x:1,blockIdx.x:0,blockDim.x:32
threadIdx.x:2,blockIdx.x:0,blockDim.x:32
threadIdx.x:3,blockIdx.x:0,blockDim.x:32
threadIdx.x:4,blockIdx.x:0,blockDim.x:32
threadIdx.x:5,blockIdx.x:0,blockDim.x:32
threadIdx.x:6,blockIdx.x:0,blockDim.x:32
threadIdx.x:7,blockIdx.x:0,blockDim.x:32
threadIdx.x:8,blockIdx.x:0,blockDim.x:32
threadIdx.x:9,blockIdx.x:0,blockDim.x:32
threadIdx.x:10,blockIdx.x:0,blockDim.x:32
threadIdx.x:11,blockIdx.x:0,blockDim.x:32
threadIdx.x:12,blockIdx.x:0,blockDim.x:32
threadIdx.x:13,blockIdx.x:0,blockDim.x:32
threadIdx.x:14,blockIdx.x:0,blockDim.x:32
threadIdx.x:15,blockIdx.x:0,blockDim.x:32
threadIdx.x:16,blockIdx.x:0,blockDim.x:32
threadIdx.x:17,blockIdx.x:0,blockDim.x:32
threadIdx.x:18,blockIdx.x:0,blockDim.x:32
threadIdx.x:19,blockIdx.x:0,blockDim.x:32
threadIdx.x:20,blockIdx.x:0,blockDim.x:32
threadIdx.x:21,blockIdx.x:0,blockDim.x:32
threadIdx.x:22,blockIdx.x:0,blockDim.x:32
threadIdx.x:23,blockIdx.x:0,blockDim.x:32
threadIdx.x:24,blockIdx.x:0,blockDim.x:32
threadIdx.x:25,blockIdx.x:0,blockDim.x:32
threadIdx.x:26,blockIdx.x:0,blockDim.x:32
threadIdx.x:27,blockIdx.x:0,blockDim.x:32
threadIdx.x:28,blockIdx.x:0,blockDim.x:32
threadIdx.x:29,blockIdx.x:0,blockDim.x:32
threadIdx.x:30,blockIdx.x:0,blockDim.x:32
threadIdx.x:31,blockIdx.x:0,blockDim.x:32
L:20200706_C++C++Program20231003_ClionProgramcmake-build-debug20231003_ClionProgram.exeStarting...
Vectorsize32
Executionconfiguration>>
Arraysmatch.
5.其它知识点
(1)host和device同步
核函数的调用和主机线程是异步的,即核函数调用结束后,控制权立即返回给主机端,可以调用cudaDeviceSynchronize(void)函数来强制主机端程序等待所有的核函数执行结束。当使用cudaMemcpy函数在host和device间拷贝数据时,host端隐式同步,即host端程序必须等待数据拷贝完成后才能继续执行程序。需要说明的是,所有CUDA核函数的启动都是异步的,当CUDA内核调用完成后,控制权立即返回给CPU。
(2)函数类型限定符
函数类型限定符指定一个函数在host上执行还是在device上执行,以及可被host调用还是被device调用,函数类型限定符如下所示:

说明:__device__和__host__限定符可以一起使用,这样可同时在host和device端进行编译。
参考文献:
[1]《CUDA C编程权威指南》
[2]2.1-CUDA编程模型概述:https://github.com/ai408/nlp-engineering/tree/main/20230917_NLP工程化/20231004_高性能计算/20231003_CUDA编程/20231003_CUDA_C编程权威指南/2-CUDA编程模型/2.1-CUDA编程模型概述
服务器托管,北京服务器托管,服务器租用 http://服务器托管网www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
阅读文本大概需要3分钟。 2019刚刚开始,社交软件先火了一把,多个公司集结发布社交APP软件。IM、视频等软件到底还有没有机会;到底还有还有没有技术含量。今天就来聊一聊IM、视频。 目前腾讯、阿里、百度、网易等大厂都推出了各自的I…
