
代码的分层重构
Hi,我是阿昌,今天学习记录的是关于代码的分层重构的内容。
来看看如何重构整体的代码,也就是如何对代码分层。
一、遗留系统中常见的模式
一个学校图书馆的借书系统。当时的做法十分“朴素”,在点击“借阅”按钮的事件处理器中,直接读取借书列表中的书籍 ID,然后连接数据库,执行一条 update 语句,把这些书籍的借阅者字段改成当前的学生 ID。
Eric Evans 的《领域驱动设计》这本书,才发现这种做法就是书中介绍的 Smart UI 模式。它虽然简单好理解,但归根结底还是一种面向过程的编程思想。
一旦逻辑变得更复杂,这种模式的问题就会凸显出来。举个最简单的例子,比如借书前需要校验学生的类型,本科生最多可以借 3 本,而研究生最多可以借 10 本。
如果本科生借阅了 5 本书,在点击按钮的时候就会弹出错误消息。我们用伪代码来表示就是:
var bookCount = bookDataTable.count
var studentType = DB.query("SELECT TYPE FROM STUDENTS WHERE ID = " + studentId)
if (studentType = "本科生" && bookCount > 3)
MessageBox.error("本科生一次最多借阅3本图书")
if (studentType = "研究生" && bookCount > 10)
MessageBox.error("研究生一次最多借阅10本图书")
for(var book in bookDataTable.values)
DB.update("UPDATE BOOKS SET BORROWER_ID = " + studentId + " WHERE BOOK_ID = " + book.id)
也许只是添加这几行代码,并不觉是什么大问题,但紧接着教师的借阅数量也需要校验,讲师和教授的借阅数量也会有不同的限制。
当逻辑越来越复杂,这种过程式的代码就只能向一个地方堆代码。即使可以抽一些函数出来,也只能是杯水车薪。
其实还有更严重的问题:由于将界面展示、业务逻辑、数据库访问都放在一个文件中,发散式变化的坏味道十分严重。
调整界面布局要改这个文件,修改业务逻辑要改这个文件,甚至修改表名、列名也要修改这个文件。除了早期的桌面客户端应用,还有在 JSP 和 ASP 中直接写业务逻辑并访问数据库的,也属于 Smart UI。
除此之外,Martin Fowler 在《企业应用架构模式》还提出了事务脚本(Transaction Script)模式。
该模式分离了用户界面和业务逻辑,但仍然还是按数据的方式去组织业务,没有建立对象模型。
为了改善这种状况,人们开始重构这种模式。
将界面逻辑、业务逻辑和数据库访问分离开来,形成了 UI、Service、Dao 这样的三层结构。
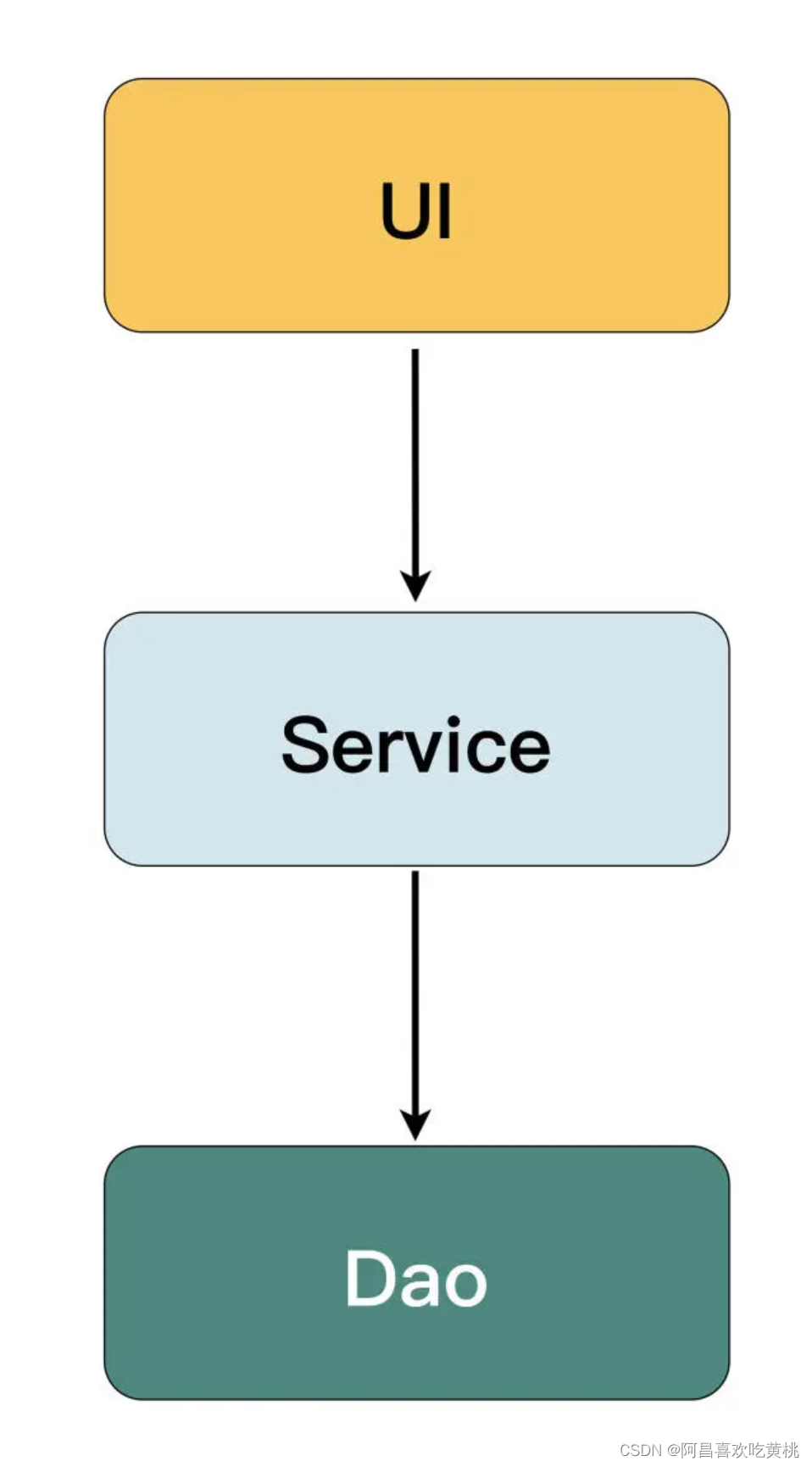
上面的代码也就变成了下面这样(让从伪代码切换回 Java)。
// UI层
BookService bookService = new BookService();
bookService.borrowBook(userData, bookDataList);
// Service层
if ("教师".equals(userData.getType())) {
if ("讲师".equals(userData.getLevel()) || "助教".equals(userData.getLevel())) {
if (bookDataList.count() > 20) {
throw new BookBorrowException("讲师和助教一次最多借阅20本图书");
}
}
else if ("教授".equals(userData.getLevel()) || "副教授".equals(userData.getLevel())) {
if (bookDataList.count() > 50) {
throw new BookBorrowException("教授和副教授一次最多借阅50本图书");
}
}
}
else if ("学生".equals(userData.getType())) {
if ("本科生".equals(userData.getLevel())) {
if (bookDataList.count() > 3) {
throw new BookBorrowException("本科生一次最多借阅3本图书");
}
}
else if ("研究生".equals(userData.getLevel())) {
if (bookDataList.count() > 10) {
throw new BookBorrowException("研究生一次最多借阅50本图书");
}
}
}
BookDao bookDao = new BookDao();
bookDao.borrowBook(userData.getUserId(), bookDataList)
// Dao层
for(var book in bookDataList)
DB.update("UPDATE BOOKS SET BORROWER_ID = " + userId + " WHERE BOOK_ID = " + book.getId())
感觉是不是跟平时编写的代码十分类似?这样的分层仍然是过程式的,和事务脚本相比,并没有本质区别。
它虽然在 Service 层向 Dao 层传递数据时使用了对象,但这种不含任何行为的贫血模型也只是起了数据传递的作用。而且,像代码中的 UserData 和 BookData 所定义的位置往往都是很随意的,有时定义在 UI 层,有时定义在 Service 层,有时定义在 Dao 层。
上面图中所画的箭头只是代表了数据流动的方向,而不是对象依赖的方向。这种模式最大的问题在于,当逻辑变得复杂时,服务层的代码会变得越来越臃肿,不同的服务之间也很难相互调用和复用逻辑,每一个服务类都将变成上帝类(God Class)。
二、领域模型
随着面向对象编程范式的流行,越来越多的人倾向于用对象为要解决的问题建立模型(Domain Model),用对象来描述问题中的不同元素。
元素中所有的数据和行为都将在对象中有所体现。也就是说,不再用过程来控制逻辑,而是将逻辑分别放入不同的对象中。
对于上面借书的例子,如果把各种判断借书数量是否合规的逻辑,放到不同的 User 对象中去,将书籍借阅的逻辑,也就是设置书籍借阅状态的逻辑,放到 Book 中去,就会得到这样的代码:
public abstract class User {
public abstract void borrow(Book[] books);
}
public class UndergraduateStudent extends User {
@Override
public void borrow(Book[] books) {
if (books.length > 3) {
throw new BookBorrowException("本科生一次最多借阅3本图书");
}
for(Book book : books) {
book.lendTo(this);
}
}
}
public class Book {
public void lendTo(User user) {
status = BookStatus.LEND_OUT;
borrowerId = user.getId();
}
}
可以看到,这段代码充分利用了面向对象继承和封装的优势,分解了原来的复杂逻辑,将其分散到不同的对象中去。
乍一看也许有点困惑,因为逻辑十分分散,而且想看懂一个业务场景,要在不同的对象之间来回跳转,远不如过程式代码那样直观。而且还会有各种纠结的地方,比如到底是“人借阅书”,还是“书借给人”。但这其实就是面向对象的优雅之处,它对客观世界进行了建模,但是并不需要完全去照搬客观世界。
“人借阅书”还是“书借给人”并不重要,重要的是如何更顺畅地编写代码。例子中,既有“人借阅书”,又有“书借给人”。“人借阅书”是为了解决在借阅时的校验问题,“书借给人”是为了将人的信息标记在书上。
在了解了领域模型模式后,一定迫不及待地想把事务脚本模式的代码都重构成领域模型了吧?
这个重构过程中,可能分辨不出自己的代码到底属于哪种模式。一个小技巧,就是看要获取一个值的时候,是从对象中获取,还是直接从数据库中查询。
比如想查询一本书是否被借出了,查询数据库 BOOKS 表,如果 BORROWER_ID 这个字段为空,就返回 1,那这就是事务脚本模式:
String sql = "SELECT COUNT(*) FROM BOOKS WHERE BOOK_ID = :bookId AND BORROWER_ID IS NULL";"
boolean isBorrowed = DB.query(sql) == 0;
这种处理方式把数据和模型割裂开了,而且 IS NULL 和 ==0 大概率会把人搞晕,认知负载非常高。
如果用 SQL 去获取一个模型,然后在代码中判断 getBorrowerId 方法的返回值是否为空,那就是贫血模型模式:
String sql = "SELECT * FROM BOOKS WHERE BOOK_ID = :bookId";
Book book = DB.query(sql);
if (book.getBorrowerId() != null) { }
这种处理方式把模型当做数据的载体,比单纯的事务脚本要好很多。但是所有判断逻辑都会落在客户端代码处。
如果用 SQL 去获取一个模型,然后调用模型的 isBorrowed 方法来判断书籍是否被借出,就是领域模型模式:
String sql = "SELECT * FROM BOOKS WHERE BOOK_ID = :bookId";
Book book = DB.query(sql);
if (book.isBorrowed()) { }
这种处理方式把模型当做数据和行为的载体,把行为封装在了领域模型内部。
领域模型最重要的一点是,要随着业务的变化而不断演进。尽管上面的模型对于大学编程课的作业,可能还说得过去,但真实的借阅场景显然更复杂。比如,我希望查询一本书籍的所有借阅历史。
书籍的借阅是有有效期的,当有效期快到了的时候,我希望给用户发短信提醒,有效期过了就会有相应的惩罚逻辑。当“借阅”这个名词在业务的描述中频繁出现时,就是一种要为它建模的信号了。
对于现在的模型来说,“借阅”体现在 Book 对象的 borrowerId 这个字段上。也可以继续在 Book 上添加 validTo 这种字段来表示借阅的有效期,但显然借阅历史是无法表示出来的。
对于持久化来讲,借阅历史的多条数据显然无法用书籍的一条数据来表示。这时,我们就需要为“借阅”来单独建模了。作为书籍和用户之间的关联关系,它其实是某种关联对象(Association Object)。
public class Borrowing {
private User user;
private Book book;
}
public class User {
private ListBorrowing> borrowings;
public void borrow(Book[] books) {
for(Book book : books)
borrowings.add(new Borrowing(this, book));
}
}
当 Borrowing 这个模型建立起来后,它就可以持久化起来作为借阅的历史记录,也可以在它上面添加各种业务字段,如有效期等。
三、数据映射器和仓库
在上面的代码中,并没有添加任何数据访问相关的逻辑。这也是领域模型模式的一个难点。
领域模型中的字段需要与数据库中的表字段进行双向映射,通常来说,可以继续使用之前的 Dao 来实现这种映射。
例如当一个借阅发生时,你可以:
public class BorrowingDao {
public void insert(Borrowing borrowing) {
String sql = "INSERT INTO BORROWINGS...";
// 执行SQL
}
}
把这种方式叫做数据映射器(Data Mapper)模式,它分离了领域模型和数据库访问代码的细节,也封装了数据映射的细节。
然而不管是叫 BorrowingDao 还是 BorrowingMapper,都暗示了它们与数据库的关系。
在领域模型中,往往希望模型更加“干净”,希望使用的是一种和数据访问无关的组件。
另一方面,这种模式也导致表和领域对象的一一对应。在简单的业务场景下这并不是问题,但在复杂的情况下,你就无法设计出合理的模型。比如上面的例子,一个借阅就是一个 Borrowing,这时你很可能放弃给 User 和 Book 建模,而直接去构建 Borrowing 模型,这就又回到事务脚本的老路上去了。
还有一点就是,当查询的需求变得复杂时,数据映射器就显得力不从心了。这时需要使用的是仓库(Repository)模式,让它来负责协调领域模型和数据映射器。仓库模式又被翻译为资源库或者仓储,不过我更倾向于翻译为仓库。在领域驱动设计中,构造一个新的复杂的领域模型时,我们可以使用工厂(Factory)模式,那工厂“生产”出来的“产品”,自然要放到仓库中了。
Repository 还有一层意思,就是“知识库”或“智囊团”。之所以把它放在数据映射器之前,就是因为它比数据映射器更懂得如何去查询领域对象,你可以基于它来设计任何你想要的查询。
仓库的接口与集合的接口十分接近,可以向仓库中添加对象,也可以从中删除对象,就好像是在操作内存中的集合一样。而实际上,真正执行操作的,是封装在仓库内部的数据映射器。
仓库不过是提供了一个更加面向对象的方式,将领域对象和数据访问隔离开来。
public class UserRepository {
public void add(User user) { }
public void save(User user) { }
public User findById(long userId) { }
}
还可以为各个仓库创建接口,定义在领域对象所在的包中。将仓库的实现类和数据映射器定义在一起,这样领域模型不依赖任何数据访问的组件,就显得十分整洁了。
在使用仓库模式时,只从领域对象的源头操作。不会去对 Borrowing 创建一个 BorrowingRepository,而是将 Borrowing 放到 User 内部,然后通过 UserRepository 去获取 User,进而获取到当前 User 所有的 Borrowing。
这么做的原因是,Borrowing 只是一个关联对象,并不是一个所谓的“源头”。如果用领域驱动设计中的术语来说就是,Borrowing 不是一个聚合根(Aggregate Root)。
也可以将这个“源头”理解为工厂模式创建出来的产品。要去仓库中取的是一个产品(聚合根),而不是这个产品的某个零件(关联对象)。
这也是为什么在 DDD 中,仓库只是针对聚合根的,只有聚合根才有仓库,聚合根上的其他实体或值对象是没有仓库的。
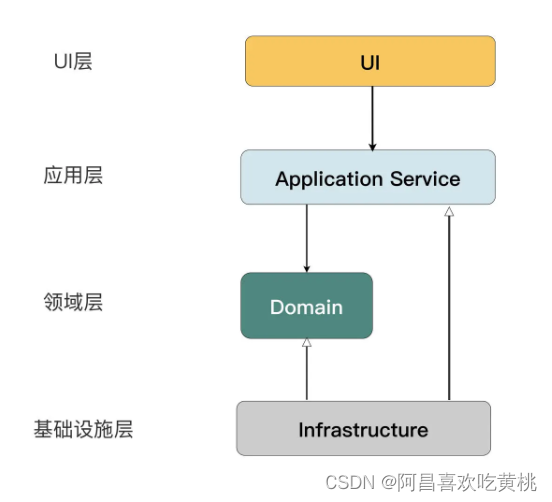
最后,由于仓库的接口是面向集合的,复杂查询自然也不在话下。我们在实际设计时,为了实现依赖倒置,即领域层不依赖数据访问组件,可以将仓库的接口定义在领域层,而将实现类和数据映射器定义在数据访问层。
四、应用服务
解决了业务逻辑和数据访问分离的问题,把目光向“前”看,看看业务逻辑之前的逻辑应该如何处理。
一个软件系统,除了业务逻辑之外,还存在一些非业务的逻辑。比如用户认证、事务、日志记录等。
像前面说过的如果一个借阅快到期了就发送通知,这种对于第三方(短信通知)服务的编排,也属于这类逻辑。
Martin Fowler 等人把这类逻辑叫做应用逻辑(Application Logic)。可以理解成是因为有了应用程序,才会有的逻辑。
为了把业务逻辑和应用逻辑分离,可以使用服务层(Service Layer)模式。它是一组在领域模型之上构建的应用服务(Application Service),用来处理某个业务场景相关的应用逻辑。
从某种意义上,也可以认为服务层是对领域模型的封装,可以对 UI 层提供更加友好的接口。由于它跟业务场景一一对应,所以 Bob 大叔在整洁架构里,管它叫做用例(Usecase)。
对于短信通知的场景,应用服务的代码如下所示:
public class BorrowingValidityService {
public void validate(long userId) {
User user = userRepository.findById(userId);
for(Borrowing borrowing : users.allBorowings()) {
if(!borrowing.isValid()) {
notificationService.send(new BorrowingInvalidMessage(borrowing.getBook()));
}
}
}
}
注意,判断一个借阅是否有效属于业务逻辑,而在无效时发送短信则属于应用逻辑,要在应用服务中处理。
这相当于,领域模型提供了判断借阅是否有效的能力,而如何使用这种能力,是应用逻辑来决定的,不同的场景有不同的用法。
而对于借阅的应用服务,代码如下:
public class BorrowService {
public void borrow(long userId, long[] bookIds) {
User user = userRepository.findById(userId);
Book[] books = bookRepository.findByIds(bookIds);
user.borrow(books);
userRepository.update(user);
}
}
在应用服务中,通过仓库获取领域模型,调用领域模型中的方法,然后再通过仓库更新领域模型。
如果了解领域驱动设计(DDD),一定会相当熟悉应用服务、领域模型、仓库这些模式。但这些模式并不只属于 DDD。
在 DDD 诞生之前,这些模式就已经存在了,《企业应用架构模式》中甚至还提出了很多可以替代的模式。
DDD 只是把这些模式进行组合,形成了一套以领域模型模式为基础的最佳实践。
五、总结
遗留系统中常见的代码样例说起,将一个事务脚本一步步重构成了 DDD 中常见的分层架构。
这期间穿插着介绍了领域模型、数据映射器、仓库、应用服务等多种模式。不管系统位于这个路线的哪个阶段,都应该有能力把它重构好。项目业务没有这么复杂,事务脚本也能解决绝大部分应用场景。
没错,事务脚本本身就是一种解决领域逻辑位置的模式,这条路最终会走向混乱。
有的时候,之所以觉得业务没那么复杂,是因为在脑子里将业务映射成了数据库表,那么写出的代码自然是事务脚本。
如果不用大脑做这一层映射,而是先将业务直接反映到领域模型中,然后再用代码去实现到数据库表的映射,往往情况就会有所好转。
应该刻意培养自己领域建模的意识,如果没有这种意识,那么绝大多数软件对你来说,都只不过是 CRUD。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
一、AS400 简介 AS/400是一种主机型计算机,是IBM公司开发的。AS/400是IBM的应用服务器产品,针对企业级应用开发、重要应用系统支持进行设计开发。AS/400的系统工作环境中同时支持多种操作系统和多种编程语言的应用程序开发和运行,支持多用户…
