
软件系统是通过软件开发来解决某一个业务领域或问题单元而产生的一个交付物。而通过软件设计可以帮助我们开发出更加健壮的软件系统。因此,软件设计是从业务领域到软件开发之间的桥梁。而DDD是软件设计中的其中一种思想,旨在提供一种大型复杂软件的设计思路和规范。通过DDD思想可以让我们的业务架构、系统架构、部署架构、数据架构、工程架构等都具备高扩展性、高维护性和高测试性。
但是落地DDD是一件很困难的事情。首先在思想认知层面就比较难以突破。
DDD本身是一种思想,不是某种具体的技术,因此在代码实现和系统架构层面没有约束。而由于市面上成熟的ORM框架(比如hibernate、mybatis等),使得大部分软件开发都是直接面向数据库开发。在传统开发中的应用分层架构又和DDD思想的分层架构很类似。从而导致很多人在初学DDD时有一定的理解偏差,从而导致无法落地DDD思想。
这篇文章记录我对DDD的学习、感悟与项目工程代码重构实战心得!
一、Domin Primitive
领域“元数据”的意思。主要是讲解领域的基本准则。这也是使用DDD思想的基本准则。
1.1 隐性的概念显性化
exp:电话号码通常是由区号编码+号码组成。在实际的业务中会有很多需要电话号码的业务。比如登录认证、导购分销等业务;我们需要对电话号码进行基础性校验;获取区号编码等;在常规操作下,会在每一个用到电话号码的方法入口都会写大量的这种校验代码和判断代码,尽管我们可以将它的校验和获取区号编码抽离成util类(实际上大多数工程中都是这么做的),但这种方式治标不治本。基于DDD思想可以发现这里有一个隐性概念:区号编码。
我们可以基于DDD思想,将电话号码创建为一个拥有独立概念和行为的值对象:PhoneNumber,将基础性校验和获取编码等无状态行为封装在值对象中。这样在方法中就不需要再充斥着写大量的校验和判断。
1.2 隐性的上下文显性化
exp:在银行转账场景中,通常我们会说A账户给B账户转1000元。这里的1000元实际上有两层含义,数字1000,货币元。但我们通常会忽略货币单位元。导致在实现转账功能时,没有考虑到单位。一旦有国际转账时,就又会陷入到大量的if else中。
我们基于DDD思想,将钱创建为一个拥有独立概念和行为的值对象:Money,这样我们所说的钱才具备完整的概念。通过这种方式就可以将货币这个隐性上下文显性化,从而避免当前未识别到但是未来可能会爆雷的bug。
1.3 封装多对象行为
exp:在跨境转账的场景中,需要转换汇率,我们可以将转换汇率封装成一个值对象。通过封装金额计算逻辑和各种校验逻辑,使得整个方法极其简单。
1.4 DP和值对象的区别
DP是阿里大神提出来的概念;值对象是DDD思想中的概念。
学习之后,我个人认为DP是对值对象的进一步补充,使其拥有了更加完整的概念。在值对象【不变性】的基础上补充了【可校验性】和【独立行为】。当然也是要求【无副作用】。所谓的无副作用就是【状态不可变】。
1.5 DP和DTO的区别
| DTO | DP | |
|---|---|---|
| 功能 | 数据传输对象,属于技术细节 | 属于领域中的业务概念 |
| 数据关联性 | 不具备数据关联性 | 数据之间有强关联性 |
| 行为 | 无行为 | 拥有十分丰富的行为和业务逻辑 |
1.6 使用DP VS 不使用DP
| 不使用DP | 使用DP | |
|---|---|---|
| API接口清晰度 | 含混不清 | 方法签名清晰易懂 |
| 数据校验、错误处理 | 校验逻辑分布多个地方、大量重复代码 | 校验逻辑内聚,在方法边界外完成 |
| 业务代码的清晰度 | 充斥大量胶水代码,淹没业务核心逻辑 | 代码简洁明了,业务逻辑一目了然 |
| 测试复杂度 | TC数量:N_M_P(N个参数,每个参数M种校验,有P个方法在调用) | TC数量:N+M+P |
| 其他好处 | 整体安全性大大提升、不可变性、线程安全 |
二、应用架构
2.1 DDD思想下的标准应用架构
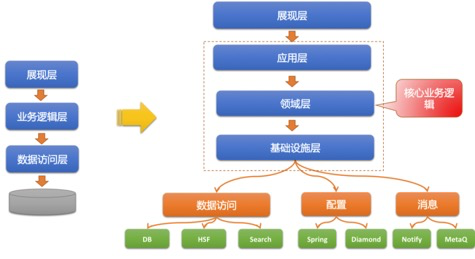
传统的MVC架构分为展现层、业务逻辑层和数据访问层,更加注重从展现层到数据访问层自上而下的交互,编写出来的代码像是脚本式代码。
而基于DDD原则,工程架构被分为应用层、领域层和基础设施层。将工程中不同的功能和职责划分到不同的层级中。核心的业务逻辑放在领域层中。
2.1.1 应用层
按照DDD的思想,应用层负责协调用户界面和领域层之间的交互。可以通俗的认为是对领域服务的编排,其本身不包含任何业务逻辑。
2.1.2 领域层
领域层负责实现核心业务的逻辑和规则。按照DDD的思想,这一层包含实体模块、值对象模块、事件、领域服务。
2.1.3 基础设施层
基础设施层不处理任何业务逻辑,只包含基础设施,通常包含数据库、定时任务、MQ、南向网关、北向网关等。
2.2 我对演进出六边形架构的理解
2.2.1 再谈应用层
在实际业务逻辑当中,除了用户界面层之外,还有其他外部系统会调用本服务,比如xxljob、MQ、或者提供给外部系统调用http或者rpc接口等。因此在实际当中,应用层应当是协调外部系统与领域层之间的交互。
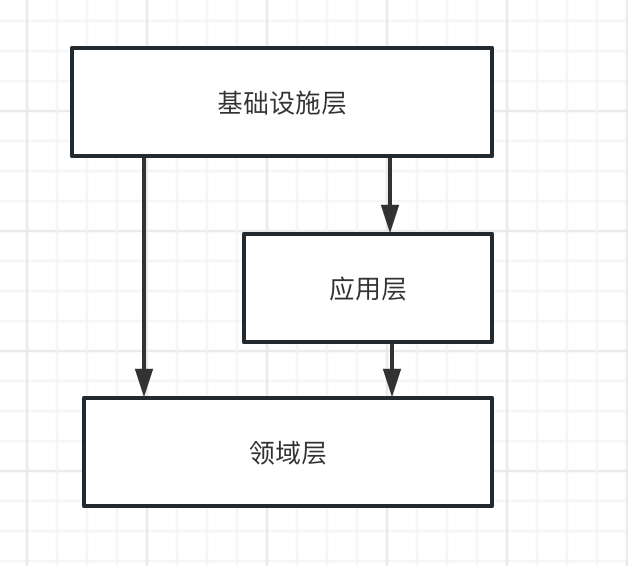
按照标准架构层级依赖关系来看,应用层依赖了领域层和基础设施层。由于依赖了基础设施层,因此破坏了应用层本身的可维护性和测试性。因此我们需要基于接口进行依赖倒置。
为了防止领域概念外泄,需要对应用层进一步的抽象为外部服务和内部服务,所有外部服务必须通过内部服务调用领域层。这样就可以防止领域模型的外泄。
2.2.2 再谈领域层
同样的,按照标准架构层级依赖关系,领域层依赖基础设施层,但这也破坏了领域层本身的可维护性和可测试性。因此我们基于DDD中的资源库思想,抽象repository层,通过接口实现依赖反转。让领域层不再依赖基础设施层。从而提高领域层本身的可维护性和可测试性。
2.2.3 再谈基础设施层
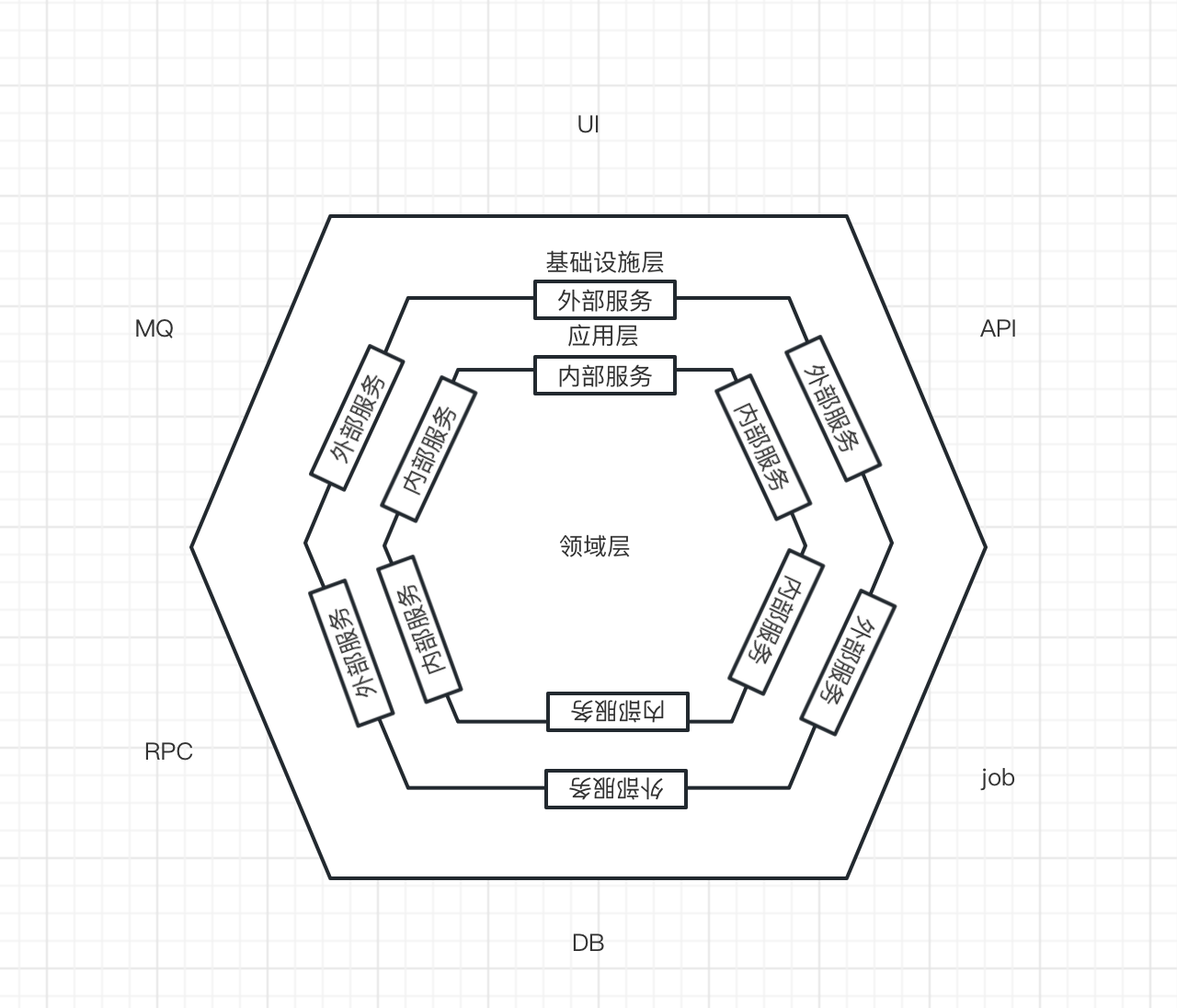
对于基础设施层而言,它主要作用是提供基础设施的能力,比如数据库、MQ、远程服务调用等。进一步抽象可以发现它们就是端口和适配器。通过端口实现与外部系统的交互,通过适配器完成数据和概念的转换。
2.2.4 演进出六边形架构
通过依赖反转,神奇的事情发生了。基础设施层变成了最外层。
我们结合对应用层、领域层和基础设施层进一步的理解再加上反转后的应用架构,便可以得到六边形架构:
2.3 工具类、配置类的代码应该放在哪里?
在一个实际的工程当中,除了上面所说的三层之外,通常会使用到一些工具类(JSON解析工具类、字符串工具类等)。各层可能都会使用到工具类。
从工具类的定位来看,它应当属于基础设施层,但是基础设施层属于最上层,如果放在基础设施层,那么就会破坏依赖顺序。因此我们在逻辑划分上可以把工具类归类为基础设施或者通用域,在具体的工程结构中,可以单独一个模块放工具类。
在实际工程中还有一种类型的代码是配置相关的。从业务维度划分的话可以分为业务类配置和基础设施类配置。因此我们需要根据配置的类型将其放在对应的位置。比如为了灵活应对业务,我们通常会配置一个动态开关,来动态调整业务的逻辑,这种业务开关类的配置就应该放在领域层;再比如数据库的配置属于基础设施配置,这类配置就应当放在基础设施层。
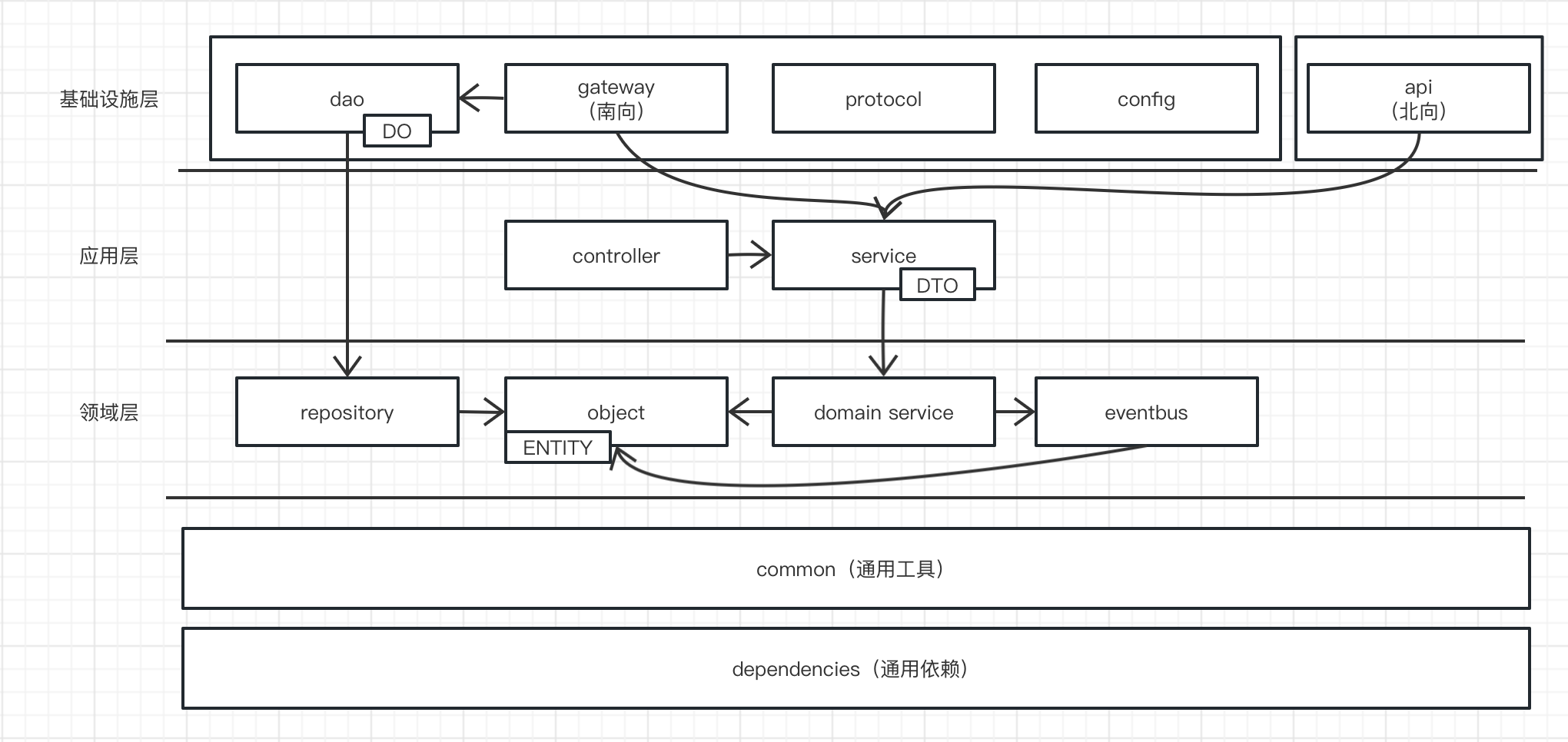
2.4 我对于项目的六边形架构的实践
我们团队做的的职责是业务底座,包含一系列的基础能力建设。其中对于IDaaS系统而言,基于六边形架构实现出以下工程结构:
三、repository模式
3.1 什么是repository模式?
在DDD思想中,repository表示资源库的概念,用于区分数据模型和领域模型。它操作的对象是聚合根,因此它属于领域层。
3.2 为什么要使用repository模式?
repository模式有两个非常重要的作用:1、与底层存储进行解偶;2、为解决贫血模型提供了一种规范。
3.3 什么是贫血模型?
由于过去ER模型以及主流ORM框架的发展,让很多开发者对实体的概念还停留在与关系形数据库映射这个层面。从而导致实体只有空洞的属性,而实体的业务逻辑散落各个service、util、helper、handler等各种角落中。这种现象就被称为贫血模型现象。
如何判断自己的工程是否有贫血模型现象?
1、大量的XxxDO或者Xxx:实体对象只包含与数据库表映射的属性,没有行为或者及其少量的行为;
2、业务逻辑在各种service、controller、util、helper、handler中:实体的业务逻辑散落在不同层级、不同类、不同方法中,相似场景有大量的重复代码。
3.4 为什么贫血模型不好?
无法保证实体对象的完整性和一致性:贫血模型下,实体属性的状态和值只能由调用方保证,但是属性的get和set是公开的,因此所有调用方都可以调用。所以无法保证对象的完整性和一致性。
操作实体对象的边界很难发现:由于对象只有属性,属性的边界值、调用范围不受实体自身控制,各个地方都可以调用,边界值和范围也只能由调用方自行保障。如果实体的边界值有所变化,那么所有调用方都需要调整,这种情况下很容易导致bug的产生。
强依赖底层:贫血模型下的实体和数据库模型映射、协议等。因此如果底层改变,那么上层逻辑需要全部跟着改变。“软件”变成了“固件”。
总结一句话:贫血模型下,软件的可维护性、可扩展性、可测试性极差!
扩展:
软件的可维护性=底层基础设施变化时,需要新增/修改的代码量是多少(越少可维护性越好)
软件的可扩展性=新增或变更业务逻辑时,需要新增/修改的代码量是多少(越少可扩展性越好)
软件的可测试性=每条TC执行的时长 * 新增或变更业务逻辑时产生的TC(时长越低/TC越少,测试性好)
3.5 实际情况中,为什么贫血模型难以消灭?
1、数据库思维
随着ER和ORM框架的发展,让多数开发者在刚入门的时候(自学、培训等方式),就认为实体就是数据库表映射;从而简单的将面向业务领域开发转变成了面向数据库开发,渐渐地就认为软件开发就是CRUD。
2、简单
尽管有些架构师或者开发人员知道贫血模型不好,但是企业为了占领市场,需要快速推出产品。因此工期被压缩的很厉害。而贫血模型恰好简单,在软件初期阶段,可以快速实现业务逻辑。从而迫使开发人员不得不“先实现了再说”。这种现象也是行业的普遍现象。
3、脚本思维
有些开发人员具备一定的抽象思维,将一些共性的代码写成util、helper、handler等类。但写代码依然是脚本思维。比如一个方法中,先来个字段校验代码,再来个对象转换代码,然后调用远程服务,对远程服务返回的结果再来个对象转换,……最后调用Dao类的方法保存对象。这种代码在很多工程中太常见了。
基于这些因素,导致贫血模型难以消灭。
这些因素的根本原因是什么?
根本原因就是,大部分的开发人员混淆了数据模型和领域模型这两个概念。
数据模型(Data Model):数据模型解决的是数据如何持久化、如何传输的问题;
领域模型(Domin Model):领域指的是某一个独立的业务领域或者问题空间,领域模型就是解决这个业务领域或者问题空间而设计的模型;解决的是业务领域的问题。
在DDD中,repository就是用于区分数据模型和领域模型提出来的概念。
3.6 使用repository之后,数据模型和领域模型如何转换?
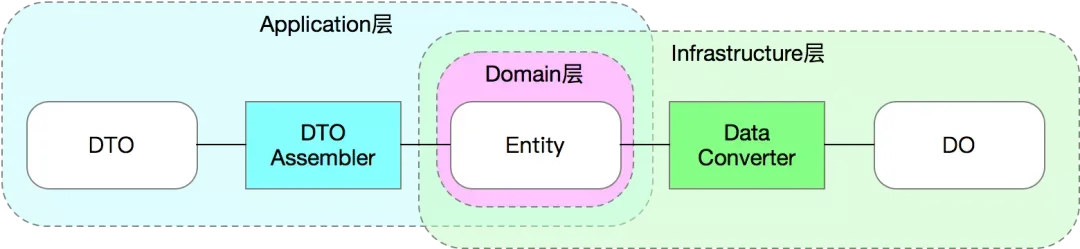
使用repository之后,数据模型和领域模型都各司其职。通过Assembler和Converter进行模型之间的转换。
在代码中,动态转换映射 VS 静态转换映射
虽然Assembler/Converter是非常好用的对象,但是当业务复杂时,手写Assembler/Converter是一件耗时且容易出bug的事情,所以业界会有多种Bean Mapping的解决方案,从本质上分为动态和静态映射。
动态映射方案包括比较原始的 BeanUtils.copyProperties、能通过xml配置的Dozer等,其核心是在运行时根据反射动态赋值。动态方案的缺陷在于大量的反射调用,性能比较差,内存占用多,不适合特别高并发的应用场景。而BeanUtils等copy类工具隐藏了内部copy的过程,很容易引发bug且不易排查。
MapStruct通过注解,在编译时静态生成映射代码,其最终编译出来的代码和手写的代码在性能上完全一致,且有强大的注解等能力。会节省大量的成本。
3.7 代码层面模型规范和比较
| DO | Entity | DTO | |
|---|---|---|---|
| 命名规范 | XxxDO | Xxx | XxxDTO/XxxRequest/XxxVO/XxxCommand等 |
| 代码层级 | 基础设施层 | 领域层 | 应用层 |
| 字段名称标准 | 于数据库字段保持一致 | 业务语言 | 和调用方商定 |
| 字段类型标准 | 和数据库字段保持一致 | 根据业务特征确定事基础类型还是值对象 | 和调用方商定 |
| 是否需要序列化 | 不需要 | 不需要 | 需要 |
| 转换器 | Assembler | Assembler/Converter | Converter |
3.8 代码层面repository规范
1、接口名命名规范
reposit服务器托管网ory中的接口名不要使用底层存储的名称(insert、update、add、delete、query等),而是尽量使用具有业务含义的命名。比如save、remove、find等。
2、接口的参数规范
repository操作的对象是聚合根。因此只能操作聚合根或者实体。这样才能屏蔽底层的数据模型,避免数据模型渗透到领域层。
四、领域层设计规范
4.1 实体类
大多数DDD架构的核心都是实体类,实体类包含了一个领域里的状态、以及对状态的直接操作。Entity最重要的设计原则是保证实体的不变性(Invariants),也就是说要确保无论外部怎么操作,一个实体内部的属性都不能出现相互冲突,状态不一致的情况。
4.1.1 创建即一致
constructor参数要包含所有必要属性,或者在constructor里有合理的默认值。
4.1.2 使用Factory模式来降低调用方复杂度
由于创建即一致的原则,导致实体的构造方法可能会很复杂,因此可以使用Factory模式来快速的构造出一个新的实体。降低调用方的复杂度。
4.1.3 尽量避免public setter
一个最容易导致不一致性的原因是实体暴露了public的setter方法,特别是set单一参数会导致状态不一致的情况。如果需要改变状态,尽量语义化方法名称。
4.1.4 通过聚合根保证主子实体的一致性
通常主实体会包含子实体,这时候主实体就需要起到聚合根的作用,即:
-
子实体不能单独存在,只能通过聚合根的方法获取到。任何外部的对象都不能直接保留子实体的引用
-
子实体没有独立的Repository,不可以单独保存和取出,必须要通过聚合根的Repository实例化
-
子实体可以单独修改自身状态,但是多个子实体之间的状态一致性需要聚合根来保障
exp:常见的电商域中聚合的案例如主子订单模型、商品/SKU模型、跨子订单优惠、跨店优惠模型等。
4.1.5 不可以强依赖其他聚合根实体或领域服务
一个实体的原则是高内聚、低耦合,即一个实体类不能直接在内部直接依赖一个外部的实体或服务。
对外部对象的依赖性会直接导致实体无法被单测;
以及一个实体无法保证外部实体变更后不会影响本实体的一致性和正确性。
正确依赖外部的方式
只保存外部实体的ID:这里我再次强烈建议使用强类型的ID对象,而不是Long型ID。强类型的ID对象不单单能自我包含验证代码,保证ID值的正确性,同时还能确保各种入参不会因为参服务器托管网数顺序变化而出bug。
针对于“无副作用”的外部依赖,通过方法入参的方式传入。比如上文中的equip(Weapon,EquipmentService)方法。
4.1.6 任何实体的行为只能直接影响到本实体(和其子实体)
这个原则更多是一个确保代码可读性、可理解的原则,即任何实体的行为不能有“直接”的”副作用“,即直接修改其他的实体类。这么做的好处是代码读下来不会产生意外。
另一个遵守的原因是可以降低未知的变更的风险。在一个系统里一个实体对象的所有变更操作应该都是预期内的,如果一个实体能随意被外部直接修改的话,会增加代码bug的风险。
4.1.7 可以利用enum来代替继承关系,后续也可以利用Type Object设计模式来做到数据驱动
4.2 领域服务
当一个业务逻辑需要用到多个领域对象作为输入,输出结果是一个值对象时,就说明需要使用到领域服务。
4.2.1 单对象策略型
这种领域对象主要面向的是单个实体对象的变更,但涉及到多个领域对象或外部依赖的一些规则。
在这种类型下,实体应该通过方法入参的方式传入这种领域服务,然后通过Double Dispatch来反转调用领域服务的方法。
什么是Double Dispatch
exp:对于“玩家”实体而言,有一个“equip()”装备武器的方法。
按照常规思路,“玩家”实体需要注入一个EquipmentService,然而实体只能保留自己的状态,
除此之外的其他对象实体无法保证其完整性,因此我们不通过注入的方式使用EquipmentService;
而是通过方法参数引入的方式来使用。即“玩家”实体的"equip()"方法定义为:
public void equip(Weapon weapon, EquipmentService equipmentService) {
if(equipmentService.canEquip(this, weapon)) {
this.weaponId = weapon.getId();
}
}
这种方式就称为Double Dispatch方式。
Double Dispatch是一个使用Domain Service经常会用到的方法,类似于调用反转。
4.2.2 跨对象事务型
当一个行为会直接修改多个实体时,不能再通过单一实体的方法作处理,而必须直接使用领域服务的方法来做操作。在这里,领域服务更多的起到了跨对象事务的作用,确保多个实体的变更之间是有一致性的。
4.2.3 通用组件型
这种类型的领域服务提供了组件化的行为,但本身又不直接绑死在一种实体类上。他的好处是可以通过组件化服务降低代码的重复性。
接口组件化来实现通用领域服务
exp:在游戏系统中,原价、NPC、怪物都是可移动的。因此可以设计一个Movable接口,
让玩家、NPC、怪物实体实现Movable接口。然后再实现一个MoveService,从而实现一个移动通用服务。
4.3 策略对象(Domain Policy)
Policy或者Strategy设计模式是一个通用的设计模式,但是在DDD架构中会经常出现,其核心就是封装领域规则。
一个Policy是一个无状态的单例对象,通常需要至少2个方法:canApply 和 一个业务方法。
canApply方法用来判断一个Policy是否适用于当前的上下文,如果适用则调用方会去触发业务方法。
通常,为了降低一个Policy的可测试性和复杂度,Policy不应该直接操作对象,而是通过返回计算后的值,
在Domain Service里对对象进行操作。
4.4 副作用的处理方法 – 领域事件
什么是副作用?
“副作用”也是一种领域规则。一般的副作用发生在核心领域模型状态变更后,同步或者异步对另一个对象的影响或行为。比如:当用于积分达到100时,会员等级升1级。
在DDD中,解决“副作用”的手段是领域事件。通过EventBus事件总线可以实现领域事件的传播。
目前领域事件的缺陷和展望
由于实体需要保证完整性,因此不能够直接依赖EventBus,所以EventBus只能保持全局singleton。但是全局singleton对象很难被单测,这就容易导致Entity对象很难被完整单测覆盖全。
五、写在最后
通过对于DDD的学习与实践,越来越能够体会到它作为一种软件设计思想和指导,对于大型复杂软件的建设十分有帮助。对于历史遗留屎山工程的重构也提供了一个很好的指导方向。
作者:京东科技孙黎明
来源:京东云开发者社区 转载请注明来源
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
