
作者:卢城,平台运维研发工程师,来自中移信息技术有限公司磐基PaaS团队
本文描述了 DeepFlow Server 用到的 MySQL 数据库改成 PostgreSQL 数据库的改造思路和实现细节。
01
DeepFlow Server 的数据库流向图
在进入正题之前,我们需要了解 MySQL 数据库在 DeepFlow 里的数据流向细节。
DeepFlow Server 使用 MySQL 数据库存储 Agent 收集的 Kubernetes Apiserver 拉取的全量资源数据和 watch 的资源变更数据,以供后续 Server 端进行观测数据的关联分析和资源查询展示。由于 kubernetes 的 watch 机制,资源数据变更频发,这就需要频繁增删改数据,这类操作像 ClickHouse 这种非关系数据库的架构并不适合,只有关系型数据库才能有效支撑。DeepFlow 在入库观测数据时用到 SmartEncoding 机制,为所有观测数据自动注入资源、服务和业务标签,首先 Agent 获取到字符串格式的标签并汇总到 Server 上,接下来 Server 会对所有的标签进行编码。对观测数据的 SmartEncoding 过程包含三个阶段:

DeepFlow 数据流向图
1.采集阶段
DeepFlow Agent 从 K8S ApiServer 的 list/watch 接口获取资源数据,同时 Agent 从 eBPF 获取网络观测数据,Agent 为每一条观测数据自动注入 VPC(Integer)、IP、PID 标签。
2.存储阶段
DeepFlow Agent 上报资源和观测数据给 DeepFlow Server 后,Server 根据 Agent 标记的 VPC、IP、PID 标签,为观测数据自动注入少量的、Int 编码的元标签(Meta Tag),包括 IP 和 PID 所对应的云资源属性、K8s 资源属性、进程属性,并存储到 ClickHouse 数据库中。
3.查询阶段
Server 自动计算所有自定义标签和元标签之间的关联关系,用户可直接通过 SQL/PromQL 在所有观测数据上查询(过滤、分组)所有的标签。
以笔者搭建一套 DeepFlow 的 Demo 环境中的数据举例:
MySQL库中存储了 K8s 资源数据,包括:
| 类型 | 表名 | 变更类表名(ch 开头) |
|---|---|---|
| 集群 | pod_cluster、kubernetes_cluster | ch_pod_cluster |
| 节点 | pod_node | ch_pod_node、ch_pod_node_port |
| 命名空间 | pod_namespace | ch_pod_ns、 |
| 容器服务 | pod_service 、pod_service_port | ch_pod_service_k8s_annotation、ch_pod_service_k8s_label |
| 工作负载 | pod_group、pod_group_port | ch_pod_group、ch_pod_group_port |
| Pod | pod | ch_pod、ch_pod_port、ch_pod_k8s_annotation、ch_pod_k8s_env、ch_pod_k8s_label |
| ReplicaSet / InPlaceSet | pod_rs | |
| Ingress | pod_ingress、pod_ingress_rule、pod_ingress_rule_backend | ch_pod_ingress |
| 区域、可用区、主机、VPC、子网 | az、region、vtap、ip_resource、vinterface、vinterface_ip、vl2、vl2_net、vm | ch_az、ch_region、ch_vtap、ch_vtap_port、ch_subnet、ch_device、ch_ip_relation |
顾名思义,ch 开头的表会不断的更新,而稳定最新的数据存在上面中间列的表中,中间列的表的共同特点是 id+名称+详细描述字段的组合。
同时,ClickHouse 中的 flow_log、flow_metrics 库中分别存储了网络链路原始数据和网络性能指标数据,库里每张表都存储了资源数据 id 关联数据。
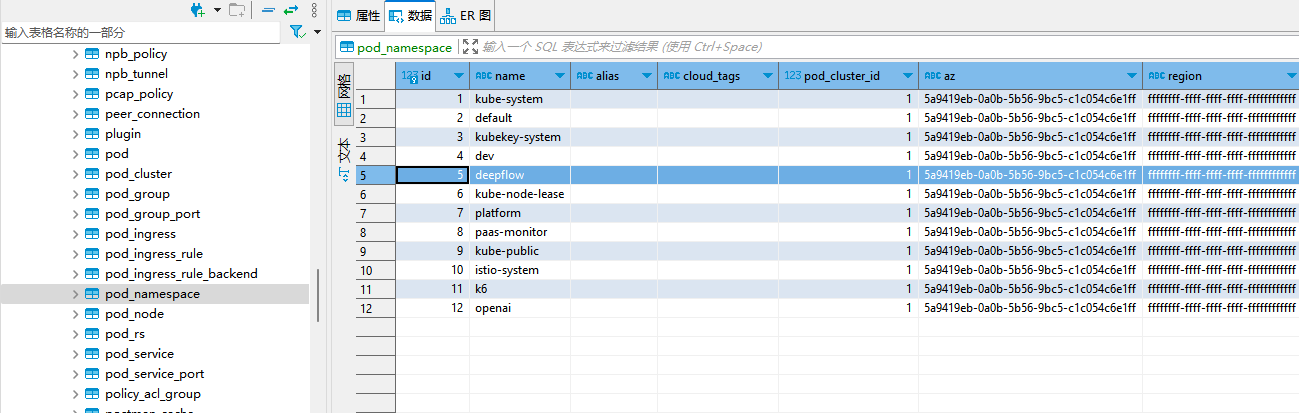
如下图 ClickHouse 的 flow_log.l7_flow_log 表中 pod_ns_id_0 (源端所属 namespace)和 pod_ns_id_1 (对端所属 namespace) 就对应 flow_tag.pod_ns_map 表中的 id。flow_tag.pod_ns_map 表数据来自 MySQL 数据库。

ClickHouse 中的 flow_tag 库使用了 MySQL 数据库表引擎远程关联 MySQL 库中相关表,以下是 flow_tag.pod_ns_map 表 SQL:
CREATE DICTIONARY flow_tag.pod_ns_map
(
`id` UInt64,
`name` String,
`icon_id` Int64
)
PRIMARY KEY id
SOURCE(MYSQL(PORT 30130 USER 'root' PASSWORD 'deepflow' REPLICA (HOST 'deepflow-mysql' PRIORITY 1) DB DeepFlow TABLE ch_pod_ns INVALIDATE_QUERY 'select(select updated_at from ch_pod_ns order by updated_at desc limit 1) as updated_at'))
LIFETIME(MIN 0 MAX 60)
LAYOUT(FLAT());
对应的 MySQL 数据库表内容中可以看到 namespace 的 id 为5的是 deepflow,和 ClickHouse 的 flow_log.l7_flow_log 表中 pod_ns_id_0 和 pod_ns_id_1 字段相呼应:
02
调试编译阶段
由于改造内容很多,本地断点调试和测试尤为重要。要想在本地调试 server 代码而且只调试数据库部分,过程简单总结如下:
-
在和外网通畅的环境先尝试编译原版代码,保证代码没有问题
#Go 版本要1.20以上 $ go version go version go1.20.7 linux/amd64 #获取稳定版工程代码,该版本带有 cpu profling 观测能力 $ git clone https://github.com/deepflowio/deepflow.git $ git checkout v6.3.9 $ git branch --show-current v6.3.9 #进入 server 端代码目录 $ cd server $ ls ./server bin cmd common controller Dockerfile go.mod go.sum ingester libs Makefile patch querier README.md server.yaml vendor $ make clean $ make vendor $ CGO_ENABLED=0 GOOS=linux GOARCH=amd64 make server -e BINARY_SUFFIX=.amd64 $ CGO_ENABLED=0 GOOS=linux GOARCH=arm64 make server -e BINARY_SUFFIX=.arm64 #编译成功,在 bin 目录下出现两个二进制包 $ cd bin $ ls deepflow-server.amd64 deepflow-server.arm64 #编译成功,在 vendor 目录下有下好的包 $ cd vendor $ ls github.com go4.org golang.org google.golang.org go.opentelemetry.io gopkg.in gorm.io go.uber.org inet.af k8s.io modules.txt sigs.k8s.io skywalking.apache.org #编译好后,打包镜像 $ docker build --build-arg TARGETARCH=amd64 -t deepflow-server:amd-20230936 . $ docker build --build-arg TARGETARCH=arm64 -t deepflow-server:arm-20231015 . $ docker save deepflow-server:amd-20230936 > deepflow-server-amd.20230936.tar $ docker save deepflow-server:arm-20231015 > deepflow-server-arm.20231015.tar镜像拿到后,替换原始镜像,和 deepflow agent 等模块调试测试下,没有问题后,进行下一步。
-
笔者用的是 GoLand 进行开发,下载上述 server 代码到本地,用 GoLand 打开,开始尝试在本地连接 MySQL 数据库,跑起来。期间对代码进行删减注释,聚焦在数据库部分。
-
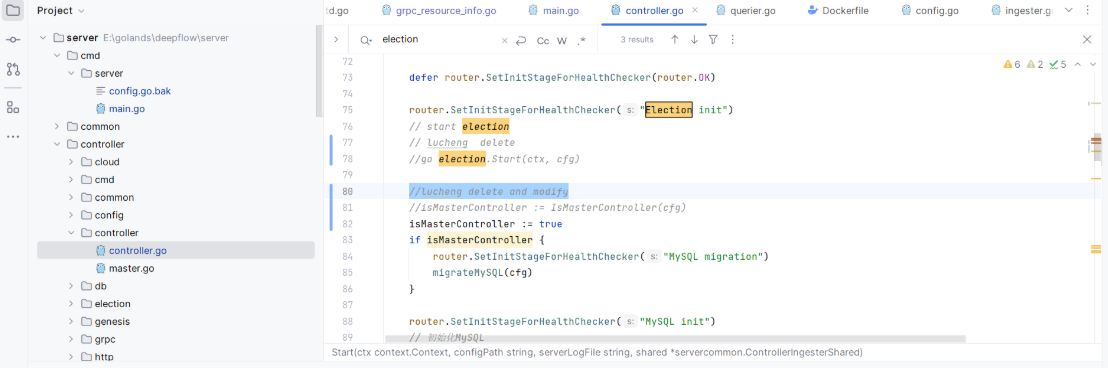
关闭 election 多 Server 主从选举逻辑
-
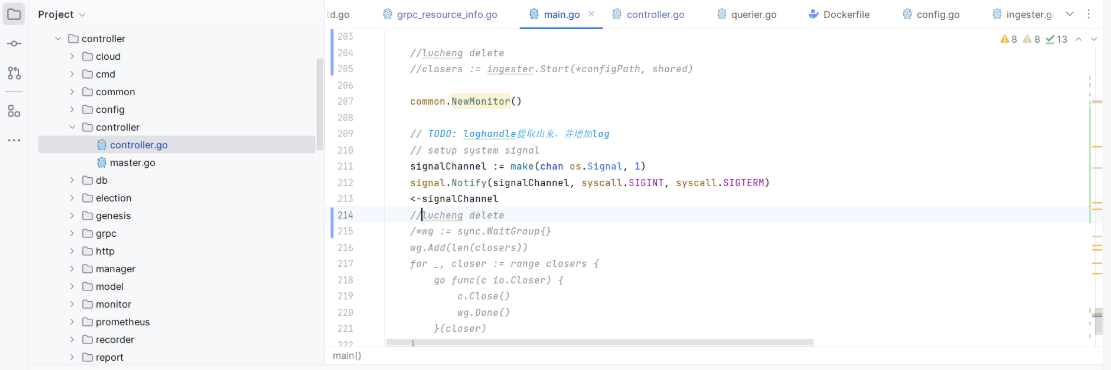
关闭 ingester 调用链关联逻辑
-
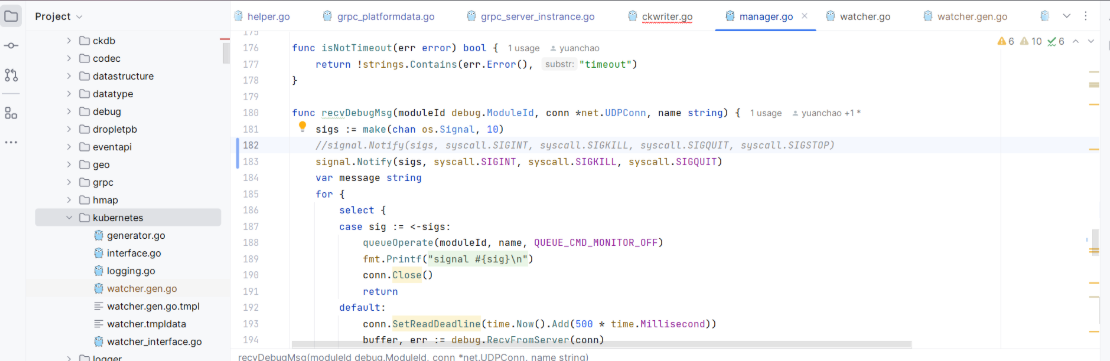
去掉不支持 windows 环境的 syscall.SIGSTOP
-
去掉不支持 windows 环境的 netlinks
- 注释掉 Lookup 函数,以下是其中一处

- 去掉 netns 依赖,其无法在 windows 环境下使用
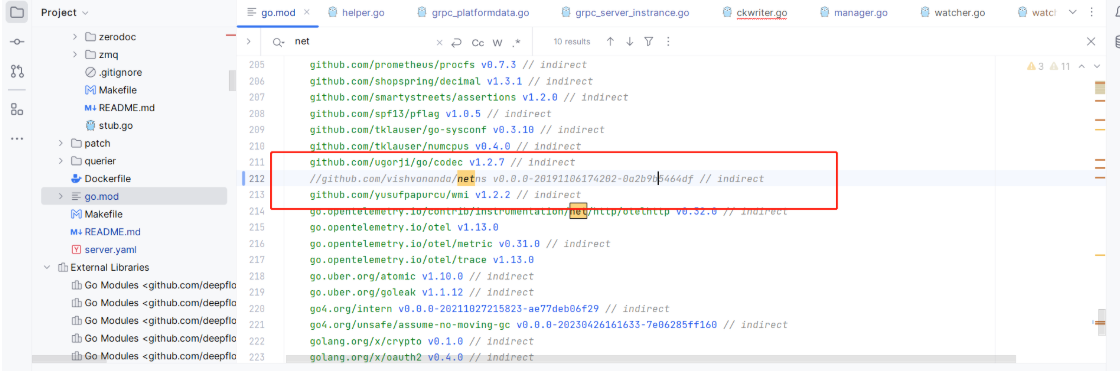
-
从前面编译好的 vendor 目录里获取后期 go generator 生成的 go 文件填充到工程中,包括:
- 补 idmap、lru 的 go 文件

- 补 kubernets 的 go 文件
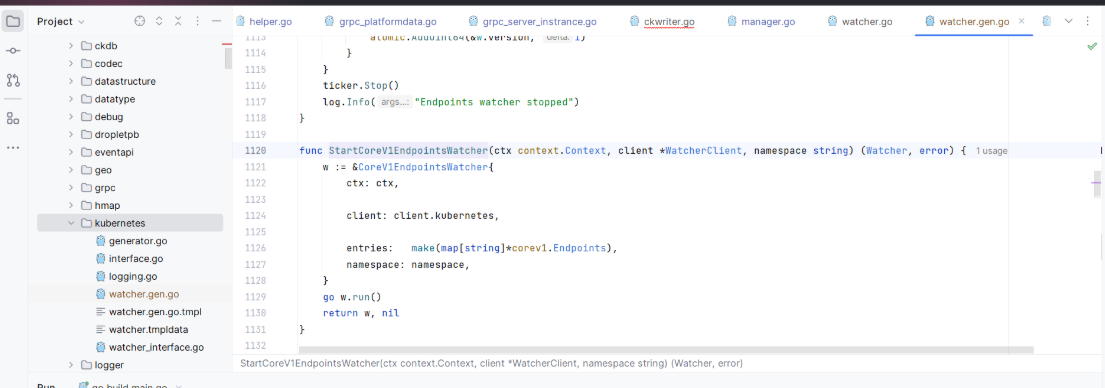
-
其他,还包括覆盖 ClickHouse 驱动,涉及 conn_batch.go 文件等等。
-
修改 server.yaml 配置,连本地数据库
# mysql 相关配置 mysql: enabled: true database: deepflow user-name: root user-password: deepflow host: localhost port: 31234 。。。
-
上述操作做完,执行 main 函数,server 成功运行,MySQL 数据库开始初始化,ClickHouse 数据库开始初始化,观察数据正常生成后,可以开始 pg 改造了。
03
代码开发阶段
前提条件
- DeepFlow Server 端源代码是 GO 工程,其数据库 ORM 组件用的是gorm。gorm 默认支持了 MySQL、PostgreSQL、SQLite 等多种数据库。在 go.mod 中添加 postgres 驱动依赖即可使用。
gorm.io/driver/mysql v1.3.4
//add
gorm.io/driver/postgres v1.3.4
gorm.io/driver/sqlite v1.3.4
gorm.io/gorm v1.23.5
- ClickHouse 除了支持 MySQL 数据库引擎,同时也支持 PostgreSQL 数据库表引擎。

开发内容
第一、 配置支持 MySQL、PostgreSQL 两种数据源
- server.yaml 中多配置 PostgreSQL 数据源,并且通过 enabled=true 和 false 来控制使用哪个数据库
# mysql 相关配置
mysql:
enabled: false
database: deepflow
user-name: root
user-password: deepflow
host: localhost
port: 31234
timeout: 30
# whether drop database when init failed
drop-database-enabled: false
auto_increment_increment: 1
# limit the total number of process queried at a time
result_set_max: 100000
# postgresql 相关配置
postgres:
enabled: true
database: postgres
user-name: postgres
user-password:
host: localhost
port: 5432
timeout: 30
# whether drop database when init failed
drop-database-enabled: false
auto_increment_increment: 1
# limit the total number of process queried at a time
result_set_max: 100000
注意:曾尝试 postgres 部分不配置 result_set_max 等,会导致程序僵死,却又无报错日志,排查了好久,最后发现下面代码处有死循环,所以建议参数都保持一致
// FindInBatchesObj gets all data that meets the query conditions in batches func FindInBatchesObj[T any](query *gorm.DB) ([]T, error) { // TODO unify return pointer or struct data := make([]T, 0) pageIndex := 0 pageCount := mysql.GetResultSetMax() pageData := make([]T, 0) for pageIndex == 0 || len(pageData) == pageCount { err := query.Find(&pageData).Limit(pageCount).Offset(pageIndex * pageCount).Error if err != nil { return []T{}, err } data = append(data, pageData...) pageIndex++ } return data, nil }
- 同时 Server 端
/controller/controller.go代码中添加数据源判断
//判断可用数据源的必要逻辑
if cfg.MySqlCfg.Enabled && cfg.PostgresCfg.Enabled {
log.Fatalf("Postgres and MySQL must have only one enabled. ")
} else if !cfg.MySqlCfg.Enabled && !cfg.PostgresCfg.Enabled {
log.Fatalf("Postgres and MySQL must have one enabled. ")
} else if cfg.MySqlCfg.Enabled {
dbName = "Mysql"
} else if cfg.PostgresCfg.Enabled {
dbName = "Postgres"
}
//数据源选择后,初始化数据源
if cfg.MySqlCfg.Enabled {
err := mysql.InitMySQL(cfg.MySqlCfg)
if err != nil {
log.Errorf("init "+dbName+" failed: %s", err.Error())
time.Sleep(time.Second)
os.Exit(0)
}
} else if cfg.PostgresCfg.Enabled {
err := mysql.InitPostgreSQL(cfg.PostgresCfg)
if err != nil {
log.Errorf("init "+dbName+" failed: %s", err.Error())
time.Sleep(time.Second)
os.Exit(0)
}
}
-
初始化数据库连接等函数放在
/controller/db/mysql/gorm.go代码中:
//初始化 MySQL
func InitMySQL(cfg MySqlConfig) error {
DbConfig = cfg
Db = Gorm(cfg)
if Db == nil {
return errors.New("connect mysql failed")
}
var version string
err := Db.Raw(fmt.Sprintf("SELECT version FROM db_version")).Scan(&version).Error
if err != nil {
return errors.New("get current db version failed")
}
if version != migration.DB_VERSION_EXPECTED {
return errors.New(fmt.Sprintf("current db version: %s != expected db version: %s", version, migration.DB_VERSION_EXPECTED))
}
return nil
}
//初始化 PostgreSQL
func InitPostgreSQL(cfg PostgreSqlConfig) error {
DbPsqlConfig = cfg
Db = PostgreSQLGorm(cfg)
if Db == nil {
return errors.New("connect postgresql failed")
}
var version string
err := Db.Raw(fmt.Sprintf("SELECT version FROM db_version")).Scan(&version).Error
if err != nil {
return errors.New("get current db version failed")
}
if version != migration.DB_VERSION_EXPECTED {
return errors.New(fmt.Sprintf("current db version: %s != expected db version: %s", version, migration.DB_VERSION_EXPECTED))
}
return nil
}
//初始化 MySQL 连接参数
func Gorm(cfg MySqlConfig) *gorm.DB {
dsn := GetDSN(cfg, cfg.Database, cfg.TimeOut, false)
return GetGormDB(dsn)
}
//初始化 PostgreSQL 连接参数
func PostgreSQLGorm(cfg PostgreSqlConfig) *gorm.DB {
dsn := GetPsqlDSN(cfg, cfg.Database, cfg.TimeOut, false)
return GetPsqlGormDB(dsn)
}
注意:上述代码中查询 db_version 的版本,这个在初始化数据库前有个判断,如果 db_version 中无数据则全量执行初始化 sql,如果表中已有版本号,则判断版本执行增量 sql。MySQL 的增量 sql 文件在 /controller/db/mysql/migration/rawsql/issu 中。而 pg 版由于是在当前版本上改造,无需维护增量 sql。
- 所有涉及数据源部分改造都在
/controller/db文件夹中,需要注意的是,之前有尝试把 db/mysql 改成db/dbsql,但是发现涉及包引用路径的改动特别多,后来放弃改动,不影响使用。

5.还有需要一个注意的点是由于 pg 数据库需要初始化 function、trigger 等需要用到管理员权限,另外考虑生产部署需要,PostgreSQL 的初始化 sql 是手动执行的,你只要在建 db_version 表是直接插入当前版本号,server 端程序就不会自动执行初始化 sql。
CREATE TABLE IF NOT EXISTS db_version (
version VARCHAR(64) PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
TRUNCATE TABLE db_version;
insert into db_version (version) VALUES('6.3.1.51');
第二、初始化 SQL 改造
注意:以下描述都是 MySQL 改造成 PostgreSQL,来减少文字描述篇幅。
-
datetime 转 timestamp
-
ENGINE=innodb DEFAULT CHARSET=utf8 表声明需去掉
-
“上引号不能用
-
PostgreSQL 数据库的 CHAR 类型填充数据会保留空格,改成 VARCHAR 则不会保留。
另外一个思路,在代码中加上 trim 函数去除空格,这次改造选择将类型改成 VARCHAR 解决,后续可以优化。
CREATE TABLE IF NOT EXISTS db_version (
version VARCHAR(64) PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
TRUNCATE TABLE db_version;
-
LONGBLOB 改成 BLOB
-
LONGTEXT 改成 TEXT
-
UNSIGNED 绝对值不支持,需替换成 CHECK 函数
INTEGER UNSIGNED -> INTEGER CHECK(netns_id>=0)
int(11) unsigned -> 删除
tinyint(1) unsigned -> CHECK(create_method>=0)
int(10) unsigned -> CHECK(policy_id>=0)
TINYINT(3) UNSIGNED -> CHECK(app_label_column_index>=0)
id int(11) unsigned NOT NULL AUTO_INCREMENT, #自增序列,建议删除
- TINYINT(1)需去掉(1),不然报 syntax error at or near “(“,
TINYINT(1) -> TINYINT
TINYINT(3) -> TINYINT
-
PRIMARY KEY (id,domain),和id INTEGER NOT NULL AUTO_INCREMENT,冲突报错如下:
ERROR: Incorrect table definition, auto_increment column must be defined as a key
解决办法:创建 SEQUENCE,id 字段添加 nextval 方法,以 vnet 表改造举例,
MySQL 表语法:
CREATE TABLE IF NOT EXISTS vnet(
id INTEGER NOT NULL AUTO_INCREMENT,
。。。
PRIMARY KEY (id,domain),
INDEX state_server_index(state, gw_launch_server)
)ENGINE=innodb DEFAULT CHARSET=utf8 AUTO_INCREMENT=256 /* reset in init_auto_increment */;
DELETE FROM vnet;
PostgreSQL 表语法:
CREATE SEQUENCE seq_vnet START 256; --创建 SEQUENCE
CREATE TABLE IF NOT EXISTS vnet(
id INTEGER NOT NULL default nextval('seq_vnet'), --id 字段添加 nextval 方法
。。。
PRIMARY KEY (id,domain)
) /* reset in init_default nextval('seq_plugin') */;
CREATE INDEX vnet_index ON vnet(state, gw_launch_server);
DELETE FROM vnet;
COMMENT ON COLUMN vnet.state IS '0.Temp 1.Creating 2.Created 3.Exception 4.Modifing 5.Destroying 6.To run 7.Running 8.To stop 9.Stopped';
- 双引号””不能用,要用单引号”
"1m" -> '1m'
epc " 1:route, 2:transparent" -> ' 1:route, 2:transparent'
- int 需改成 INTEGER
int(10) -> INTEGER
int(11) -> INTEGER
int -> INTEGER
-
double 要改成 number
-
float 要改成 number
-
enum 不支持,修改字段类型为 Varchar,同时引入 check 方法
alarm_policy 表
--data_level enum('1s','1m')
data_level VARCHAR(4) check (data_level in ('1s','1m'))
report_policy 表
--`interval` enum('1d','1h') NOT NULL DEFAULT '1h',
interval VARCHAR(4) check (interval in ('1d','1h')) NOT NULL DEFAULT '1h',
-
MEDIUMBLOB 转 BLOB
-
mail_server.user 和 go_genesis_process.user 是 pg 关键字 改成 user_name, go 代码的 model 也需要修改,同时 MySQL 的 init sql 也需要修改
MySQL 和 PostgreSQL 同时修改字段名:
--user VARCHAR(256) DEFAULT '',
user_name VARCHAR(256) DEFAULT '',
go 代码改造
type GenesisProcess struct {
ID int `gorm:"primaryKey;column:id;type:int;not null" json:"ID"`
。。。
//user -> user_name
//update
User string `gorm:"column:user_name;type:varchar(256);default:null" json:"USER_NAME"`
。。。
}
func (GenesisProcess) TableName() string {
return "go_genesis_process"
}
- data_source.interval 也是 pg 关键字,需改成 data_source.interval_time,go 代码的 model.go 也需要修改,同时 MySQL 的 init sql 也需要修改
MySQL 和 PostgreSQL 同时修改字段名:
--interval INTEGER NOT NULL,
interval_time INTEGER NOT NULL,
.controllerdbmysqlmodel.go 代码改造
//Interval int `gorm:"column:interval;type:int" json:"INTERVAL"`
//update
Interval int `gorm:"column:interval_time;type:int" json:"INTERVAL_TIME"`
.controllerhttpservicedata_source.go 代码改造
if name, ok := filter["name"]; ok {
interval := convertNameToInterval(name.(string))
if interval != 0 {
//Db = Db.Where("`interval` = ?", interval)
//lucheng update
Db = Db.Where("interval_time = ?", interval)
}
}
-
on update current_timestamp不支持,需在建表前添加 FUNCTION 和 trigger。
CREATE OR REPLACE FUNCTION "public"."cs_timestamp"()
RETURNS "pg_catalog"."trigger" AS $BODY$
begin
new.updated_at= current_timestamp;
return new;
end
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100
create trigger db_version_updated_at before update on db_version for each row execute procedure cs_timestamp();
create trigger plugin_updated_at before update on plugin for each row execute procedure cs_timestamp();
create trigger vtap_repo_updated_at before update on vtap_repo for each row execute pr服务器托管网ocedure cs_timestamp();
。。。
- index 和 references 外键有冲突
如果 index 是复合索引,那么 references 外联了复合索引的一个字段,会报错:
PRIMARY KEY (id,domain)
REFERENCES vl2(id),
将主键索引改成唯一索引
PRIMARY KEY (id,domain), -> CREATE UNIQUE INDEX vinterface_unique_index ON vinterface(id,domain);
- uuid 语法不支持
解决方案,默认插入语句直接写死 UUID,如下所示
INSERT INTO sys_configuration (param_name, value, comments, lcuuid) VALUES ('cloud_sync_timer', '60', 'unit: s', 'ffffffff-ffff-ffff-ffff-fffffffffff1');
INSERT INTO sys_configuration (param_name, value, comments, lcuuid) VALUES ('pcap_data_retention', '3', 'unit: day', 'ffffffff-ffff-ffff-ffff-fffffffffff2');
INSERT INTO sys_configuration (param_name, value, comments, lcuuid) VALUES ('system_data_retention', '7', 'unit: day', 'ffffffff-ffff-ffff-ffff-fffffffffff3');
INSERT INTO sys_configuration (param_name, value, comments, lcuuid) VALUES ('ntp_servers', '0.cn.pool.ntp.org', '', 'ffffffff-ffff-ffff-ffff-fffffffffff4');
go 代码插入的由 uuid 函数填充。
- 字段里声明 utf8不支持
name varchar(256) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '',
报错:
type "pg_catalog.varchar_utf8" does not exist
删除即可
第三、数据库方言改造
- server 端代码用到 MySQL 的 insert ignore 语法,意思是,当执行 INSERT 操作时,如果数据表中不存在对应的记录,执行插入操作;如果数据表中存在对应的记录,则执行更新操作。这个语法在 pg 里不存在,但是 pg 使用的是 onconfict 语法。
举例:.controllerhttpserviceresourcedomain.go 改造点:
//lucheng update
//err := mysql.Db.Clauses(clause.Insert{Modifier: "IGNORE"}).Create(&domain).Error
if strings.Compare(mysql.Db.Name(), "postgres") == 0 {
err := mysql.Db.Debug().Clauses(clause.OnConflict{DoNothing: true}).Create(&domain).Error
if err != nil {
log.Warningf("create domain failed: %s", err)
}
} else {
err := mysql.Db.Clauses(clause.Insert{Modifier: "IGNORE"}).Create(&domain).Error
if err != nil {
log.Warningf("create domain failed: %s", err)
}
}
- server 端代码中有拼接 sql 的使用,其中用到了““,该语法在 pg 中不支持,需去掉
举例:.controllertrisolarisdbmgrdbmgr.go 改造点:

- 还发现 pg 语法更为严格,拼接 sql 语法中少个空格也会报错,MySQL 不会,补上也不影响 MySQL
举例:.controllertrisolarisvtapvtap_discovery.go 改造点:

第四、ClickHouse 对接部分添加 PostgreSQL 表引擎逻辑
- 改造体现在创建连接,连接后的 ClickHouse 建表,检查并更新已存在表三块地方:
举例:.controllertagrecorderdictionary.go 改造点:
// 在本区域所有数据节点更新字典
// Update the dictionary at all data nodes in the region
host := ""
if c.cfg.MySqlCfg.Enabled {
host = c.cfg.MySqlCfg.Host
} else if c.cfg.PostgresCfg.Enabled {
host = c.cfg.PostgresCfg.Host
}
replicaSQL := fmt.Sprintf("REPLICA (HOST '%s' PRIORITY %s)", host, "1")
connect, err := clickhouse.Connect(clickHouseCfg)
if err != nil {
continue
}
log.Infof("refresh clickhouse dictionary in (%s: %d)", address.IP, clickHouseCfg.Port)
- 建表语句的改造,主要体现需新增 pg 相服务器托管网关建表 sql
举例:.controllertagrecorderconst.go 改造点,创建K8S_ENVS等 DICTIONARY 字典表:
CREATE_K8S_ENVS_DICTIONARY_PGSQL = "CREATE DICTIONARY %s.%sn" +
"(n" +
" `id` UInt64,n" +
" `envs` String,n" +
" `l3_epc_id` UInt64,n" +
" `pod_ns_id` UInt64n" +
")n" +
"PRIMARY KEY idn" +
"SOURCE(PostgreSQL(PORT %s USER '%s' PASSWORD '%s' %s DB %s TABLE %s INVALIDATE_QUERY 'select(select updated_at from %s order by updated_at desc limit 1) as updated_at'))n" +
"LIFETIME(MIN 0 MAX %d)n" +
"LAYOUT(FLAT())"
第五、优化日志输出
- 为了快速定位问题,要开启 sql 的 debug 模式,需要去
.controllerdbmysqlcommonutils.go中配置日志输出级别为 Debug:
func GetPsqlGormDB(dsn string) *gorm.DB {
Db, err := gorm.Open(postgres.New(postgres.Config{
//DSN: "host=192.168.10.10 user=deepflow dbname=db_deepflow password=Gauss123 port=5432 sslmode=disable",
DSN: dsn,
PreferSimpleProtocol: true,
}), &gorm.Config{
NamingStrategy: schema.NamingStrategy{SingularTable: true}, // 设置全局表名禁用复数
Logger: logger.New(
l.New(os.Stdout, "rn", l.LstdFlags), // io writer
logger.Config{
SlowThreshold: 0, // 慢 SQL 阈值,为0时不打印
//调试的时候改成 Debug
LogLevel: logger.Error, // Log level
IgnoreRecordNotFoundError: false, // 忽略 ErrRecordNotFound(记录未找到)错误
Colorful: true, // 是否彩色打印
}), // 配置 log
})
if err != nil {
log.Errorf("PostgreSql Connection failed with error: %v", err.Error())
return nil
}
sqlDB, _ := Db.DB()
// 限制最大空闲连接数、最大连接数和连接的生命周期
sqlDB.SetMaxIdleConns(50)
sqlDB.SetMaxOpenConns(100)
sqlDB.SetConnMaxLifetime(time.Hour)
return Db
}
- 如果想指定某个 sql 打印日志,可以修改全局 log-level 为 debug,并修改代码加上 debug 方法:
server.yaml 中配置修改 error->debug:
# logfile path
log-file: /var/log/deepflow/server.log
# loglevel: "debug/info/warn/error"
log-level: debug
举例:

- 为了快速准确定位方法位置改了 debug 日志输出内容。
举例:.controllerrecorderrecorder.go 改造点:
func (r *Recorder) updateStateInfo(cloudData cloudmodel.Resource) {
...
//log.Debugf("update domain (%+v)", domain)
log.Debugf("updateStateInfo domain (%+v)", domain)
...
- 在改造期间,也发现 Server 端代码有些数据库更新入库操作缺少一些错误日志的地方,为减少调试过程遇到无报错日志的情况还是都加上。
举例:.controllermonitoranalyzer.go 改造点:
// 获取可用区中的数据节点 IP
err := mysql.Db.Where("region IN (?)", regionLcuuids.ToSlice()).Find(&azAnalyzerConns).Error
//lucheng add
if err != nil {
log.Error(err)
}
04
测试上线阶段
应公司要求需要将镜像底包替换成国产化操作系统,基于 pg 代码进行编译打包镜像 Dockerfile 需要修改:
FROM euler:22.03 as deepflow-server #openeuler 镜像底包
MAINTAINER lucheng
#RUN apk add tzdata
COPY ./server.yaml /etc/
RUN mkdir /etc/mysql
COPY ./controller/db/mysql/migration/rawsql /etc/mysql
RUN mkdir /etc/pgsql #虽然新增 pgsql 文件夹,但这里并没用到自动初始化 sql,后续还需要适配调试下。原因是有些 pg 数据库的操作需要用到管理员账户,比如创建用户、赋权、function 等,后续可以考虑在发布 pg 镜像时直接加上这部分。
COPY ./controller/db/mysql/migration/pgsql /etc/pgsql
COPY ./controller/cloud/filereader/manual_data_samples.yaml /etc/
COPY ./querier/db_descriptions /etc/db_descriptions/
ARG TARGETARCH
COPY ./bin/deepflow-server.${TARGETARCH}.pg /bin/deepflow-server
CMD /bin/deepflow-server
#编译好后,打包镜像
$ docker build --build-arg TARGETARCH=amd64.pg -t deepflow-server-pg:amd-20230936 .
$ docker build --build-arg TARGETARCH=arm64.pg -t deepflow-server-pg:arm-20231015 .
$ docker save deepflow-server-pg:amd-20230936 > deepflow-server-pg-amd.20230936.tar
$ docker save deepflow-server-pg:arm-20231015 > deepflow-server-pg-arm.20231015.tar
上传到测试环境和 DeepFlow 的 Grafana、deepflow-app、deepflow-agent 联调测试,经过多轮测试验证证明此次改造成功!目前内部已发版上线。
05
改造实践总结
DeepFlow Server 使用 Go 代码编写,用到 grpc、protobuf、协程等提高性能手段,整体性能表现非常优秀。
同时开发改造体验也很好,使用的是 gin、gorm 等都是主流开发框架上手容易文档丰富,而且 go 代码编译 x86 和 arm 两种环境的包只要在 x86 环境一次性编译好,不需要再去 arm 环境再折腾一次。
通过让DeepFlow Server 支持 PostgreSQL 数据源能让用户拥有更多选择,好处显而易见。
06
什么是 DeepFlow
DeepFlow 是云杉网络开发的一款可观测性产品,旨在为复杂的云基础设施及云原生应用提供深度可观测性。DeepFlow 基于 eBPF 实现了应用性能指标、分布式追踪、持续性能剖析等观测信号的零侵扰(Zero Code)采集,并结合智能标签(SmartEncoding)技术实现了所有观测信号的全栈(Full Stack)关联和高效存取。使用 DeepFlow,可以让云原生应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 DevOps/SRE 团队提供从代码到基础设施的监控及诊断能力。
GitHub 地址:https://github.com/deepflowio/deepflow
访问 DeepFlow Demo,体验零插桩、全覆盖、全关联的可观测性。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
