
这篇论文:
- 提出了prob-and-allocate训练策略,在prob阶段获得样本损失,在allocate阶段分配样本权重。
- 以[2]的meta-weight-net为Baseline,取名为CurveNet,进行部分改动。
另外,这篇论文提供的源码结构混乱,复现难度较大。主要的工作也是基于meta-weight-net,创新的内容有限。但是,这篇文章在Introduction对long-tailed data + noisy labels问题的描述非常清晰。
Introduction
Backg服务器托管round
分别单独处理long-tailed data和noisy labels的数据偏置时,re-weighting策略是常见且有效的办法:通过loss值分配相应的权重。但如果两类偏置同时出现,re-weighting效果就不佳了。
具体来说,对于包含noisy labels的训练数据,noisy labels的样本往往具有较大的训练损失,因此加权函数应该将大损失映射到小样本权重,以减轻标签噪声的影响。
对于类别不平衡的训练数据,尾类样本通常会因训练不足而遭受较大损失,因此加权函数应该为这些硬正样本分配较大的权重,使网络更加强调尾类以提高整体性能表现。
tailed类loss大,但从noisy labels角度看是噪声标签,需要小权重;从imbalance角度看,需要大权重。
处理两类偏置的关键问题:区分尾部类别的干净样本和标签损坏的样本。
Motivation
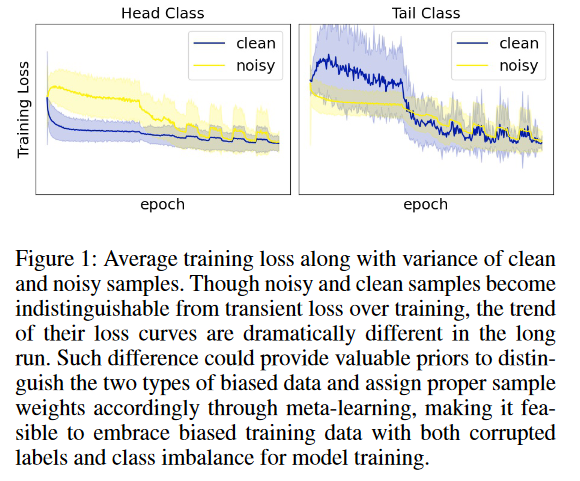
观察Figure 1右图。噪声样本的损失在训练开始时保持稳定,而干净样本的损失在开始时急剧上升,然后迅速下降。因此,训练损失曲线实际上包括了有价值的信息,并且可以提供有用的先验来区分尾类的干净样本和噪声样本。
虽然文中提出的CurveNet与meta-weight-net参数更新方法几乎一致,但meta-weight-net论文中,meta-weight-net的输入(也就是loss)随着训练而变化,无法代表样本的整体训练状态。
此外,meta-weight-net只能处理单一的数据偏置,两类偏置一起的情况原文中并未对其测试。而改进的CurveNet可以同时处理两类偏置。
Method
Meta-weight-net部分
在Method一节中,meta-weight-net的部分内容占了几乎半页。。。称之为“Revisiting Meta-Weight-Net”。
- meta-weight-net基于MLP提出了分类网络(mathcal{F}),其中参数记为(omega)。
- 带偏置的training-data: (mathcal{D}服务器托管^{tra}={x_{i}^{tra},y_{i}^{tra}}_{i=1}^{N}),无偏置的meta-data: (mathcal{D}^{meta}={x_{i}^{meta},y_{i}^{methat{a}}}_{i=1}^{M}),N,M表示样本数,(Ngg M), (X, Y)分别表示数据和标签。
meta-data作为无偏置数据来自验证集,有点像Zero-shot的Transductive设置。这种设置我到现在还是觉得莫名其妙。
对于传统的训练,分类器的参数训练通过最小化损失:
]
(mathcal{F})一般是卷积神经网络。接下来为了简化,我们令(mathcal{L}_{tra}=mathcal{L}(Y^{tra},mathcal{F}(X^{tra}|omega)))。然而,数据存在偏置时,公式1可能不能很好地优化参数。这时需要采用re-weighting策略,对损失施加权重(mathcal{G}(mathcal{L}_{tra}|Theta)),(mathcal{G})是输出权重的网络,(Theta)为该网络参数。此时,公式1变为:
]
具体来说(mathcal{G})为一个仅含1个隐藏层的MLP,含100个神经元节点,以Sigmoid为激活函数,输出区间为[0,1]。通过元学习进行参数优化:
]
总觉得这里和元学习没啥关系。
式3的损失函数用(mathcal{L}_{meta})表示。由于两种参数(omega, Theta)都需要更新,所以需要分开更新,更新一种参数时令另一种参数为已知量。
- 先更新(omega),这里的(omega)作为临时更新参数,t为当前epoch:
]
- 临时更新的(omega)用来更新(Theta),更新完就可以丢弃:
]
- 再用更新后的(Theta)更新真正的(omega):
]
以上都是作者照搬了meta-weight-net的内容,作者总结了meta-weight-net的缺陷:
- meta-weight-net采用当前损失值作为输入,该损失值在整个训练过程中发生巨大变化,并且无法代表样本的状态。
- 损失值在每个epoch都不同,并且在训练过程中变得越来越小,这不利于(用于分类的)网络收敛。
- 当噪声和tail class 样本呢同时存在时,权重可能很大也可能很小,导致分类器的性能不理想。
作者以此为motivation,提出了prob-and-allocate训练策略,不再随着权重赋值,而是先统一收集损失,在分配权重。
CurNet
把第i个样本,T个epoch内的损失收集起来:(L_i=[l_{i,0},l_{i,1},cdots,l_{i,T}]),由于初始参数随机产生,可以移除前S个损失,结果变为:(L_i=[l_{i,S},l_{i,S+1},cdots,l_{i,T}])。
对于同一类,计算loss的均值:
]
接下来,对每个类的样本,减去类内的均值:
]
这里(k(1le kle K))表示class,(mathbb{1})表示Dirac delta函数,输入的两个变量相等时输出1,否则输出0。
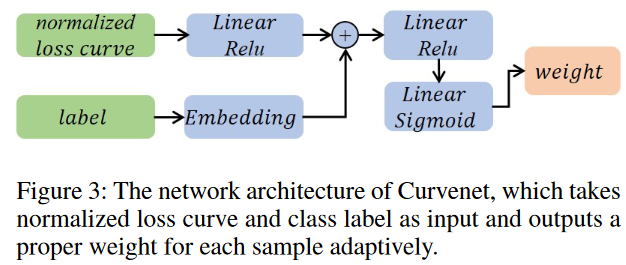
归一化损失向量可以表示为 I,然后依次馈送到全连接层,每个层都耦合到 ReLU 激活层。 P为最后一个全连接层的输出神经元数量,这里通过实验设置为64。
作为进一步促进噪声识别的一种方法,我们采用类标签嵌入方法将类信息丰富到损失曲线特征中。这种嵌入方法在自然语言处理领域常用(Cao et al. 2021),这里的嵌入矩阵可以表示为:(Y^{Ktimes P}=[Y_{1},cdots,Y_{K}].)。再把I 和 Y连接并输入到MLP中。
优化的时候忽略几层
为了加速(Theta)优化,根据FaMUS (Xu et al. 2021)(triangledown_Thetamathcal{L}_{meta}^t|_{Theta^t})重写为:
proptosum_i^Zfrac{partialmathcal{L}_{meta}^t}{partialhat{omega}_i^t}bulletfrac{partialhat{omega}_i^t}{partialmathcal{G}(Theta^t)}bulletfrac{partialmathcal{G}(Theta^t)}{partialTheta^t},
tag{9}]
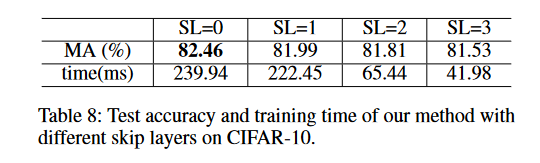
Z表示分类器的层数。然后冻结前SL层,再更新(Theta),此时式9变为:
]
这种做法感觉没什么用,作者的消融实验也证实了这一点,此外,作者的没有比较整体的训练时间,因此这个消融实验的结果说服力欠佳。
改变了输入的式4和式6
]
]
整体的训练框架如下:
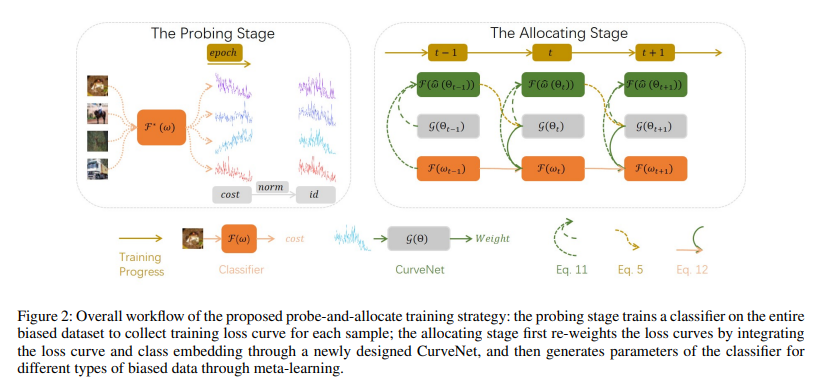
当学习率改变时,不同类别样本的损失值曲线存在显着差异。因此,在探测阶段采用循环学习率(Smith 2017)来训练分类器(mathcal{F}(omega)),O2U-Net 也采用了这种方法(Huang et al. 2019)。此外,当分类器的学习率降低时,认为CurveNet已经优化得很好,不再更新CurveNet的参数以加快训练速度。
Experiments
实验部分没有什么亮点,作者主要与Baseline meta-weight-net进行对比。作者放了一张不同类的参数权重与epoch的关系:
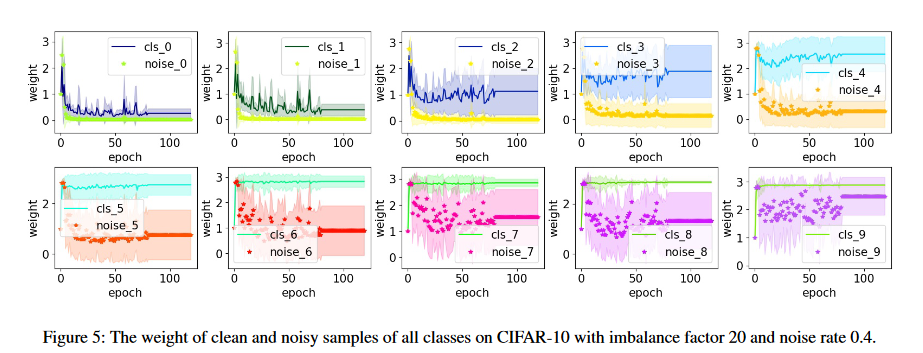
可观察到:
- clear样本权重大于noisy样本;
- 尾部类的权重显著大于头部类
这种结果确实是理想的情况,证明了损失曲线有着有效信息。但观察尾部类的3张图,它们的权重还是靠的有点近,不确定作者的方法在尾部类的精度上如何。
参考文献
- Jiang, Shenwang, et al. “Delving into sample loss curve to embrace noisy and imbalanced data.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 36. No. 6. 2022.
- Shu, Jun, et al. “Meta-weight-net: Learning an explicit mapping for sample weighting.” Advances in neural information processing systems 32 (2019).
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
