
本文来自博客园,作者:T-BARBARIANS,博文严禁转载,转载必究!
一、前言
DPDK技术原理相关的文章不胜枚举,但从实战出发,针对DPDK丢包这一类问题进行系统分析的文章还是凤毛麟角。
刚好最近几个月一直在做DPDK的相关性能优化,x86和arm平台都在做。在完整经历了发现问题、分析问题、解决问题的所有阶段后,回顾过去这段时间的来龙去脉,觉得可以将其将形成一篇技术文章,并予以分享。
优化目的只有一个:DPDK零丢包!
零丢包,谈何容易!在整个性能优化期间,查阅过大量资料;调整过大量参数;尝试过多种优化手段。相关的不相关的招都使过,很多时候都是无功而返,优化过程简直就是一个每天都想放弃的过程。
但是俗话说得好:只要功夫深,铁棒磨成针。对任何事物的认知必然是一个由浅入深的过程,DPDK也不例外。通过持续的尝试和总结,x86和国产化平台最后都收到了很好的效果。
接下来就吐血奉献过去一段时间的经历和思考,希望可以为大家提供一些参考和相关问题的解决思路。
篇幅较长,而且信息量有些大,完整阅读加理解大概需要30分钟。
二、背景与问题
与使用DPDK的大多数同行一样,我们也是通过DPDK获取数据面的大规模网络流量,在用户态将流量直接传递给某个应用,最终体现业务价值。
愿景很美好,现实很残酷,DPDK丢包了。
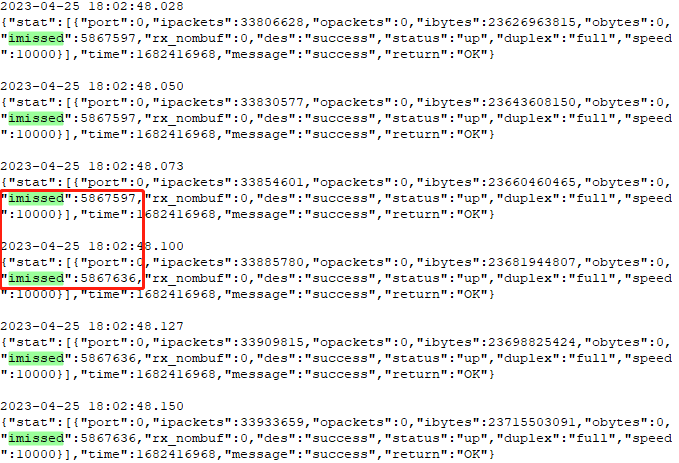
图1
在时间点 [18:02:48.073,18:02:48.100] 之间发生了丢包,丢包个数为:5867636 -5867597 = 39。这是在很短时间内的丢包数,情况严重时每秒成千上万个包被丢弃,应用层收到的报文残缺不全,这就没法玩了。
上 篇
一、x86平台优化经历
10Gbps线速网卡,流量也才在2Gbps—3Gbps之间,这也能丢包?
(1)ring环长度尽可能大
各大平台搜索一通,公开的秘籍就是:给我把ring环加大!
ring环就是大家耳熟能详的DPDK无锁队列,收包ring环是DPDK收包流程里最底层的一个队列,直接与DMA打交道,用于存储DMA从网卡搬运至此的网络报文。
在我看来,加大ring环有两个作用,一是增加储存网络报文的容量;二是抗流量突发。
我们把ring环长度由1024干到了16384,同时增加了DPDK队列统计函数:rte_eth_rx_queue_count(uint16_t port_id, uint16_t queue_id),用于实时统计当前环形队列已使用的描述符个数,即ring环里当前驻留了有多少个未消费的数据包。
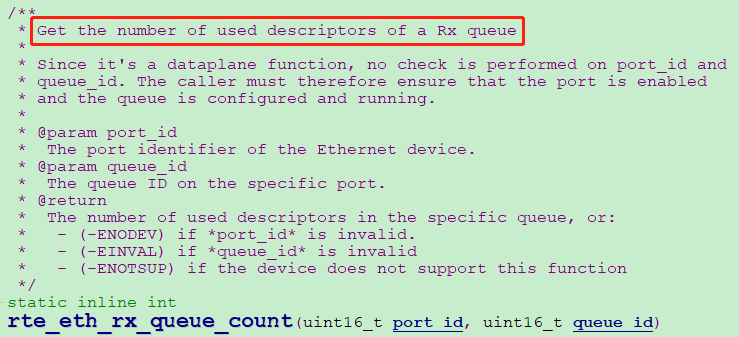
图2
加大ring环就不丢包了吗?把队列统计信息通过日志实时打印,继续观察。

图3
很明显,DPDK继续丢包。还丢包那我就继续加,但是DPDK收包ring环的设置是有上限的,uint16_t nb_rx_desc(The number of receive descriptors to allocate for the receive ring),表明DPDK最大可以将收包ring环设置为65535。

图4
还真设置过最大值,但是无济于事,继续丢包。说明在我们环境上增大ring环容量并不能解决全部问题。这时候陷入了僵局,是什么问题导致了丢包呢?
从图3我们可以看到一个现象,当ring环被打满时,才出现了imissed统计值增长。DMA往ring环里放数据,收包线程从ring环里取数据,现在ring环保持高水位,这充分说明了是上层收包线程未及时的将ring环里的数据包取走呀!根据这个重要线索,我们重新审视了与收包相关的应用层代码。
(2)线程任务尽可能轻量
业务流程逻辑可简化如下图所示。
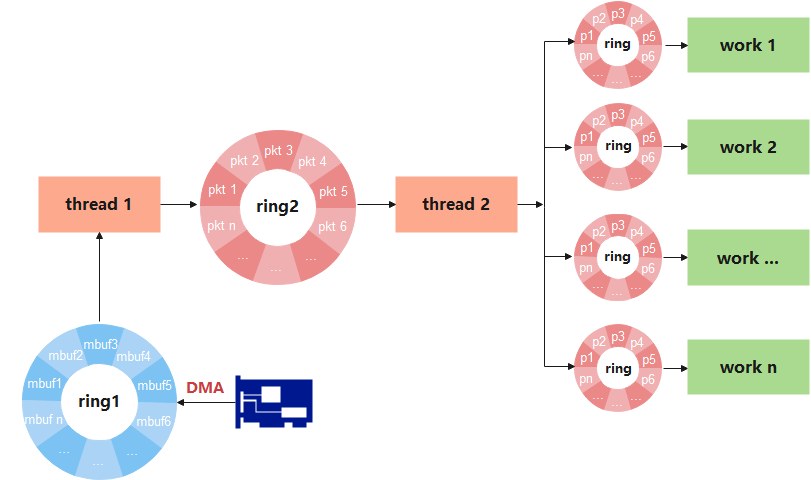
图5
1、网络数据包通过DMA拷贝到ring1;
2、thread1负责从ring1里接收数据包,同时还要做一些其它任务,例如限速、过滤、数据包初始化等工作,最后将初始化后的描述符传递至ring2;
3、thread2从ring2里获取描述符,进行数据预取,协议解析(eth、ip、tcp、udp等等)等相关工作,最后通过hash算法将描述符散列到对应work线程的接收队列;
4、各work线程从对应的ring环里获取描述符,进行业务处理。
流程结构很清晰,各个线程被安排得明明白白。但是问题恰恰出现在看似没有问题的地方。
回到上一个问题,ring1被打满,只能是thread1未及时消费掉ring1的数据,造成ring1可用buf越来越少,DMA无法将网卡收到的所有网络报文拷贝至ring1里,最终导致了DPDK丢包。
如何证明?屏蔽大法呀!
当我屏蔽掉thread1里的限速和过滤,丢包现象明显减少;当我屏蔽掉数据包初始化流程,再也没有出现过丢包。很明显,问题就出在初始化流程里,它的负荷相对于限速和过滤来说,对thread1造成了更大的影响。后来通过uftrace(有关uftrace的用法可以参考我的另一篇文章,链接:https://www.cnblogs.com/t-bar/p/16898892.html)也发现了“初始化流程”函数的消耗时间比“限速”和“流量过滤”要长,占比更高,也提供了充分的理论支撑,且发现了相对更耗时的罪魁祸首clock_gettime()。
比较了3个时间函数,time(),clock_gettime(),rdtsc()。time和clock_gettime都可以直接获取时间,且time性能更好,但是精度是秒级别,不适用于高精度时间计时;clock_gettime可获取纳秒级精度时间,且性能还不错(相对gettimeofday()而言);rdtsc其实性能最好,但是获取的是系统启动以来的CPU时钟周期数,还需要一定的转换方法才能转换为时间,对于更高的流量场景,例如20+Gbps,30+Gbps,建议使用rdtsc()。
之所以之前选择clock_gettime一是精度高,二是性能相对较好。但是这里的问题就在于:流量规模上来后,当“收包”,“限速”,”过滤”,“初始化”四个流程组合在一起时,任务过重,clock_gettime又是最耗时的任务,形成了木桶的最短板。
明确了问题所在,如何优化呢?
那就是任务拆分!thread1显然无法在完成限速、过滤、初始化任务的同时,又把ring1消费在低水位。因此有必要把thread1的当前任务进行拆分,即再加一个搬砖线程。
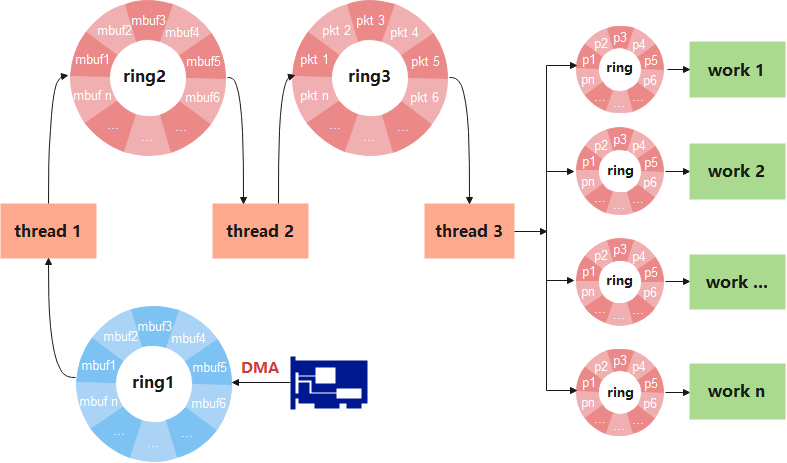
图6
3个线程的分工分别为:
1、thread1只负责从ring1收包,并将数据包传递至ring2;
2、thread2从ring2获取数据包,完成限速、过滤、初始化工作,并将报文传递至ring3;
3、thread3从ring3获取数据报文,完成协议解析(eth、ip、tcp、udp等等)等相关工作,最后通过hash算法将各个Pacekt散列至对应ring队列。
完成上述改造后,ring1再也未出现过因为thread1的不及时消费导致队列被打满的情况。也印证了标题,各线程任务尽量轻量,各司其职。
(3)mbuf的释放有讲究
摸着石头过河往往都会遇到你永远想不到的困难,克服这些困难需要寻找问题线索、解决问题的方法和耐力。
上面程序优化后,兴奋感并没有持续太久,DPDK居然又丢包了,这次直接懵逼了。。。
当我在图6的thread3直接释放packet,即切断各work的输入,屏蔽业务流程后,不再发生丢包,证明之前的优化至少解决了thead1来不及及时消费ring1数据包的问题。
新问题又出在哪里呢?感觉毫无头绪,当前唯一的线索就是打开业务后丢包,屏蔽业务后又不丢包,那大概率问题出在work上,还是看日志吧!
新丢包现象有如下图所示信息:

图7
这次的丢包和前面的丢包有些不一样:imissed发生增长的同时,伴随着rx_nombuf的增长!
rx_nombuf是什么指标?看看DPDK的定义:用于接收报文的mbuf分配失败。

图8
此时脑海里产生了两个想法:一是内存池设置过小,导致thread1收取报文时mbuf不够;二是work线程数较少,业务来不及处理,mbuf产生堆积,最终导致mbuf没有及时归还到内存池。
后来的验证真的很失望,内存池从100万扩大至200万,甚至扩大至600万,还是丢包;work线程数从8个扩大至16个,还是丢包;双管齐下,两个参数都加大,还是丢包!新问题总是接踵而至,感觉好艰难。

运行一段时间后,mbuf不够是事实,可为什么加大了资源还是丢包呢?毫无头绪的时候,又只有把代码重新搬出来再看看。
各个work线程,以及mbuf的释放有如下逻辑图所示:
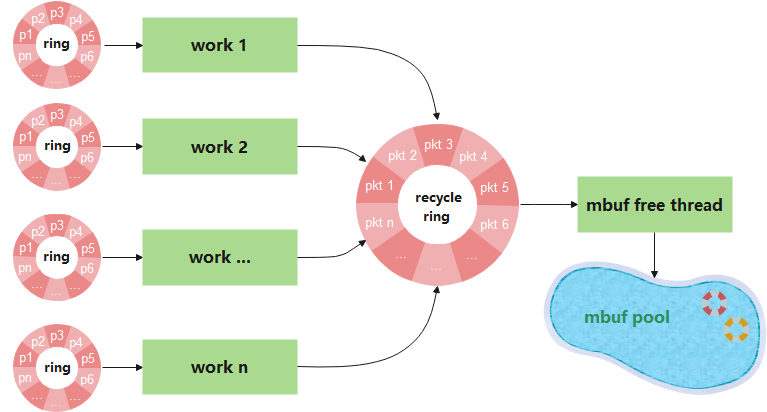
图9
1、每一个work从对应的ring环消费packet;
2、每一个work thread处理完业务后,作为生产者将packet生产至recycle ring;
3、mbuf free thread作为消费者,从recycle ring消费元素,通过调用rte_pktmbuf_free实现mbuf的释放。
从哪可以获取一些帮助定位丢包问题的信息呢?还是只有通过日志,我们增加了各work线程对应ring环中待处理packet个数,以及mbuf回收线程待处理packet个数的实时统计日志。
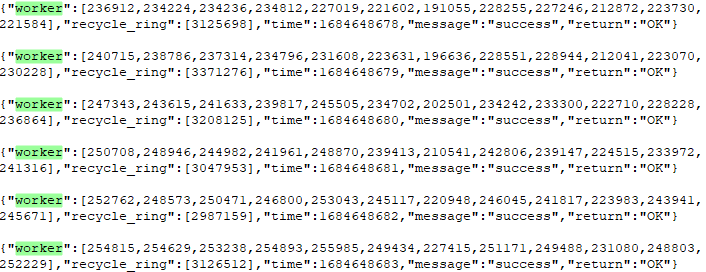
图10
从日志可以得到两个信息:
1、一共12个work线程,每一个work线程的ring环中都出线了元素堆积;
2、recycle ring出现了元素堆积,且接近recycle ring的长度极限;
真实原因开始逐渐显现,是因为mbuf free thread来不及消费导致recycle ring堆积,各work也无法及时向recycle ring生产,也导致了work各个ring环堆积!就像高速路上的汽车一样,前方不远处堵车,最终你也得堵车。。。
那为什么recycle ring会堆积呢?那就是mbuf释放太慢了,内存池的mbuf基本所剩无几,最终出现了图7描述的问题 “imissed发生增长的同时,伴随着rx_nombuf的增长!”
问题找到了,如何优化呢?想到了两种方案:
1、再增加一对recycle ring、mbuf释放线程,使一部分work向新的recycle ring生产;
2、取消recycle ring和mbuf释放线程,由各work线程直接调用rte_pktmbuf_free进行mbuf释放。
第一种方案稍微复杂一些,并且会增加资源开销。同时存在一个潜在的问题:多个work作为生产者,同时向同一个ring环生产数据,是会产生竞争的。虽说是所谓的无锁队列,但是DPDK底层还是通过CMPSET原子操作实现的,只能说是将同步带来的开销降到了最低。因此,如果work越多,越有可能触碰ring环的生服务器托管网产极限。
第二种方案更加简单,且减小了资源开销。由之前的mbuf free thread统一释放,还不如各work独自调用rte_pktmbuf_free释放,因为独乐乐不如众乐乐啊。
不服就干!于是乎mbuf的释放方案就再次演进为如下图所示逻辑。
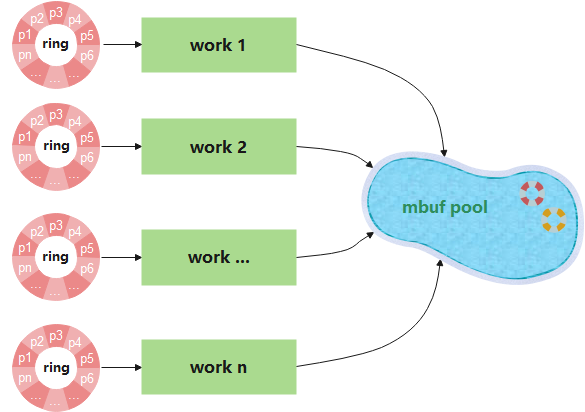
图11
完成对应改造后继续测试,但是还是发现work队列有大量堆积,偶尔还是会出现丢包,并伴随着rx_nombuf的增长。
再次陷入了僵局,感到有些心灰意冷,下班路上的淅沥小雨迎面打在脸上,令我沮丧到了极点。回到家躺在床上也是迟迟不能入睡,思考着每一个细节和下一步的调查手段。第二天清晨醒来,自己又像被打了鸡血一样,发誓要死磕到底!这种心理状态确实是我这段是时间的真实写照:雄心壮志上班,垂头丧气下班,周而复始。
再回头看看业务逻辑:work线程从对应ring环取出mbuf,最后直接调用rte_pktmbuf_free释放mbuf,中间只有业务处理。怀疑业务过慢?好,屏蔽掉业务流程,且work取出packet后立即释放packet。结果居然与业务屏蔽前一致,即还是偶发丢包!好,那就说明这里的瓶颈不在业务流程上,可以怀疑的只有rte_pktmbuf_free了。
描述到这里,才真正到了本小节的核心点:mbuf的释放有讲究!讲究并不是指前面改造的mbuf释放方案,而是指使用rte_pktmbuf_free时,如何避坑!
那就研究一下rte_pktmbuf_free吧。下面不得不用代码的形式来介绍rte_pktmbuf_free,提取了rte_pktmbuf_free内部实现的一部分关键函数做简要说明。
第一步先介绍mbuf释放时,检查当前线程是否存在独享的小内存池cache。
1 #define RTE_PER_LCORE(name) (per_lcore_##name)
2
3 static inline unsigned
4 rte_lcore_id(void)
5 {
6 return RTE_PER_LCORE(_lcore_id);
7 }
8
9 static __rte_always_inline struct rte_mempool_cache *
10 rte_mempool_default_cache(struct rte_mempool *mp, unsigned lcore_id)
11 {
12 if (mp->cache_size == 0)
13 return NULL;
14
15 if (lcore_id >= RTE_MAX_LCORE)
16 return NULL;
17
18 rte_mempool_trace_default_cache(mp, lcore_id,
19 &mp->local_cache[lcore_id]);
20 return &mp->local_cache[lcore_id];
21 }
22
23 static __rte_always_inline void
24 rte_mempool_put_bulk(struct rte_mempool *mp, void * const *obj_table,
25 unsigned int n)
26 {
27 struct rte_mempool_cache *cache;
28 cache = rte_mempool_default_cache(mp, rte_lcore_id());
29 rte_mempool_trace_put_bulk(mp, obj_table, n, cache);
30 rte_mempool_generic_put(mp, obj_table, n, cache);
31 }
概括起来可表述为:
1、通过rte_mempool_default_cache检查当前线程是否存在独享的小内存池cache;

2、如果mp->local_cache[lcore_id]为NULL,则cache为空,表明当前线程不存在这么一个小内存池cache;否则cache是一个有效地址,即当前线程存在这么一个小内存池cache。注意rte_lcore_id(),后面会重点分析。
第二步,介绍mbuf释放时的两种不同逻辑。
1 static __rte_always_inline void 2 rte_mempool_do_generic_put(struct rte_mempool *mp, void * const *obj_table, 3 unsigned int n, struct rte_mempool_cache *cache) 4 { 5 void **cache_objs; 6 7 /* No cache provided */ 8 if (unlikely(cache == NULL)) 9 goto driver_enqueue; 10 11 /* increment stat now, adding in mempool always success */ 12 RTE_MEMPOOL_CACHE_STAT_ADD(cache, put_bulk, 1); 13 RTE_MEMPOOL_CACHE_STAT_ADD(cache, put_objs, n); 14 15 /* The request itself is too big for the cache */ 16 if (unlikely(n > cache->flushthresh)) 17 goto driver_enqueue_stats_incremented; 18 19 /* 20 * The cache follows the following algorithm: 21 * 1. If the objects cannot be added to the cache without crossing 22 * the flush threshold, flush the cache to the backend. 23 * 2. Add the objects to the cache. 24 */ 25 26 if (cache->len + n flushthresh) { 27 cache_objs = &cache->objs[cache->len]; 28 cache->len += n; 29 } else { 30 cache_objs = &cache->objs[0]; 31 rte_mempool_ops_enqueue_bulk(mp, cache_objs, cache->len); 32 cache->len = n; 33 } 34 35 /* Add the objects to the cache. */ 36 rte_memcpy(cache_objs, obj_table, sizeof(void *) * n); 37 38 return; 39 40 driver_enqueue: 41 42 /* increment stat now, adding in mempool always success */ 43 RTE_MEMPOOL_STAT_ADD(mp, put_bulk, 1); 44 RTE_MEMPOOL_STAT_ADD(mp, put_objs, n); 45 46 driver_enqueue_stats_incremented: 47 48 /* push objects to the backend */ 49 rte_mempool_ops_enqueue_bulk(mp, obj_table, n); 50 }
概括起来可表述为:
1、当cache为NULL,直接通过末尾的rte_mempool_ops_enqueue_bulk释放。注意,是每次只释放一个mbuf;
2、若cache不为NULL。当释放的个数小于阈值flushthresh时,将释放的mbuf拷贝至当前线程小内存池cache,并立即返回(不做真正的释放);当本次释放的mbuf个数与cache池之和即将超过flushthresh时,先一次性批量释放小cache内存池的所有mbuf,再将本次待释放的mbuf拷贝至cache池,再次立即返回。
DPDK为什么设计线程独享的小内存池cache?我想应该是为了更高效的释放mbuf。
好比我们去ATM机上取钱,假设总共取一万元。第一种是每次先插卡、输入密码、输入100、取出100、再拔卡,完成一次操作,反复执行1万次;第二种是先插卡、输入密码、输入10000、听一会钱翻滚的声音,取出1万元、最后拔卡。毋庸置疑,第二种方式的效率实在是高效太多,存钱也是一样的道理。我不禁想到,我不会就是用的第一种方式(每次只还一个mbuf)归还mbuf吧,难道当前每个线程的独享cache池未生效?此时,上面提到的rte_lcore_id()又重新成为了重要线索!
1、通过rte_lcore_id()可以得到什么?
返回的是一个unsigned值,最终用于获得当前线程的cache偏移地址。这个unsigned变量的值,是变量per_lcore__lcore_id 的值
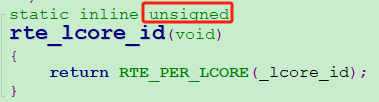
2、per_lcore__lcore_id变量如何定义的?
是通过 RTE_PER_LCORE 宏定义的。per_lcore_##name,’## ‘ 操作符用于将参数name与字符串 per_lcore_连接起来,形成新的标识符。由于传递的是_lcore_id,因此有最终定义变量per_lcore__lcore_id。但是什么时候定义的,还要继续看文章接下来的描述。

3、per_lcore__lcore_id变量在什么时候定义的,是什么时候初始化的?每个线程的独享cache池又是何时初始化的?怎么才能正确使用cache池?
为了弄清楚这三个问题,又追了一遍DPDK源码,而且稍微有些复杂,让我娓娓道来吧。
(a)per_lcore__lcore_id在DPDK为每一个逻辑核创建worker线程时定义并初始化的
1、DPDK初始化调用rte_eal_init过程中,会为当前设备的所有逻辑核创建一个worker线程。语句RTE_LCORE_FOREACH_WORKER是一个循环,RTE_MAX_LCORE为当前设备的逻辑核个数,有多少个逻辑核,就创建多少个worker线程。


2、接下来,在每一次的循环过程中,调用pthread_create,使用回调函数eal_worker_thread_loop创建每个逻辑核的worker线程

3、eal_worker_thread_loop封装了eal_thread_loop,到此我们终于看到了__rte_thread_init,即per_lcore__lcore_id变量定义并初始化的函数
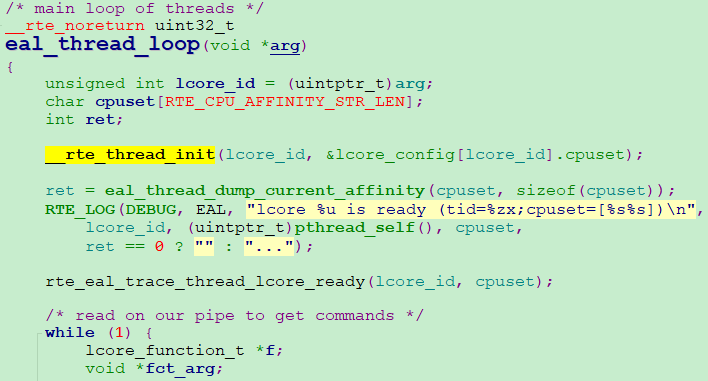
4、RTE_PER_LCORE(_lcore_id) 定义变量per_lcore__lcore_id,整个语句RTE_PER_LCORE(_lcore_id) = lcore_id 完成对per_lcore__lcore_id变量赋值,赋值为当前逻辑核的 id 值,通过lcore_id传参 !
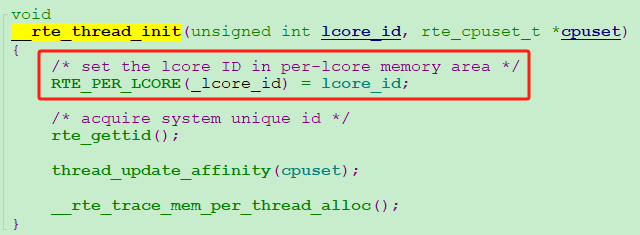
(b) 每个线程独享的cache池何时初始化的?
答案就是在dpdk创建公共大内存池时完成的,通过rte_pktmbuf_pool_create最终调用rte_mempool_create_empty实现。你看,创建内存池的函数里还为每一个逻辑核创建了一个独享cache池,locore_id就是每个逻辑核的id!这样,每个独立的小cache池就和每个worker线程对应起来了。

(c)怎么才能正确使用cache池?
兄弟们,走过路过,千万不能错过。秘籍终于来啦!
那就是:需要释放mbuf的线程,也就是会调用rte_pktmbuf_free方法的线程,必须通过rte_eal_remote_launch来创建!

rte_eal_remote_launch的参数f就是用户指定的业务回调函数,arg是 f 的运行参数,worker_id是你希望业务函数 f所运行的逻辑核id,因为通过正确的worker_id才能和对应的worker线程实现通信!
rte_eal_remote_launch最后通过eal_thread_wak服务器托管网e_worker向对应逻辑核的worker线程管道发送一个message,通知worker运行指定函数 f。
最后,对应worker的回调函数eal_thread_loop通过while,循环等待rte_eal_remote_launch发送的message,收到消息后,便开始执行你传递的业务回调函数f 。
函数f 里调用rte_pktmbuf_free时,通过rte_lcore_id()可以获取到本worker线程定义并初始化过的per_lcore__lcore_id变量,因此最终成功找到本线程的独享cache池地址!
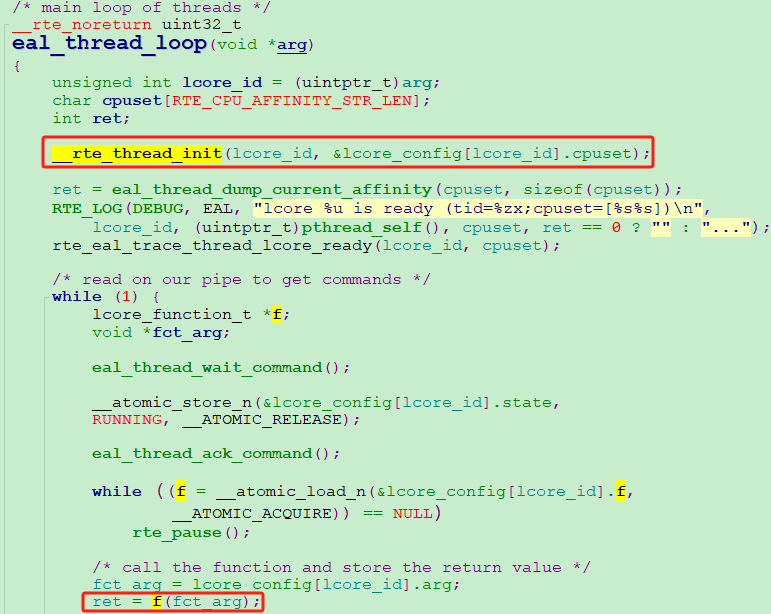
最后一个问题!为什么我的线程专属cache池未生效?
到这里,终于可以明确回答了,我们的业务线程都是自己调用的pthread_create来创建的业务线程,创建过程中也未调用__rte_thread_init初始化per_lcore__lcore_id变量(虽然我们业务线程也是绑核、独占该线程),导致各线程调用rte_pktmbuf_free释放mbuf时,变量per_lcore__lcore_id都是未定义的!返回的是一个不正确的值,导致cache为NULL,因为找不到这么一个线程专享cache池,所以最终所有线程的mbuf都是逐个释放的!后来改为rte_eal_remote_launch才最终解决问题!
使用pthread_create来直接创建的业务线程,再调用__rte_thread_init初始化per_lcore__lcore_id变量,在释放mbuf时讲道理也能正确获取到线程cache池,不过没有求证过。
到这里,本小节终于讲完了。整理这些信息感觉挺累的,做程序员是真的不容易!
二、x86平台优化总结
回头看x86的优化过程,好比是从头到尾的疏通了一条下水道。
线程任务尽可能轻量–解决了引水,保证水都能进来;mbuf的释放有讲究–既疏通了内部水道,也实现了引水的完整排放。自从水道畅通,10Gbps,20Gbps,40Gbps吞吐都不在话下啦!
除了绑核、线程独占、内存池巨页分配、CPU performance模式设置等基本的性能优化手段,DPDK的实际性能表现还是和你的业务代码框架和实现有很大关系。零件都是好零件,就看自己如何搭,希望大家少踩点坑吧!
看到这,请先喝口水,休息一会吧!接下来的内容也很精彩。
下 篇
一、arm平台调查优化经历
接下来我们看点不一样的:丢包跟你没关系!瓦特?

相信我XDM:是软件触碰了硬件性能瓶颈。
将x86平台无比丝滑的业务搬到了arm平台,结果惨不忍睹。arm国产化平台我们尝试过“XX”的两款服务器级别CPU,结合我们的业务,数据不仅丢得多,而且丢得非常的莫名其妙。
(1)丢包现象
先看看发生了什么。

图12
首先是丢包,其次是丢包现象与上前文图3有些区别,图3是:丢包时伴随队列que满。
而此时是:发生丢包时,队列que并没有满,且距离队列满还非常遥远(队列已经设置得非常大,32768个描述符空位)。查看其它统计:各worker线程的待处理mbuf很少,没有堆积;也没有出现rx_nombuf,即内存池足够大,不存在内存申请失败。
这就完全不知道从哪开始着手调查了,最难理解的就是:只使用DPDK进行收包(相当于屏蔽了所有业务流程),然后立即释放mbuf,还是会发生丢包,并且其它所有指标居然都是正常的。
这到底是撞了什么鬼?竟然还有如此怪异的现象发生,丢包到底丢在哪里了,实话实说,我是真的不知道!
(2)丢包点追踪
到了说不清,道不明的阶段,混沌了。但是老板不认啊,拿钱办事,你得说个一二三。说不知道就是请出门左转见HR,打工人的卑微。
没办法,继续看起了源码。思考,分析了一段时间,结合理论,陆陆续续才开始产生了一些新的思路和想法。
1、imissed的定义是什么?

Total of Rx packets dropped by the HW。指统计的是被hardware所丢弃包的总和,即硬件丢弃的packet之和。什么硬件?不清楚。
because there are no available buffer (i.e. Rx queues are full)。因为Rx queues没有可用buffer,例如:Rx queues接收队列满。注意这里只提到了“接收队列满”这一种情况,这种描述符合上文图3的现象:丢包时伴随队列满。但是并不符合图12的丢包情形:丢包时队列未满。
2、从物理层到最终的应用层,数据包是如何流转的?

a、网卡收到数据包;
b、由DMA将数据包拷贝到内存中的ring buffer,即DPDK的收包队列Rx queue;
c、应用程序通过轮询的方式将数据包取走,供业务使用。
3、猜测是网卡丢包
结合图3和图12的两种丢包现象分析:
图3:DPDK的Rx queue已经被收上来的数据包填满,无可用buffer,因此DMA也无法将数据包拷贝到Rx queue的地址空间,所以imissed同步增长。
图12:Rx queue统计值未满,很空,imissed却偶尔增长,偶发丢包。
这里假设imissed是基于DPDK Rx queue的统计。那第一种和第二种丢包就会自相矛盾,因为第二种丢包现象发生时,queue根本没有满,那么不可能出现imissed统计增长。因此“imissed是基于DPDK Rx queue的统计”这种假设是不成立的。
DPDK对queue的统计不可靠?不可能的事情。
4、为什么判断是网卡丢包?
我们使用的是82599 10Gigabit 网卡,且测试流量在6Gbps,按道理是能覆盖的。
回忆一下前面描述的imissed定义,指的是被硬件所丢弃包的总和。再看看DPDK源码imissed的统计相关代码:
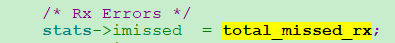
total_missed_rx的统计来源于8个IXGBE_MPC寄存器。
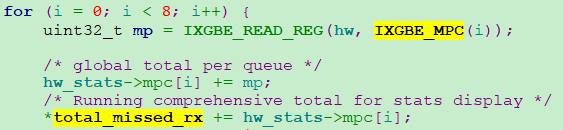
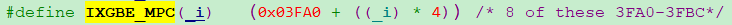
统计最终从IXGBE_MPC寄存器完成读取,IXGBE_MPC寄存器是ixgbe网卡的寄存器吗?又下载一份82599 ixgbe网卡手册继续追,总共1000+页,感到崩溃。
只有搜关键字了,“IXGBE_MPC”,“MPC”,“0x03FA0”,还真找着了。ixgbe网卡里叫RXMPC寄存器,也是总共有8个,和DPDK源码里的寄存器地址对上了。
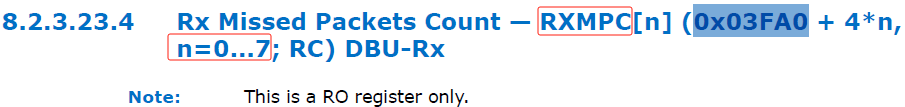
再找找RXMPC寄存器的相关信息。

手册上说,当Rx packet buffer发生overflows时,会丢包!
Missed packet interrupt is activated for each received packetthat overflows theRx packet buffer (overrun)。即当 Rx packet buffer 溢出时,接收的每一个包都会产生一个丢包中断事件,并且记录在“EICR”寄存器的第17bit。
另外,每一个丢包都会被计数增加至寄存器 RXMPC[n] 中。明白了,DPDK的imissed统计数值读取的是网卡的RXMPC计数寄存器!
和DPDK源码关于imissed的定义:统计的是被hardware所丢弃包的总和。这个hardware指的就是网卡,这里与DPDK源码又对上啦!
那 Rx packet buffer 是哪里的buffer,是指的DPDK的Rx queue,还是网卡自身的Rx packet buffer?
看到这里越来越兴奋了,再找一下Rx packet buffer是什么。

手册说是一个可编程的内存接收空间,大小为512KB。再看看详细介绍。
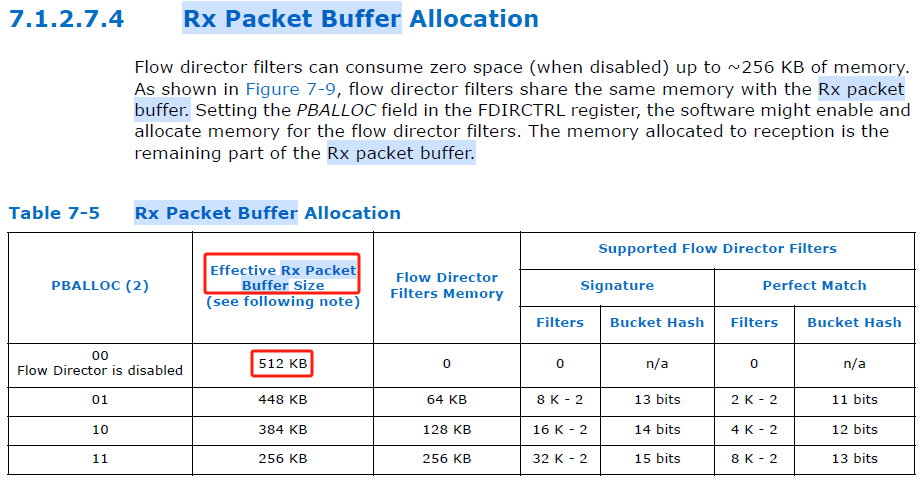
Rx packet buffer也指的是82599网卡自身的包存储缓冲区!总共有512KB。且网卡支持流控,当关闭流控时,所有的512KB会全部用于数据接收。
再找找手册上有没有与数据包接收的相关介绍。

看到这里我已经高兴坏了。因为手册已经说得很清楚了,网卡收到数据包后会先将数据包存储至网卡的receive data FIFO(即512KB的Rx packet buffer),然后再通过DMA将数据包投递至指定的本主机的接收队列里。receive queue,才是指的DPDK的Rx queue!
上面所有的关键信息总结起来就是:
a、82599网卡有一个数据包接收的FIFO队列缓冲区,最大为512KB;
b、当512KB的Rx packet buffer发生overflow时,网卡会丢包;
c、网卡发生丢包时,将丢包计数到 RXMPC寄存器,同时会产生丢包中断事件,且事件信息记录在网卡EICR寄存器的第17 bit。
(3)网卡丢包证明
接下来就是该证实上面的猜测了。记得证实猜测的前一个晚上很兴奋,一直没睡好,总想着第二天赶紧去把它坐实了!
我们在ixgbe imissed的统计函数ixgbe_dev_stats_get,模拟读取imissed的统计值,增加读取EICR寄存器变量的逻辑,最终通过日志实时打印EICR寄存器值。
一起来见证精彩时刻:

图13
图13可总结为:
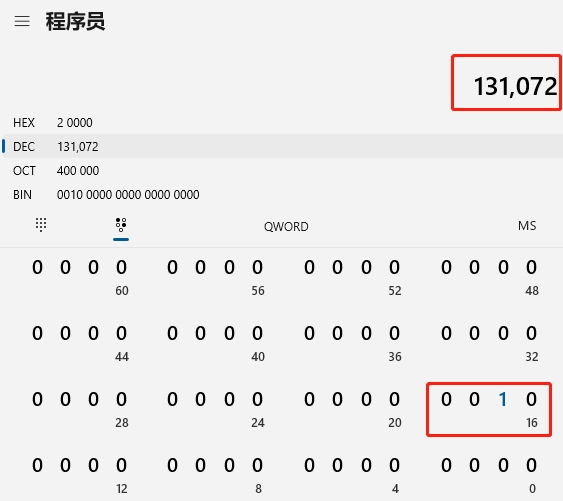
1、当第一次发生imissed时,EICR寄存器的十进制值为131072,que未满;
2、第二次、第三次发生imissed时,EICR也为131072,que也未满;
3、其它时刻,未发生丢包,EICR值均为0。
日志里的“131072”代表了什么?就是EICR寄存器第17bit被置1时的十进制值。真相大白,真的是网卡发生了丢包啊!
兴奋之情,实在是无以言表!我居然也体会到了:提出猜想,并验证猜想的快乐!
到这里我们就可以把网卡imissed丢包归类为两种情况了:
1、DPDK的环形接收队列Rx queue溢出时,会发生imissed;
很明显,DPDK的Rx queue溢出,代表上层来不及收包,Rx queue无多余空闲空间,那DMA也无法将网卡队列的数据包及时拷贝至Rx queue,最终导致网卡的 FIFO 队列溢出,出现丢包。这种情形是大家最常见的!
2、DPDK的环形接收队列Rx queue空闲,而网卡的FIFO队列Rx packet buffer独自溢出时,也会发生imissed。
这种情况是不多见的,但是我们arm平台刚好碰到了这种情况!
两种丢包情形,其实本质都是因为网卡的缓冲区溢出导致,一个是间接导致,一个是直接导致。这个结论在这之前是不是没见过?哈哈。我搜遍了内外网反正是没看见过。
(4)网卡缓冲区为什么会独自溢出?
回答这个问题前,我们先来看看网络数据是如何达到内存的。
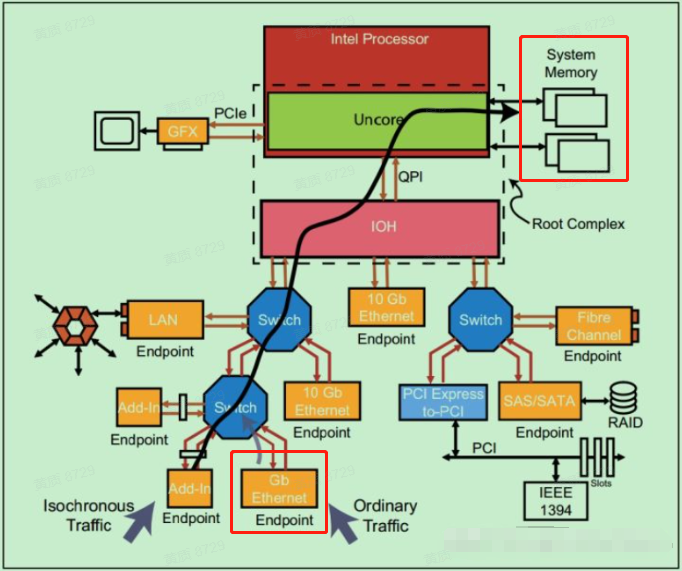
简单描述为:
1、网络数据包到达网卡;
2、DMA将数据包从网卡经由PCIE通道传递至与CPU直连的内存中。
那在硬件上至少有3个地方可能存在性能瓶颈,一个是PCIE通道带宽;第二个是内存频率;第三个是CPU。
PCIE,协商出来的带宽是4GB/s,10Gbps收包,即使加上业务I/O速率,远远低于这个值,因此应该不存在性能瓶颈。
内存频率,我们x86也是使用一样的内存条,按理也不存在性能瓶颈。
那就只剩CPU了,为何怀疑CPU存在性能瓶颈呢?我们再看一个图。
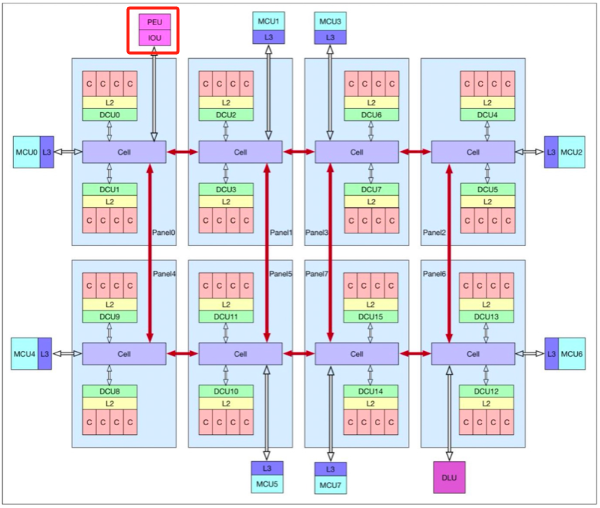
如果有同行以前看到过这个图,其实就知道arm平台的这款芯片名字了。
从官方给的CPU结构图看,PEU(可以理解为是PCIE与CPU的接口)与numa0直接相连,且只与numa0相连。我个人理解:这种架构比较容易触碰性能瓶颈,因为整个CPU的所有I/O数据,包括网络I/O、磁盘I/O都必须经过numa0,numa0表现的带宽就会成为整个CPU的性能瓶颈。而且其它numa的I/O数据只能通过numa0的QPI总线传递和转发。
因此,怀疑是网卡单独溢出的原因是:I/O增大时,数据规模达到numa0的数据带宽,多种数据形成竞争关系,导致DMA不足以及时的将网卡缓冲区数据传递至内存,最终导致网卡缓冲区溢出丢包。
不过这里我只是猜测,也没有办法去证实了。如果有这方面的专家,还望不吝赐教。
再看看intel某款芯片的CPU架构图:
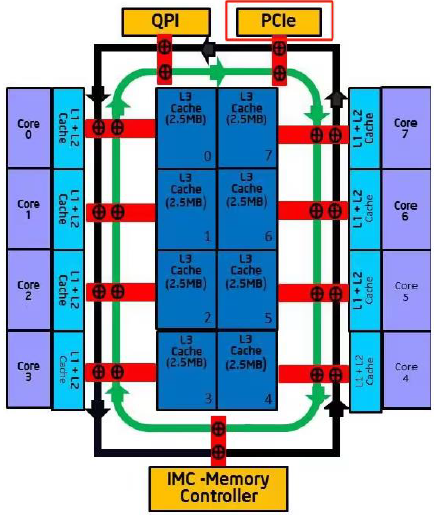
PCIE总线不与任何核心直接相连,节点相连,且各numa或者core获取 I/O 数据不需要任何其它numa或者core来中转,可以极大的提高总线带宽。
(5)还有性能优化空间吗?
arm平台碰到的丢包问题完全超出了业务开发人员的能力范畴。不过还好分析出了丢包点和丢包原因,俗称甩锅。
但是任何东西,包括人,有时候榨一榨就还能得到点什么,懂的都懂。
继续做了以下几点优化:
1、DPDK收包相关线程工作在同一个numa上;
2、DPDK内存池分配在收包线程所在的numa节点上;
3、尽可能的加大内存池规模。
你还别说,又提升了2个Gbps,应该是DPDK减小资源竞争获得的收益。不过至此以后真的再也没有任何提升手段了。
哦,差点忘了,arm平台的DPDK还有一个坑,也是无意中发现的:收包函数rte_eth_rx_burst的第四个参数nb_pkts,一定要是2的指数幂,即2 ^ 10 =1024,2 ^ 14 = 16384,2 ^ 15 =32768这种形式。如果指定任意2的非指数幂整数,DPDK会将向量化收包(neon,arm平台的SIMD技术)替换为非向量化收包函数,极大的降低收包性能。例如将ixgbe_recv_pkts_vec替换为ixgbe_recv_pkts_bulk_alloc。
二、arm平台优化总结
arm平台碰到了很罕见的丢包现象,通过查阅源码和网卡手册,最终定位到是网卡自身发生了丢包,跟DPDK没有太大关系。如果非要说有关系,那就是DPDK占用的数据通道带宽挤压了DMA的数据传递。
另外一个大的收获就是确定了imissed一定是基于网卡的统计。发生imissed时,一种是我们常见的间接原因导致imissed(上层不能及时收包,导致DPDK ring满,然后导致DMA无法投递至ring环,最终网卡缓冲区溢出);另一种就是我们在arm平台碰到的直接原因导致的imissed(资源竞争直接导致DMA无法及时将数据包投递至DPDK ring环,导致网卡缓冲区溢出,且DPDK ring环非常空闲)。
最后通过减小DPDK资源竞争的方法(一是减少垮numa内存访问,二是DPDK加速获取报文接收的mbuf。我理解可以减少数据在多种资源下的传输吧),提升了一丢丢性能。
好了,前前后后写了一个月,本次就分享到这里吧!谢谢阅读!
技术是不断实践积累的,在此分享出来与大家一起共勉!
如果文章对你有些许帮助,还请各位技术爱好者登录点赞呀,非常感谢!
本文来自博客园,作者:T-BARBARIANS,博文严禁转载,转载必究!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
控制理论中的可观测性是指:系统可以由其外部输出确定其内部状态的程度。在复杂 IT 系统中,具备可观测性是为了让系统能达到某个预定的稳定性、错误率目标。随着微服务数量的急速膨胀和云原生基础设施的快速演进,建设可观测性已经成为了保障业务稳定性的必要条件。 然而,…
