
原文链接点击 DPDK内存碎片优化,性能最高提升30+倍!
背景
DPDK(Data Plane Development Kit)是一个用于高性能数据包处理的开源项目,常用于构建各类高性能网络应用。基于 DPDK 的设计思想及其提供的线程/内存模型,SPDK(Storage Performance Development Kit)被开发出来,广泛用于构建各类高性能存储应用。
为了提升应用程序的性能,DPDK 基于大页内存实现了一套自己的内存管理接口,这些内存接口被广泛应用于SPDK/DPDK 的各类应用中,而且不少应用会在 IO 路径中进行内存的分配与释放。DPDK 常用的内存接口有:
void *rte_malloc(const char *type, size_t size, unsigned align);
void *rte_realloc(void *ptr, size_t size, unsigned int align);
void rte_free(void *ptr);
在实际使用过程中,我们发现 DPDK 原生的内存分配接口在一些场景下有着较大的性能问题。本文将结合实际遇到的问题,为大家介绍如何优化 DPDK 内存碎片问题。
问题现象
当接到 DPDK 内存碎片化的问题反馈后,经过多方排查,最终将怀疑点锁定到大页内存的分配上,并将实际使用时内存分配的逻辑与参数进行抽象后,编写了如下的测试 case:
uint64_t entry_time, time;
size_t size = 4096;
unsigned align = 4096;
for (int j = 0; j 单线程执行内存分配,总共分配 1 万个 4k 大小的对象, 每 2000 次分配后计算平均耗时,中间不释放内存,各阶段单次平均耗时如下表:
| malloc次数 | 平均耗时 |
|---|---|
| 0-2000 | 15us |
| 2000-4000 | 44us |
| 4000-6000 | 77us |
| 6000-8000 | 168us |
| 8000-10000 | 253us |
从上表可以看到,随着分配次数的增加,后续每分配 4K内存的耗时在线性增加,按照我们之前的理解,单线程下多次分配内存耗时不会过高,每次分配4K内存的耗时应该差不多,但是当前结果与预期不符,针对该场景我们进行了深入分析。
分析
首先结合代码分析了 DPDK 分配的逻辑,然后结合火焰图对怀疑点加了些调试手段以进一步 debug,最终得到了结论,并对结论进行了的验证。
代码分析
DPDK 通过 heap 管理每个 NUMA 节点上的大页内存,对于一块连续内存,首先转换成一个 struct malloc_elem 对象 elem,再将 elem 插入链表中,并保证链表中每项的地址按大小排序。每个 heap 都维护了 13 个链表,每个链表中的 elem 大小在相同范围内,比如大小 0-256 的 elem 在同一个链表,256-1024 的 elem 在同一个链表,1024-4096 的 elem 在同一个链表…。
DPDK内存分配的主要逻辑如下图所示:
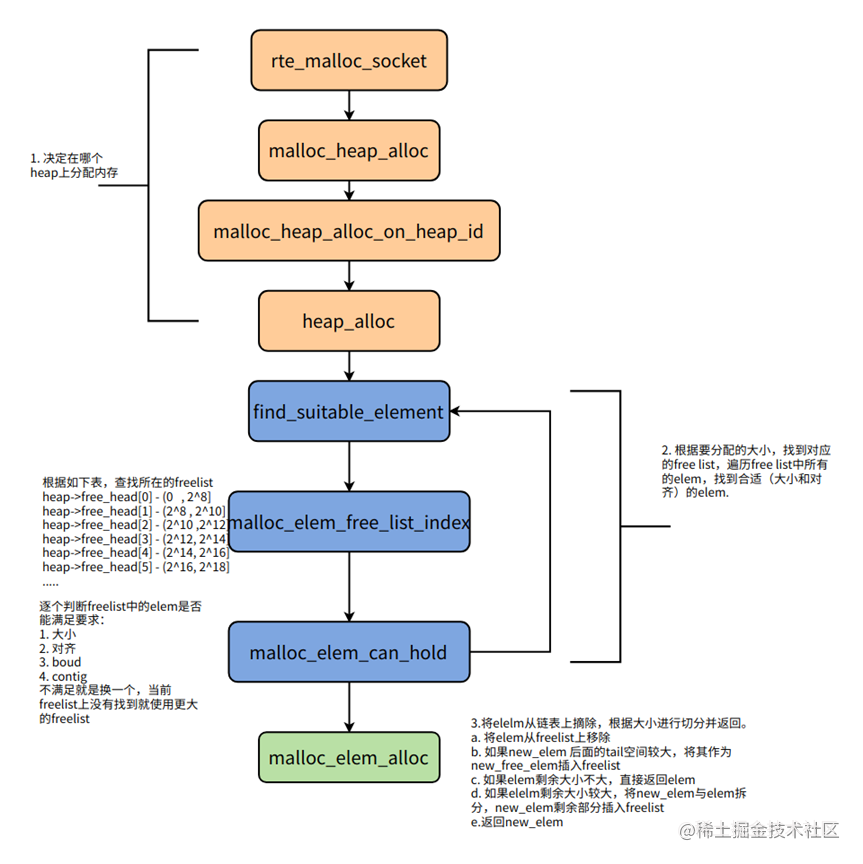
- 根据参数和当前线程所在 CPU 决定从哪个 heap 上分配内存。
- 根据要分配的大小,找到对应的链表(对应代码中的 free_head[N]),遍历该链表中所有的 elem,找到合适(满足大小、对齐等要求)的 elem。
- 将 elelm 从链表上摘除,根据大小进行切分并返回。
抓火焰图
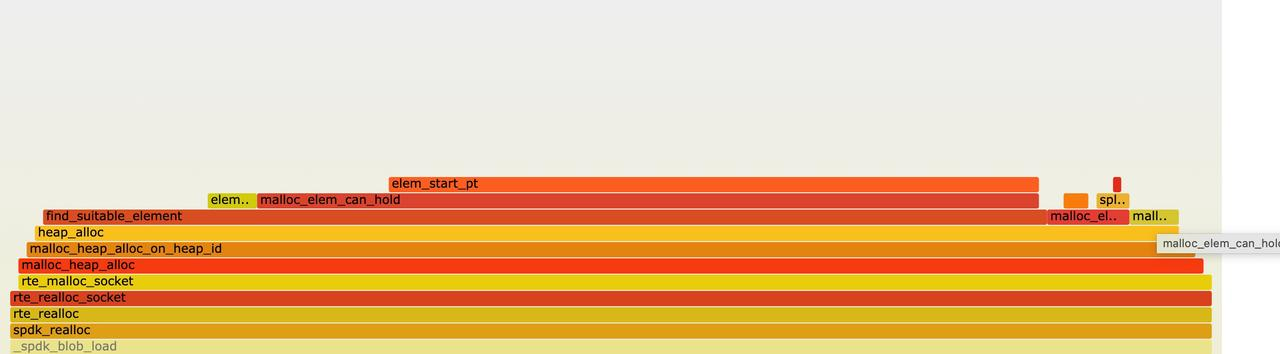
可以看到 find_subitable_element 函数耗时非常高,这个函数的作用就是遍历链表上的 elem,找到满足要求的 elelm。以分配 4K 内存为例,首先遍历第三个链表即 free_head[2] 上的所有 elem,逐个检查是否满足要求,如果找到合适的 elem,就从链表上摘除,根据大小进行切分并返回,如果 free_head[2] 上找不到,会依次在free_head[3]、free_head[4] 上查找,直到找到为止。
从代码分析单次判断 elem 是否满足要求耗时应该很短,所以怀疑是链表上元素过多,导致整个遍历耗时过久。
那么我们可以尝试添加些 log,看看各个链表上 elem 的个数是否有变化
添加调试手段
经分析 DPDK 有些内存 dump 的 rpc,其中用到的 malloc_heap_get_stats 函数会遍历 heap 上所有链表上的 elem,我们可以简单修改,查看每个链表上的 elem 个数。
系统刚启动完成时,可以看到 elem 个数不多,大小也比较集中。
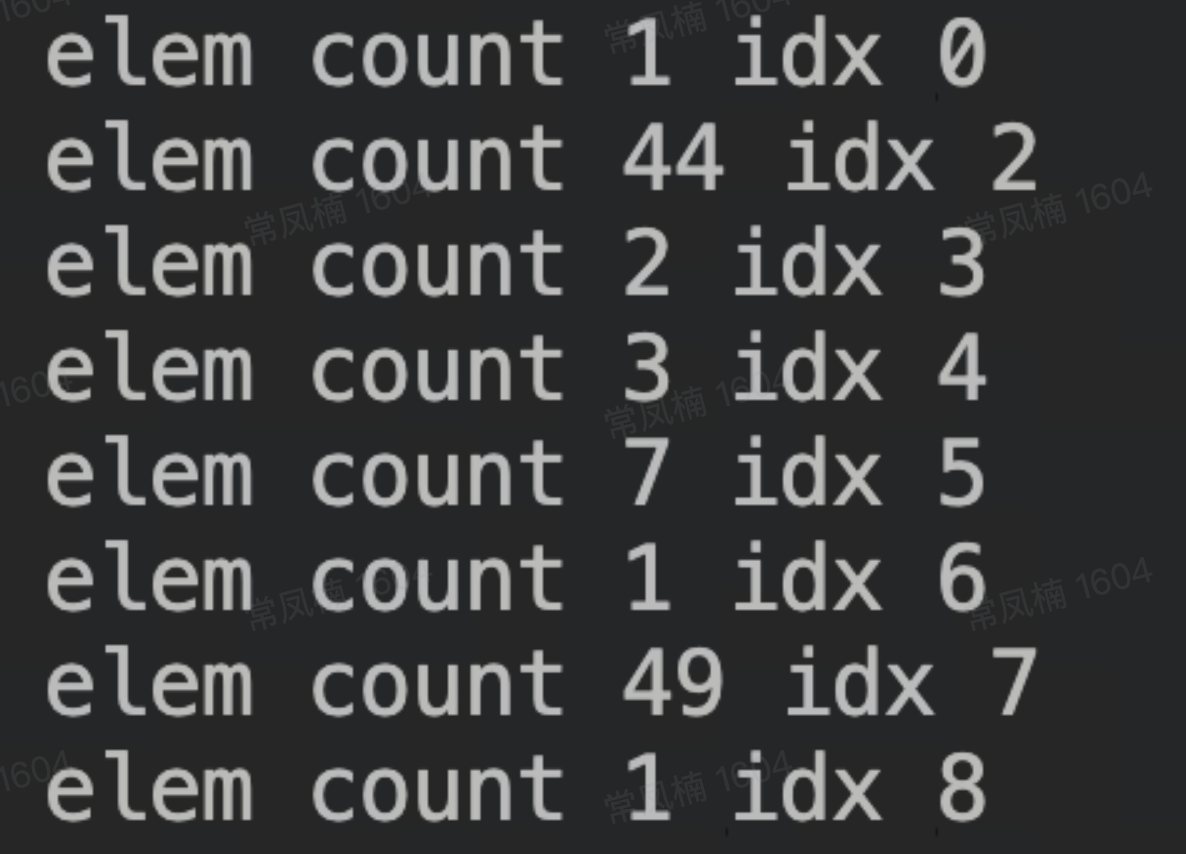
分配 2000 个 4K 内存后,看到 free_head[2] 上 elem 数量明显增加:
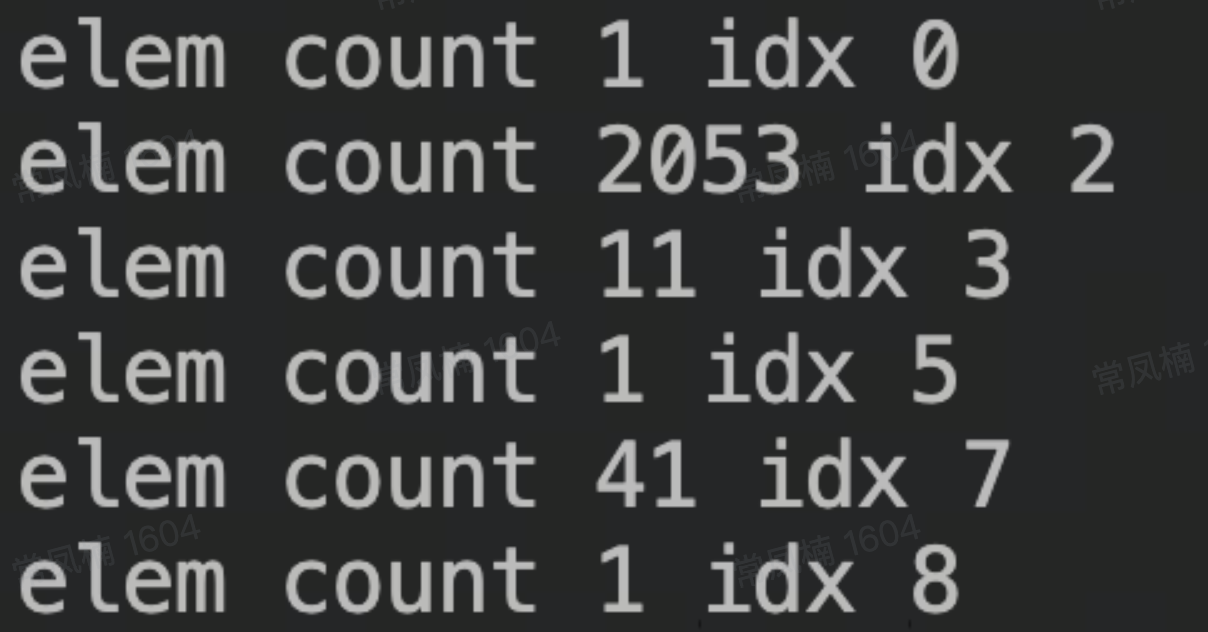
- 分配 4000 个 4K 内存后:
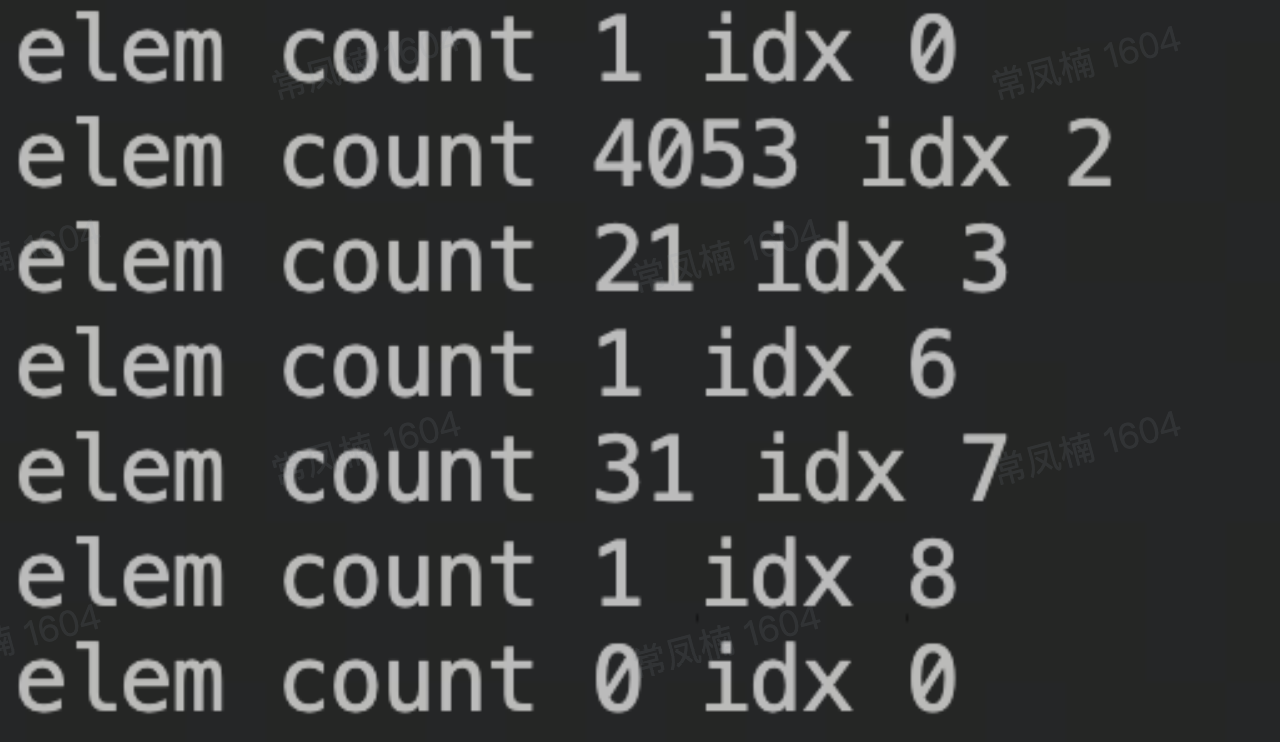
可以看到 free_head[2] 上 elem 个数随着分配次数的增加线性增加,这会导致每次分配 4K 所需遍历的 elem 个数也会增加,那么为什么会这样呢?
原因分析
添加 log 发现,free_head[2] 上所有 elem 的大小都小于 4096 字节:
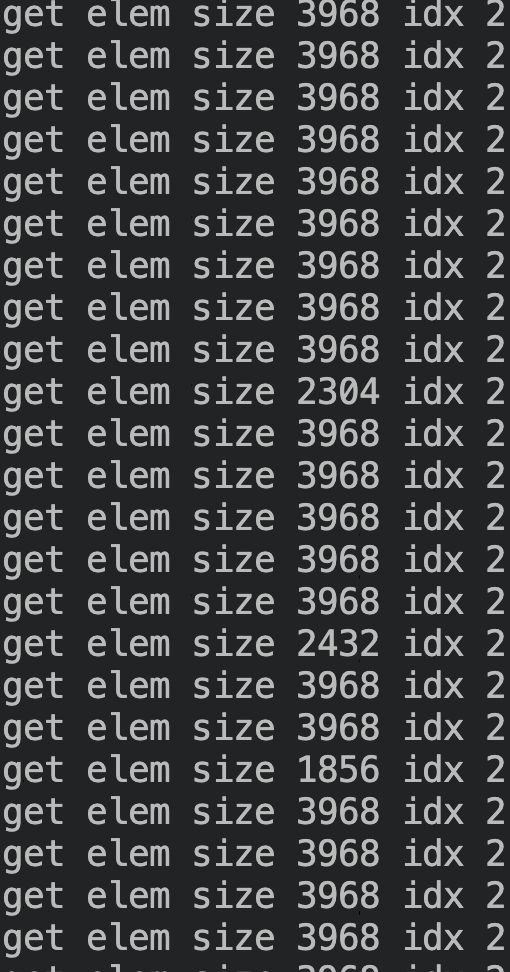
为什么会出现这么多小的 elem 呢?经分析我们发现是在分配时切分 elem 而生成,切分 elem 示意图如下:
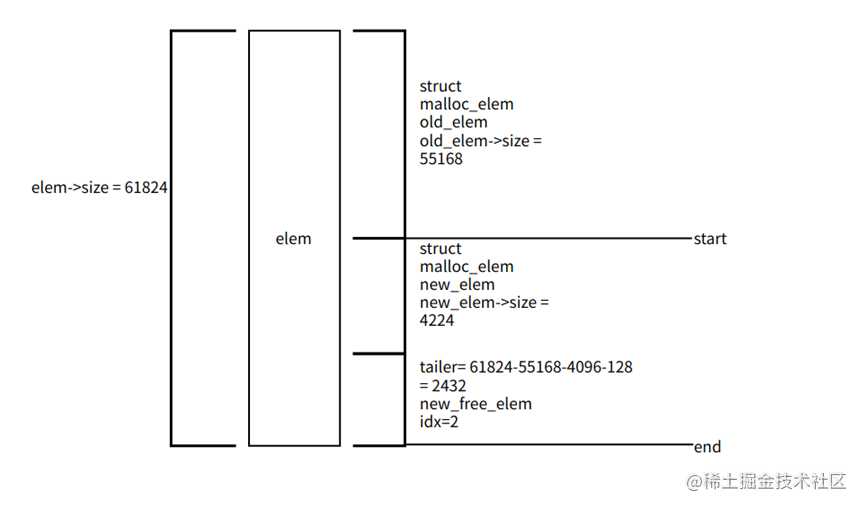
以上图为例:
- 当调用 find_suitable_element 函数后,找到了一个满足要求的 elem,该 elem 大小一般远大于 4096 字节,所以在 malloc_elem_alloc 中会切分。
- malloc_elem_alloc 中会从 elem 末尾开始,根据大小和对齐算出 new_elem 的地址,由于分配内存要求 4K 对齐,所以 end-start 很可能大于 4096 ,而我们只要 4096,那么 new_elem 后面的 tailer 这段空间为避免浪费,是可以被重新利用的,由于其大小是 2432,也会被插入 free_head[2] 中。这也就导致了 free_head[2] 上 elem 个数在线性增加。
验证
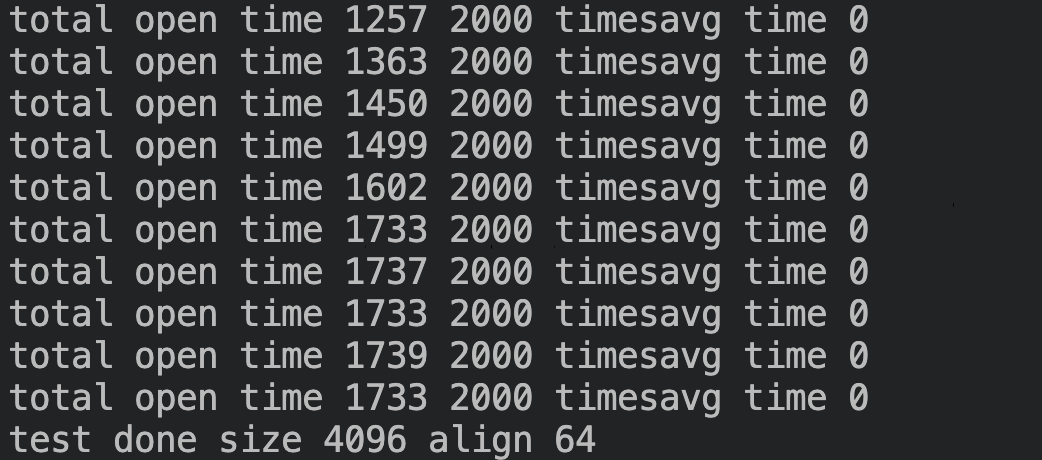
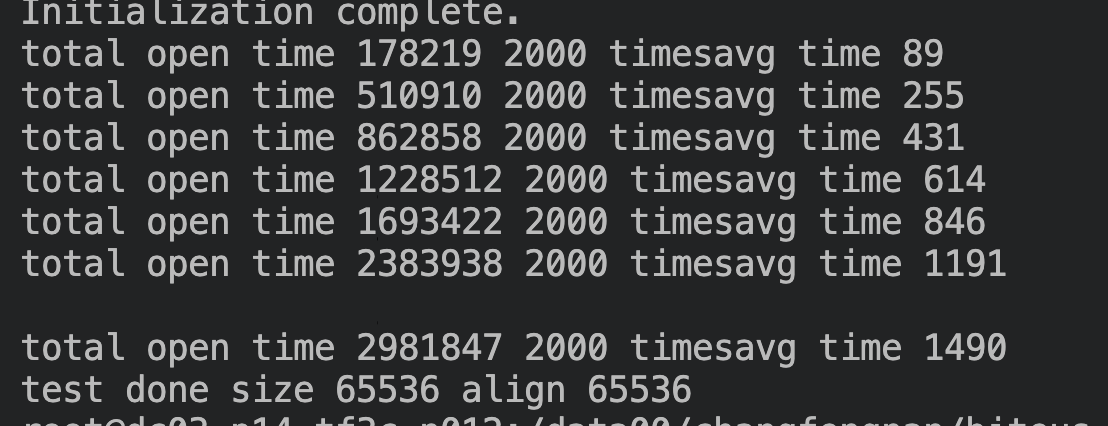
根据上述分析,如果 align 为 64 字节,elem 的尾部空间应该小于 64,不会再插入链表,就不会有这个问题,将测试代码中的 align 参数改为 64 后,测试结果如下:
平均耗时 0.7us ~ 0.8us,不再有线性增加的现象。
那么是不是所有的 align 都有这个问题?我们又测了分配 64K 大小,align 为 64K 的情况,也出现了相同的情况。
结论
DPDK在管理内存时会将相邻大小的 elem 放在一个链表,分配时根据大小 4K 找到对应的链表 free_head[2],遍历该链表上的 elem 来查找满足要求的 elem,当分配时指定 align 过大,会使找到的 elem 尾部空间较大,为避免空间浪费会将尾部空间重新插入 free_head[2] 链表中,导致 free_head[2] 链表中 elem 数量增多,下次分配时又需要先遍历 free_head[2],使每次分配耗时呈线性增加。
解决方案
方案一:
struct malloc_heap {
rte_spinlock_t lock;
LIST_HEAD(, malloc_elem) free_head[RTE_HEAP_NUM_FREELISTS];
size_t free_head_max_size[RTE_HEAP_NUM_FREELISTS];
.....
}
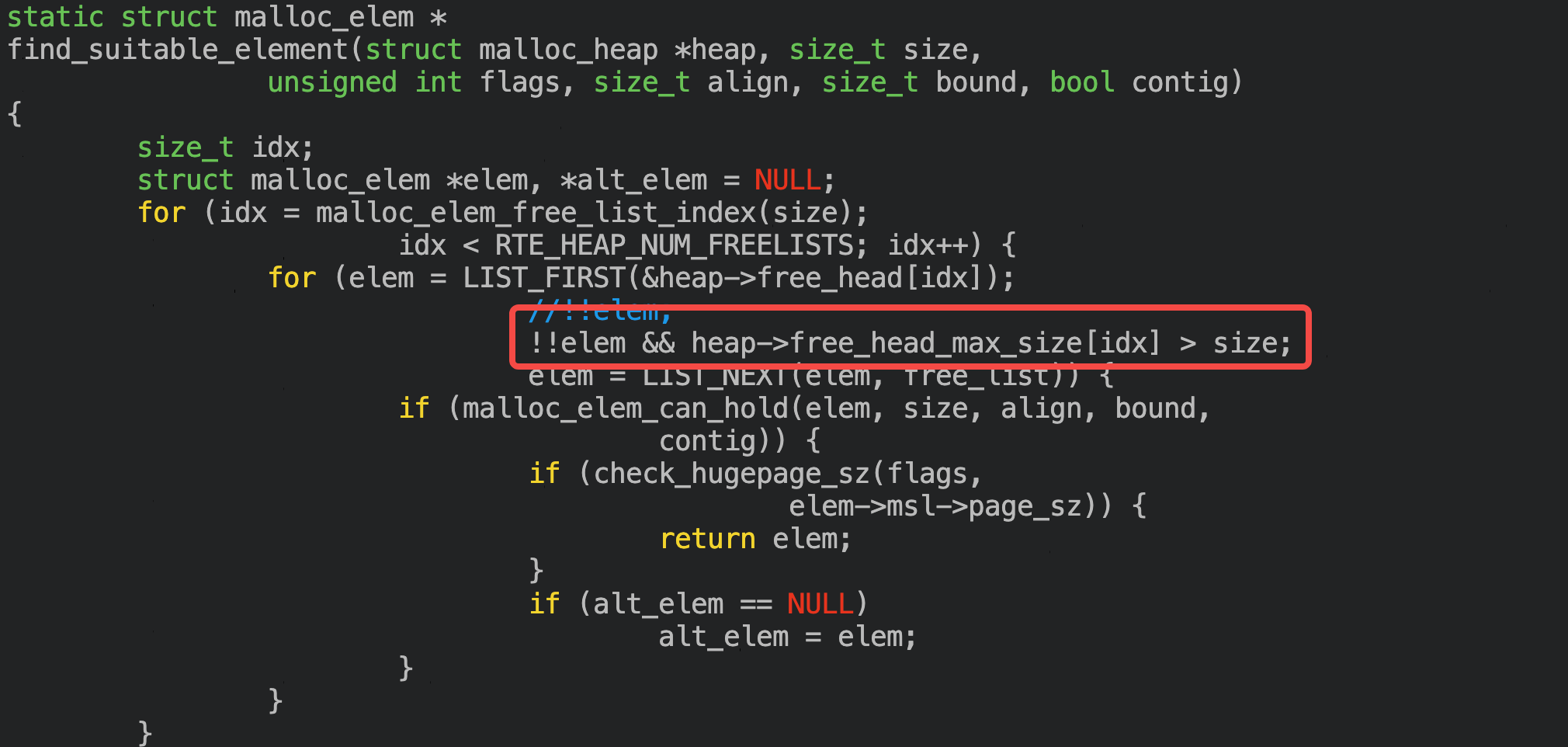
在 heap 中新增 free_head_max_size 数组,记录每个 freelist 中 elem 的最大 size,遍历时如果要求的 size 大于该 freelist 上最大的size,可以直接跳过,但缺点是每次分配/释放时都要维护该数组。
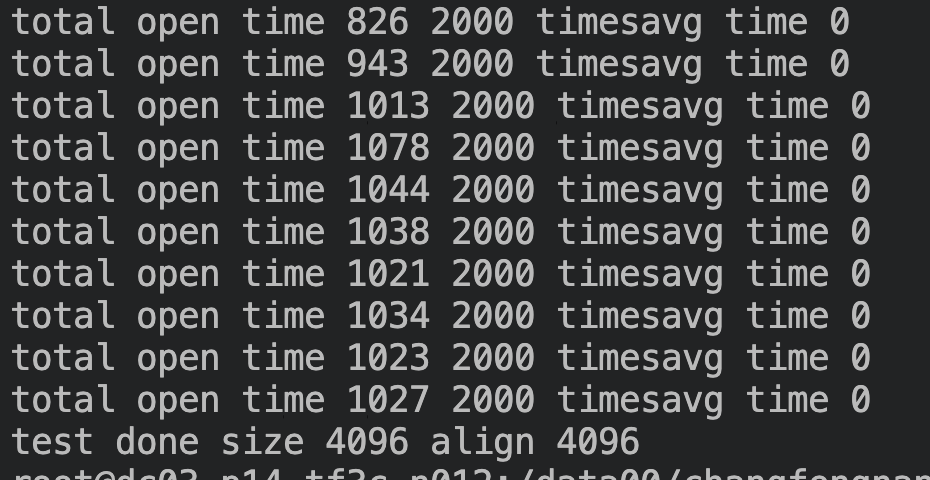
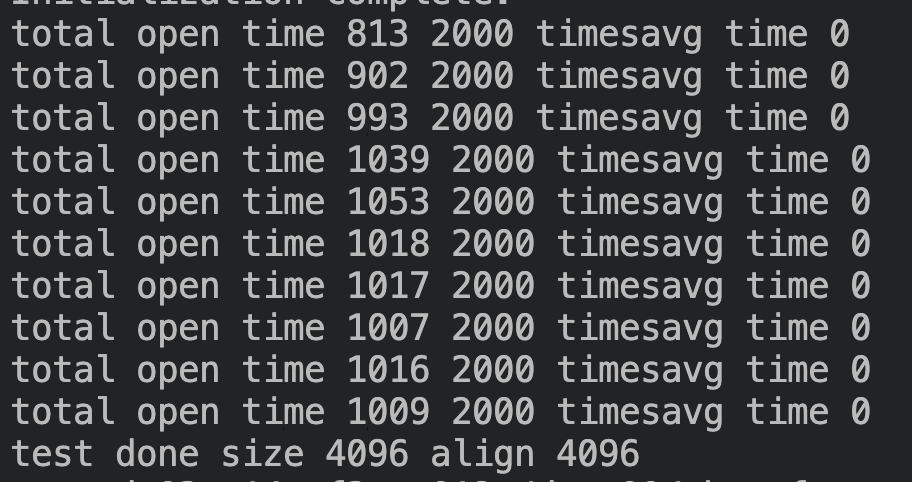
可以看到单次分配耗时没有再呈线性增加,平均耗时稳定在0.5us左右,对比之前性能提升30 倍+:
方案二:
在原有的逻辑中,大小为 4K 的 elem 在 free_head[2] 上,4K 刚好处于边界,如果修改链表选择的规则,改到在 free_head[3] 进行查找,也可以解决问题。以分配 4K 为例,在 4K-16K 的链表上更容易找到对应的 elem,16K 也是在 16K-64K 的链表上能查找的概率更高。

也即每个链表上包含的元素大小范围如下:
heap->free_head[ 0 ] - ( 0 , 2 ^ 8 ) 0 free_head[ 1 ] - [ 2 ^ 8 , 2 ^ 10 ) 256 free_head[ 2 ] - [ 2 ^ 10 , 2 ^ 12 ) 1024 free_head[ 3 ] - [ 2 ^ 12 , 2 ^ 14 ) 4 k free_head[ 4 ] - [ 2 ^ 14 , 2 ^ 16 ) 16 k 对比测试效果与方案一无明显差异,优点是对 16K/64K 等处于边界点的分配效率也有提升,缺点是可能会对极端情况有影响,需要更多测试。
测试验证
单线程
bulk:连续分配 1000 个对象,memset 后,1000 个对象一起释放,统计单次平均分配/释放耗时
no-bulk:分配 1 个对象,memset, delay 5us, 释放,重复 1 万次,统计平均分配和释放的总耗时
realloc:分配 1 个对象,memset, realloc 成原本 2 倍大小,memset, realloc 成原本 4 倍大小,memset,释放,重复 1000 次,统计平均总耗时
| 单次分配大小 | 测试项 | 修改前align=64 | 修改后align=64 | 修改前align=4096 | 修改后align=4096 |
|---|---|---|---|---|---|
| 64 | bulk | 0.309/0.083 | 0.287/0.079 | / | / |
| no-bluk | 5.275 | 5.273 | / | / | |
| realloc | 0.538 | 0.512 | / | / | |
| 128 | bulk | 0.410/0.074 | 0.399/0.085 | / | / |
| no-bluk | 5.270 | 5.264 | / | / | |
| realloc | 0.584 | 0.616 | / | / | |
| 512 | bulk | 0.380/0.115 | 0.382/0.086 | / | / |
| no-bluk | 5.291 | 5.292 | / | / | |
| realloc | 1.033 | 0.963 | / | / | |
| 1024 | bulk | 0.636/0.117 | 0.36/0.146 | / | / |
| no-bluk | 5.291 | 5.289 | / | / | |
| realloc | 1.56 | 1.31us | / | / | |
| 3072 | bulk | 0.801/0.386 | 0.812/0.343 | 0.875/0.217 | 0.883/0.225 |
| no-bluk | 5.32 | 5.26 | 5.77 | 5.81 | |
| realloc | 2.15 | 2.09 | 2.774 | 2.769 | |
| 4096 | bulk | 1.099/0.486 | 0.771/0.474 | 0.90/0.324 | 0.762/0.362 |
| no-bluk | 5.62 | 5.329 | 5.65 | 5.394 | |
| realloc | 2.89 | 2.59 | 3.36 | 2.81 | |
| 8192 | bulk | 0.967/0.563 | 1.011/0.589 | 0.886/0.516 | 0.883/0.476 |
| no-bluk | 5.37 | 5.37 | 5.43 | 5.43 | |
| realloc | 4.68 | 4.65 | 4.87 | 4.75 | |
| 16384 | bulk | 1.33/0.87 | 1.21/0.881 | 1.379/0.938 | 1.33/0.95 |
| no-bluk | 5.49 | 5.465 | 5.57 | 5.525 | |
| realloc | 9.59 | 9.528 | 9.76 | 9.705 | |
| 32768 | bulk | 2.22/2.01 | 2.276/2.06 | 2.41/2.06 | 2.44/2.068 |
| no-bluk | 5.65 | 5.646 | 5.72 | 5.71us | |
| realloc | 20.5 | 20.49 | 20.8 | 20.74 | |
| 131072 | bulk | 10.432/10.526 | 10.397/10.531 | 10.68/10.79 | 10.676/10.818 |
| no-bluk | 9.87 | 9.866 | 9.9 | 9.9 | |
| realloc | 82.0 | 82.15 | 82.8 | 82.56 | |
| 524288 | bulk | 42.8/42.59 | 43.058/42.689 | 43.6/43.2 | 43.609/43.357 |
| no-bluk | 23.72 | 23.74 | 23.8 | 23.8us | |
| realloc | 406 | 406 | 407 | 408.75 | |
| 1048576 | bulk | 125.2/125.7 | 124.9/125 | 88.2/86.8 | 87.3/86.9 |
| no-bluk | 42.38 | 42.25 | 42.46 | 42.46 | |
| realloc | 869 | 873 | 890 | 888 |
多线程
bulk:连续分配 1000 个对象,memset 后,1000 个对象一起释放,统计单次平均分配/释放耗时
no-bulk:分配 1 个对象,memset, delay 5us, 释放,重复 1 万次,统计平均分配和释放的总耗时
realloc:分配 1 个对象,memset, realloc 成原本 2 倍大小,memset, realloc 成原本 4 倍大小,memset,释放,重复 1000 次,统计平均总耗时
| 单次分配大小 | 测试项 | 修改前align=64 | 修改后align=64 | 修改前align=4096 | 修改后align=4096 |
|---|---|---|---|---|---|
| 64 | bulk | 15.0/6.5 | 15.1/6.5 | / | / |
| no-bluk | 22.6 | 22.6 | / | / | |
| realloc | 73.5 | 73.8 | / | / | |
| 128 | bulk | 17.4/6.7 | 17.2/6.7 | / | / |
| no-bluk | 23.5 | 23.5 | / | / | |
| realloc | 73.9 | 73.3 | / | / | |
| 512 | bulk | 16.8/6.2 | 16.4/6.2 | / | / |
| no-bluk | 22.3 | 22.4 | / | / | |
| realloc | 82.1 | 79.5 | / | / | |
| 1024 | bulk | 18.5/6.8 | 15.9/6.7 | / | / |
| no-bluk | 25.1 | 24.0 | / | / | |
| realloc | 92.1 | 84.7 | / | / | |
| 3072 | bulk | 18.2/7.8 | 18.2/7.9 | 29.1/6.7 | 29.3/6.5 |
| no-bluk | 23.9 | 25 | 36.8 | 36.3 | |
| realloc | 91.8 | 91.3 | 117.7 | 116.2 | |
| 4096 | bulk | 21.3/8.5 | 16.7/8.4 | 30.3/14.2 | 23.0/7.5 |
| no-bluk | 28.9 | 24.6 | 39.2 | 30.0 | |
| realloc | 101.8 | 95.1 | 125.6 | 108 | |
| 8192 | bulk | 18.4/12.0 | 18.4/12 | 25.0/9.8 | 24.1/11.5 |
| no-bluk | 26.0 | 25.9 | 31.2 | 30.9 | |
| realloc | 110.7 | 108.4 | 122.8 | 121 | |
| 16384 | bulk | 22.9/19.4 | 19.4/19.0 | 28.5/16.5 | 27.2/15.6 |
| no-bluk | 27.8 | 26.5 | 33.5 | 31.5 | |
| realloc | 125.6 | 122.5 | 140.9 | 136.2 | |
| 32768 | bulk | 27.4/33.2 | 27.4/33.2 | 32.8/30.3 | 34.1/27.5 |
| no-bluk | 28.9 | 28.8 | 34 | 34 | |
| realloc | 171 | 168.2 | 184.5 | 180.8 | |
| 131072 | bulk | 44.8/170 | 44.6/171 | 44.7/169.4 | 44.6/167 |
| no-bluk | 58.5 | 58.1 | 63.2 | 62.9 | |
| realloc | 463.6 | 458.3 | 472.7 | 470 | |
| 524288 | bulk | 160/655 | 160/660 | 160.8/653.7 | 160.1/652.5 |
| no-bluk | 162.8 | 163 | 168.8 | 168.7 | |
| realloc | 1812 | 1826 | 1824 | 1820 |
16 个线程,每个线程单独绑核后做如下测试:
连续分配 N 个 4K 大小对象,4K 对齐,每次分配之间 delay 5us, 统计耗时,然后连续释放 N 个 4K 对象,不delay,统计单次耗时
| 单线程分配次数 | 优化前 | 优化后 |
|---|---|---|
| 64 | 109us | 16us |
| 128 | 214us | 17.8us |
| 256 | 408us | 17.5us |
| 512 | 962us | 18.2us |
| 1024 | 3.1ms | 15.3us |
| 2048 | 8.6ms | 17.6us |
| 4096 | 20.5ms | 17.4us |
DPDK malloc perf test
malloc 测试,修改前:
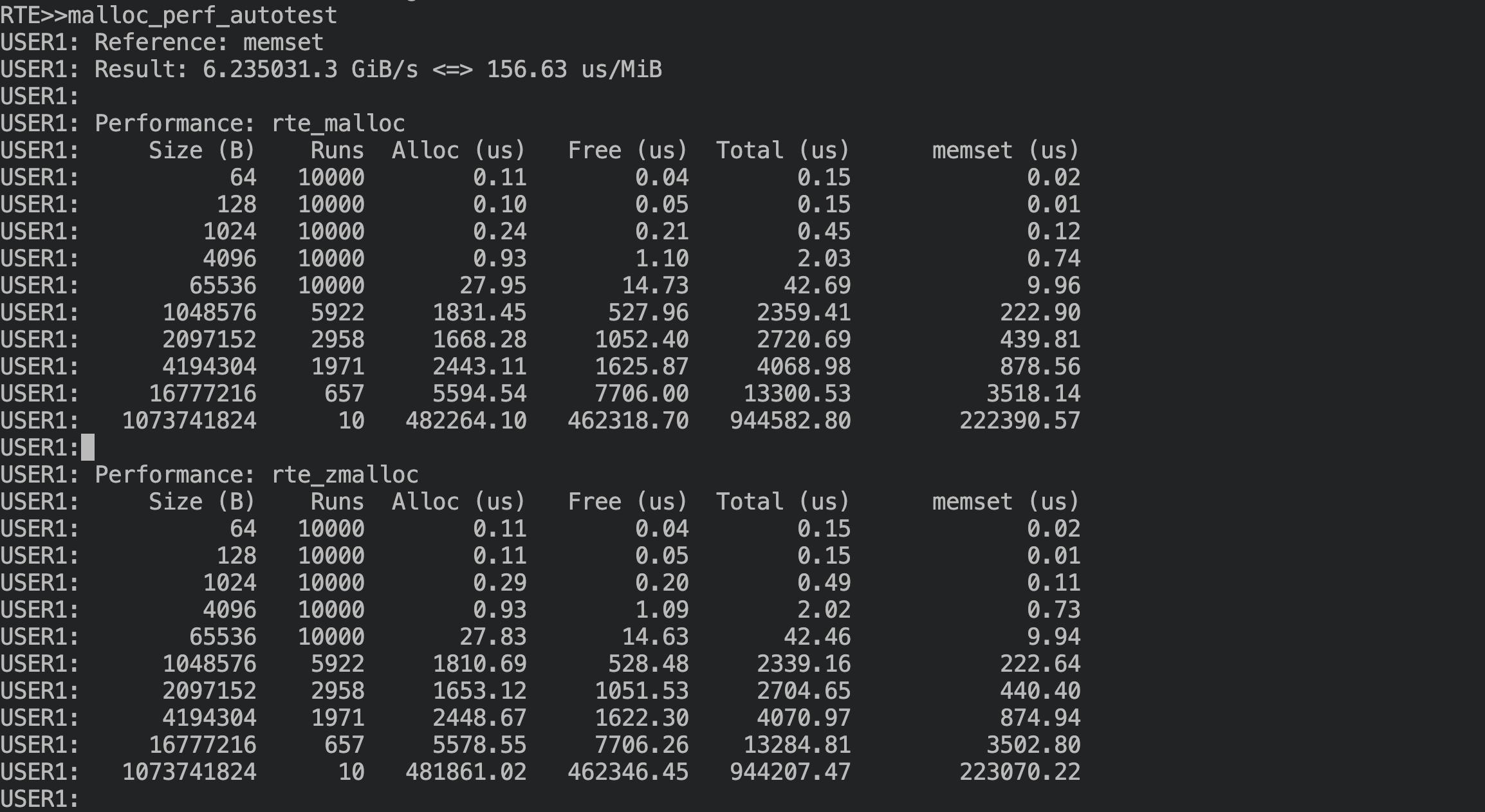
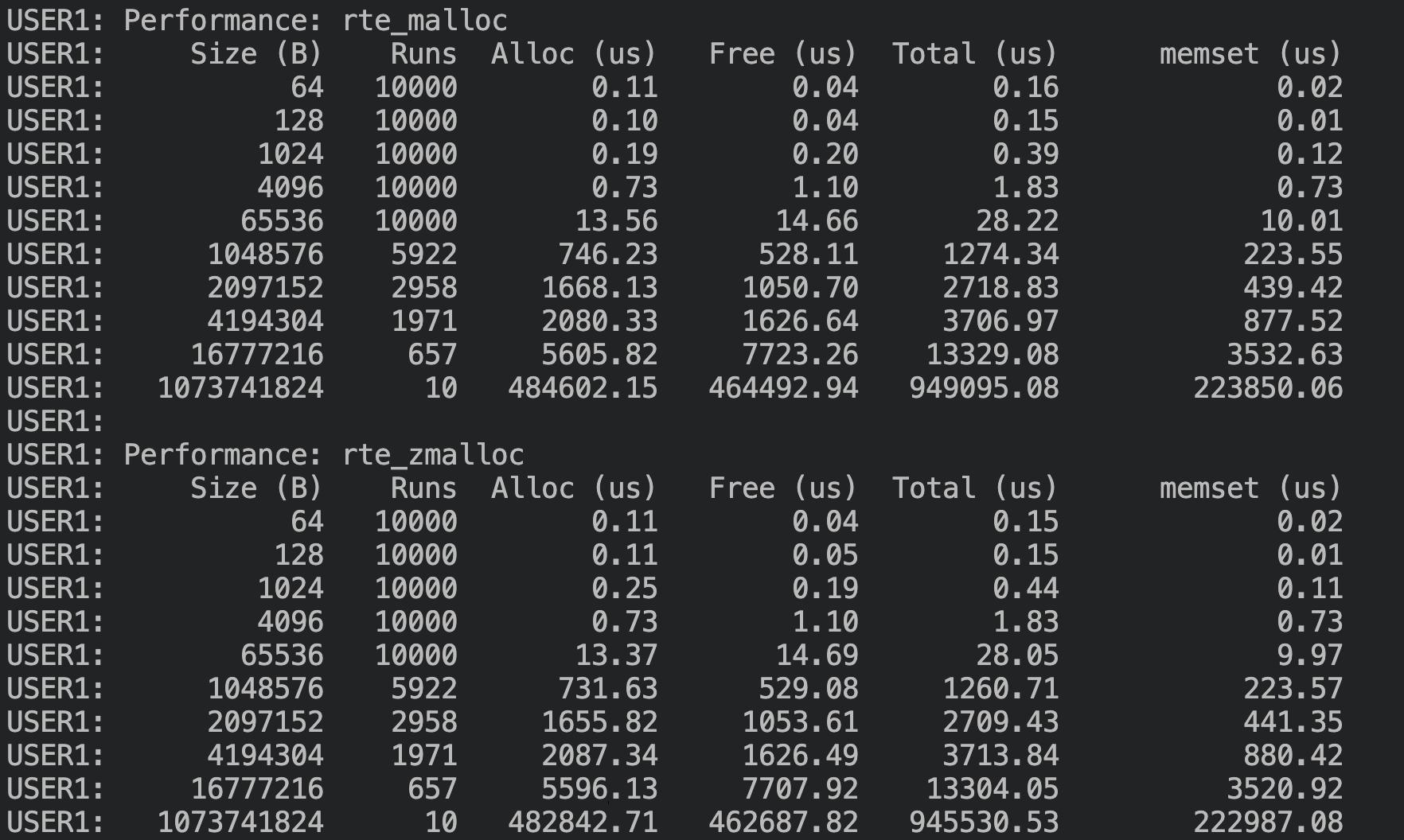
malloc 测试,修改后,可以看到没有性能衰退,4K/64K/1M 等大小分配有 15%-50% 的性能提升:
memzone 测试,修改前:
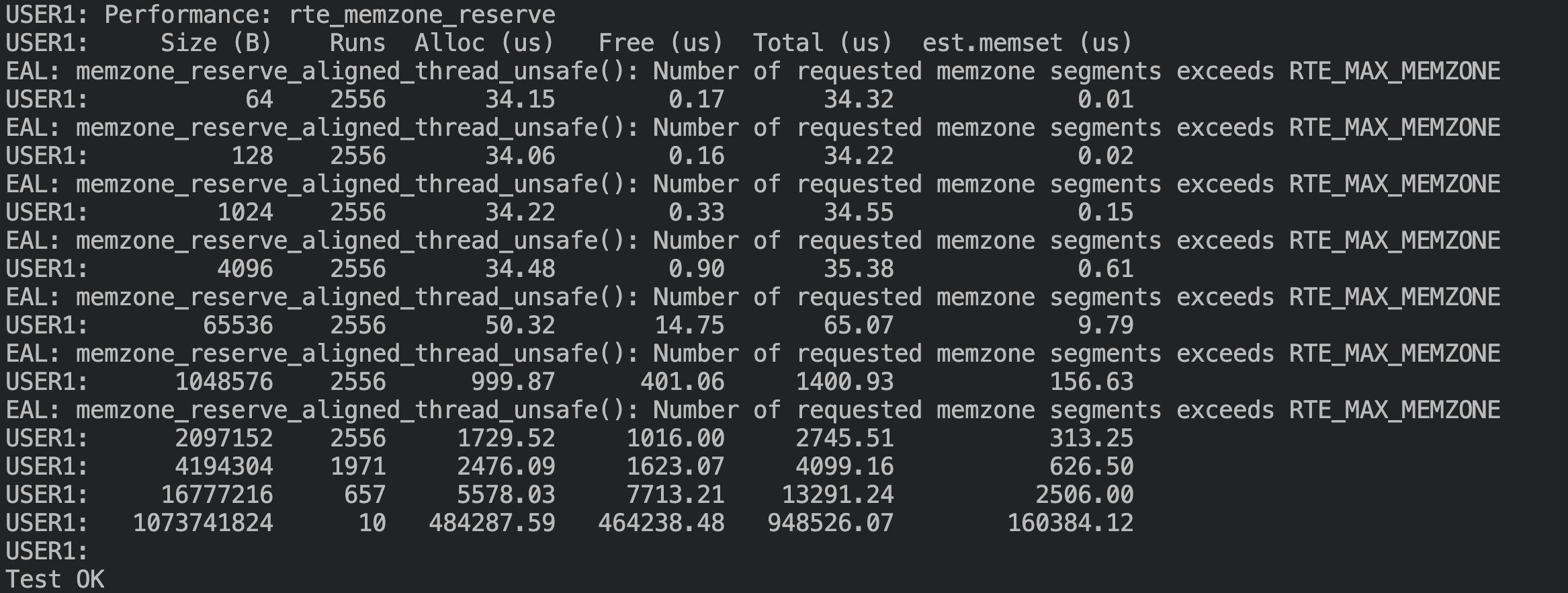
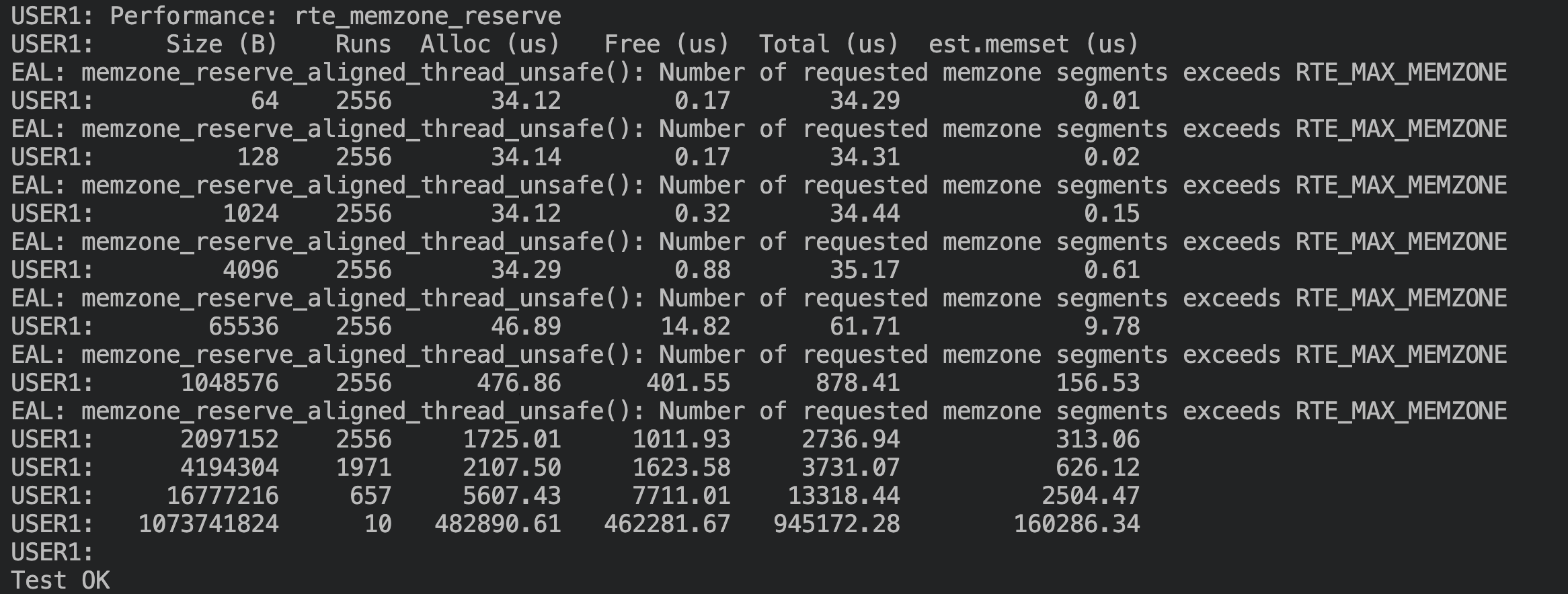
memzone测试,修改后没有性能衰退,64K/1M 大小的分配分别有 7% 和 52% 的性能提升:
总结
通过以上分析,确定了 DPDK 内存碎片化的诱因是在分配时要求对齐的大小比较大,导致 elem 切分时产生了很多碎片,并影响了后续内存分配的效率。经过完整的测试,最终选用了方案二,改动简单,效果也更好,不仅解决碎片场景下的问题,使得性能提升 30+ 倍,也在非碎片情况下,使得 4K/64K/1M 等大小的内存分配性能提升 15-50% ,同时也能缓解多进程并发分配时竞争锁的压力。目前字节跳动 STE 团队已将该补丁提交至 DPDK 社区,并于 2023 年 2 月 合入 DPDK 主线,链接如下:https://inbox.dpdk.org/dev/CAJFAV8x5k55jH0A_BHN9jxA1m-3o08tKr7RbCesvVL7o4MKgGQ@mail.gmail.com/
DPDK/SPDK 作为开源项目,凭借其出色的性能表现赢得了众多开发者的青睐,我们也希望在使用开源项目获得收益的同时,能为项目与社区带来更多想法,做出更多贡献,与开发者们一起推进社区的建设。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
