
一、让自己习惯C++
条款01、视C++为一个语言联邦
条款02、尽量以const,enum,inline,替换 # define
用编译器替换预处理器
什么是预处理
在C++中,预处理是指在编译过程之前的一个阶段,通过预处理器(preprocessor)对源代码进行处理的过程。预处理器会根据预处理指令(以井号#开头)对源代码进行文本替换、宏展开等操作,生成一个经过预处理的源文件。
以下是常用的预处理指令及其作用:
-
#define:用于定义宏常量或宏函数。#define指令会将所有出现在源代码中的宏名称都替换为指定的文本。 -
#include:用于包含头文件内容。#include指令会将指定的头文件内容插入到该指令所在位置。 -
等等
a、普通常量
宏 预处理指令定义常量,如:
# define ASPECCT_RATIO 1.653尽量用以下来代替:
const 常量
const double AspectRaio = 1.653;另外 定义一个常量的 char*-based字符创,必须写const两次
const char* const authorName = "Acott Meyers"其实string对象通常比char*-based合宜
const std::string authorName("Scott Meyers")b、class专属常量
解释:
1.常量的作用域限制在class内,必须让他成为 class 的一个成员
2.确保此常量至多只有一份实体,必须让它成为一个 static 成员:
class Game{
private:
static const int NumTurns= 5;
int scores[NumTurns];
};常量变量默认是不允许在类中直接初始化的。但是静态成员变量可以在类内进行初始化,所以是 static const int
也可以使用enum来实现
class Game{
private:
enum {NumTurns = 5};
int scores[NumTurns];
};c、看起来像函数的宏
//以 a 和 b 的较大值调用f
#define CALL_WITH_MAX(a, b) f((a) > (b)) ? (a) : (b)使用template inline 函数在编译阶段处理函数调用点的,减少函数调用的开销,也能获得宏的的效率
template
inline T callWithMax(const T& a, const T& b){
return (a,b) ? a: b;
}条款03、尽可能使用const
const与指针
如果关键字 const 出现在星号左边,表示被指物是常量,作函数参数时,不能在函数中改变
#include
void add(const int* a, const int* b){
*a+=1; // 错误!
int c = *a + *b;
std::cout 如果关键字 const 出现在星号右边,表示指针自身是常量
#include
int main(){
// 被指物为常量
char* const p = "hello";
// p = "jason"; // 此时指针p不可以被修改,
std::cout 如果关键字 const 出现在星号两边,表示被指物和指针两者都是常量
#include
int main(){
char words[] = "hello";
const char* const p = words;
std::cout const与迭代器
#include
#include
int main(){
std::vector vec{1,2,3,4,5};
std::vector::const_iterator iter =
vec.begin(); // const 出现在迭代器右边
*iter += 10; // 不能通过迭代器修改被指内容
// ++iter;
}
const与函数
const成员函数
#include
class TextBlock{
private:
std::string text;
public:
TextBlock(const std::string & str):text(str){}
const char& operator[] (std::size_t position) const{
return text[position];
}
char& operator [] (std::size_t position){
return text[position];
}
};
int main(){
TextBlock tb("Hello");
std::cout 这里例子是太过造作。
真实程序中 const 对象大多用于 passes by pointer-to-const 或 passes by reference-to-const
应用在函数参数中
void print(const TextBlock& ctb){
std::cout 应用在成员函数
include
class Myclass{
private:
bool lengthIsValid;
mutable int num;
public:
void test() const{
lengthIsValid = 0; // 错误!在const成员函数内不能赋值给lengthIsValid
num=10; // 正确,mutable关键字修饰的变量可以被修改
}
};
int main(){
Myclass myclass;
}
条款04、确定对象被使用前已先被初始化
为避免在对象初始化之前过早地使用它们,需要做三件事:
- 为内置型对象进行手工初始化,因为C++不保证初始化
- 构造函数最好使用成员初值列,而不要在构造函数体内使用赋值操作。初值列列出的成员变量,其排列次序应该和他们在class中的声明次序相同。另外,C++17支持在类中直接对私有变量进行初始化而不通过构造函数
- 为免除“跨编译单元之初始化次序问题”,用 local static 对象替换 non-local static 对象
前两点很好理解,这里对第三点给出例子解释:
class FileSystem{
public:
std::size_t numDisks(){}
};
FileSystem& tfs(){
static FileSystem fs;
return fs;
}
class Directory{};
Directory::Directory(){
std::size_t disks = tfs.numDisks();
}
Directory& tempDir(){
static Directory td;
return td;
}二、构造/析构/赋值运算
条款05、了解C++默默编写并调用哪些函数
如果你声明的一个空类,如:
class Empty{};那么编译器会为它声明一个copy构造函数、一个copy assignment操作符和一个析构函数。如果你没有声明任何构造函数,编译器会你声明一个default构造函数。所有这些函数都是public且inline的。所以上面你声明的空类会被编译器处理为:
class Empty{
public:
Empty(){} // default构造函数
Empty(const Empty& rhs){} // copy构造函数
~Empty(){} // 析构函数
Empty& operator=(const Empty& rhs){} // copy assignment操作符
};
调用copy构造函数的例子
#include
template
class NameObject{
public:
NameObject(const char* name, const T& value);
NameObject(const std::string& name, const T& value);
private:
std::string nameValue;
T objecctValue;
};
int main(){
NameObject no服务器托管网1("Smallest Primer Number", 2);
NameObject no2(no1); // 调用copy构造函数
}一个错误的例子:
C++不允许“让 reference 改值向不同对象”
更改const成员是不合法的
基于以上两点,如下例子不正确:
#include
template
class NameObject{
public:
NameObject(const std::string& name, const T& value);
private:
std::string& nameValue; // C++不允许“让 reference 改值向不同对象”
const T objecctValue; //更改const成员是不合法的
};
int main(){
std::string newDog("Persephone");
std::string oldDog("Satch");
NameObject p(newDog, 2);
NameObject s(oldDog, 36);
p = s;// 错误;C++不允许 让reference
}
条款06、若不想使用编译器自动生成的函数,就该明确拒绝
如果不希望 copy 构造函数 以及 copy assignment 操作符起作用,则应该声明为 private 并没有定义
#include
class HomeForSale{
public:
private:
HomeForSale(const HomeForSale&);
HomeForSale& operator =(const HomeForSale&);
};
int main(){
HomeForSale home;
home h1;
home h2(h1);
}如此一来,就可以阻止编译器暗自创建他们。而拷贝HomeForSale对象的时候,编译器会阻止:

将连接期报错移动到编译期
class Uncopyable{
protected:
Uncopyable(){} // 允许对象构造和析构
~Uncopyable(){}
private:
Uncopyable(const Uncopyable&); // 但阻止copying
Uncopyable& operator =(const Uncopyable&);
};
// class HomeForSale 不再声明 copy 构造函数 或 copy assign. 操作符
class HomeForSale : private Uncopyable{};
int main(){
HomeForSale home1;
HomeForSale home2(home1);
}
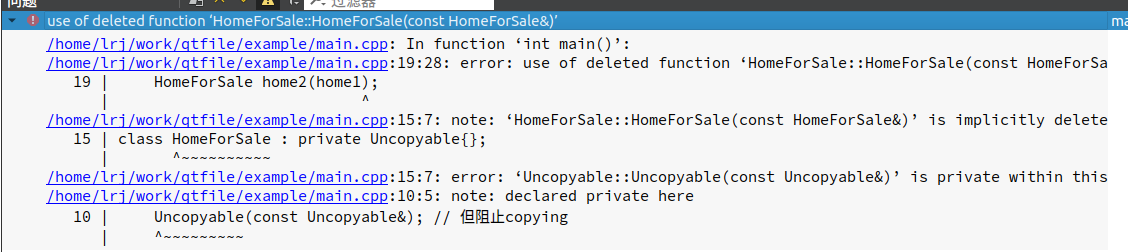
总结:
为驳回编译器自动(暗自)提供的技能,可将相应的成员函数声明为private并且不予实现。使用 像 Uncopyable 这样的 base class 也是一种做法。
条款07、为多态基类声明 virtual 析构函数
C++11不存在 “ non-virtual 析构函数问题”,此条款略过
条款08、别让异常逃出析构函数
不要让异常逃离析构函数是指在析构函数中抛出异常时,不要让该异常传播到析构函数的调用点以外。这是因为对象的析构过程通常是在对象生命周期的最后阶段发生的,此时其他对象和资源已经被清理或释放。如果析构函数抛出异常并且该异常逃离了析构函数,将会导致以下问题:
-
对象的析构不完全:如果析构函数抛出异常,对象的析构可能无法完成,导致对象状态没有得到完全清理或释放。这可能会导致资源泄漏或其他未定义行为。
-
内存泄漏:如果在抛出异常之前执行了动态内存分配,并且在抛出异常后没有适当地释放该内存块,将会导致内存泄漏。
-
无法回滚操作:如果在对象构造期间进行了一些操作,并且在析构函数中发生异常,无法回滚这些操作。这可能会导致数据不一致或逻辑错误。
为了避免异常从析构函数中逃离,可以采取以下措施:
-
在析构函数中捕获异常并处理:可以在析构函数中使用
try-catch块来捕获异常,并在适当的情况下进行处理。例如,记录异常信息或执行必要的清理操作。
析构函数抛出异常就结束程序。通常通过调用 abort 完成:
#include
class DBConnection{
public:
static DBConnection create(){
static DBConnection db;
return db;
}
void close(){
int num=0;
throw num; // 假装抛出异常
}
};
//该类用于管理 DBConnection 资源,在其析构函数调用 DBConnection 的close,用以关闭数据库
class DBConn
{
private:
DBConnection db;
public:
~DBConn() {
try{db.close();}
// 省略代码:制作运转记录,记下对close的调用失败
catch (int)
{
// 这里最好打印信息,因为QT IDE只会给你报崩溃的信息
std::abort();
}
}
DBConn(DBConnection d):db(d){}
};
int main()
{
// 现在就可以这样写代码。
// dbc 对象销毁时候,会调用其析构函数,....自动关闭 DBConnection 的数据库
DBConn dbc(DBConnection::create());
}
本例的假设情况:
如果程序遭遇一个“于析构函数期间发生的错误”后无法继续执行,“强迫结束程序”是个合理选项。毕竟它可以阻止异常从析构函数传播出去(那会导致不明确的行为)。也就是说调用 abort 可以抢险置“不明确行为”于死地。
吞下因调用而发生的异常:
修改上例代码中的DBConn类的析构函数如下:
~DBConn() {
try{db.close();}
// 省略代码:制作运转记录,记下对close的调用失败
catch (int){}
}这里析构函数将异常吞掉了,一般而言,这是和坏主意,因为压制了“某些动作失败”的重要信息!然而有时候吞下异常也比负担“草率结束程序”或“不明确行为带来的风险”好。为了让这成为一个可行方案,程序必须能够继续可靠地执行,及时在遭遇并忽略一个错误之后。
上面两种方法没有无法对“导致 close 抛出异常”的情况做出反应,另外一个思路是重新设计 DBonn接口,使其客户有机会对可能和出现的问题作出反应。例如 DBConn 自己可以提供一个close函数,给客户一个机会得以处理“因该操作而发生的异常”:
#include
class DBConnection{
public:
static DBConnection create(){
static DBConnection db;
return db;
}
void close(){
int num=0;
throw num; // 假装抛出异常
}
};
//该类用于管理 DBConnection 资源,在其析构函数调用 DBConnection 的close,用以关闭数据库
class DBConn
{
private:
DBConnection db;
bool closed=false;
public:
void close(){ // 供客户使用的新函数
db.close();
closed = true;
}
~DBConn() {
if(!closed){ // 关闭连接(如果客户不那么做的话)
try{db.close();}
catch(int) {
// 如果关闭动作失败,
// 记录下来并结束程序或吞掉异常
};
}
}
DBConn(DBConnection d):db(d){}
};
int main()
{
// 现在就可以这样写代码。
// dbc 对象销毁时候,会调用其析构函数,....自动关闭 DBConnection 的数据库
DBConn dbc(DBConnection::create());
}总结:
- 析构函数绝对不要吐出异常。如果一个被析构函数调用的函数可能抛出异常,析构函数应该捕捉任何异常,然后吞下它们(不传播)或结束程序。
- 如果客户需要对某个操作函数运行期间抛出的异常作出反应,那么 class 应该提供一个普通函数(而非在析构函数中)执行操作
条款09、绝不在构造和析构函数中调用 virtual 函数
如标题
条款10、令 operator= 返回一个 reference to *this
#include
class Widget{
public:
Widget& operator =(const Widget& rhs){
// 将右侧对象的值赋给左侧对象的成员变量
if (this != &rhs){
value = rhs.value;
}
// 返回左侧对象
return* this;
}
Widget(int num):value(num){}
Widget(){};
void getValue(){
std::cout 本例子以operator=操作符为例, +=, -=, *=也适用
条款11、在 operator= 中处理 “自我赋值”
条款12、复制对象时勿忘其每一个成分
三、资源管理
条款13、以对象管理资源
中心:资源取得时机便是初始化时机
一般情况下:
#include
class Investment{};
Investment * creatInvestment(){
Investment* i = new Investment;
return i;
}
void f()
{
Investment* pInv = creatInvestment();
// 中间代码省略
delete pInv; // 必须释放pInv所指向对象,否则导致内存泄露
}
int main(){
f();
}但是有时候由于中间代码出现问题,delete pInv 语句会无法得到执行,这样便导致内存泄露!
下面这个例子示范“以对象管理资源”的两个关键想法:
获得资源后立即放进管理对象内
creatInvestment() 返回的资源被当作其管理 unique_ptr的初值
管理对象运行析构函数确保资源被释放
#include
#include
class Investment{};
Investment * creatInvestment(){
Investment* i = new Investment;
return i;
}
void f()
{
// 获得资源后立即放进管理对象内
std::unique_ptr pInv(creatInvestment());
// 中间代码省略
// delete pInv; // 管理对象运行析构函数确保资源被释放,不需要手动释放内存
}
int main(){
f();
}
不过,unique_ptr是 C++11 引入的智能指针模板,用于管理动态分配的内存资源。它提供了一个独占所有权的智能指针,确保只有一个指针可以访问动态分配的内存块,从而避免内存泄漏和悬挂指针(dangling pointer)的风险。这样做就不行:
#include
#include
class Investment{};
Investment * creatInvestment(){
Investment* i = new Investment;
return i;
}
void f()
{
// 获得资源后立即放进管理对象内
Investment* ptr = creatInvestment();
//不能把同一块内存由两个unique_ptr管理者同时管理
std::unique_ptr pInv1(ptr);
std::unique_ptr pInv2(pInv1); // 不允许
// 中间代码省略
// delete pInv; // 管理对象运行析构函数确保资源被释放,不需要手动释放内存
}
int main(){
f();
}

而STL容器要求其元素发挥 “正常的” 复制行为,因此容不得unique_ptr。
但是shared_ptr就不一样了:
#include
#include
class Investment{};
Investment * creatInvestment(){
Investment* i = new Investment;
return i;
}
void f()
{
// 获得资源后立即放进管理对象内
Investment* ptr = creatInvestment();
//同一块内存可以由两个shared_ptr管理者同时管理
std::shared_ptr pInv1(ptr);
std::shared_ptr pInv2(pInv1);
pInv2 = pInv1; // 同上,无任何变化
// 中间代码省略
// delete pInv; // 管理对象运行析构函数确保资源被释放,不需要手动释放内存
}
int main(){
f();
}
条款14、在资源管理类中小心 copying 行为
对于 heap-based 资源,可以用unique_ptr以及shared_ptr进行管理。但是别的资源就需要建立自己的资源管理类。
下述例子实现了对 mutex* 的管理,并禁止复制,相当于unique_str:
#include
#include
using namespace std;
void lock(mutex* pm){};
void unlock(mutex* pm){};
class Lock{
private:
mutex* mutexPtr;
public:
explicit Lock(mutex* pm):mutexPtr(pm)
{
lock(mutexPtr); // 构造函数获取资源
}
~Lock()
{
unlock(mutexPtr); // 析构函数释放资源
}
private:
// 不希望 copy 构造函数 以及 copy assignment 操作符起作用
Lock(const Lock&);
Lock& operator =(const Lock&);
};
int main(){
mutex m;
Lock m1(&m);
Lock m2(m1); // 禁止复制,条款6
}使用shared_ptr
#include
#include
#include
using namespace std;
void lock(mutex* pm){};
void unlock(mutex* pm){};
class Lock{
private:
std::shared_ptr mutexPtr;
public:
// 以某个 mutex 初始化 shared_ptr,
// 第二参数是unlock
// 当shared_ptr 被销毁时会调用unlock
explicit Lock(mutex* pm):mutexPtr(pm, unlock)
{
lock(mutexPtr.get()); // 构造函数获取资源
}
// 不再声明析构函数
// 条款5-》class析构函数会自动调用其non-static成员变量的析构函数
};
int main(){
mutex m;
Lock m1(&m);
Lock m2(m1);
}条款15、在资源管理类中提供对原始资源的访问
来看一个例子,就理解标题的意思:
#include
#include
using namespace std;
class Investment{};
Investment * creatInvestment(){
Investment* i = new Investment;
return i;
}
int daysHeld(const Investment* pi){
return 10;
}
int main(int argc, char *argv[])
{
std::shared_ptr pInv(creatInvestment());
// 错误,函数需要的是Investment*指针!
// 传过来的却是类型为 std::shared_ptr对象
int days = daysHeld(pInv);
return 0;
}
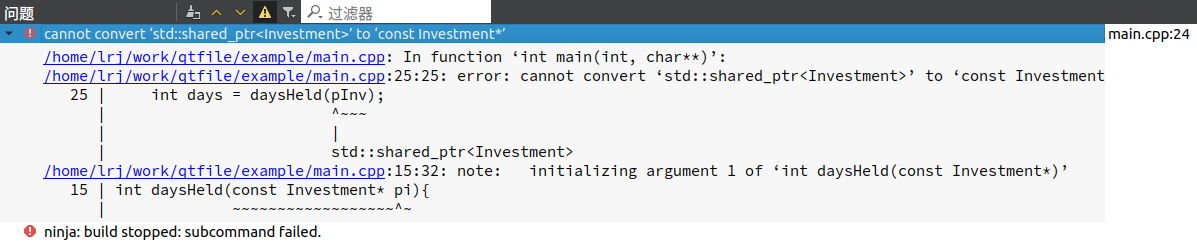
那么如何获得原始指针:
方法一:使用shared_ptr的get成员函数,用来执行显式转换,也就是他会返回智能指针内部的原始指针(的复件):
int main(int argc, char *argv[])
{
std::shared_ptr pInv(creatInvestment());
//使用shared_ptr的get成员函数,获取智能指针内部的原始指针
int days = daysHeld(pInv.get());
return 0;
}
方法二:就像(几乎)所有智能指针一样,shared_ptr也重载了指针取值(pointer deference)操作符(operator->和operator*),他们允许隐式转换至底部原始指针:
#include
#include
using namespace std;
class Investment{
//
public:
bool isTaxFree() const{
return true;
}
};
Investment * creatInvestment(){
Investment* i = new Investment;
return i;
}
int main(int argc, char *argv[])
{
// shared_ptr管理一笔资源
std::shared_ptr pi1(creatInvestment());
// 经由 operator->f访问资源
bool taxable1 = !(pi1->isTaxFree());
// unique_ptr 管理一批资源
std::unique_ptr pi2(creatInvestment());
// 经由 operator*访问资源
bool taxable2 = !((*pi2).isTaxFree());
return 0;
}条款16、成对使用 new 和 delete 时要采取相同形式
必须一一对应:
#include
#include
using namespace std;
int main(int argc, char *argv[])
{
std::string* stringPtr1 = new std::string;
std::string* stringPtr2 = new std::string[100];
delete stringPtr1; // 删除一个对象
delete [ ] stringPtr2; // 删除一个由对象组成的数组
return 0;
}如果你喜欢用typedef:
#include
#include
using namespace std;
int main(int argc, char *argv[])
{
typedef std::string AddressLines[4]; // 每个人地址有4行
// 每行是一个string
// 注意,“new AddressLines” 返回一个string*,就像
// “new string[4]”一样
std::string* pa1 = new AddressLines;
// 那必须匹配“数组形式”的delete
// delete pa1;//行为未有定义
delete [] pa1;
return 0;
}条款17、以独立语句将 newed 对象置入智能指针
从int prioryty(){}阅读下述例子,即可理解标题:
#include
#include
class Widget{
public:
Widget& operator =(const Widget& rhs){
// 将右侧对象的值赋给左侧对象的成员变量
if (this != &rhs){
value = rhs.value;
}
// 返回左侧对象
return* this;
}
Widget(int num):value(num){}
Widget(){};
void getValue(){
std::cout pw, int priority){}
int main(int argc, char *argv[])
{
// shared_ptr构造函数需要一个原始指针(raw pointer)
// 但该构造函数是个explicit构造函数,无法进行隐式转换,
// 将自“new Widget”的原始指针转换为processWidget所要求的
// shared_ptr,所以下面这样写不能通过编译
// processWidget(new Widget, priority());
// 这样写才能通过编译,干了三件事:如果是这个顺序
// 执行 “new Widget”、调用priority、调用new Widget构造函数
// 调用priority失败会“new Widget”返回的指针遗失,引发资源泄露
processWidget(std::shared_ptr (new Widget), priority());
// 所以最好是使用分离语句
std::shared_ptr pw(new Widget); // 在单独语句内以智能指针
//存储new Widget所得对象
processWidget(pw,priority()); // 这个调用动作绝不至于造成泄露
return 0;
}
分离语句即可说明:
以独立语句将 newed 对象存储于(置于)指针内。如果不这样做,一旦异常被抛出,有可能导致难以察觉的资源泄露
四、设计与声明
条款18、让接口容易被正确使用,不易被误用
很可能传一个错误的参数:
#include
class Date{
public:
Date(int month, int day, int year){};
};
int main(int argc, char *argv[])
{
Date d(30, 3, 1995); // 月份不可能大于12!!
return 0;
}-
std::shared_ptr在构造函数中提供了一个可选的删除器(deleter)参数,用于自定义资源的释放方式。删除器是一个函数或者可调用对象,用于在shared_ptr的引用计数器变为0时释放资源。删除器可以是普通函数、函数指针、lambda 表达式等,只要符合指定的删除器的函数签名即可。删除器接受一个指向资源的指针(被
shared_ptr管理的指针)作为参数,不返回任何值。下面是一个示例,展示了如何给
shared_ptr提供自定义的删除器:#include #include struct MyStruct { void operator()(int* p) { std::cout ptr(new int(42), MyStruct()); // 使用默认删除器释放资源 std::shared_ptr ptr2(new int(100)); return 0; }在上面的示例中,
MyStruct是一个删除器类,它重载了operator(),在函数体中使用 delete 运算符释放资源。在创建std::shared_ptr时,通过提供MyStruct的实例作为构造函数的第二个参数,我们指定了自定义删除器。需要注意的是,使用删除器时,它必须与被管理指针的类型兼容,否则会导致未定义的行为。此外,当存在多个
shared_ptr共享同一个对象时,它们必须使用相同类型的删除器。自定义删除器为我们提供了更大的灵活性,能够管理不同类型的资源释放方式,例如,在资源释放时执行一些额外的操作。
条款19、设计 class 犹如设计 type
条款20、宁以 pass-by-reference-to-const 替换 pass-by-value
首先来看下 pass-by-reference-to-const 的传递成本:
#include
class Person{
public:
Person(){}
virtual ~Person(){}
private:
std::string name;
std::string address;
};
class Student: public Person{
private:
std::string schoolName;
std::string schoolAddress;
public:
Student(){}
~Student(){}
};
bool validateStudent(Student s){
// 省略对Student对象的检查
return 1;
}
int main(int argc, char *argv[])
{
Student plato;
bool platoIsOK = validateStudent(plato);
return 0;
}这里例子中,无疑地Student的 copy 函数会被调用,以 plato 为蓝本将 s 初始化。同样明显地,当 validayeStudent 返回后, s 会被销毁。因此,对此函数而言,参数的传递成本是 “一次 Student copy 构造函数调用,加上一次 Student 析构函数调用”。
而使用 pass by reference-to-const 可以回避上述那些构造和析构动作:
bool validateStudent(const Student& s)const的作用:validateStudent 不能修改传入的Student
除了效率之外,两种传递方式还有别的区别,来看看这里例子:
#include
class Window{
public:
std::string name() const{
return "windown";
}
virtual void display() const{
std::cout printNameAndDisplay函数的本意是,调用传入对象的display成员函数。也就是说,如果传入的是Window对象,就调用其display成员函数;如果传入的是WindowWithScrollBars对象,就其display成员函数。
但是参数传递方式选择为 pass-by-value时候,即使传入的是WindowWithScrollBars对象,也是调用基类Window的display成员函数。下图是上例子的执行结果

而将printNameAndDisplay函数参数传递方式修改为pass-by-reference-to-const时,就能实现该函数设计的本意:
void printNameAndDisplay(const Window& w){
std::cout 
但是对于内置类型,以及 STL 的迭代器和函数对象而言,比如 int,尽量选择 pass-by-value
条款21、必须返回对象时,别妄想返回其 reference
返回对象时,返回其 reference,可行?
#include
class Rational{
public:
Rational(int numerator = 0, int denominator = 1)
:n(numerator),d(denominator){}
private:
int n, d;
friend const Rational&
operator*(const Rational& lhs, const Rational& rhs);
};
const Rational& operator*(const Rational& lhs,
const Rational& rhs){
// local 变量,是在 stack 空间创建的
// 是不能作为返回值的
Rational result(lhs.n * rhs.n, lhs.d *rhs.d);
return result;
}
int main(int argc, char *argv[])
{
Rational a(1,2);
Rational b(3,5);
Rational c = a * b;
return 0;
}


考虑在 heap 内构造一个对象,看能返回 referene,还是行不通:
const Rational& operator*(const Rational& lhs,
const Rational& rhs){
// 考虑在 heap 内构造一个对象
Rational* result= new Rational(lhs.n * rhs.n, lhs.d *rhs.d);
return result;
}
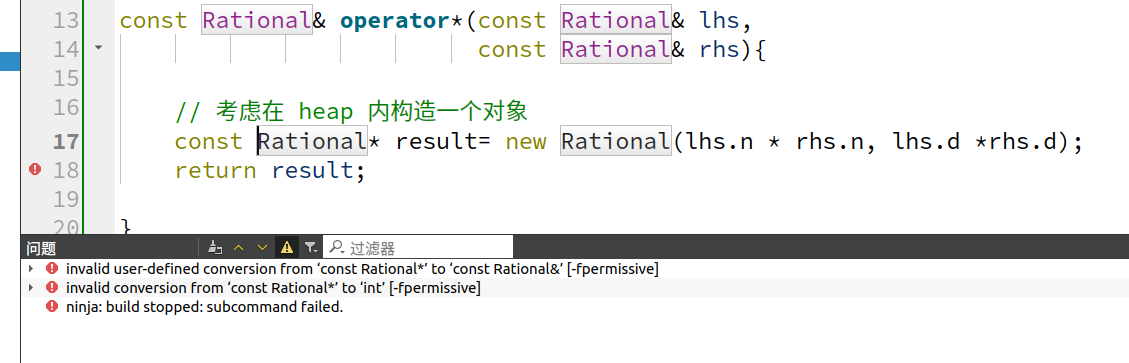
考虑使用 static 关键字:
const Rational& operator*(const Rational& lhs,
const Rational& rhs){
// 定义一个在函数内部的 static Rational 对象
static Rational result = Rational(lhs.n * rhs.n, lhs.d *rhs.d);
return result;
}这次代码可用通过编译
但是在书中这种写法也会在延伸点上出现问题。所以一个“必须返回新对象”的函数的正确写法是:就让那个函数返回一个新对象:
const Rational operator*(const Rational& lhs,
const Rational& rhs){
// local 对象可以直接被返回,而不是返回其reference
Rational result = Rational(lhs.n * rhs.n, lhs.d *rhs.d);
return result;
}
总结:
绝不要返回 pointer 或 reference 指向一个 local stack 对象,或返回 reference 指向一个 heap-allocated对象,或返回 pointer 或 reference 指向一个local static 对象而有多个可能同时需要多和这样的对象。条款4已经为 “在单线程环境中合理返回 reference 指向一个 local static 对象”提供一份设计实例。
条款22、将成员变量声明为private
一旦将一个成员变量声明为 public 或 protected 而客户开始使用它们,就很难改变那个成员变量所涉及的一切。太多代码需要重写、重新测试、重新编写文档、重新编译。从封装的角度观之,其实只有两种访问权限:priavate(提供封装)和其他(不提供封装)。
请记住:
- 切记将成员变量声明为 private。这可赋予客户访问数据的一致性、可细微划分控制、允诺约束条件获得保证,并提供 class 作者以充分的实现弹性
- protected 并不比 pulic 更具封装性
条款23、宁以 non-member、non-friend 替换 member 函数
#include
class WebBrowser{
public:
void clearCache();
void clearHistory();
void removeCookies();
// 如果想一整个执行所有这些动作
// 方式一:
// 在类中提供这样一个函数,调用上面三个函数
void clearEveryThing();
};
// 方式二:
// 也可以用一个non-member函数实现
void clearBrowser(WebBrowser& wb){
wb.clearCache();
wb.clearHistory();
wb.removeCookies();
}1、member 函数clearEveryThing 带来的封装性比 non-member 函数clearBrowser 低:
- 对象内的数据,愈多函数可访问,数据的封装性就愈低
2、降低编译依赖性
24、若所有参数皆需类型转换,请为此采用 non-member 函数
先来看看何为隐式转换:
#include
class Rational {
public:
// 构造函数刻意不为 explicit,
// 允许 int-to-Rational 隐式转换
Rational (int numerator = 0,
int denominator = 1)
:n(numerator),d(denominator){}
// 分子(numerator)和 分母(denominator)的的访问函数
int numerator() const;
int denominator() const;
private:
int n,d;
};
int main(int argc, char *argv[])
{
// 这便是隐式转换:
// 【 将会隐式地将整数5转换为Rational类型,并通过调用构造函数
// Rational(int numerator = 0, int denominator = 1)来
// 创建Rational对象r。在这种情况下,numerator将被初始化为5,
// denominator将被初始化为1】
Rational r =5;
return 0;
}
再来看看operator* 的使用会涉及到什么问题:
#include
class Rational {
public:
// 构造函数刻意不为 explicit,
// 允许 int-to-Rational 隐式转换
Rational (int numerator = 0,
int denominator = 1)
:n(numerator),d(denominator){}
// 分子(numerator)和 分母(denominator)的的访问函数
int numerator() const;
int denominator() const;
const Rational operator* (const Rational& rhs) const{}
private:
int n,d;
};
int main(int argc, char *argv[])
{
Rational oneEighth(1,8);
Rational oneHalf(1,2);
Rational result = oneHalf * oneEighth;
result = result * oneEighth;
// 能运行
result = oneHalf * 2;
// 错误!
result = 2 * oneHalf;
return 0;
}为啥 result = oneHalf * 2 可以运行, 而result = 2 * oneHalf 却会报错:
1、result = oneHalf * 2 发生了所谓隐式转换:
oneHalf 是一个内含 operator* 函数的 class 的对象,所以编译器调用该函数。然后编译器知道你正在传递一个 int,而函数需要的是 Rational; 但它也知道只要调用 Rational 构造函数并赋予你所提供的 int,就可以变出一个适当的 Rational 来。于是它就这样做了。换句话说此一调用动作在编译器眼中有点像这样:
const Ration temp(2); // 根据2建立一个暂时的 Rational 对象
result = oneHalf * temp; // 等同于 oneHalf.operator*(temp)当然,只因为涉及到 non-explicit 构造函数,编译器才会这样做。如果 Rational 构造函数是 explicit ,以下语句没有一个能通过编译:
result = oneHalf * 2;
result = 2 * oneHalf;
2、result = 2 * oneHalf,整数2并没有相应的class,也就没有 operator* 成员函数。编译器也会尝试寻找可被以下这般调用的 non-member operator* (也就是在命名空间或在 global 作用域内):
result = operator*(2, oneHalf); // 错误但本例并不存在这样一个接受 int 和 Rational 作为参数的 non-member operator*,因此查找失败
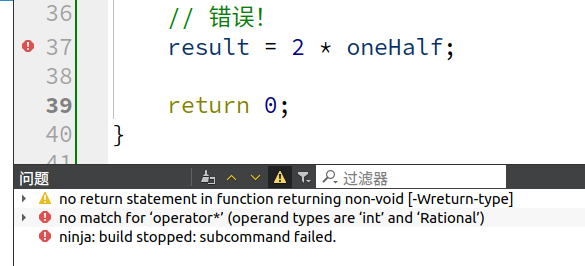
那怎么可以支持混合式算术运算。可行之道终于拨云见日:让 operator* 成为一个 non-member 函数, 便允许编辑器在每个实参身上执行隐式类型转换:
#include
class Rational {
public:
// 构造函数刻意不为 explicit,
// 允许 int-to-Rational 隐式转换
Rational (int numerator = 0,
int denominator = 1)
:n(numerator),d(denominator){}
// 分子(numerator)和 分母(denominator)的的访问函数
int numerator() const;
int denominator() const;
private:
int n,d;
};
// 注意:参数是两个Rational对象的引用
const Rational operator* (const Rational& lhs,
const Rational& rhs) {}
int main(int argc, char *argv[])
{
Rational oneEighth(1,8);
Rational oneHalf(1,2);
Rational result = oneHalf * oneEighth;
result = result * oneEighth;
// 能运行
result = oneHalf * 2;
// 万岁,通过编译了!
result = 2 * oneHalf;
return 0;
}
最后一个问题:operator* 是否应该成为 Rational class 的一个 friend 函数呢?
就本例而言答案是否定的,因为 operator* 可以完全由 Rational 的 public 接口完成任务。这导出一个重要的观察:member 函数的反面是 non-member 函数,不是 friend 函数。
无论任何时候可以避免 friend 函数就该避免。
请记住:
如果你需要为个函数的所有参数(包括被 this 指针所指的那个隐喻参数)进行类型转换,那么这个函数必须是个 non-member.
条款25、考虑写出一个不抛异常的 swap 函数
先来看看std::swap的典型实现:置换 a 和 b 的值
namespace std {
template
void swap(T& a, T& b)
{
T temp(a); // a 复制到temp
a = b; // b 复制到 a
b = temp; // temp 复制到 b
}
}只要类型 T 支持 copying (通过 copy 构造函数和 copy assignment 操作符完成),缺省的 swap 实现代码就会帮你置换类型为 T 的对象。
尝试将 std::swap 针对 Widget 特化:
#include
#include
class WidgetImp1{
public:
private:
int a,b,c;
std::vector v;
};
class Widget{
private:
WidgetImp1* pImp1; // 一旦要置换
public:
Widget(){}
Widget (const Widget& rhs){}
Widget& operator =(const Widget& rhs){
*pImp1 = *(rhs.pImp1);
}
};
// 一旦要置换两个 Widget 对象值,需要做的就是置换其pImp1指针。
// 但缺省的 swap 算法 效率很低:
// 不止复制三个 Widget, 还复制三个 WidgetWidgetImp1对象
//
// 所以要告诉 std::swap:
// 当 Widgets 被置换时真正该做的是置换其内部的pImp1指针
// 所以,将 std::swap 针对 Widget 特化
namespace std {
template
void swap(Widget& a, Widget& b)
{
swap(a.pImp1, b.pImp1);
}
}
using namespace std;
int main(int argc, char *argv[])
{
Widget a;
Widget b;
std::swap(a,b);
return 0;
}
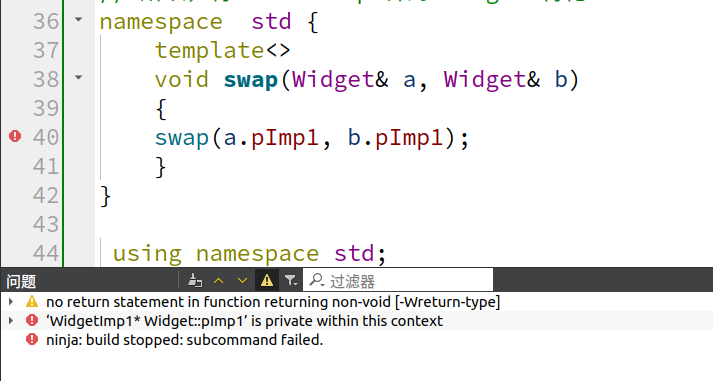
但是发现pImp1指针是私有变量,在类外访问不了
所以要在类中定义一个swap成员函数,并在swap特化函数中 使用该函数:
#include
#include
class WidgetImp1{
public:
private:
int a,b,c;
std::vector v;
};
class Widget{
private:
WidgetImp1* pImp1; // 一旦要置换
public:
Widget(){}
Widget (const Widget& rhs){}
Widget& operator =(const Widget& rhs){
*pImp1 = *(rhs.pImp1);
}
// 给swap 特化 所调用
void swap(Widget& other){
using std::swap;
swap(pImp1, other.pImp1);// 置换pImp1指针
}
};
// 一旦要置换两个 Widget 对象值,需要做的就是置换其pImp1指针。
// 但缺省的 swap 算法 效率很低:
// 不止复制三个 Widget, 还复制三个 WidgetWidgetImp1对象
//
// 所以要告诉 std::swap:
// 当 Widgets 被置换时真正该做的是置换其内部的pImp1指针
// 所以,将 std::swap 针对 Widget 特化
namespace std {
template
void swap(Widget& a, Widget& b)
{
a.swap(b);
}
}
using namespace std;
int main(int argc, char *argv[])
{
Widget a;
Widget b;
std::swap(a,b);
return 0;
}
上面都是 class ,而非 class template。关于 class template 的 swap 函数暂时不学习。
请记住:
- 当 std::swap 对你的类型效率不高时,提供一个 swap 成员函数,并确定这个函数不抛出异常。
- 如果你提供一个 member swap,也该提供一个non-member swap 用来调用前者。对于classes (而非 templates),也清特化 std::swap.
- 调用 swap 时应针对 std::swap 使用 using 声明式,然后调用 swap 并且不带任何 “命名空间资格修饰符”
- 为“用户定义类型”进行 std templates 全特化是好的,但千万不要尝试在 std 内加入某些对 std 而言全新的东西
五、实现
条款26、尽可能延后变量定义式的出现时间
过早定义变量的例子:
#include
const int MininmumPasswordLength = 10;
std::string encryptPassword(const std::string& password){
using namespace std;
// 过早定义变量encrypted
// 如果下面抛出异常,该变量没用使用到
// 但还是要承受该变量的构造和析构成本
string encrypted;
if (password.length() 最好延后 encrypted 的出现,直到真正需要它。
但循环怎么办?
如果变量只在循环内使用,那么把它定义于循环外并在每次循环迭代时赋值给它比较好,还是该把它定义于循环内?
class Widget{};
const int n;
//A、 定义于循环外
Widget w;
for (int i=0; i两种写法的成本:
做法A: 1个构造函数 + 1个析构函数+ n个赋值操作
做法B:n个构造函数 + n个析构函数
看情况而定!一般选B!
条款27、尽量少做转型动作
旧式转型
// C风格
(T)expression // 将expression 转型为T
// 函数风格
T(expression) //将expression转型为T新式转型
// 用来将对象的常量性转除
const_cast(expression)
// 安全向下转型
dynamic_cast(expression)
// 低级转型,很少用
reinterpret_cast(expression)
// 用来强迫转换
static_cast(expression)
旧式转型合法,但一般用新式转型:
1、容易在代码中被辨识
2、各转型动作的目标愈窄,编译器愈可能诊断出错误的运用
唯一使用旧式转型的的时机是,当我要调用一个 explicit 函数将一个对象传递给一个函数时。例如:
#include
class Widget{
public:
explicit Widget(int size){}
};
void doSomeWork(const Widget& w){}
int main(int argc, char *argv[])
{
// 以一个int加上“函数风格”的转型动作创建一个Widget
doSomeWork(Widget(15));
// 以一个int加上“C++风格”的转型动作创建一个Widget
// 蓄意的“对象生成”动作感觉不怎么像“转型”,所以一般
// 用前者
doSomeWork(static_cast(15));
return 0;
}
这里避免用转型
#include
class Window{
public:
virtual void onResize(){}
};
class SpecialWindow: public Window{
public:
virtual void onResize(){
// 避免这种写法
static_cast(*this).onResize();
// 使用这种写法
Window::onResize(); // 调用Window::onResize 作用于*this身上
// 这里写SpecialWindow专属行为
//。。。。。。。。。。。。。。
}
};
int main(int argc, char *argv[])
{
SpecialWindow sw;
return 0;
}dynamic_cast 比较耗时
之所以需要dynamic_cast,通常时候因为你想在一个你认定为 derived class 对象身上执行derived class 操作汉航速,但你手上却只有一个“指向base”的Pointer 或 referene, 你只能靠它们处理对象。
省略。。。。。。。。。。
请记住:
如果可以,尽量避免转型,特别是在注重效率的代码中避免dynamic_cast。如果有个涉及需要转型动作,试着发展无需转型的替代设计。
如果转型式必要的,试着将他隐藏于某个函数背后。客户随后可以调用该函数,而不需要将转型放进他们自己的代码内。
宁可使用C++-style(新式)转型,不要使用旧式转型。前者很容器辨识出来,而且也比较有着分门别类的职掌。
条款28、避免返回 handles 指向对象内部成分
#include
#include
#include
class Point{
public:
Point(int a, int b):x(a),y(b){}
void setX(int newVal){}
void setY(int newVal){}
int getX(){return x;}
private:
int x,y;
};
struct RectData
{
Point leftTop;
Point rightDown;
};
class Rectangle{
private:
std::shared_ptr pData;
public:
// point 式自定义类型,根据条款20
// by-reference 更加高效
// 此时返回的式内部数据的引用,有被修改的风险
// 所以要前面要加上 const
const Point& upperLeft() const {return pData->leftTop;}
const Point& lowerRight() const {return pData->rightDown;}
Rectangle(Point p1, Point p2){
pData->leftTop = p1;
pData->rightDown = p2;
}
};
本例中是成员函数返回 references,但如果它们返回的式指针或者迭代器也应该如此
空悬号码牌的问题:
#include
#include
#include
class Point{
public:
Point(int a, int b):x(a),y(b){}
void setX(int newVal){}
void setY(int newVal){}
int getX(){return x;}
private:
int x,y;
};
struct RectData
{
Point leftTop;
Point rightDown;
};
class Rectangle{
private:
std::shared_ptr pData;
public:
// point 式自定义类型,根据条款20
// by-reference 更加高效
// 此时返回的式内部数据的引用,有被修改的风险
// 所以要前面要加上 const
const Point& upperLeft() const {return pData->leftTop;}
const Point& lowerRight() const {return pData->rightDown;}
Rectangle(Point p1, Point p2){
pData->leftTop = p1;
pData->rightDown = p2;
}
};
class GUIObject{};
const Rectangle boundingBox(const GUIObject& obj){}
int main(){
GUIObject* pgo;
const Point* pUpperLeft = &(boundingBox(*pgo).upperLeft());
}本例子最后一句:
boundingBox(*pgo)对 boundingBox 的调用获得一个新的、暂时的Rectangle 对象。这个对象没有名称,所以暂时称它为 temp。
&boundingBox(*pgo).upperLeft()随后 upperLeft 作用于 temp 身上,返回一个 reference 指向 temp 的内部成分,更具体地说指向一个用以标识 temp 的 Points。于是pUpperLeft指向那个对象。
但是在在那个语句结束后,boundingBox 的返回值,也就是我们所说的 temp,将被销毁,而那间接导致 temp 内的 Points 析构。最终导致pUpperLeft 指向一个不再存在的对象;
也就是说一旦产生pUpperLeft 的那个语句结束,pUpperLeft 也就变成空悬、虚吊(dangling)
但是我有个疑问:
这里的shared_ptr怎么不需要分配内存?
请记住:
避免返回 handles (包括 references、指针、迭代器)指向对象内部。遵守这个条款可增加封装性,帮助 const 成员函数的行为像个 const,并将 “虚吊号码牌”(dangling handles)的可能性降至最低。
条款29、为 ” 异常安全 “而努力是值得的
仔细分析下例ChangeBackground函数
#include
#include
using namespace std;
struct Image
{
char image[480*640];
};
class PrettyMenu{
public:
void ChangeBackground(Image& imgSrc);
private:
mutex mutex1; // 互斥器
Image* bgImage; // 目前的背景图像
int imageChanges; // 背景图像被改变的次数
};
void PrettyMenu::ChangeBackground(Image& imgSrc)
{
mutex1.lock(); // 取得互斥器
delete bgImage; // 摆脱旧的背景图像
++imageChanges; // 修改图像变更次数
bgImage = new Image(imgSrc); // 安装新的背景图像
mutex1.unlock(); // 释放互斥器
}
int main(int argc, char *argv[])
{
PrettyMenu pt;
return 0;
}该函数可能会发生的问题:
泄露资源:new Image(imgSrc) 导致异常,对 unlock 的调用就绝不会执行,于是互斥器就永远把持住了
数据败坏:new Image(imgSrc) 抛出异常,bgImage就是指向一个已被删除的对象,imageChanges 也被累加,而其实并没有新的图像被成功安装起来
泄露资源的问题如何解决:以对象管理资源
#include
#include
using namespace std;
struct Image
{
char image[480*640];
};
class PrettyMenu{
public:
void ChangeBackground(Image& imgSrc);
private:
mutex mutex1; // 互斥器
Image* bgImage; // 目前的背景图像
int imageChanges; // 背景图像被改变的次数
};
void lock(mutex* pm){}
void unlock(mutex* pm){}
class Lock{
private:
mutex* mutexPtr;
public:
explicit Lock(mutex* pm):mutexPtr(pm)
{
lock(mutexPtr);
}
~Lock()
{
unlock(mutexPtr);
}
};
void PrettyMenu::ChangeBackground(Image& imgSrc)
{
Lock m1(&mutex1); // 来自条款14:获得互斥器并确保它稍后被释放
delete bgImage; // 摆脱旧的背景图像
++imageChanges; // 修改图像变更次数
bgImage = new Image(imgSrc); // 安装新的背景图像
}
int main(int argc, char *argv[])
{
PrettyMenu pt;
return 0;
}如此,利用对象管理资源!
再来专注解决数据败坏,在解决该问题之前,先面对异常安全函数的三个保证:
基本承诺:
如果异常被抛出,程序内的任何事物仍然保持在有效状态下。没有任何对象或数据结构会因此而败坏,所有对象都处于一种内部前后一致的状态。举个例子,ChangeBackground 函数抛出异常后,PrettyMenu 对象仍然可以继续拥有原背景图像 ,或是令它拥有某个缺省背景图像。
强烈保证:
如果异常被抛出,程序状态不改变。调用这样的函数需有这样的认知:如果函数成功,就是完全成功,如果函数失败,程序会回复到 “调用之前的状态”。
不抛掷保证:
承诺绝不抛出异常,因为它们总是能够完成它们原先承诺的功能。
异常安全码(Exception-safe code)必须提供上述三种保证之一,对于大部分函数往往在基本承诺和强烈保证中择一;
怎么让ChangeBackground 函数提供强烈保证:
- 用智能指针管理Image*
- 调整++imageChanges 到真的发生新背景图像安装之后
class PrettyMenu{
...
std::shared_ptr bgImage;
...
}
void PrettyMenu::ChangeBackground(Image& imgSrc)
{
Lock m1(&mutex1);
bgImage.reset(new Image(imgSrc));// 以 “new Image” 的执行结果设定bgImage 内部指针
++imageChanges;
}上述两个改变几乎足够让 ChangeBackground 提供强烈的异常安全保证。
但是我们还想进一步。有一个一般化的设计策略很典型地会导致强烈保证,很值得熟悉。这个策略被称为–copy and swap:
1、为你打算修改的对象(原件)做出一份副本,然后在那副本身上做一切必要修改。
2、若有任何修改动作抛出异常,原对象仍保持未改变状态。
3、待所有改变都成功后,再将修改过的那个副本和原对象在一个不抛出异常的操作中置换(swap)。
实现上通常是将所有 “隶属对象的数据” 从原对象服务器托管网放进另一个对象内,然后赋予原对象一个指针,指向那个所谓的实现对象(implementation object,即副本)。这种手法常被称为 pimpl idiom,条款31 详细描述了它。典型的写法如下:
// 将所有 “隶属对象的数据” 从原对象放进另一个对象内
// 让 PMImpl 成为一个 struct 而不是 一个 class:
// 1、PrettyMenu 的数据封装性已经由于 “pImpl是private” 而获得了保证
// 2、如果令 PMImpl 为一个class,不是很方便 (条款25)
struct PMImpl{
std::shared_ptr bgImage;
int imageChanges;
};
class PrettyMenu{
...
private:
mutex mutex1
// 赋予原对象一个指针
std::shared_ptr pImpl;
};
void PrettyMenu::ChangeBackground(Image& imgSrc)
{
using std::swap; // 见条款25
Lock m1(&mutex1);
// 创建副本
// 感觉应该写成下面这个:
//std::shared_ptr pNew(new PMImpl(*pImpl));
std::shared_ptr pNew(new PMImpl);
// 修改副本
pNew->bgImage.reset(new Image(imgSrc));
++pNew->imageChanges;
// 置换(swap)数据
swap(pImpl, pNew);
}本例中,借以 “copy-and-swap” 策略 对对象状态实现 “全有或全无”。
清记住:
1、异常安全函数(Exception-safe function) 即使发生异常也不会泄露资源或允许任何数据结构败坏。这样的函数区分为三种可能的保证:基本型、强烈型、不抛异常型。
2、“强烈保证” 往往能够以 copy-and-swap 实现出来,但 “强烈保证”并非对所有函数都可实现或具备现实意义。
3、函数提供的 “异常安全保证” 通常最高只等于其所调用之各个函数的 “异常安全保证” 中的最弱者
条款30、透彻了解 inlining 的里里外外
inline 关键字的作用:
inline关键字用于修饰函数,它是一种对编译器的建议,用于告诉编译器在编译时将函数内联展开。
通常情况下,函数的调用会导致程序跳转到函数的定义处执行,然后再返回到调用点。当函数较小且频繁调用时,这种跳转和返回的开销可能会成为性能瓶颈。
使用inline关键字可以建议编译器将函数的定义插入调用点,而不是跳转到函数的定义处执行。这样可以减少函数调用的开销,提高程序的执行效率。
要声明一个内联函数,只需在函数定义的前面加上inline关键字即可。例如:
inline int add(int x, int y) {
return x + y;
}
需要注意的是,inline关键字只是对编译器的建议,编译器可以选择是否将函数内联展开。通常情况下,对于较短的函数,编译器会选择内联展开。但是对于较长的函数,编译器可能会忽略inline关键字的建议。
另外,将函数定义放在头文件中时,为了避免出现多重定义错误,通常需要将函数声明为inline。因为头文件会被多个源文件包含,如果函数定义不是inline的,则每个源文件中都会有一份函数定义,从而导致多重定义错误。
直接在 class 定义式内呈现成员函数的本体,会让该成员函数暗自成了inline 。
请记住:
1、将大多数 inlining 限制在小型、被频繁调用的函数身上。这可使日后的调试过程和二进制升级(binary upgradability) 更容易,也可以使潜在的代码膨胀问题最小化,使程序的速度提升机会最大化。
2、不要只因为 function templates 出现在头文件中,就将它们声明为 inline
条款31、将文件间的编译依存关系将至最低
在了解文件间的编译依存关系之前,先来看看这个例子:
class Person{
public:
Person(const std::string& name, const Date& birthday,
const Address& addr){}
std::string name() const;
std::string birthday() const;
std::string address() const;
private:
std::string theName; //
Date theBirthData;
Address theAddress;
};
int main(int argc, char *argv[])
{
std::string name;
Date birthday;
Address addr;
Person p(name, birthday, addr);
return 0;
}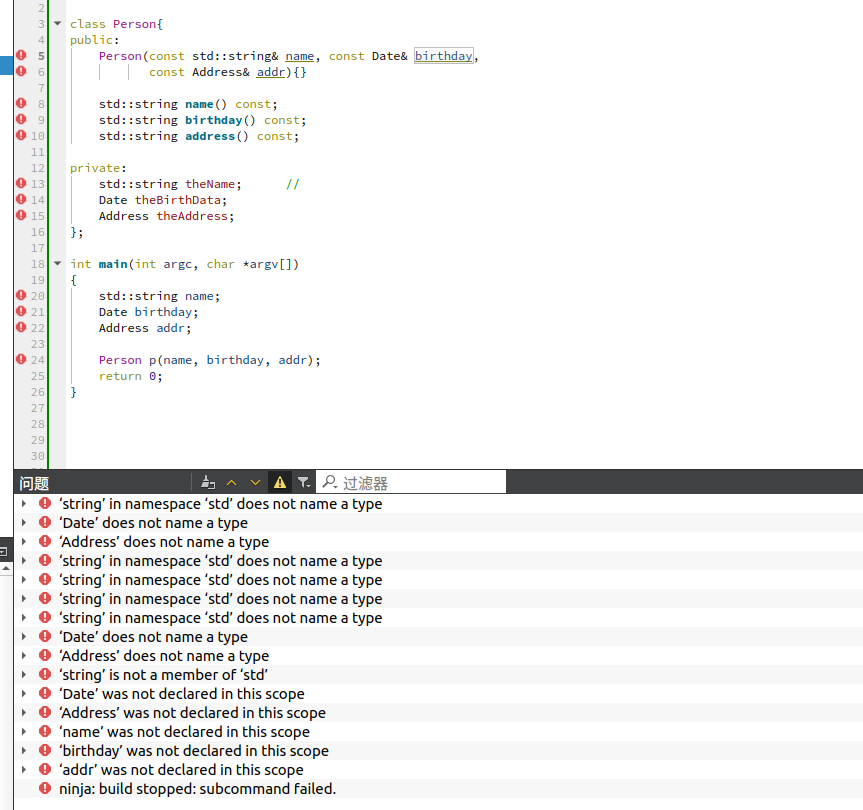
没错,这个例子根本就无法通过编译,因为编译器没有取得其实现代码所用到的 classes string, Data 和 Address的定义式。
这样的定义式通常由 #include 指示符提供,所以 Person 定义文件的最上方很可能存在这样的的东西:
#include
#include "data.h"
#include "address.h"但是这样一来,Person 定义文件和其含入文件之间形成了一种编译依存关系。
现在需要 “将对象实现细目隐藏于一个指针背后”。正对 Person 可以这样做: 把 Person 分割成两个 classes,一个只提供接口,另一个负责实现该接口。如果负责实现的那个所谓 implementation class 取名为 PersonImpl,Person 将定义如下:
#include
#include
// Person 实现类的前置声明
class PersonImpl{};
//Person 接口用到的 classes 的前置声明
class Date{};
class Address{};
class Person{
public:
Person(const std::string& name, const Date& birthday,
const Address& addr){}
std::string name() const;
std::string birthday() const;
std::string address() const;
private:
// 指针,指向实现物
// 以对象管理资源,条款13
std::shared_ptr pImpl;
};
int main(int argc, char *argv[])
{
std::string name;
Date birthday;
Address addr;
Person p(name, birthday, addr);
return 0;
}在这里,main class(Person) 只内含一个指针成员(这里使用std::shared_ptr,见条款13),指向其实现类(PersonImpl)。这般设计常被称为 pimpl idiom(pimpl 是 “pointer to implementation”的缩写)。这种 classes 内的指针名称往往就是pImpl,就像上面代码那样。
这样的设计之下,Person的客户就完全与 Dates,Addresses 以及 Persons 的实现细目分离。那些classes 的任何实现修改都不需要 Person 客户端重新编译。这样就是“接口与实现分离”。
这个分离的关键在于以“声明的依存性”替换“定义的依存性”,那正是编译依存性最小化的本质:现实中让头文件尽可能自我满足,万一做不到,则让它与其他文件内的声明式(而非定义式)相依。其他每一件事都源自于这个简单的设计策略:
1、如果使用 object reference 或 objecct pointers 可以完成任务,就不要使用 objects。
2、如果能够,尽量以 class 声明式替换 class 定义式。
3、为声明式和定义式提供不同的头文件,一个用于声明式,一个用于定义式。
像person这样使用 pimpl idiom 的 classes,往往被成为 Handle classes。
另一个制作 Handle class 的办法式,令 Person 成为一种特殊的 abstract base class(抽象基类),称为 Interface class。
这个例子有问题:
#include
#include
#include
// 一个针对Person而写的 Interface class (抽象基类)
// 目的:
// 详细描述 derived classes 的接口(见条款34)
// 所以通常不带成员变量,也没有构造函数,
// 只有一个virtual 析构函数以及一组 pure virtual 函数,
// 用来叙述整个接口
class Date{};
class Address{};
class Person{
public:
virtual ~Person();
virtual std::string name() const=0;
virtual std::string birthDate() const = 0;
virtual std::string address() const = 0;
static std::shared_ptr create(const std::string& name,
const Date& birthDate,
const Address& addr);
};
class RealPerson: public Person{
private:
std::string theName;
Date theBirthDate;
Address theAddress;
public:
RealPerson(const std::string& name, const Date& birthday,
const Address& addr)
:theName(name),theBirthDate(birthday),theAddress(addr){}
virtual ~RealPerson() {}
std::string name() const{}
std::string birthDate() const{}
std::string address() const{}
};
std::shared_ptr Person::create(const std::string &name,
const Date &birthDate,
const Address &addr)
{
return
std::shared_ptr(new RealPerson(name,birthDate,addr));
}
int main(){
std::string name;
Date dateOfBirth;
Address address;
std::shared_ptr pp(Person::create(name, dateOfBirth, address));
std::cout name() birthDate() address();
}请记住:
1、支持 “编译依存性最小化” 的一般构想是: 相依于声明式,不要相依于定义式。基于此构想的两个手段式 Handle classes 和 Interface classes
2、程序库头文件应该式以 “完全且仅有声明式”的形式存在。这种做法不论是否涉及 templates 都适用。
六、继承与面向对象设计
条款32、确定你的 public 继承塑模出 is-a 关系
请记住:
“public 继承”意味着 is-a。适用于 base classes 身上的每一件事情一定也适用于 derived classes 身上,因为每一个 derived classes 对象也都是一个 base class 对象
条款33、避免遮挡继承而来的名称
看看这个例子:
#include
int x= 1; // global 变量
void someFunc()
{
double x=2.3; // local 变量
std::cout 
看见没,打印的是2.3。是 local 变量 x, 而不是 global 变量 x,因为内层作用域的名称会遮掩(遮蔽)外围作用域的名称。没错即使类型不一样,也会被遮蔽,只看变量名称!
在类继承中呢?
#include
class Base{
private:
int x;
public:
virtual void mf1()=0;
virtual void mf1(int){}
virtual void mf2(){}
void mf3(){}
void mf3(double){}
};
class Derived: public Base{
public:
virtual void mf1(){}
void mf3(){}
void mf4(){}
};
int main(){
Derived d;
int x;
d.mf1(); // 调用 Derived::mf1
d.mf1(x); // 错误!因为 Derived::mf1 遮掩了 Base::mf1
d.mf2(); // 调用 Base::mf2
d.mf3(); // 调用 Derived::mf3
d.mf3(x); // 错误! 因为 Derived::mf3 遮掩了 Base::mf3
}如本例所见,即使 base classes 和 derived classes 内的函数有不同的参数类型也适用,而且不论函数是 virtual 或 non-virtual 一体适用。只要函数名字相同,继承类就会遮掩掉基类的函数。
当然,也有办法在扩展类中调用基类被遮掩的函数:
方法一:使用using 声明式
#include
class Base{
private:
int x;
public:
virtual void mf1()=0;
virtual void mf1(int){}
virtual void mf2(){}
void mf3(){}
void mf3(double){}
};
class Derived: public Base{
public:
// 让Base class 内名为mf1和mf3的所有东西在Derived作用域内都可见(并且public)
using Base::mf1;
using Base::mf3;
virtual void mf1(){}
void mf3(){}
void mf4(){}
};
int main(){
Derived d;
int x=1;
d.mf1(); // 调用 Derived::mf1
d.mf1(x); // 现在可以了
d.mf2(); // 调用 Base::mf2
d.mf3(); // 调用 Derived::mf3
d.mf3(x); // 现在可以了
}方法二:使用转交函数(forwarding functions)
请记住:
derived classes 内的名称会遮掩 base classes 内的名称。在 public 继承下从没有人希望如此。
为了被遮掩的名称再见天日,可使用 using 声明式或转交函数(forwarding functions)
条款34、区分接口继承和实现继承
#include
class Shape{
public:
virtual void draw() const = 0;
virtual void error(const std::string& msg);
int objectID() const;
};
class Rectangle : public Shape{
void draw() const{}
};
class Ellipse : public Shape{
void draw() const{}
};
int main(){
// 错误! Shape 是抽象的,不能实例化
Shape* ps = new Shape;
Shape* ps1 = new Rectangle;
ps1->draw();// 调用 Rectangle::draw
Shape* ps2 = new Ellipse;
ps2->draw(); // 调用 Ellipse::draw
// 调用Shape::draw
// 但是没有什么意义,因为纯虚函数在基类中根本没有定义
ps1->Shape::draw();
ps2->Shape::draw();
}声明简朴的(非纯)impure virtual 函数的目的,是让 derived classes 继承该函数的接口和缺省实现:
比如
class Shape{
public:
virtual void error(const std::string& msg);
}你必须支持一个 error 函数,但如果你不想自己写一个,可以使用 Shape class 提供的缺省版本
再看一个例子:
class Airport{};
class Airplane{
public:
virtual void fly(const Airport& destination);
};
void Airplane::fly(const Airport& destination){
// 缺省代码,将飞机飞到指定的目的地
}
class ModelA : public Airplane{};
class ModelB : public Airplane{};为了避免在ModelA 和 ModelB 中撰写相同代码,缺省飞行行为由 Airplane::fly 提供,它同时被 ModelA 和 ModelB 继承。
这是个典型的面向对象设计。两个 class 共享一份相同性质(也就是它们实现 fly的方式),所以共同性质被搬到 base class 中。
如果有一个新的类 ModelC也继承 Airplane,但是飞行动作和缺省的不一样,如果忘记重载飞机动作的话,在调用飞行动作的时候就会不可避免的使用基类的飞行动作,而这会导致错误。
class Airport{};
class Airplane{
public:
virtual void fly(const Airport& destination);
};
void Airplane::fly(const Airport& destination){
// 缺省代码,将飞机飞到指定的目的地
}
class ModelA : public Airplane{};
class ModelB : public Airplane{};
class ModelC: public Airplane{
// 未声明fly函数
};
int main(int argc, char *argv[])
{
Airport PDX;
Airplane* pa = new ModelC;
//
pa->fly(PDX);
delete pa;
return 0;
}那有什么方法,避免上述问题?
方法一:切断 “virtual 函数接口”和其 “缺省实现之间的连接”
#include
class Airport{};
class Airplane{
public:
virtual void fly(const Airport& destination) = 0;
protected:
// 这个不是接口,是用于接口的缺省代码
// 所以是protected,
// 继承类也可以访问该函数
void defaultFly(const Airport& destination);
};
void Airplane::defaultFly(const Airport& destination){
// 缺省代码,将飞机飞到指定的目的地
}
class ModelA : public Airplane{
public:
virtual void fly(const Airport &destination)
{defaultFly(destination);}
};
class ModelB : public Airplane{
public:
virtual void fly(const Airport &destination)
{defaultFly(destination);}
};
class ModelC: public Airplane{
public:
// 现在不可能意外继承不正确的fly实现代码了
// 因为 Airplane中的pure virtual 函数迫使ModelC 必须提供自己的fly版本
virtual void fly(const Airport &destination){}
};
int main(int argc, char *argv[])
{
Airport PDX;
Airplane* pa = new ModelA;
//
pa->fly(PDX);
delete pa;
return 0;
}如果你不喜欢以不同的函数分别提供接口和缺省实现,像上述的 fly 和 defaultFly 那样。
方法二:
pure virtual 函数必须在 derived classes 中重新声明,但它们也可以拥有自己的实现
#include
class Airport{};
class Airplane{
public:
virtual void fly(const Airport& destination)=0;
};
void Airplane::fly(const Airport& destination){
// 缺省代码,将飞机飞到指定的目的地
}
class ModelA : public Airplane{
public:
virtual void fly(const Airport &destination)
{Airplane::fly(destination);}
};
class ModelB : public Airplane{
public:
virtual void fly(const Airport &destination)
{Airplane::fly(destination);}
};
class ModelC: public Airplane{
public:
virtual void fly(const Airport &destination);
};
void ModelC::fly(const Airport &destination){
// 将C型飞机飞至指定的目的地
}
int main(int argc, char *argv[])
{
Airport PDX;
Airplane* pa = new ModelA;
//
pa->fly(PDX);
delete pa;
return 0;
}纯虚函数也可以有定义!
声明 non-virtual 函数的目的是为了令 dedrived classes 继承函数的接口及一份强制性实现:
每个扩展类都必须有这个non-virtual 函数
pure virtual函数、simple(impure) virtual 函数、 non-virtual 函数之间的差异,使得你得以精确指定你想要 derived classes 继承的东西:之继承接口,或是继承接口和一份缺省实现,或是继承接口和一份强制实现
请记住:
1、接口继承和实现继承不同。在Public 继承之下,derived classes 总是继承 base class 的接口
2、pure virtual 函数只具体指定接口继承
3、简朴的(非纯)impure virtual 函数具体指定接口继承以及缺省实现继承
4、non-virtual 函数具体指定接口继承以及强制性实现继承
条款35、考虑 virtual 函数以外的其他选择
healthValue 并为被声明 pure virtual,这暗示我们将会有个计算健康指数的缺省算法(见条款34)
class GameCharacter{
public:
virtual int healthValue() const;
}还有其他方法:
借由 Non-Virtual Interface 手法实现 Template Method 模式:
class GameCharacter{
private:
virtual int doHealthValue() const{
// 缺省算法,计算健康指数
}
public:
// derived classes 不重新定义它,见条款36
// 在class 定义式内呈现成员函数本体,会让其暗自成为inline,条款30
int healthValue() const{
// 做一些事前工作,
// 做真正的工作
int retValue = doHealthValue();
// 做一些事后的工作
return retValue;
}
}借由 Function Pointers 实现 Strategy 模式:
书上的代码表述不清楚
省略。。。。
条款36、绝不重新定义继承而来的 non-virtual 函数
条款37、绝不重新定义继承而来的缺省参数值
virtual 函数系动态绑定(dynamically bound),而缺省参数值却是静态绑定(statically bound)。
这句话是不是看起来不好理解,先来看看动态绑定和静态绑定式什么意思:
// 一个用以描述几何形状的 class
class Shape{
public:
enum ShapeColor{Red, Green, Blue};
// 所有形状都必须提供一个函数,用来绘出自己
virtual void draw(ShapeColor color = Red) const =0;
};
class Rectangle: public Shape{
public:
// 赋予不同的缺省参数值。这真糟糕
virtual void draw(ShapeColor color = Green) const{
std::cout Virtual 函数系动态绑定,意思是调用一个Virtual 函数时,究竟调用哪一份函数实现代码,取决于发出调用的那个对象的动态类型
pc->draw(Shape::Red); // 调用Circle::draw(Shape::Red)
pr->draw(Shape::Red); // 调用 Rectangle::draw(Shape::Red)缺省参数值是静态绑定。意思是你可能会在“调用一个定义于dereived class 内的函数”的同时,却使用 base class 为它指定的缺省参数值
// 调用Rectangel::draw(Shape::Red)
// 是的,你没看错参数是Shape::Red
// 而不是在Rectangle里重新定义的Shape::Green
pr->draw();
即使把指针换成references问题仍然存在。问题在于draw 是个 virtual 函数,而它有个缺省参数值 在 derived class 中被重新定义了。
当你想令 virtual 函数表现出你所想要的行为但却遭遇麻烦,聪明的做法是考虑替代设计。条款35中,NVI(non-virtual interface)手法:令 base class 内的一个 public non-virtual 函数调用 private virtual 函数,后者可被 derived classes 重新定义。这里我们可以让 non-virtual 函数指定缺省参数,而 private virtual 函数负责真正的工作:
#include
// 一个用以描述几何形状的 class
class Shape{
public:
enum ShapeColor{Red, Green, Blue};
void draw(ShapeColor color = Red) const{ // 如今它是non-virtual
doDraw(color); // 调用一个virtual
}
private:
// 真正的工作在此完成
virtual void doDraw(ShapeColor color) const=0;
};
class Rectangle : public Shape{
public:
private:
// 注意,不须指定缺省参数值
// 就算你这里重新定义了缺省参数,也没有用
// 因为non-vitual 函数应该绝对不被 derived classes 覆写(条款36)
// 这个设计很清楚地使得 draw 函数的color 缺省参数总是为Red
virtual void doDraw(ShapeColor color) const{
std::cout draw();
delete r;
// 即使以对象调用此函数,也不需要指定参数值
Rectangle r1;
r1.draw();
}请记住:
绝对不要重新定义一个继承而来的缺省参数值,因为缺省参数值都是静态绑定,而 virtual 函数—- 你唯一应该覆写的东西—却是动态绑定。
条款38、通过复合塑模出 has-a 或 “根据某物实现出”
#include
#include
template
class Set{
public:
bool member(const T& item) const;
void insert(const T& item);
void remove(const T& item);
std::size_t size() const;
private:
std::list rep;
}
template
bool Set::member(const T &item) const
{
return std::find(rep.begin(), rep.end(), item) != rep.end()
}
template
bool Set::insert(const T &item)
{
if (!member(item)) rep.push_back(item);
}
template
void Set::remove(const T &item)
{
typename std::list::iterator it =
std::find(rep.begin(), rep.end(), item);
if (it != rep.end()) rep.erase(it);
}
template
std::size_t Set::size() const
{
return rep.size();
}
请记住:
复合的意思和 public 继承完全不同
在应用域,复合意味着 has-a, 在实现域,复合意味着更具某物实现出
条款39、明智而审慎地使用private继承
看完这个例子后,你是否理解是否要谨慎使用 private 继承:
#include
class Person{};
class Student: private Person{};
void eat(const Person& p);
void study(const Student& s);
int main(){
Person p;
Student s;
eat(p);
// 错误!
// classes之间的继承关系是private
// 编译器不会自动将一个derived class 对象转换为一个 base class 对象
// 这确实与 public 继承不一样
// 第二条规则:
// 由 private base 继承而来的所有成员,在 derived class 中都会变成 private 属性,
// 纵使它们在 base class 中原来是 protected 或 public 属性
eat(s);
}条款40、明智而审慎地使用多重继承
一个简单的多重继承的例子:
#include
class BorrowableItem{ // 图书光允许你借某些东西
public:
void checkOut(){} // 离开时进行检查
};
class ElectronicGadget{
private:
bool checkOut() const{} // 执行自我检测,返回是否检测成功
};
class MP3Player:
public BorrowableItem,
public ElectronicGadget{};
int main(){
MP3Player mp;
// 有歧义,不知道是用那个基础类的
mp.checkOut();
// 应该这样
mp.BorrowableItem::checkOut();
}再复杂一点,一个钻石型多重继承:
#include
#include
class File{
public:
std::string fileName = "jason";
};
class InputFile : public File{};
class OutFile : public File{};
class IOFile : public InputFile,
public OutFile{};
int main(){
IOFile io;
std::cout 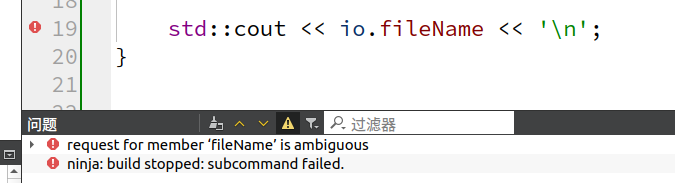
File class 有个成员变量 fileName,但是 IOFile 从其每一个 base class 继承一份,所以其应该有两份 fileName 成员变量。所以导致有歧义!
解决方法是:直接继承 File 的 classes 采用 “virtual 继承”
class File{
public:
std::string fileName = "jason";
};
class InputFile : virtual public File{};
class OutFile : virtual public File{};
class IOFile : public InputFile,
public OutFile{};
其他省略
七、模板与泛型编程
条款41、了解隐式接口和编译期多态
条款42、了解 typename 的双重意义
以下 template 声明式,class 和 typename 意义完全相同:
template class Widget;
template class Widget;其实下面个例子运行不起来。
#include
#include
// 下述 template function 接受一个STL兼容容器作为参数
template
void prinr2nd(const C& container){ // 打印容器内的第二个元素
if (container.size() >= 2){
C::const_iterator iter(container.begin()); // 取得第一元素的迭代器
++iter; // 将 iter 移往第二元素
int value = *iter; // 将该元素复制到某个int
std::cout 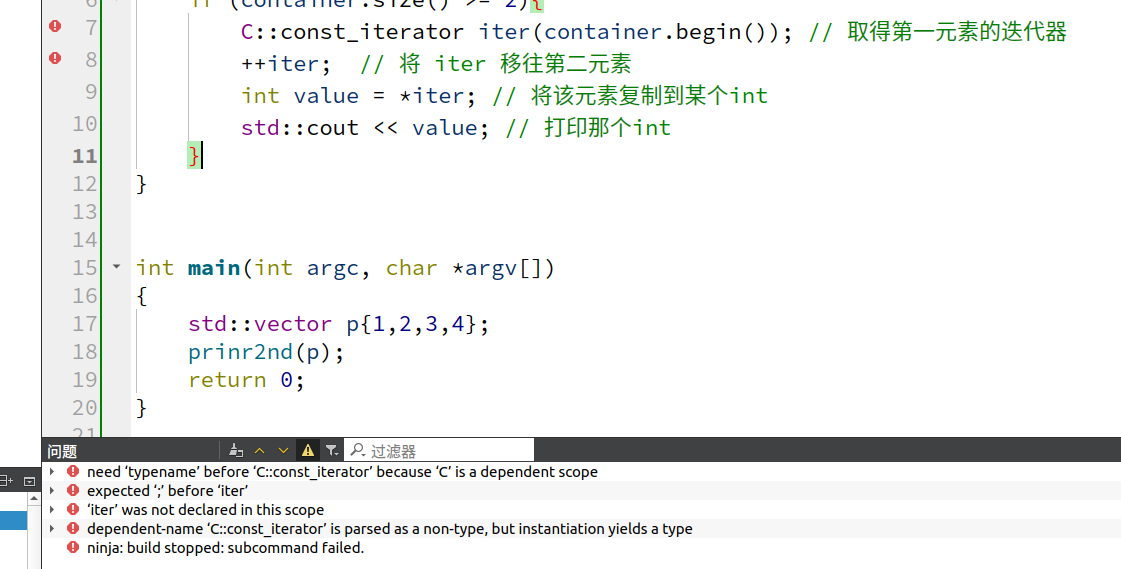
这是解决办法:
#include
#include
// 下述 template function 接受一个STL兼容容器作为参数
template
void prinr2nd(const C& container){ /
if (container.size() >= 2){
//iter 的类型是 C::const_iterator,实际是什么必须取决于 template 参数C
// template 内出现的名称如果相依某个 template 参数,称之为从属名称(dependent names)
// 如果从属名称在class内呈嵌套状,我们称为嵌套从属名称(nested dependent name)
// C::const_iterator 就是这样嵌套从属类型名称,所以必须以template 为前导
typename C::const_iterator iter(container.begin());
++iter;
int value = *iter;
std::cout 当然也有例外,但暂不学习
在真实程序的代表性例子:
template
void workWithIterator(IterT iter){
typename std::iterator_traits::value_type temp(*iter);
}
// 如果你认为 std::iterator_traits::value_type 读起来不畅快
// 可以考虑建立一个 typedef
template
void workWithIterator(IterT iter){
typedef typename std::iterator_traits::value_type value_type;
value_type temp(*iter);
}请记住:
声明template 参数时,前缀关键字 class 和 typename 可互换
请使用关键字 typename 标识嵌套从属类型名称;但不得在 base class lists(基类列)或member initialization list (成员初值列)内以它作为 base class 修饰符。
条款43、学习处理模板化基类内的名称
看这个不能通过编译的例子:
#include
#include
class CompanyA{
public:
void sendCleartext(const std::string& msg);
void sendEncrypted(const std::string& msg);
};
class CompanyB{
public:
void sendCleartext(const std::string& msg);
void sendEncrypted(const std::string& msg);
};
class MsgInfo{};
template
class MsgSender{
public:
void sendClear(const MsgInfo& info)
{
std::string msg;
// 在这里,根据 info 产生信息
Company c;
c.sendCleartext(msg);
}
void sendSecret(const MsgInfo& info)
{}
};
template
class LoggingMsgSender: public MsgSender{
public:
void sendClearMsg(const MsgInfo& info)
{
// 将“传送前”的信息写至log:
// 调用 base class 函数; 这段无法通过编译
// 问题在于:
// 当编译器遭遇 class template LoggingMsgSender 定义式时,并不知道它继承什么样的class
// 当然它继承的是 MsgSender,但其中的Company是个是个template参数,
// 不到后来(当 LoggingMsgSender 被具体化)无法确切知道它是什么。
// 而如果不知道 Company 是什么,就无法知道 class MsgSender看起来像什么
// 更确切地说是没办法知道它是否有个 sendClear 函数
sendClear(info);
// 将“传送后”的信息写至log
}
};
int main(){
MsgSender m;
}解决之道:针对 某个Company 产生一个MsgSender 特化版:
条款44、将与参数无关的代码抽离 templates
条款45、运用成员函数模板接受所有兼容类型
条款46、需要类型转换时请为模板定义非成员函数
条款47、请使用 traits classes 表现类型信息
条款48、认识template 元编程
八、定制 new 和 delete
条款49、 了解 new-handler 的行为
通过本例了解 new-handler:
#include
// 以下是 operator new 无法分配足够内存时,该被调用的函数
void outOfMem(){
std::cerr  看见没,在崩溃前有报错信息了!!
看见没,在崩溃前有报错信息了!!
一个设计良好的 new-handler 函数必须做的事情:
1、让更多内存可被使用:
当程序一开始执行就分配一大块内存,而后当new-handler 第一次被调用,将它们释还给程序使用
2、安装另一个new-handler
3、卸除 new-handler
4、抛出 bad_alloc 的异常
5、不返回,通常调用 abort 或 exit。
C++ 并不支持 class 专属之 new handlers,但可以自己实现。只需令每个一个class 提供自己的 set_new_handler 和 operator new 即可。
条款50、了解 new 和 delete 的合理替换时机
条款51、编写 new 和 delete 时需固守常规
条款52、写了 placement new 也要写 placement delete
九、杂项讨论
条款53、不要轻忽编译器的警告
条款54、让自己熟悉包括 TR1 在内的标准程序库
条款55、让自己熟悉 Boost
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
