

编者按:随着互联网内容数量的急剧增长,个性化推荐已成为各大科技公司的核心竞争力之一。那么,如何构建一个可靠、高效的基于嵌入技术的推荐系统,使其能够在实际生产环境中正常运行呢?这是所有从业者都关心的问题。
本文是Embedding技术与应用的最后一篇,探析 Embedding 应用工程的文章。作者认为,要让一个推荐系统项目取得成功,不能仅仅停留在算法层面,更需要从工程实现的角度进行全面的考量和设计。
文章详细阐述了一个推荐系统从零到一的完整流程,包括:生成嵌入、存储嵌入、处理与迭代嵌入、检索嵌入、更新与版本控制嵌入、推理与延迟优化、在线与离线评估等多个方面。这些都是构建一个可靠、高效推荐系统必须解决的关键问题。作者还指出,从业务角度来看,要让一个基于机器学习的项目成功实施,需要数据、技术和产品相互配合,不能单纯依靠算法本身。
这篇文章为我们深入剖析了工程实现对推荐系统的重要性,让我们更全面地认识到机器学习项目不仅需要出色的算法,还需要考量数据、技术构建、产品匹配等多方面因素,方能取得成功。本文为从业者提供了很好的工程思路与指导,具有重要的参考价值。
以下是译文,enjoy!
作者 | Vicki Boykis
编译|岳扬
欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
01 将嵌入的应用视为工程问题
通常情况下,机器学习工作流程(machine learning workflows)会给整个应用工程系统增加巨大的复杂度和开销,原因有很多[1]。首先,这个工作流程会将数据混合,而这些数据需要在下游进行监测,以防产生漂移。其次,它们的输出是不确定的,这意味着需要非常小心地跟踪这个工作流,因为我们通常不会对数据进行版本控制。第三,它们会导致处理管道(processing pipeline)出现混乱。
处理管道(processing pipeline)的混乱是胶水代码(glue code)的一种特殊情况,通常出现在数据准备流程中。随着新的信号被识别和新的信息源被添加,这些管道可以有机地演变。如果不加注意,为了以机器学习友好的格式准备数据所构建的系统,这个系统通常由多个数据处理步骤组成,包括数据抓取、数据清洗、数据转换、数据合并等,而且这些步骤之间可能存在多个依赖关系和中间文件输出。如果不加注意,这个系统可能会变得非常复杂和难以维护
从PinnerSage和Wide and Deep等模型的系统架构图中可看出,生产环境中使用嵌入的推荐系统[2],都有许多可活动组件。
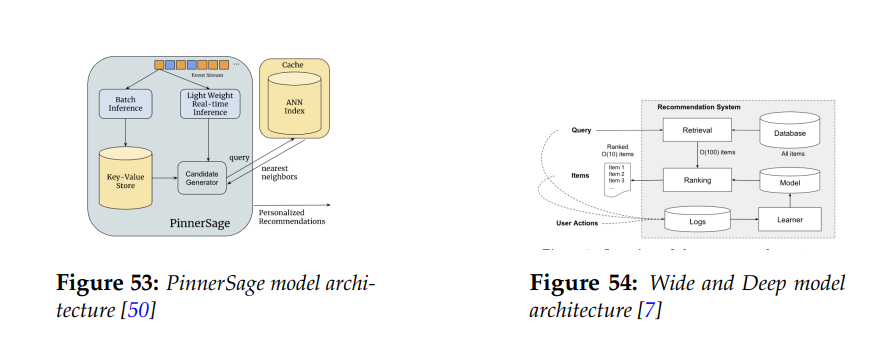
图1 PinnerSage和Wide and Deep模型的系统架构图
您可能还记得我们在这张图中讨论了推荐系统的基础阶段。

图2 在上下文中处理嵌入的通用流程
如果考虑一个成功的推荐系统在生产环境中的所有要求,实际生产环境中的推荐系统通常包含以下阶段:
• 生成嵌入(Generating embeddings)
• 存储嵌入(Storing embeddings)
• 嵌入特征工程和迭代(Embedding feature engineering and iteration)
• 工件检索(Artifact retrieval)
• 更新嵌入(updating embeddings)
• 对嵌入进行版本控制和数据漂移(versioning embeddings and data drift)
• 推理和延迟情况(Inference and latency)
• 在线(A/B测试)和离线(度量指标扫描)模型评估(Online (A/B test) and offline (metric sweep) model evaluation)
如果要考虑到我们上面关注的这些问题,任何生产环境中的推荐系统的系统架构图都会看起来像下面这样:
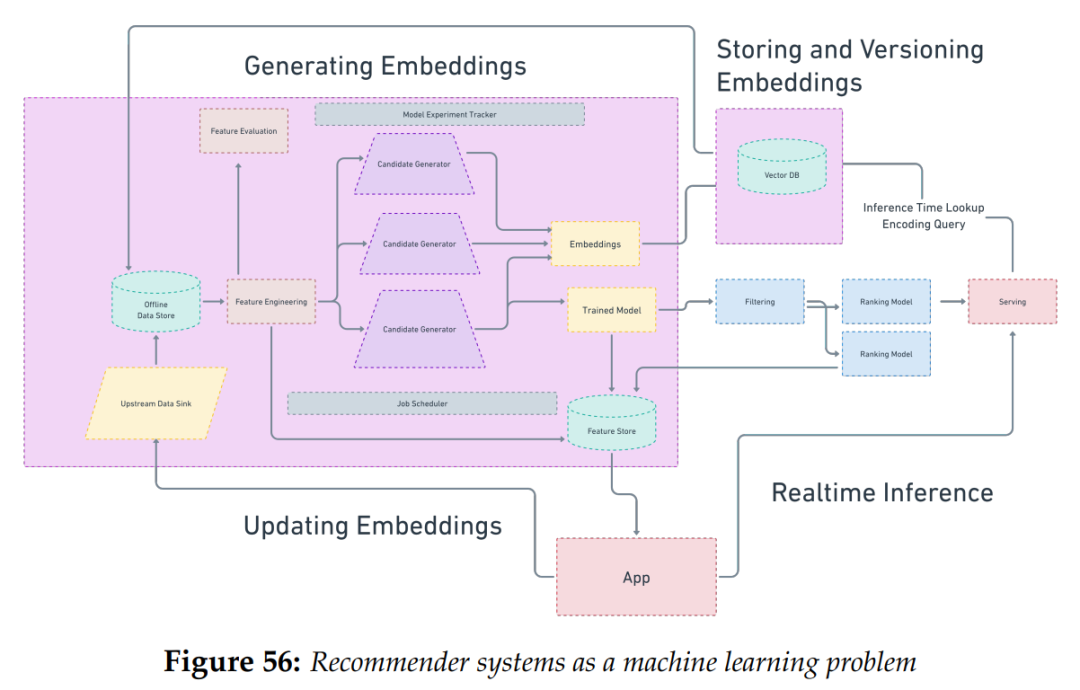
图3 将推荐系统作为一个机器学习问题来看待
02 生成嵌入(Generating embeddings)
通过前文,我们已经了解到,嵌入通常是训练神经网络模型时生成的副产品,一般是在添加用于分类或回归的最终输出层之前使用的倒数第二层。一般有两种方法来生成嵌入。一种方法是训练私有化的模型,就像YouTube、Pinterest和Twitter所做的那样。现在也越来越多人对训练私有化大语言模型表现出兴趣[3]。
然而,深度学习模型的一个重要的优点是我们也可以使用预训练模型。预训练模型是指已经在大量训练数据上进行训练、与我们的目标任务相似的模型,可以用于下游任务。BERT就是一种预训练模型[4],通过微调,可以用于任何机器学习任务。在微调过程中,我们可以采用已经在通用数据集上进行过预训练的模型。例如,BERT 是在 BookCorpus 和 English Wikipedia 上训练的,前者是由 11K 本书籍和 25 亿个单词组成的,后者是由 8 亿个单词组成的[5]。
关于训练数据的一些说明
训练数据是任何模型中最重要的部分。对于预训练的大语言模型来说,训练数据通常来自于对互联网的大规模爬取。为了保持竞争优势,这些训练数据集的组成通常不会被公开,因此需要进行相当多的逆向工程和猜测。例如,《What’s in my AI》[6]一书中介绍了GPT系列模型背后的训练数据,发现GPT-3是在Books1和Books2的基础上进行训练的。Books1很可能是BookCorpus[7],而Books2很可能是LibGen[8]。GPT还包括Common Crawl、WebText2和Wikipedia等大型开源数据集。这些信息非常重要,因为在选择预训练模型时,我们至少需要从高层次上了解它的训练数据,以便解释在微调时发生了哪些变化。
在微调模型时,我们需要执行与从头开始训练模型相同的所有步骤。需要收集训练数据、训练模型和将损失函数最小化。当然也有几个不同之处。当创建新模型时,我们会复制现有的预训练模型,但最终输出层除外,我们会根据新任务从头开始初始化输出层。在训练模型时,我们会随机初始化这些参数,且只继续调整前几层的参数,使它们专注于这项任务,而不是从头开始训练。通过这种方式,如果我们有一个像BERT这样的模型,训练完成后就可以泛化学习整个互联网,但我们这个使用Flutter制作的应用程序其语料库对流行话题非常敏感,因此需要每天更新,那么我们就可以重新调整模型的重点,而不必训练一个新的模型,只需要使用 10k 个样本,而非原来的数亿个[9]。同样,我们也可以对BERT嵌入进行微调。
还有其他一些通用语料库可用,例如GloVE、Word2Vec 和FastText[10](也使用CBOW进行训练)。我们需要决定是使用这些语料库,还是从头开始训练一个模型,或者采用第三种方法,通过API获取可用的嵌入[11],就像OpenAI的嵌入那样,尽管这样做可能相对于训练或微调我们自己的模型来说成本更高[12]。当然,我们需要根据具体用例在项目开始时进行评估和选择。
03 存储和检索嵌入
当我们训练好模型后,需要从其中提取嵌入。一般来说,模型经过训练后,其输出结果是一个包含所有模型参数的数据结构,包括模型的权重、偏置、层数和学习率(weights, biases, layers and learning rate)。 在训练模型时,嵌入被定义为一个层(layer),并与其他层一起组成了整个模型对象,在模型训练期间,嵌入在内存中存储。当我们将模型写入磁盘时,会将它们作为模型对象传播,并序列化到内存中,并在重新训练或推断时加载。
最简单的嵌入存储形式可以是numpy数组,该数组最初存在于内存中,并可以在需要时被访问和使用。
但是,如果我们正在迭代构建一个具有嵌入的模型,我们希望能够对它们进行多种操作:
• 在推理时批量或逐个访问模型
• 对嵌入的质量进行离线分析
• 嵌入特征工程
• 用新模型更新嵌入
• 版本控制嵌入
• 为新文档编码新的嵌入
处理这些用例的最复杂和可定制的软件是向量数据库(vector database),而介于向量数据库和使用内存数据库之间的是已经存在的存储系统或数据库(如Postgres和SQLite)的向量搜索插件,以及缓存(如Redis等)。
我们要对嵌入进行的最重要的操作是向量搜索(vector search),它允许我们找到与给定嵌入相似的嵌入向量,以便返回相似度。如果我们想要搜索嵌入,就需要一种经过优化的机制来搜索矩阵数据结构(matrix data structures),并以与传统关系型数据库经过优化来搜索基于行的关系相同的方式,执行最近邻比较。关系型数据库使用B树结构,通过在数据库中的索引列上建立的节点层次结构中,按升序排序的方式来优化读取。由于我们无法有效地对向量执行列查找(columnar lookups),因此我们需要为它们创建不同的结构。例如,许多向量存储是基于倒排索引(inverted indices)的。
通用形式的嵌入存储包含嵌入本身、将它们从隐空间(latent space)映射回单词、图片或文本的索引,以及使用各种最近邻算法在不同类型的嵌入之间进行相似度比较的方法。我们之前谈到过余弦相似度(cosine similarity)是比较隐空间表征(latent space representations)的基本方法。但是,当我们需要对数百万个向量集进行比较时,计算成本会变得非常昂贵,因为我们需要对每一对向量进行比较。为了解决这个问题,近似最近邻(ANN)算法被开发了出来,就像推荐系统中一样,从向量元素中创建邻域,并找到向量的k个最近邻。 最常用的算法包括HNSW(hierarchical navigable small worlds)和Faiss,这两种算法都是独立的库,也作为许多现有向量存储的一部分实现。
全搜索(full search)和最近邻搜索(nearest neighbor search)之间的权衡是,后者精确率较低,但速度更快。当我们在评估精确率(precision)和召回率(recall)之间切换时,我们需要注意权衡,并考虑我们对嵌入的准确率和推断延迟的要求是什么。
以下是Twitter为这个用例构建的嵌入存储系统的示例,早在向量数据库出现之前就已经存在了。[13]
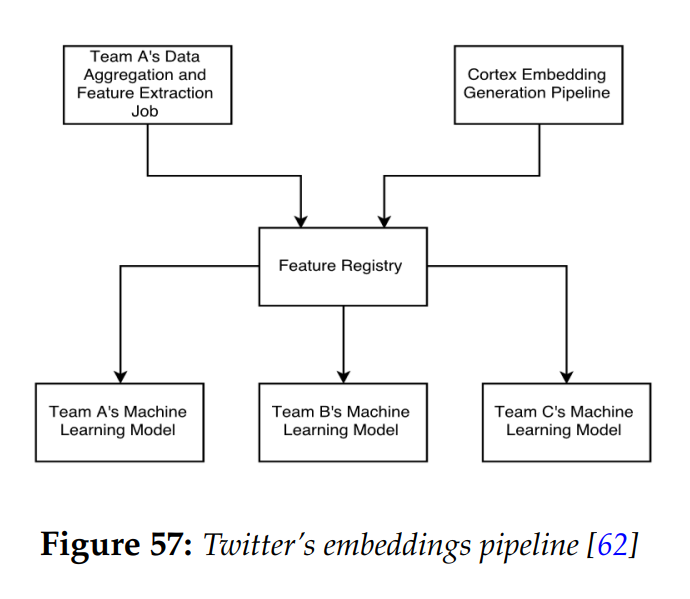
图4 Twitter的嵌入管道[13]
如本系列上一篇文章所述,Twitter在系统多处都使用了嵌入,Twitter通过创建一个集中式平台,将数据重新处理并将嵌入生成到下游的特征注册表(feature registry)中,使嵌入成为“一等公民”。
04 数据漂移检测、版本控制和可解释性
我们完成了嵌入的训练后,可能会认为已经大功告成。但是,与任何机器学习管道(machine learning pipeline)一样,嵌入需要定期更新,因为我们可能会遇到概念漂移(concept drift),概念漂移是指模型底层的数据发生变化。例如,假设某个模型包含一个二元特征,即是否拥有固定电话。但是,在2023年,由于大多数人已经改用手机作为主要电话,这在世界上大多数地方都不再是一个相关的特征,因此模型的准确性会降低。
这种现象在用于分类的嵌入中更为普遍。例如,假设我们使用嵌入进行trending栏目的话题检测。模型必须如wide and deep model那样能够泛化,以便能够检测新类别,但如果内容的类别变化很快,它可能无法实现泛化,因此我们需要经常重新训练生成新的嵌入。或者,举例来说,如果我们在图(graph)中对嵌入进行建模,如Pinterest所做的那样,而图中节点之间的关系发生了变化,我们可能就必须更新它们[14]。我们还可能会有大量的垃圾内容或损坏的内容,这会改变嵌入中的关系,在这种情况下,我们就需要重新训练。
我们可能很难理解嵌入(有些人甚至写了一整篇论文来讨论它们),并且更难以解释。例如,为什么在某个嵌入空间中,国王的嵌入向量与皇后的嵌入向量非常接近,但与骑士的嵌入向量相距很远?在某个嵌入空间中,两个flits的嵌入向量非常接近是什么意思?
我们可以从内部评估和外部评估两种角度来思考这个问题。对于嵌入本身(外部评估),我们可以通过UMAP(Uniform Manifold Approximation and Projection for Dimension Reduction)或t-sne(t-distributed stochastic neighbor embedding)进行可视化,这些算法允许我们将高维数据可视化为二维或三维数据,就像PCA一样。或者,我们也可以将嵌入适配到下游任务中(例如,摘要任务或分类任务),并以离线指标(offline metrics)相同的方式进行分析。还有其他许多不同的方法[15],但总的来说,嵌入客观上很难进行评估,我们需要将执行此评估的时间因素考虑到我们的模型构建时间中。
在重新训练初始基准模型(initial baseline model)后,我们将面临一个次要问题:如何比较第一组嵌入和第二组嵌入?也就是说,鉴于嵌入通常是无监督的,我们如何评估它们是否能很好地表示我们的数据,也就是说,我们如何知道”king”应该靠近”queen”?,对嵌入进行初步解释或评估时,嵌入本身可能很难解释,因为在多维空间中,由于向量的维度很多,有时很难理解,向量的哪个维度对应于将嵌入空间中的实体放在一起的决策[16]。与其他嵌入集进行比较时,我们可以使用最终模型任务(final model task)的离线指标(offline metrics),如精确率和召回率,或者我们可以通过比较两个概率分布(probability distributions)之间的统计距离(statistical distance),使用一种称为Kullback-Leibler divergence的指标来测量隐空间中嵌入分布的距离。
最后,假设我们有两组嵌入,需要对它们进行版本控制,并保留两组嵌入,以便在新模型效果不佳时可以回退到旧模型。这与机器学习操作中的模型版本控制问题是相辅相成的,只是在这种情况下,我们需要同时对模型和输出数据进行版本控制。
有许多不同的模型和数据的版本控制方法,其中一种方法是建立一个系统,来跟踪二级数据存储系统中资产的元数据和位置。另一个需要注意的问题是,特别是对于大词汇表,嵌入层可能会变得非常庞大,因此我们还需要考虑存储成本。
05 推理和延迟情况
在使用嵌入时,我们不仅需要在理论环境下工作,还在实际的工程环境中。任何在生产环境中运行的机器学习系统面临的最关键工程问题之一是推理时间——查询模型资产并将结果返回给终端用户需要多长时间。
为此,我们需要关心延迟,我们可以将其大致定义为全部的等待时间(any time spent waiting),这是所有生产系统中的关键性能指标[17]。一般来说,它是所有操作完成的时间——应用程序请求、数据库查询等等。Web服务级别的延迟通常以毫秒为单位衡量,每个人都会尽力将延迟时间减少到尽可能接近零。对于搜索和加载内容馈送的用例,必须是即时的,否则用户体验将会下降,我们甚至可能会失去收入。在Amazon的一项研究中,他们发现每增加100毫秒的延迟,利润就会减少1% [18]。
因此,我们需要考虑如何减少模型的占用空间以及为其提供服务的层数,从而实现对用户的即时响应。我们通过在整个机器学习系统中创建可观测性(observability)来实现这一点,从运行系统的硬件开始,到CPU和GPU的利用率,模型架构的性能以及该模型与其他组件的交互方式。例如,在执行最近邻查找时,我们执行查找的方式、我们使用的算法、我们用来编写该算法的编程语言,所有这些都会影响延迟的大小。
在《the wide and deep》论文中,推荐排序模型每秒对超过 1000 万个应用程序进行评分。该应用程序最初是单线程的,需要耗时31毫秒。通过实现多线程,能够将客户端延迟降低到14毫秒[19]。因此,需要在推理和延迟方面进行优化,以确保机器学习系统能够在生产环境中高效地运行。
机器学习系统的运营是另一个独立的领域,需要深入研究和探讨,最好单独写一篇论文来讨论。[20]
06 在线和离线模型评估
我们刚刚触及模型最关键部分之一的表面:模型在离线和在线测试中的表现如何。当我们谈论离线测试时,指的是分析模型的统计特性,以了解模型是否是一个有效的模型——即我们的损失函数是否收敛?模型是否过拟合或欠拟合?精确率和召回率是多少?我们是否遇到了任何数据漂移?对于推荐排序模型来说,我们使用像NDCG(normalized discounted cumulative gain)这样的指标来了解新模型,是否比上一次迭代对内容的排序更好?
然后是在线评估,即模型在生产环境中实际的成功程度。通常是通过A/B测试来评估的,即一组用户使用旧模型或系统,另一组用户使用新系统,并查看像点击率、提供的内容数量和在网站特定区域停留时间等指标。
07 使用嵌入的项目的成功之道
最后,当我们把所有算法和工程方面的问题都考虑清楚之后,还有最后一个问题需要考虑,那就是从业务角度来看怎样才能使我们的项目取得成功。我们应该认识到,不一定所有机器学习问题都需要用到嵌入技术,或者说,我们可能根本不需要机器学习,如果说我们的项目完全基于一些启发式规则,而这些规则可以由人类确定和分析[21]。
如果我们得出结论,我们是在一个数据丰富的空间中操作,在这个空间中自动推断实体之间的语义关系是正确的,那么我们需要问自己,是否愿意花费大量的精力来制作干净的数据集,这是任何优秀机器学习模型的基础,即使在大语言模型的情况下也是如此。实际上,干净的垂直领域数据非常重要,以至于本文讨论的许多公司最终都训练了属于自己的嵌入模型,而最近像彭博社[22]和Replit[23]这样的公司甚至正在训练自己的大语言模型,主要是为了提高其特定业务领域的准确率。
关键是,要让机器学习系统达到一个使用嵌入的阶段,我们需要一个团队,围绕需要完成的工作进行多层次的协调。在规模较大的公司中,该团队的规模将更大,但是最重要的是,大多数嵌入工作需要有人能够明确定义用例,还要一个支持实际用例并将其优先考虑的人,以及一个可以完成工作的技术人员[24]。
如果满足这些要求,我们就能构建一个基于嵌入的推荐系统。
END
参考资料
[1]David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, and Michael Young. Machine learning: The high interest credit card of technical debt.(2014), 2014.
[2]https://amatriai服务器托管网n.net/blog/RecsysArchitectures
[3]https://blog.replit.com/llm-training
[4]https://huggingface.co/docs/transformers/model_doc/bert
[5]https://resources.wolframcloud.com/NeuralNetRepository/resources/BERT-Trained-on-BookCorpus-and-English-Wikipedia-Data
[6]https://s10251.pcdn.co/pdf/2022-Alan-D-Thompson-Whats-in-my-AI-Rev-0.pdf
[7]https://github.com/soskek/bookcorpus/issues/27#issuecomment-716104208
[8]https://en.wikipedia.org/wiki/Library_Genesis
[9]Tianyi Zhang, Felix Wu, Arzoo Katiyar, Kilian Q Weinberger, and Yoav Artzi. Revisiting few-sample bert fine-tuning. arXiv preprint arXiv:2006.05987, 2020.
[10]https://fasttext.cc/docs/en/crawl-vectors.html
[11]https://platform.openai.com/docs/guides/embeddings/limitations-risks
[12]https://github.com/ray-project/llm-numbers#101—-cost-ratio-of-openai-embedding-to-self-hosted-embedding
[13]Dan Shiebler and Abhishek Tayal. Making machine learning easy with embeddings. SysML http://www.sysml.cc/doc/115.pdf, 2010.
[14]Christopher Wewer, Florian Lemmerich, and Michael Cochez. Updating embeddings for dynamic knowledge graphs. arXiv preprint arXiv:2109.10896, 2021.
[15]Krysta M Svore and Christopher JC Burges. A machine learning approach for improved bm25 retrieval. In Proceedings of the 18th ACM conference on Information and knowledge management, pages 1811–1814, 2009.
[16]Adi Simhi and Shaul Markovitch. Interpreting emb服务器托管网edding spaces by conceptualization. arXiv preprint arXiv:2209.00445, 2022.
[17]Brendan Gregg. Systems performance: enterprise and the cloud. Pearson Education, 2014.
[18]Tobias Flach, Nandita Dukkipati, Andreas Terzis, Barath Raghavan, Neal Cardwell, Yuchung Cheng, Ankur Jain, Shuai Hao, Ethan Katz-Bassett, and Ramesh Govindan. Reducing web latency: the virtue of gentle aggression. In Proceedings of the ACM SIGCOMM 2013 conference on SIGCOMM, pages 159–170, 2013.
[19]Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016.
[20]Dominik Kreuzberger, Niklas Khl, and Sebastian Hirschl. Machine learning operations (mlops): Overview, definition, and architecture. arXiv preprint arXiv:2205.02302, 2022.
[21]Martin Zinkevich. Rules of machine learning: Best practices for ml engineering. URL: https://developers. google. com/machine-learning/guides/rules-ofml, 2017.
[22]Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.
[23]Reza Shabani. How to train your own large language models, Apr 2023.
URL https://blog.replit.com/llm-training.
[24]Doug Meil. Ai in the enterprise. Communications of the ACM, 66(6):6–7, 2023.
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://vickiboykis.com/what_are_embeddings/index.html
往期相关文章:
Embedding技术与应用(3):Embeddings技术的实践应用
Embedding技术与应用 (2) :神经网络的发展及现代Embedding方法简介
Embeddig技术与应用 (1) :Embedding技术发展概述及Word2Vec
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
