
都说IT今年很难,越是在这个时候越是要坚持,相信总能看到黎明与曙光。这不我准备整理一下教程,对自己也是一个学习、总结的过程,我相信待到经济复苏,IT仍然是热门。
本文是我的第一篇付费文章,这是个开篇纵览,后服务器托管网面会深入讲解Flink理论与开发,不限于Flink这一个组件,后面也会有Spark、Clickhouse等等,代码也会配套同步到Gitee上面(Gitee地址见文末)。
目录
-
Flink 架构
-
流处理
-
示例
-
Data Sources
-
基本的stream source
-
-
DataStream Transformations
-
Data Sinks
-
Flink 中的 API
-
容错处理
-
迟到的数据
本章教程对 Apache Flink 的基本概念进行了介绍,虽然省略了许多重要细节,但是如果你掌握了本章内容,就足以对Flink实现可扩展并行度的 ETL、数据分析以及事件驱动的流式应用程序,有一个大致的了解。
Flink 架构
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如Hadoop YARN,但也可以设置作为独立集群甚至库运行。Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
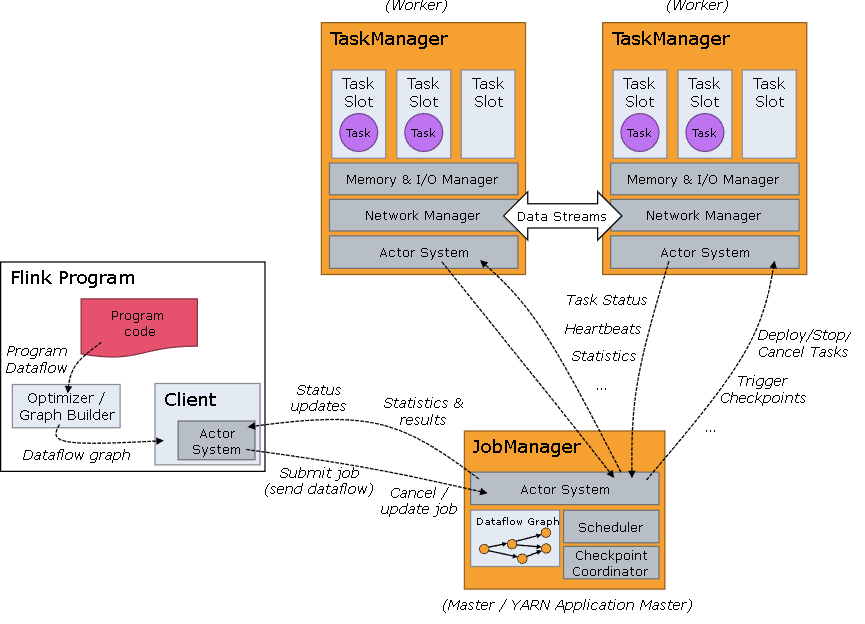
Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程./bin/flink run …中运行。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为standalone 集群启动、在容器中启动、或者通过YARN等资源框架管理并启动。TaskManager 连接到 JobManagers,宣布自己可用,并被分配工作。
流处理
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
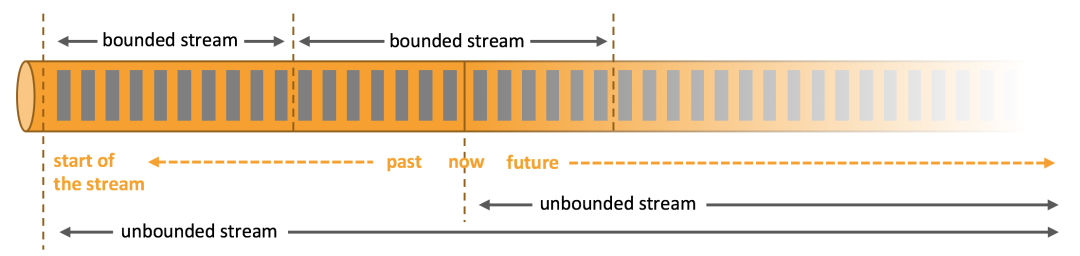
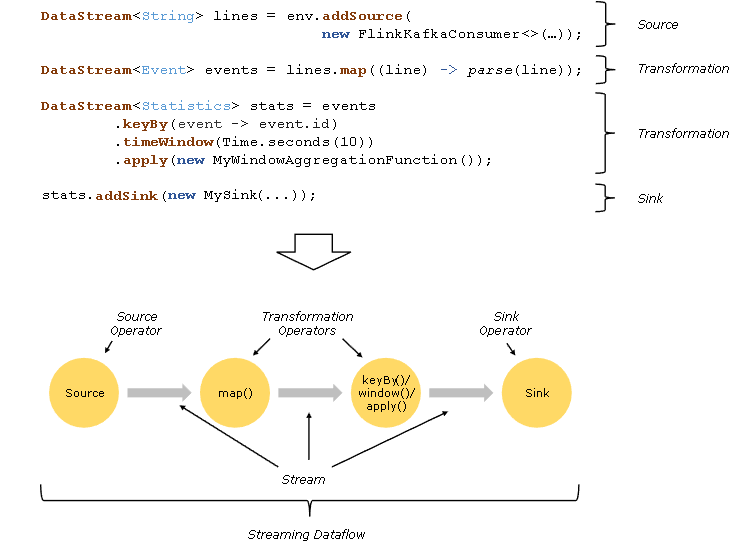
Flink 程序看起来像一个转换 DataStream 的常规程序。每个程序由相同的基本部分组成:
-
获取一个执行环境(execution environment);
-
加载/创建初始数据;
-
指定数据相关的转换;
-
指定计算结果的存储位置;
-
触发程序执行。
通常,你只需要使用 getExecutionEnvironment() 即可,因为该方法会根据上下文做正确的处理:如果你在 IDE 中执行你的程序或将其作为一般的 Java 程序执行,那么它将创建一个本地环境,该环境将在你的本地机器上执行你的程序。如果你基于程序创建了一个 JAR 文件,并通过命令行运行它,Flink 集群管理器将执行程序的 main 方法,同时 getExecutionEnvironment() 方法会返回一个执行环境以在集群上执行你的程序。
StreamExecutionEnvironmentsenv=StreamExecutionEnvironment.getExecutionEnvironment();示例
如下是一个完整的、可运行的程序示例,它是基于流窗口的单词统计应用程序,计算 5 秒窗口内来自 Web 套接字的单词数。你可以复制并粘贴代码以在本地运行,需要的maven依赖地址。
packagewordcount;
importorg.apache.flink.api.common.functions.FlatMapFunction;
importorg.apache.flink.api.java.tuple.Tuple2;
importorg.apache.flink.streaming.api.datastream.DataStream;
importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
importorg.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
importorg.apache.flink.streaming.api.windowing.time.Time;
importorg.apache.flink.util.Collector;
publicclassWindowWordCount{
publicstaticvoidmain(String[]args)throwsException{
StreamExecutionEnvironmentenv=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream>dataStream=env
.socketTextStream("192.168.20.130",9999)
.flatMap(newSplitter())
.keyBy(value->value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
System.out.println("parallelism->"+env.getParallelism());
env.execute("WindowWordCount");
}
publicstaticclassSplitterimplementsFlatMapFunction>{
@Override
publicvoidflatMap(Stringsentence,服务器托管网Collector>out)throwsException{
for(Stringword:sentence.split("")){
out.collect(newTuple2(word,1));
}
}
}
}Linux安装nc工具:yum install nc,并且在命令行键入数据:
[root@hadoop-001~]#nc-lk9999
flinkflinkspark
flinkhadoopspark程序执行结果:
#IDEA执行,默认flink并行度是8,可以env.setParallelism来设置
parallelism->8
1>(spark,1)
7>(flink,2)
1>(spark,1)
8>(hadoop,1)
7>(flink,1)两个窗口的结果,可以看到,把flink spark hadoop三个单词的总次数一个不漏的算出来了。需要注意打印结果,1>表示编号为1的task打印的,代码的gitee地址 。
我们知道了一个Flink程序通常有source -> transform -> sink,即 读取数据源,处理转换数据,结果保存 ,接下来将逐步介绍这些基本用法。
Data Sources
Source 是你的程序从中读取其输入的地方。你可以用 StreamExecutionEnvironment.addSource(sourceFunction) 将一个 source 关联到你的程序。Flink 自带了许多预先实现的 source functions,不过你仍然可以通过实现 SourceFunction 接口编写自定义的非并行 source,也可以通过实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 类编写自定义的并行 sources。通过 StreamExecutionEnvironment 可以访问多种预定义的 stream source:
1 基于文件:
-
readTextFile(path) – 读取文本文件,例如遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。
-
readFile(fileInputFormat, path) – 按照指定的文件输入格式读取(一次)文件。
-
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) – 这是前两个方法内部调用的方法。它基于给定的 fileInputFormat 读取路径 path 上的文件。根据提供的 watchType 的不同,source 可能定期(每 interval 毫秒)监控路径上的新数据(watchType 为 FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次当前路径中的数据然后退出(watchType 为 FileProcessingMode.PROCESS_ONCE)。使用 pathFilter,用户可以进一步排除正在处理的文件。
实现:
在底层,Flink 将文件读取过程拆分为两个子任务,即 目录监控 和 数据读取。每个子任务都由一个单独的实体实现。监控由单个非并行(并行度 = 1)任务实现,而读取由多个并行运行的任务执行。后者的并行度和作业的并行度相等。单个监控任务的作用是扫描目录(定期或仅扫描一次,取决于 watchType),找到要处理的文件,将它们划分为 分片,并将这些分片分配给下游 reader。Reader 是将实际获取数据的角色。每个分片只能被一个 reader 读取,而一个 reader 可以一个一个地读取多个分片。
重要提示:
-
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,当一个文件被修改时,它的内容会被完全重新处理。这可能会打破 “精确一次” 的语义,因为在文件末尾追加数据将导致重新处理文件的所有内容。
-
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,source 扫描一次路径然后退出,无需等待 reader 读完文件内容。当然,reader 会继续读取数据,直到所有文件内容都读完。关闭 source 会导致在那之后不再有检查点。这可能会导致节点故障后恢复速度变慢,因为作业将从最后一个检查点恢复读取。
2 基于套接字:
-
socketTextStream – 从套接字读取。元素可以由分隔符分隔。
3 基于集合:
-
fromCollection(Collection) – 从 Java Java.util.Collection 创建数据流。集合中的所有元素必须属于同一类型。
-
fromCollection(Iterator, Class) – 从迭代器创建数据流。class 参数指定迭代器返回元素的数据类型。
-
fromElements(T …) – 从给定的对象序列中创建数据流。所有的对象必须属于同一类型。
-
fromParallelCollection(SplittableIterator, Class) – 从迭代器并行创建数据流。class 参数指定迭代器返回元素的数据类型。
-
generateSequence(from, to) – 基于给定间隔内的数字序列并行生成数据流。
4 自定义:
-
addSource – 关联一个新的 source function。例如,你可以使用 addSource(new FlinkKafkaConsumer(…)) 来从 Apache Kafka 获取数据。更多详细信息见连接器。
基本的stream source
这样将简单的流放在一起是为了方便用于原型或测试。StreamExecutionEnvironment 上还有一个 fromCollection(Collection) 方法。因此,你可以这样做:
Listpeople=newArrayList();
people.add(newPerson("Fred",35));
people.add(newPerson("Wilma",35));
people.add(newPerson("Pebbles",2));
DataStreamflintstones=env.fromCollection(people);另一个获取数据到流中的便捷方法是用 socket
DataStreamlines=env.socketTextStream("localhost",9999)
publicstaticvoiddemo4()throwsException{
StreamExecutionEnvironmentsenv=StreamExecutionEnvironment.getExecutionEnvironment();
/**
* 1. linux安装nc工具:yum install nc
* 2. 发送数据:nc -lk 9999
*/
DataStreampersons=senv.socketTextStream("192.168.20.130",9999)
.map(line->newPerson(line.split(",")[0],Integer.valueOf(line.split(",")[1])));
persons.print();
senv.execute("DataSourceDemo");
}或读取文件
DataStreamlines=env.readTextFile("file:///path");在真实的应用中,最常用的数据源是那些支持低延迟,高吞吐并行读取以及重复(高性能和容错能力为先决条件)的数据源,例如 Apache Kafka,Kinesis 和各种文件系统,这将在后面的教程会经常使用Kafka Source。REST API 和数据库也经常用于增强流处理的能力(stream enrichment)。
由于篇幅,这里不会列出所有的代码,demo的gitee地址 。
DataStream Transformations
转换主要常用的算子有map、flatMap、Filter、KeyBy、Window等,它们作用是对数据进行清洗、转换、分发等。这里列出几个常用算子,在以后的Flink程序编写中,这将是非常常用的。通常都需要用户自定义Function,可以通过1)实现接口;2)匿名类;3)Java8 Lambdas表达式;
1. Map算子 DataStream => DataStream
输入一个元素同时输出一个元素。下面是将输入流中元素数值加倍的 map function:
DataStreamdataStream=//...
dataStream.map(newMapFunction(){
@Override
publicIntegermap(Integervalue)throwsException{
return2*value;
}
});2. FlatMap算子 DataStream => DataStream
输入一个元素同时产生零个、一个或多个元素。下面是将句子拆分为单词的 flatmap function:
dataStream.flatMap(newFlatMapFunction(){
@Override
publicvoidflatMap(Stringvalue,Collectorout)
throwsException{
for(Stringword:value.split("")){
out.collect(word);
}
}
});3. Filter算子 DataStream => DataStream
为每个元素执行一个布尔 function,并保留那些 function 输出值为 true 的元素。下面是过滤掉零值的 filter:
dataStream.filter(newFilterFunction(){
@Override
publicbooleanfilter(Integervalue)throwsException{
returnvalue!=0;
}
});KeyBy算子 DataStream => KeyedStream
在逻辑上将流划分为不相交的分区。具有相同 key 的记录都分配到同一个分区。在内部, keyBy() 是通过哈希分区实现的,有多种指定 key 的方式,以下是通过Java8 Lambdas表达式:
dataStream.keyBy(value->value.getSomeKey());
dataStream.keyBy(value->value.f0);还可以通过实现KeySelector接口,来指定key。
Rich Functions
至此,你已经看到了 Flink 的几种函数接口,包括 FilterFunction, MapFunction,和 FlatMapFunction。这些都是单一抽象方法模式。对其中的每一个接口,Flink 同样提供了一个所谓 “rich” 的变体,如 RichFlatMapFunction,其中增加了以下方法,包括:
-
open(Configuration c)
-
close()
-
getRuntimeContext()
open() 仅在算子初始化时调用一次。可以用来加载一些静态数据,或者建立外部服务的链接等,比如从数据库读取配置。
getRuntimeContext() 为整套潜在有趣的东西提供了一个访问途径,最明显的,它是你创建和访问 Flink 状态的途径。
Data Sinks
Data sinks 使用 DataStream 并将它们转发到文件、套接字、外部系统或打印它们。Flink 自带了多种内置的输出格式,这些格式相关的实现封装在 DataStreams 的算子里:
-
writeAsText() / TextOutputFormat – 将元素按行写成字符串。通过调用每个元素的 toString() 方法获得字符串。
-
writeAsCsv(…) / CsvOutputFormat – 将元组写成逗号分隔值文件。行和字段的分隔符是可配置的。每个字段的值来自对象的 toString() 方法。
-
print() / printToErr() – 在标准输出/标准错误流上打印每个元素的 toString() 值。可选地,可以提供一个前缀(msg)附加到输出。这有助于区分不同的 print 调用。如果并行度大于1,输出结果将附带输出任务标识符的前缀。
-
writeUsingOutputFormat() / FileOutputFormat – 自定义文件输出的方法和基类。支持自定义 object 到 byte 的转换。
-
writeToSocket – 根据 SerializationSchema 将元素写入套接字。
-
addSink – 调用自定义 sink function。Flink 捆绑了连接到其他系统(例如 Apache Kafka)的连接器,这些连接器被实现为 sink functions。
print() / printToErr() 主要是程序开发调试的时候,将一些中间结果打印到控制台,便于调试。
在实际业务开发中,通常会使用addSink ,里面传入一个SinkFunction对象,将结果保存到mysql等外部存储。
rows.addSink(newRichSinkFunction(){
privateConnectionconn=null;
@Override
publicvoidopen(Configurationparameters)throwsException{
super.open(parameters);
if(conn==null){
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
conn=DriverManager.getConnection("jdbc:clickhouse://192.168.1.2:8123/test");
}
}
@Override
publicvoidclose()throwsException{
super.close();
if(conn!=null){
conn.close();
}
}
@Override
publicvoidinvoke(Rowrow,Contextcontext)throwsException{
Stringsql="";
PreparedStatementps=null;
sql="insertintotable...";
ps=conn.prepareStatement(sql);
ps.setInt(1,...);
ps.execute();
if(ps!=null){
ps.close();
}
}
});在sink里面拿到数据库连接,通常在open()方法,并且组装sql,invoke()将其写入到数据库。
Flink 中的 API
Flink 为流式/批式处理应用程序的开发提供了不同级别的抽象。
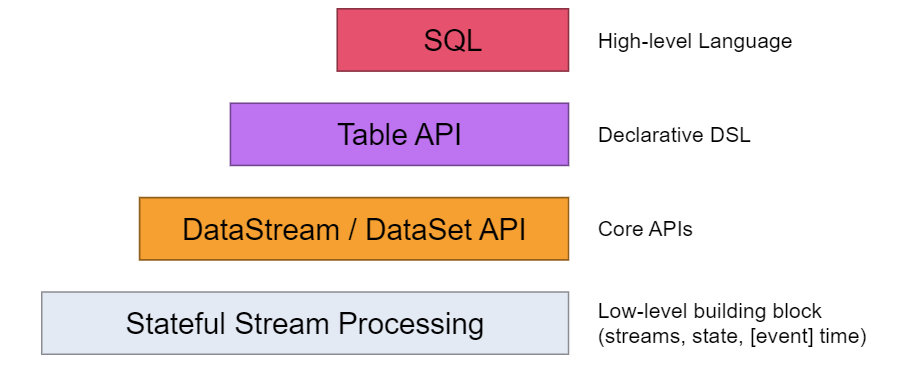
-
Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态。此外,用户可以在此层抽象中注册事件时间(event time)和处理时间(processing time)回调方法,从而允许程序可以实现复杂计算。
-
Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
-
Process Function 这类底层抽象和 DataStream API 的相互集成使得用户可以选择使用更底层的抽象 API 来实现自己的需求。DataSet API 还额外提供了一些原语,比如循环/迭代(loop/iteration)操作。
-
Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。Table API 遵循(扩展)关系模型:即表拥有 schema(类似于关系型数据库中的 schema),并且 Table API 也提供了类似于关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以声明的方式定义应执行的逻辑操作,而不是确切地指定程序应该执行的代码。尽管 Table API 使用起来很简洁并且可以由各种类型的用户自定义函数扩展功能,但还是比 Core API 的表达能力差。此外,Table API 程序在执行之前还会使用优化器中的优化规则对用户编写的表达式进行优化。
表和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。
-
Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。
容错处理
流式处理遇到程序中断是很常见的异常,如何恢复,这将是很关键的,那么Flink又是如何进行容错的呢?
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
在 PHP 中,GET 和 POST 是用于从客服务器托管网户端向服务器传递数据的两种常用的 HTTP 请求方法。它们之间的主要区别在于数据传递的方式和使用场景。 GET 方法: 数据传递方式: 使用 URL 参数传递数据,数据附加在 URL 后面,以 ? 开…
