
kafka source
接收kafka的数据
org.apache.kafka
kafka-clients
2.8.0
org.apache.flink
flink-connector-kafka_2.12
1.12.0
public class kafkaSourceStudent {
public static void main(String[] args) throws Exception {
// 运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置 kafka 连接属性
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","10.50.8.136:9093");
// 创建kafka数据源
FlinkKafkaConsumer kafkaConsumer = new FlinkKafkaConsumer("vsoc_etl_rule_filter", new SimpleStringSchema(), properties);
// 添加 Kafka 数据源到 Flink 环境
env.addSource(kafkaConsumer).print();
// 执行任务
env.execute("Flink Kafka Source Example");
}
}消费策略
提供了四种消费策略:
// 创建kafka数据源
FlinkKafkaConsum服务器托管网er kafkaConsumer = new FlinkKafkaConsumer("vsoc_etl_rule_filter", new SimpleStringSchema(), properties);
// 默认设置,读取group.id对应保存的offset开始消费的数据,读取不到读取auto.offset.rest参数设置的策略
kafkaConsumer.setStartFromGroupOffsets();
// 从最早的记录开始消费数据,排除已提交的offset信息
kafkaConsumer.setStartFromEarliest();
// 从最新的开始消费 排除已提交的offset信息
kafkaConsumer.setStartFromLatest();
// 从指定时间戳开始消费数据
kafkaConsumer.setStartFromTimestamp(213412412312L);kafka consumer的容错
当checkPoint机制开启的时候,consumer会定期把kafka的offset信息还有其他算子任务的state信息一块保存起来,当job失败重启的时候,Flink会从最近的一次checkPoint中进行恢复数据,重新消费kafka中的数据。
启动checkpoint:
// 运行环境
StreamExecutionE服务器托管网nvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 5秒执行一次 checkPoint
env.enableCheckpointing(5000);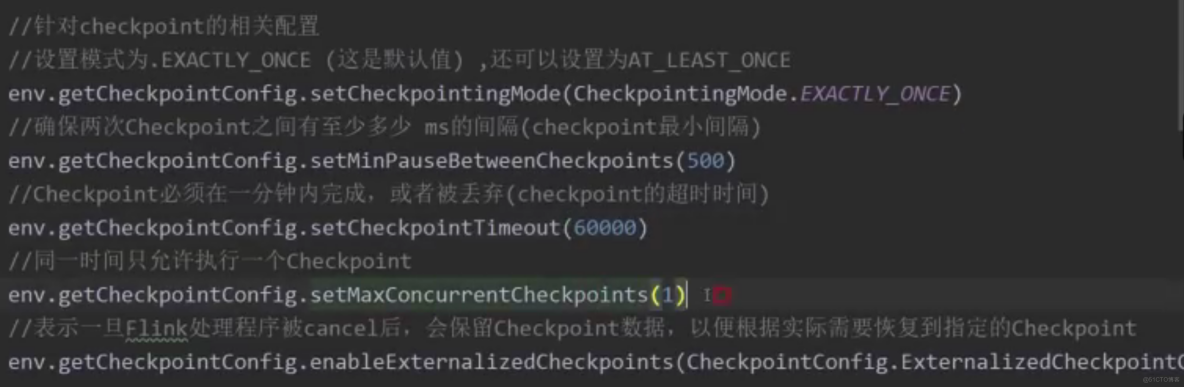
state数据存储:
- MemorySateBackend:基于内存存储
- FsSateBackend:基于远程文件系统,如hdfs
- RocksDBStateBackend:先存储在本地文件系统中,会同步到远程文件系统
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
左偏树 左偏树是一种可以让我们在 (O(log n )) 的时间复杂度内进行合并的堆式数据结构。 为了方便以下的左偏树为小根堆来讨论。 定义 外结点:左儿子或者右儿子是空节点的结点。 距离:一个结点 (x) 的距离 (dis[x]) 定义为其子树中与结点 (x…
